






【3050 Ti】也能本地部署Qwen2.5-VL
引言
随着多模态人工智能技术的快速发展,视觉语言模型(Vision-Language Models, VLMs)逐渐成为研究和应用的热点。Qwen2.5-VL是阿里巴巴通义实验室推出的一款先进的视觉语言模型,能够处理图像和文本的联合任务,如图像描述生成、视觉问答(VQA)、图文匹配等。
本文将详细介绍如何在一台配备NVIDIA GeForce RTX 3050 Ti显卡的设备上部署Qwen2.5-VL。
一、Qwen2.5-VL介绍
1.1 模型背景
Qwen2.5-VL是基于Qwen2.5大模型开发的视觉语言模型,继承了Qwen系列在自然语言处理领域的强大能力,同时扩展了对视觉信息的理解和生成能力。它支持多种跨模态任务,能够无缝结合图像和文本数据,为用户提供丰富的应用场景。
1.2 开源与生态
Qwen2.5-VL已开源,用户可以通过阿里云ModelScope平台获取模型权重和相关文档。此外,ModelScope还提供了详细的教程和API支持,帮助开发者快速集成模型到自己的项目中。
二、模型能力
Qwen2.5-VL具备以下核心能力:
2.1 图像描述生成
输入一张图片,模型可以自动生成描述性文字。例如:
- 输入:一张风景照片
- 输出:这张照片展示了一棵位于新西兰瓦纳卡湖中的著名柳树,被称为“那棵瓦纳卡树”。这棵树以其独特的姿态和在平静湖水中的完美倒影而闻名。周围的景色包括白雪覆盖的山脉和宁静的天空,使其成为摄影师和游客们钟爱的拍摄地点。整张照片捕捉到了这一自然地标令人惊叹的美丽与宁静。

2.2 视觉问答(VQA)
给定一张图片和一个问题,模型会返回答案。例如:
- 输入:图片 + 问题“图片中的动物是什么?”
- 输出:“图片中的动物是一只小猫。它有着橙色的毛发和蓝色的眼睛,看起来非常可爱。小猫正坐在一块木头上,背景是模糊的绿色植物。

2.3 图文匹配
判断一段文本是否与图片相关联。例如:
- 输入:图片 + 文本“这是一张关于科技的照片”
- 输出:这张照片确实可以被视为一张关于科技的照片,尽管它以一种非常艺术化和象征性的方式呈现。以下是一些支持这一观点的理由…

2.4 跨模态内容生成
模型可以根据文本生成相关的图像描述,或者根据图像生成相关的文本内容。
- 输入:图片中的狗狗在哪儿
- 输出:图片中的狗狗位于一片绿色的草地上,正朝向镜头方向奔跑。它嘴里叼着一根木棍,显得非常活泼和快乐。狗狗的位置大约在画面的中央偏上部分,背景是一片开阔的草地,没有其他明显的障碍物或物体。

三、部署方案
在本节中,我们将详细介绍如何在一台配备RTX 3050 Ti显卡的设备上部署Qwen2.5-VL。
3.1 硬件环境
- GPU:NVIDIA GeForce RTX 3050 Ti(4GB显存)
- CPU:Intel Core i5 或更高
- 内存:至少8GB RAM(建议16GB)
- 存储:至少20GB可用空间(用于安装依赖和模型文件)
3.2 软件环境
- 操作系统:Windows 10/11 或 Linux(Ubuntu 20.04)
- Python版本:3.8或更高
- CUDA Toolkit:CUDA 11.7(与RTX 3050 Ti兼容)
- PyTorch:1.12或更高
- Anaconda:最新版本
- Transformers库(Hugging Face)
3.3安装步骤
1、克隆 Qwen2.5-VL GitHub 存储库
git clone https://github.com/QwenLM/Qwen2.5-VL
2、创建虚拟环境并指定版本(可选)
# 我创建的虚拟环境名称为qwenvl
conda create -n your_env_name python=3.x
3、激活虚拟环境,安装Pytorch及CUDA环境,可以直接到Pytorch官网复制代码直接安装。https://pytorch.org/

# 激活虚拟环境
activate qwenvl
# 安装Pytorch及CUDA环境
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
4、导航到 Qwen2.5-VL GitHub 存储库目录并安装Qwen2.5-VL
# 1、导航到Qwen2.5-VL本地目录
cd Qwen2.5-VL
# 2、使用以下命令安装 Web 应用程序所需的依赖项:
pip install -r requirements_web_demo.txt
# 3、安装模型,由于电脑配置问题,我选择的是较小的 3B 模型
python web_demo_mm.py --checkpoint-path "Qwen/Qwen2.5-VL-3B-Instruct"
5、电脑配置好的可以选择更大的模型
# 1、显存高于8GB可以选择7B 模型
python web_demo_mm.py --checkpoint-path "Qwen/Qwen2.5-VL-7B-Instruct"
# 2、专业级别的 GPU,那么可以直接上 72B 的最大模型
python web_demo_mm.py --checkpoint-path "Qwen/Qwen2.5-VL-72B-Instruct"
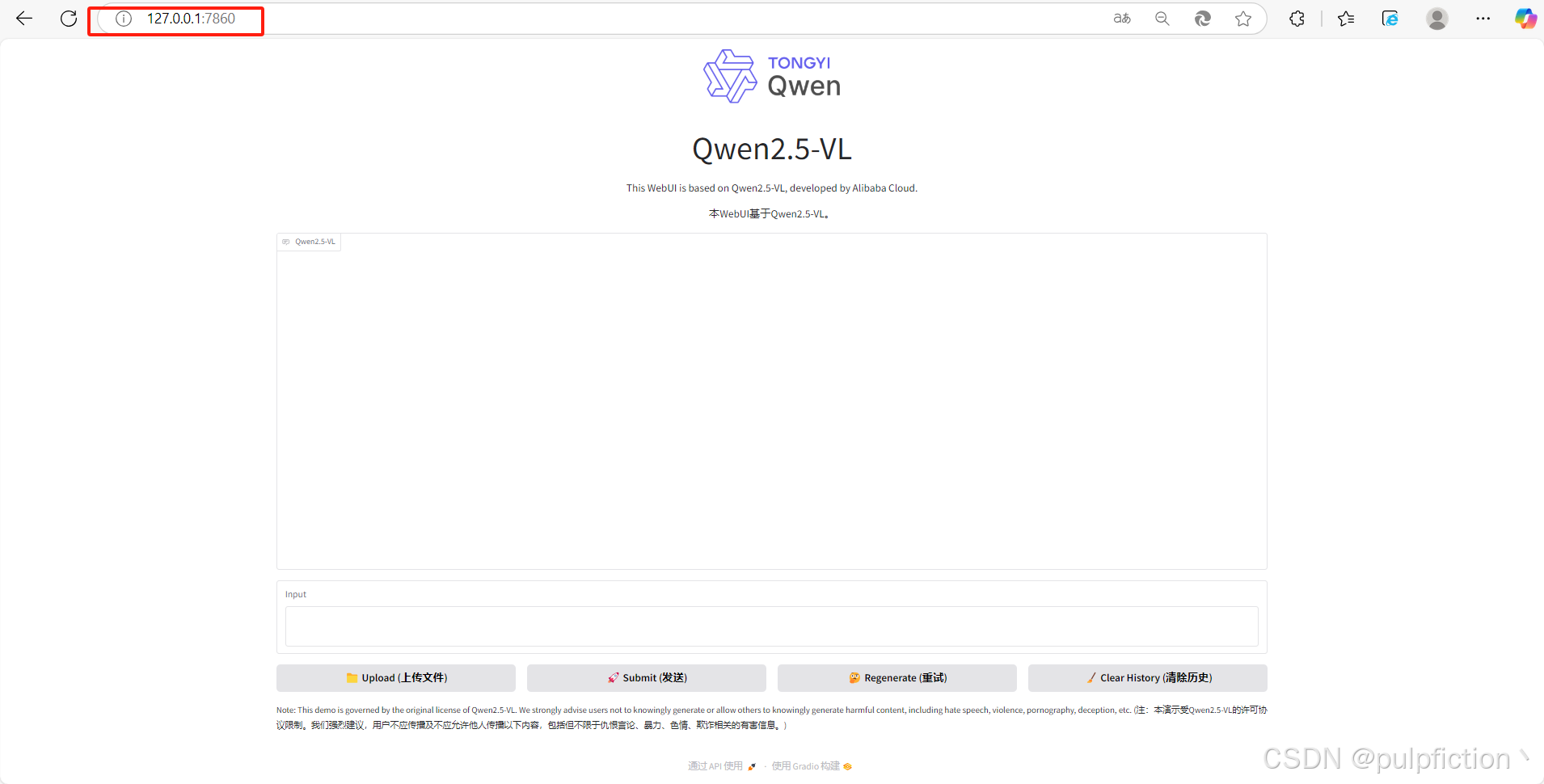
6、安装完成后在浏览器上打开本地链接 http://127.0.0.1:7860 即可正常使用
四、注意事项
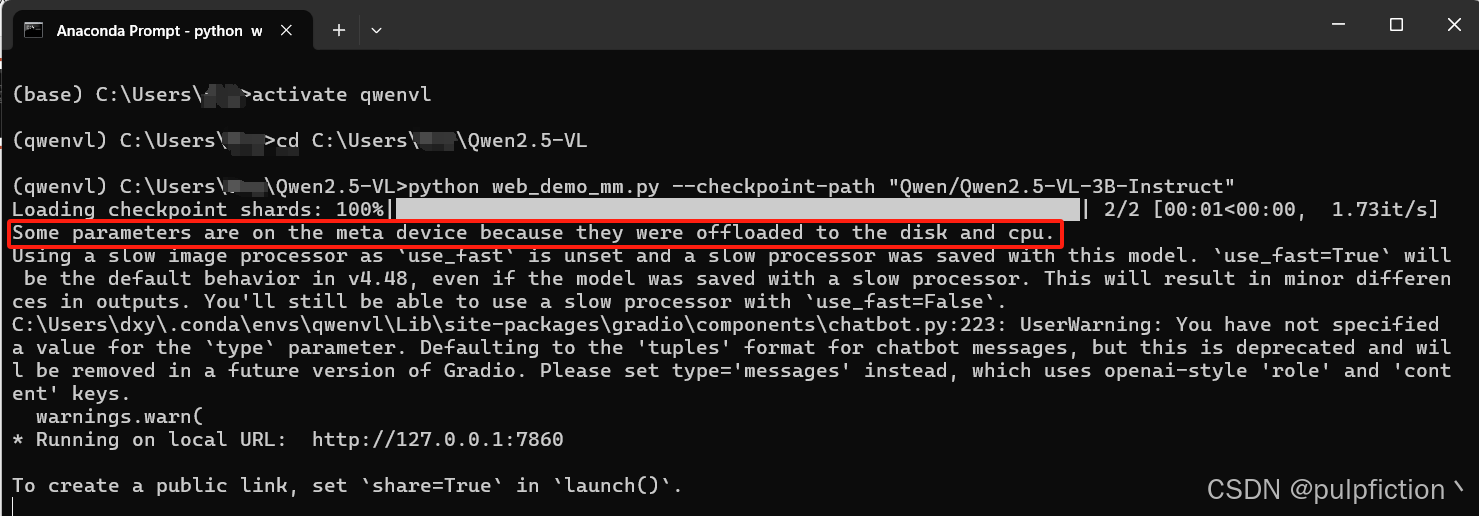
1、当出现“Some parameters are on the meta device because they were offloaded to the disk and cpu.”说明模型运行在CPU上,极大概率运行报错。
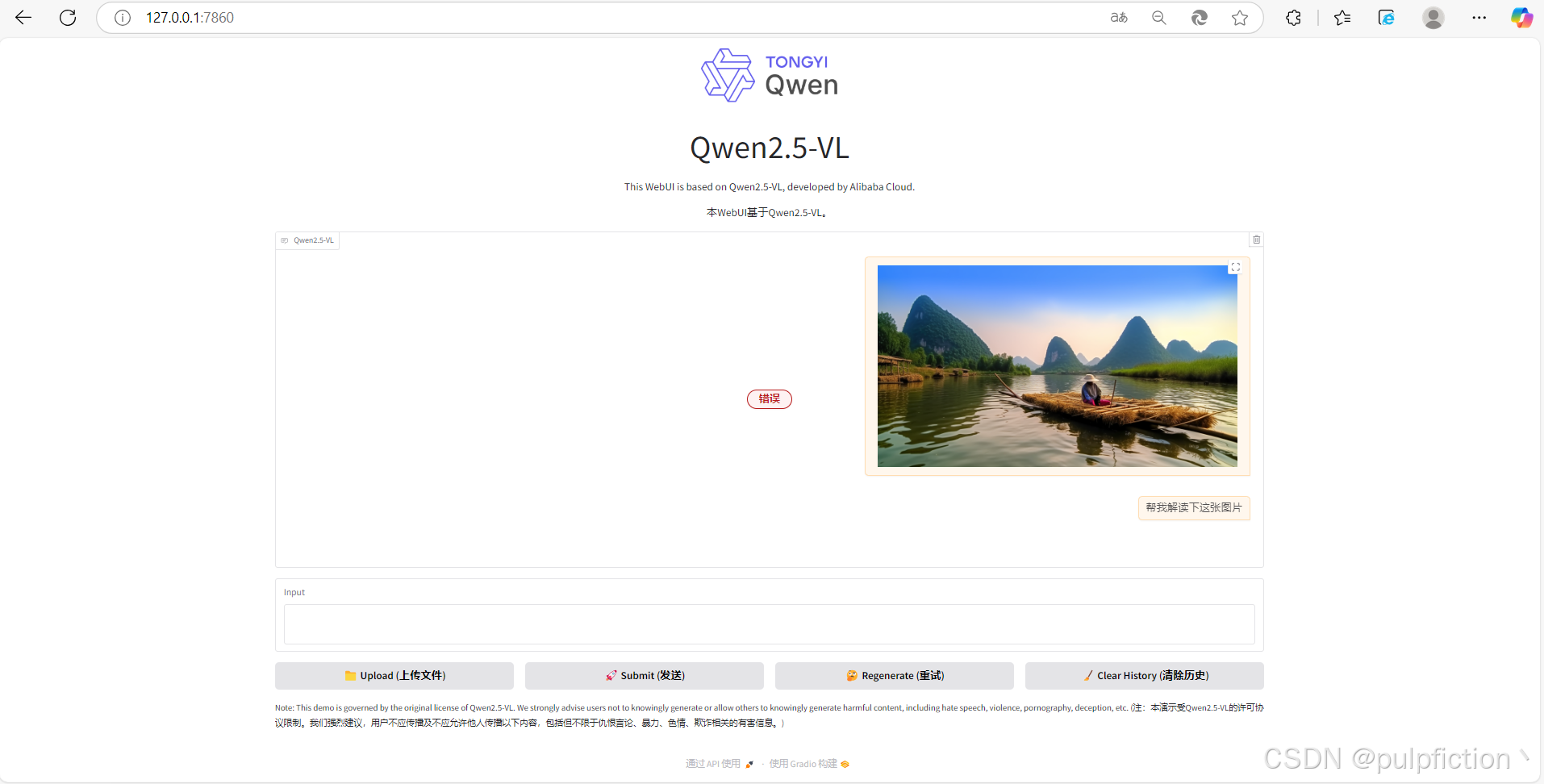
2、解决方法:找到本地 Qwen2.5-VL GitHub 存储库目录web_demo_mm.py文件。

3、打开web_demo_mm.py文件,将下列图片中的代码替换为下面代码,并指定在CUDA上运行:。

# 设置设备映射
device_map = {
"": "cuda:0" if not args.cpu_only else "cpu"
}
# 检查CUDA可用性
if not args.cpu_only and not torch.cuda.is_available():
raise RuntimeError("CUDA设备不可用,请添加--cpu-only参数运行")
# 加载模型时显式指定设备
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
args.checkpoint_path,
device_map=device_map,
torch_dtype=torch.bfloat16 if not args.cpu_only else torch.float32
)
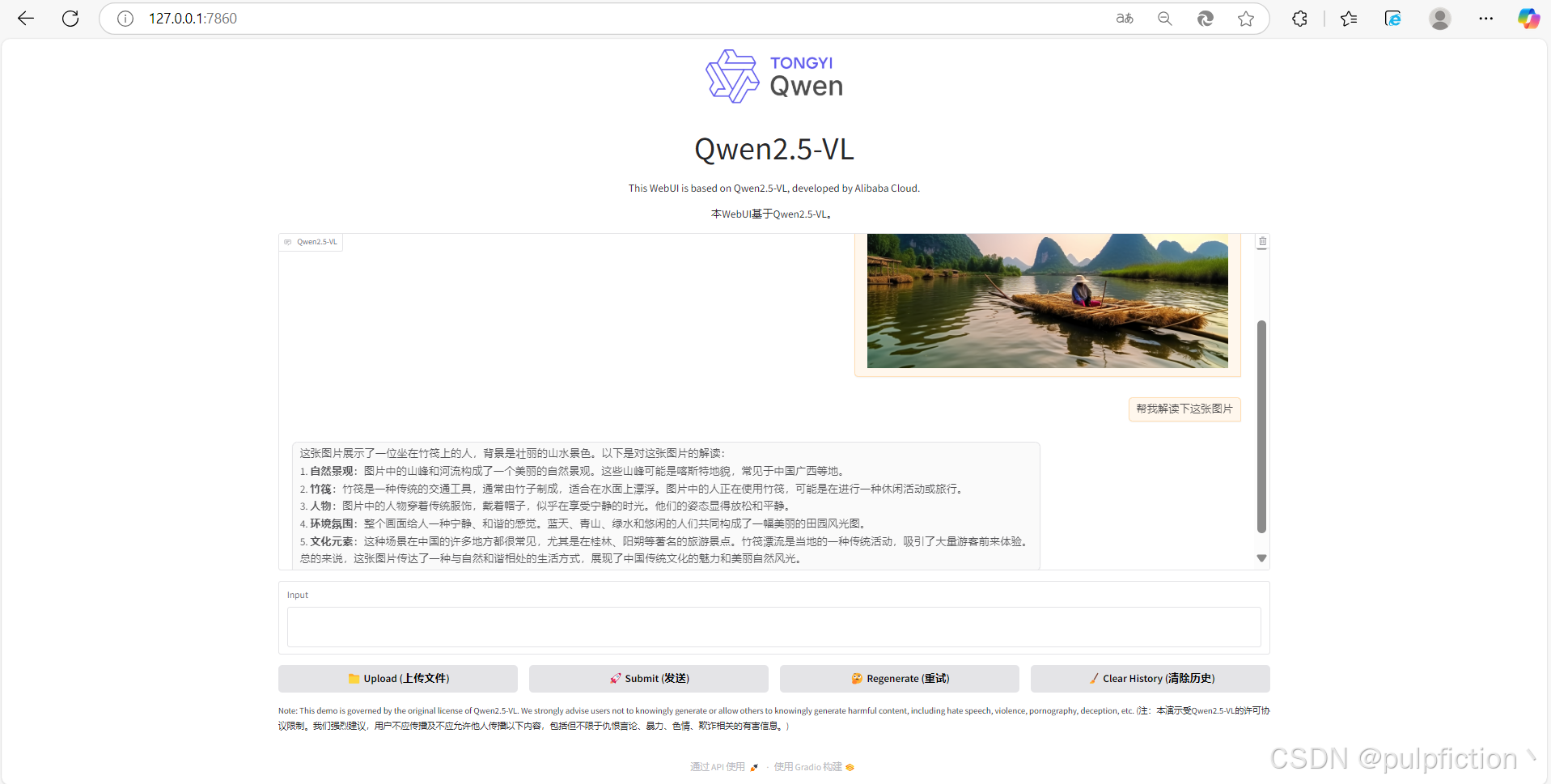
4、重新运行环境,激活模型

















 2871
2871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









