







1.前言
1.1.运行效果:风速发电预测(线性回归模型 、XGBoost模型 、决策树回归模型 、随机森林回归模型 、梯度提升回归模型与LSTM模型对比,多特征输入,单标签输出,可轻易替换_哔哩哔哩_bilibili
1.2.环境库:

如果库版本不一样, 一般也可以运行,这里展示我运行时候的库版本,是为了防止你万一在你的电脑上面运行不了,可以按照我的库版本进行安装并运行
如果想查看自己本地目前库的版本,可以运行下面的代码
import tensorflow as tf
print("TensorFlow版本:", tf.__version__)
import numpy as np
import pandas as pd
import datetime as dt
import plotly
import matplotlib
print("NumPy版本:", np.__version__)
print("Pandas版本:", pd.__version__)
print("Plotly版本:", plotly.__version__)
print("Matplotlib版本:", matplotlib.__version__)
import xgboost
import sklearn
print("XGBoost版本:", xgboost.__version__)
print("sklearn版本:", sklearn.__version__)2.数据集介绍
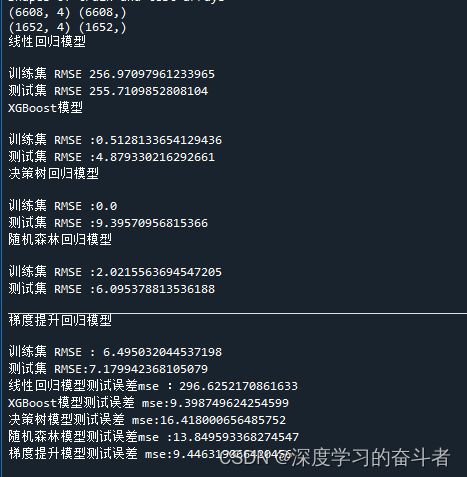
2022年美国某个风电场数据集(从1月1号中午12:00开始收集数据,截止时间为:12月31号下午11:00,每隔一个小时收集数据一次),一共8760行数据。
一共有6列数据:列名字为Time stamp(2022); System power generated | (kW) ;Wind speed | (m/s); Wind direction | (deg); Pressure | (atm) ;Air temperature | ('C);
对应的中文名字:时间戳("Time stamp");系统发电功率;风速;风向;气压;空气温度。
数据开始位置

数据截止位置

3.项目文件夹

data文件夹装载风力发电数据集
code.py是线性回归模型 、XGBoost模型 、决策树回归模型 、随机森林回归模型 、梯度提升回归模型
LSTM.py是LSTM预测模型
version.py是查看自己本地目前库的版本
4.效果
4.1.五个传统机器学习模型(线性回归模型 、XGBoost模型 、决策树回归模型 、随机森林回归模型 、梯度提升回归模型)
一个样本的特征:风速;风向;气压;空气温度;样本对应的标签:系统发电功率。
训练集与测试集比例:4:1。也就是前6608行数据为训练集,后1652行是测试集。
线性回归模型
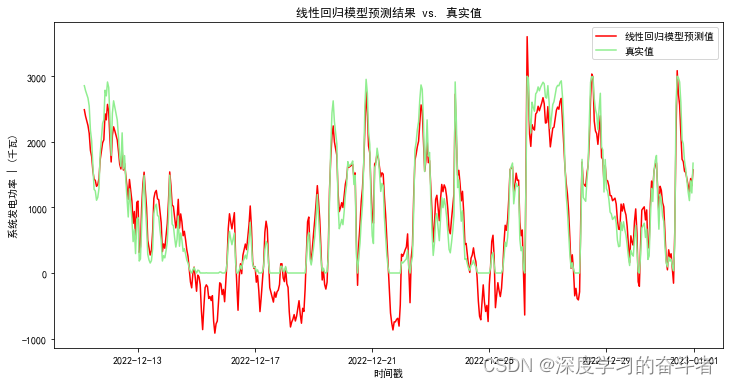
XGBoost模型
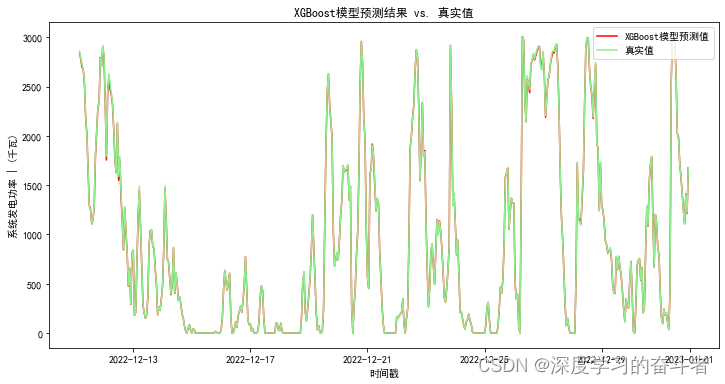
决策树回归模型
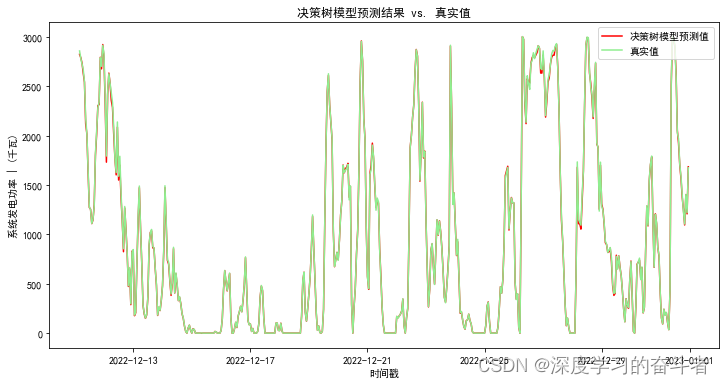
随机森林回归模型
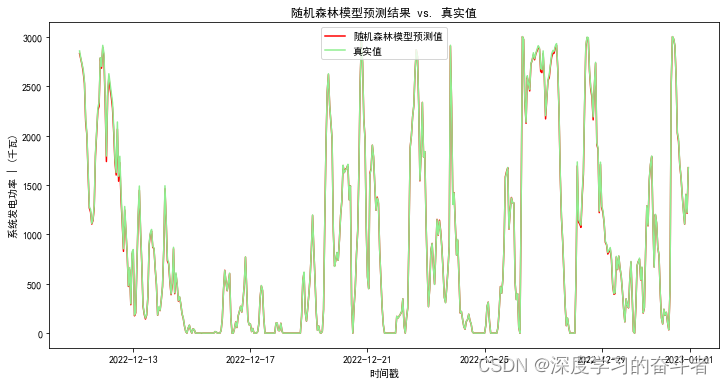
梯度提升回归模型
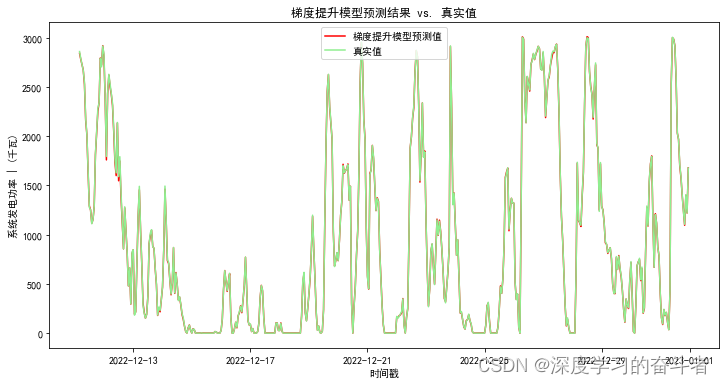 五个模型的训练集与测试集RMSE
五个模型的训练集与测试集RMSE
测试集的MSE
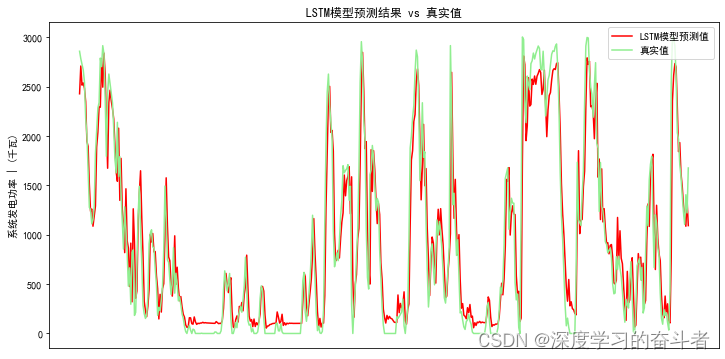
4.2.LSTM模型
因为前面五个传统机器学习模型效果已经不错了,所以这里LSTM采用另外一种特征情况
一个样本的特征(黄色部分):系统发电功率前24个值;样本对应的标签(蓝色部分):第25个点的系统发电功率。
LSTM模型:测试集预测值和真实值
对项目感兴趣的,可以关注最后一行
import tensorflow as tf
print("TensorFlow版本:", tf.__version__)
import numpy as np
import pandas as pd
import datetime as dt
import plotly
import matplotlib
#数据集和代码:https://mbd.pub/o/bread/mbd-ZZealphy















 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











