







Graph CCA for Temporal SElf-supervised Learning for Label-efficient fMRI Analysis(GATE)(上)
摘要
在这项工作中,我们专注于具有挑战性的任务,神经疾病分类,使用功能磁共振成像(fMRI)。在基于人群图的疾病分析中,图卷积神经网络(GCNs)取得了显著的成功。然而,这些成就与丰富的标记数据和对虚假信号的敏感是分不开的。为了改善标签有效设置下的fMRI表征学习和分类,我们提出了一种新的理论驱动的GCNs自监督学习(SSL)框架,即用于fMRI分析的时间自监督学习(GATE)的图CCA。具体来说,这就要求设计一种适合的、有效的SSL策略来提取fMRI的形成特征和鲁棒特征。为此,我们从fMRI动态功能连接(FC)中研究了几种新的用于SSL训练的图增强策略。此外,我们利用经典相关分析(CCA)在不同的时间嵌入和提出理论含义。因此,这产生了一个新的两步GCN学习过程,包括:
-
对未标记的fMRI种群图进行SSL
-
对分类任务的小标记fMRI数据集进行微调。
我们的方法在两个独立的功能磁共振数据集上进行了测试,证明了在自闭症和痴呆症诊断方面的卓越表现。
1. 引言
由于功能磁共振成像(fMRI)衍生的脑功能连接(brain Functional Connectivity, FC)可以捕捉异常的脑功能活动[1],因此在疾病诊断中得到了广泛的应用。近年来,为了量化脑连通性随时间的变化,许多研究采用滑动窗口法从血氧水平依赖(BOLD)信号[2]中提取动态FC矩阵。FC表示将进一步通过机器学习方法用于疾病诊断。
随着深度学习的成功,深度学习方法在fMRI分类方面取得了突破,如卷积神经网络(CNNs)[3]、循环神经网络(RNNs)[4]、图卷积神经网络(GCNs)[5]等。事实上,GCNs被广泛用于疾病诊断[5],[6],因为所有学科的生物标志物对于识别与疾病相关的共同模式至关重要。已有研究探索了开发用于fMRI数据[3],[5],[7],[8]的各种预测任务的GCNs。例如,Parisot等人[5]应用VGCN对fMRI数据进行监督疾病预测。然而,这些研究在很大程度上依赖于大规模的标记/注释数据来获得有希望的结果。相反,这种情况通常不满足临床实践由于昂贵和复杂的注释过程。例如,自闭症样本的注释需要医生根据复杂的协议[9]对儿童的行为和发育历史(通常是几个月到几年)进行评分。
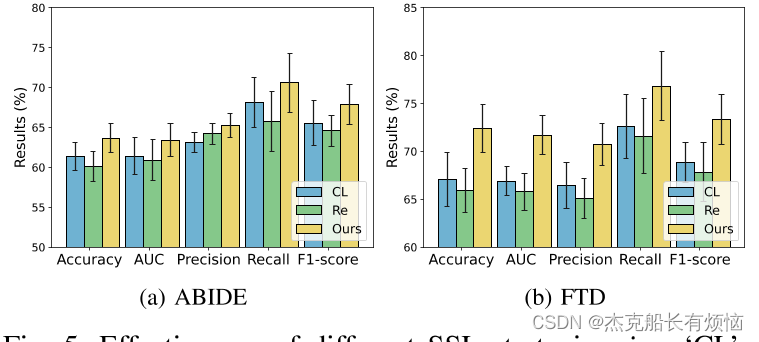
为了在标签高效数据[10] (即一小部分标签数据)上利用无标签数据和辅助表示学习,自我监督学习(SSL)已经成为无监督学习[11]的一种强大方法。为fMRI信号寻找合适的SSL策略是至关重要的,现有的SSL策略通常可以分为三类:基于对比的SSL、基于重构的SSL和基于相似性的SSL。基于对比的SSL[6],[12],[13]需要选择不同的阴性样本形成对比损失(如InforNCE损失[14]和triple损失[15]),由于样本数量有限,类别较少,fMRI难以进行疾病分类。基于重构的SSL[16],[17]包含一个编码器解码结构来重构输入,但由于拟合低信噪比fMRI特征可能会过拟合到伪特征[16],因此该方法并不实用。因此,我们重点研究基于相似性的SSL[18],[19],它强制相同数据(例如,数据及其增强)的多个视图的相似性,可以提供最佳的实用价值,以辅助无标记fMRI数据在图上的节点分类。
然而,基于相似性的SSL策略给基于GCN的功能磁共振分析带来了两个独特的挑战,这两个挑战目前尚未被探索:
挑战1:如何为fMRI分析找到合适的增强方法,从一个BOLD信号生成不同的视图?
增强应该减少伪特征和目标标签[20]之间的相关性。
挑战2:如何设计SSL训练在fMRI分析上的一致性损失?
要使相关信号之间的一致性最大化。典型相关分析(Canonical Correlation analysis, CCA)[21]是一种经典的多变量分析方法,被广泛应用于fMRI分析[22]中,其目的是最大化两种表征之间的相关性。
为了解决上述挑战,我们提出了fMRI分析的时间自监督学习图CCA (GATE),以实现有希望的结果,并帮助对未标记的fMRI数据进行预训练和对小标记数据进行微调(见图1)。具体而言,如图2所示,我们首先制定了一种fMRI分析的增强策略,从BOLD信号生成两个相关视图。这种增强策略的主要动机是,它使SSL能够从两种不同的观点捕获与疾病相关的关键信息。基于这两种不同的视图,我们通过GCN编码器获得它们的嵌入矩阵,提取主题之间的关联。此外,执行基于cca的目标函数,以最大限度地提高两个视图表示的相关性。这项工作的新颖之处和贡献可以概括如下:
•我们在fMRI数据上提出了一种新的SSL方法(GATE),这是一个有效和通用的框架来解决标签高效数据集上的学习问题。这可能会将基于gcn的方法从研究带到难以收集标签的临床应用。
•通过开发基于GCN的CCA正则化,并在BOLD信号上设计多视图时间增强策略,提出的GATE可以解决动态FC分析中的杂散因素。
•我们进行了理论讨论,以支持我们的动机,并证明了GATE是如何帮助标签高效数据学习的关键含义。
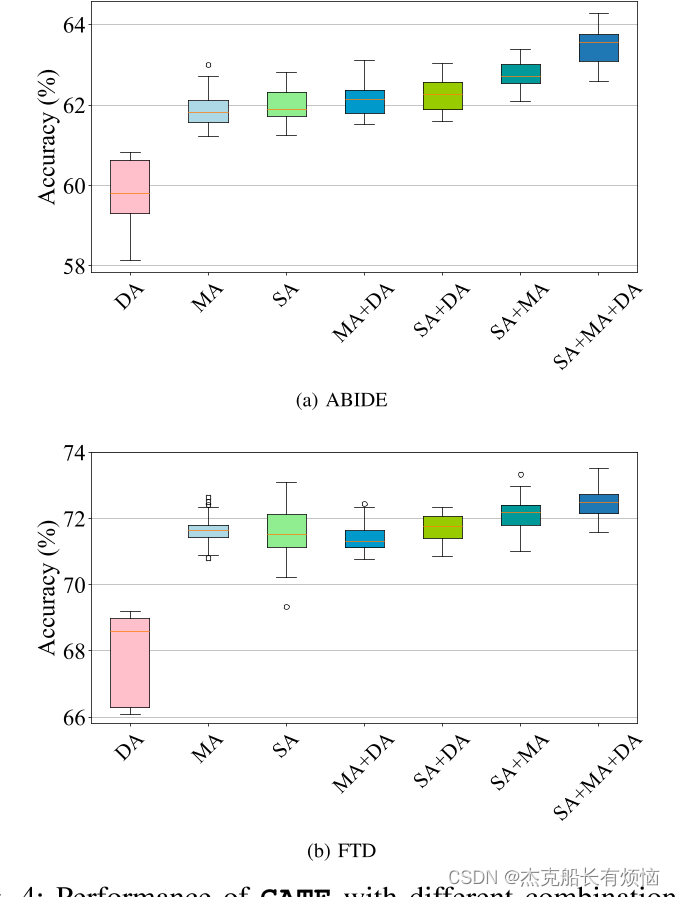
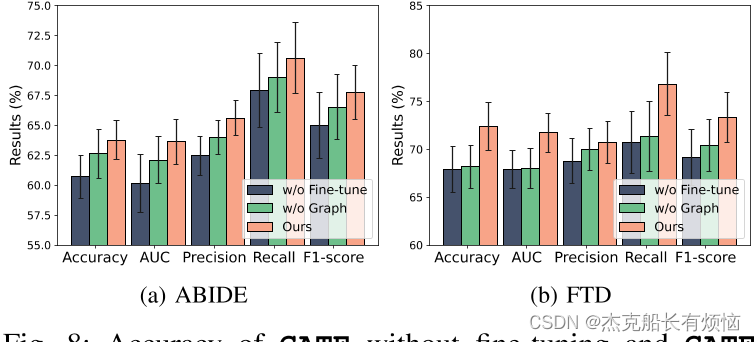
•综合比较实验表明,GATE在标签高效设置下实现了最先进的性能。我们还进行了广泛的消融实验,以讨论我们的设计和算法的关键组件。
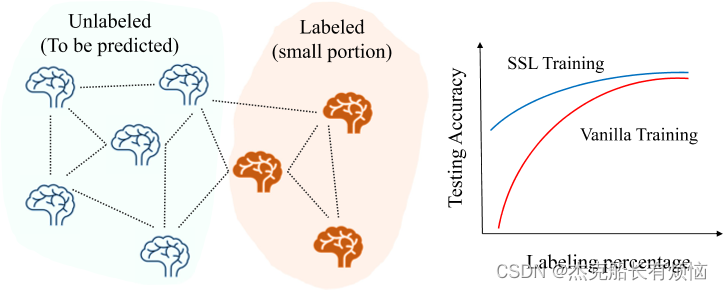
图1:这项工作的重点是利用自我监督学习(SSL)策略来改善有限标签(左)人口图上的fMRI预测性能,其中每个节点表示一个对象。实证研究(右,也见第五节)表明,当图表上标记了一小部分数据时,SSL比普通训练获得了更高的测试精度。
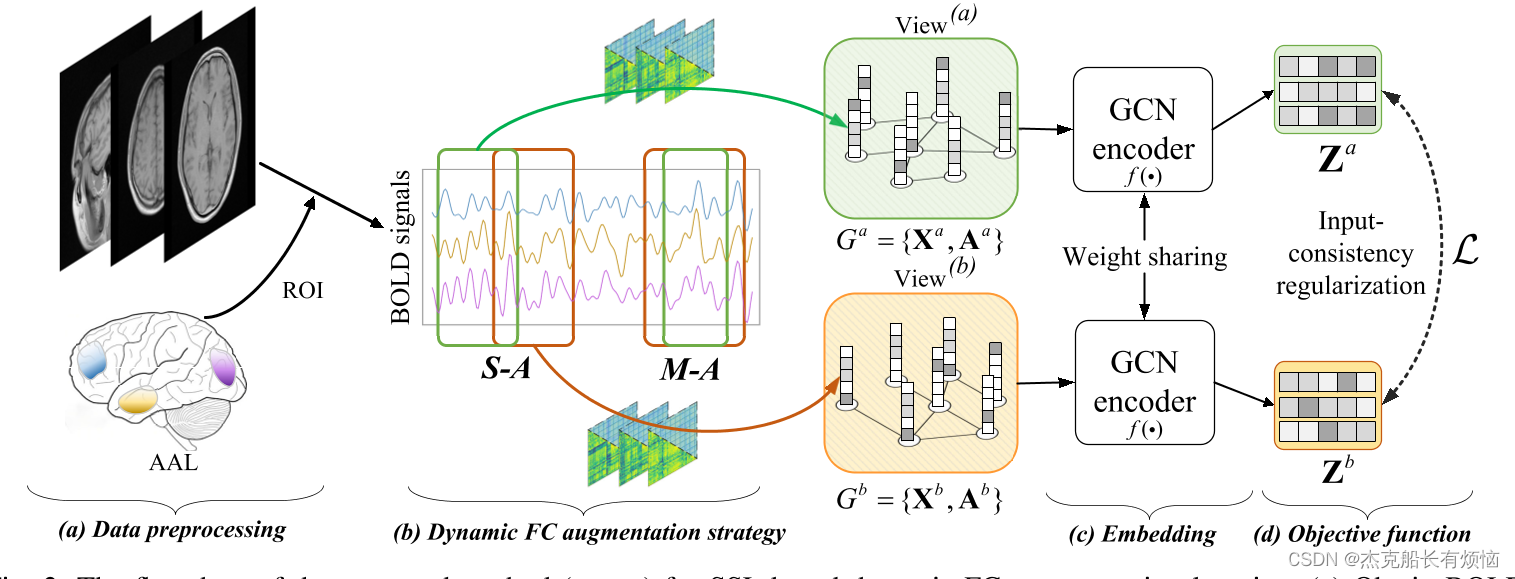
图2:提出的基于SSL的动态FC表示学习方法(GATE)流程图。(a)使用AAL模板对数据进行预处理,得到BOLD信号。(b)通过我们的增强策略(即S-A和M-A)从BOLD信号中随机生成两个视图 G a 和 G b G^a和G^b Ga和Gb。© GATE利用GCN编码器获得这两个视图的嵌入 Z a 和 Z b Z^a和Z^b Za和Zb。(d)通过优化基于CCA的损失(即式(2))来正则化嵌入的一致性。
2. 相关工作
A. Disease Prediction on fMRI data
计算机断层扫描(CT)、磁共振成像(MRI)、正电子发射断层扫描(PET)和x射线等医学成像技术已被用于疾病的诊断和早期发现。如Kam等利用多个卷积神经网络对早期轻度认知障碍[23]进行诊断。在神经科学中,MRI被广泛用于神经系统疾病的研究,根据检测到的连接类型,可以将其分为结构MRI和功能MRI。在结构MRI中,节点是由区域或脑组织之间的解剖连接来定义的,而边缘是由区域或脑组织之间的拓扑结构来构建的。例如,Yao等人提出了一种基于MRI结构数据[24]的三联体GNN模型,用于疾病诊断。在功能磁共振成像(fMRI)中,节点代表大脑的功能区域,而边缘是由它们的活动之间的相关性构建的。如Wang等人提出了相似度驱动的多视图模型,对fMRI数据[25]进行自闭症谱系疾病诊断。事实上,通过分析功能性功能性核磁共振成像(fMRI)来开发人类大脑的功能组织已经成为一种流行的方法,因为人类注意力的转移(例如,一个刺激或认知任务)与大脑功能区[26]、[27]活动的系统性变化有关。
越来越多的证据表明功能连接可能在短时间内发生动态变化[28]-[30]。已有研究表明,滑动窗口的使用有利于对fMRI数据进行动态连通性分析,因为静息状态反映了不同的生理状态,如徘徊、肌肉疲劳等。例如,Wang等人首先使用滑动窗口将rs-fMRI时间序列划分为多个分段,然后提出了时空卷积递归神经网络[31]。Yao等人提出了一种时间自适应图卷积网络来利用拓扑信息,并对整个时间序列信号[32]中的多层次语义信息建模。
B. GCNs for disease prediction on fMRI data
在过去的十年里,深度学习彻底改变了计算机辅助诊断[33]。在此基础上,深度GCNs利用节点之间的关系来寻找共同的模式/生物标记物,在神经科学[3]中对GCNs的关注越来越多。以往基于GCNs在fMRI数据的方法可以根据图中节点的定义分为两类:基于人口图的模型和基于脑区图的模型[8]。此外,这两个子组分别对应两个独立的fMRI分析任务,即基于人口图的节点分类任务模型和基于脑区图的图分类任务模型。
在基于人口图的模型中,图中的节点表示主体,边表示主体之间的相似性。例如,Parisot等人[5]利用GCN,将群体表示为一个稀疏图,其中节点与成像特征相关联,边缘权值由表型信息(如受试者的年龄、基因和性别)构建。Kazi等人[34]提出了一个在种群图上具有多个过滤核大小的GCN模型。
在基于大脑区域图的模型中,节点表示解剖的大脑区域,边缘表示这些大脑区域之间的功能或结构连接。例如,Li等[3]在脑区域图上进行了可解释的GCN模型,以了解哪些脑区域与特定的神经疾病相关。Xing等人[35]考虑在脑区域图上建立一种带有长时短时记忆模型的GCN模型用于疾病诊断。
虽然以往的GCN方法在人口图和脑区图上都取得了很好的结果,但现有的方法仍然受到大量标记数据的限制。显然,为有限的标记fMRI数据设计一种GCN方法是一个重要但尚未解决的挑战。
C. Self-supervised learning
SSL作为一种强大的无监督表示学习方法,近年来在图学习领域得到了发展。现有的SSL方法可以大致分为三种,即基于对比的SSL、基于重构的SSL和基于相似性的SSL。
基于对比的SSL方法通过手工构造正样本对和负样本对,增强了来自两个视图(例如,全局表示和本地表示)的表示之间的相似性。例如,Deep Graph Infomax (DGI)[36]采用了InforNCE[14]对比损失函数来对比局部节点表示和全局图表示。MVGRL[37]通过对比两个视图的局部嵌入和全局嵌入,提出了一种对比多视图表示学习方法。然而,基于对比的SSL方法依赖于负样本,不适合样本数量有限、类数量较少的情况。
基于重建的SSL方法通过进行基于重建的借口任务(如绘画中的图像和恢复颜色通道)来学习表示。例如,He等[16]开发了一种SSL编码器-解码器模型,从潜在表示和掩码补丁重建原始图像。Qiu等人[17]提出了一种基于表示相似性重构节点间关系的图编码器-解码器模型。然而,基于重构的SSL需要重构输入上下文(将低维特征转换为高维特征),这是不切实际的,因为拟合低信噪比的fMRI特征可能会导致对虚假特征的过拟合。
基于相似性的SSL利用了相同数据的多个视图(即输入上下文及其扩展)之间的耦合,从而在没有标记数据的情况下获得良好的表示。例如,Grill等人[18]通过两个不同的图形编码器编码两个增强视图来学习表示。虽然该技术避免了基于对比的SSL方法选择负样本的局限性和基于重建的SSL方法的重建损失,但设计一种适合fMRI数据生成多个耦合视图的策略是非常必要的。
3. 方法
如图2所示,我们概述了基于相似性的SSL方法。具体而言,拟议GATE的关键组成部分包括三个部分:(a) FC的动态增加(第三- a节);(b) GCN编码器(第三- b节);©目标函数(第三-C节),我们的方法采用标签有效设置下的两步训练过程,即步骤1:对未标记的fMRI数据进行无监督的预训练,步骤2:对一小部分标记数据进行微调,用于特定的预测任务。本节重点介绍第1步中使用的新型SSL策略,最后介绍第2步。
A. Multi-view fMRI dynamic functional connectivity generation
GATE的关键思想是确保输入内容的两个增强视图的一致性。具体地说,通过采用基于相似性的SSL,可以通过专门增加其变体来减少虚假因素。例如,如果我们训练一个模型来识别“苹果”,这两个视图可以是“红苹果”和“黄苹果”,因为两个视图都包含了“苹果”的主要特征(例如,形状)。为了构建用于fMRI分析[5]的种群图 G = { X , A } G = \{X, A\} G={X,A},其中 X X X代表受试者特征,A代表受试者相似性,我们通过构建FC作为节点特征提取时域fMRI BOLD信号,通过kNN从受试者特征和表型信息[5]构建A。
1. Dynamic functional connectivity
采用滑动窗口方法[2]将整个时间过程划分为多个子段,以捕获时间变异性。表示BOLD信号 S i ∈ R R × T S_i∈\R^{R×T} Si∈RR×T, R 为第 i R为第i R为第i个受试者的fMRI图像中大脑regionso - interests (ROIs)的数量, T T T为整个片段的长度。然后,我们通过计算配对ROIs中匹配的BOLD段之间的Pearson相关性[38]构造FC矩阵( F i ∈ R R × R F_i∈\R^{R×R} Fi∈RR×R)。最后,我们将FC矩阵的上三角形平化以表示第 i i i个受试者的fMRI特征 x i x_i xi(个人理解就是把矩阵的上三角展平变成一个向量,而这个向量就是fMRI特征 x i x_i xi)。
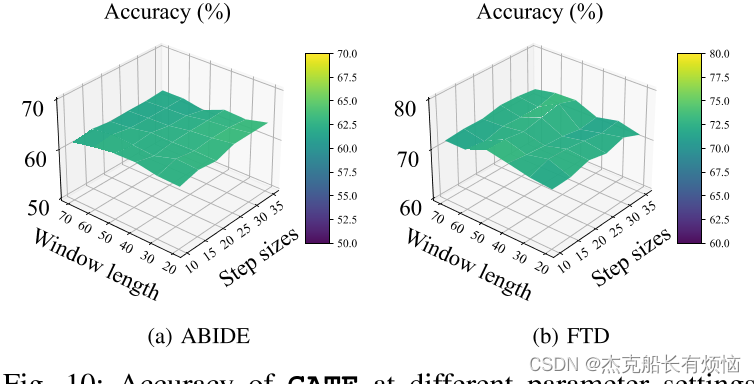
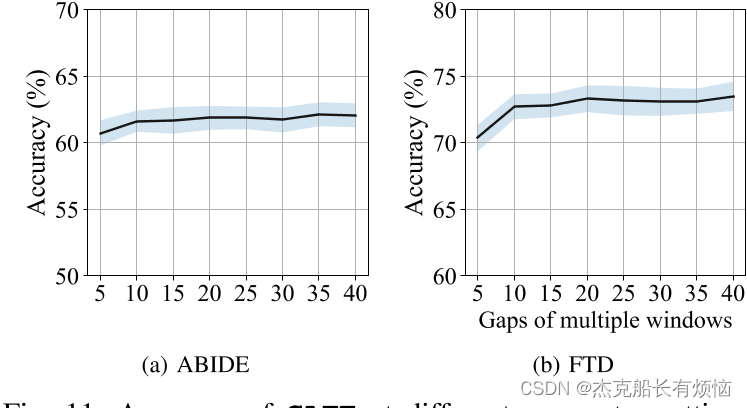
已有文献表明,基于动态FC的fMRI分析对滑动窗口大小L[39],[40]的选择是敏感的。因此,我们的目标是削弱扰动对 L L L的影响,即动态FC中的杂散特征。虽然大脑FC不是静态的,但短时间子段及其周围的时间子段应包含与神经系统疾病[28]、[41]相关的相同特征(如FC模式)。因此,我们建议通过滑动窗口对fMRI数据进行时域扩展,通过步进窗口增强(S-A)和多尺度窗口增强(M-A)获得两个相关视图( G a = X a , A a 和 G b = X b , A b G^a = {X^a, A^a}和G^b = {X^b, A^b} Ga=Xa,Aa和Gb=Xb,Ab)。
2. Step window augmentation (S-A)
如图2(A)所示, S − A S-A S−A将相邻的两个滑动窗口作为两个相关的视图( G A 和 G B G^A和G^B GA和GB)。在这种情况下,原始BOLD信号 S i S_i Si被分成M个子段 { S i 1 , … , S i M } \{S^1_i,…,S^M_i\} {Si1,…,SiM}对于第 i i i个对象,通过将窗口大小设置为 L L L,并将滑动窗口的步长设置为 s s s,得到 M = ⌊ T − L s ⌋ + 1 M=\lfloor \frac {T−L}{s}\rfloor+1 M=⌊sT−L⌋+1个子段和对应的动态FCs。在每次训练迭代中,S-A首先为第一视图 G A = { X m , A m } G^A=\{X^m,A^m\} GA={Xm,Am}随机选择一个子段(例如,第m个子段),然后将其相邻子段(例如,第 ( m ± 1 ) (m±1) (m±1)个子段)视为第二视图 G B = { X m ± 1 , A m ± 1 } G^B=\{X^{m±1},A^{m±1}\} GB={Xm±1,Am±1}。
3. Multi-scale window augmentation (M-A)
考虑到不同窗口大小产生的FCs包含了相关信息,M-A将两个不同尺度的滑动窗口作为两个相关的视图。在这种情况下,根据窗口大小L将 S i S_i Si划分为多个 M M M个子段。对于第 m m m个子段 ( m ∈ [ M ] ) (m∈[M]) (m∈[M]),我们使用两个不同的窗口大小 l a 和 l b l_a和l_b la和lb对BOLD信号进行采样以计算FCs,形成图 G a = X m , l a , A m , l a G^a={X^{m,l_a},A^{m,l_a}} Ga=Xm,la,Am,la和的两个视图。 G b = X m , l b , A m , l b G^b={X^{m,l_b},A^{m,l_b}} Gb=Xm,lb,Am,lb这两个视图送到GATE的每次训练迭代中,如图2(A)所示。
值得一提的是,还可以例如通过在每个训练迭代中随机选择一个来联合考虑S-A和M-A。此外,S-A和M-A也可以很容易地与随机落差扩大相结合(见SEC。V-C)。事实上,数据扩充在SSL中起着至关重要的作用,然而,并不是所有的数据扩充都对SSL有积极的影响[22]。因此,考虑到数据扩充在SSL中的重要作用,以及医学数据与自然数据相比的特殊属性和数据结构,研究一种适合于SSL的数据扩充具有重要的意义。与[48]相比,我们的方法直接对原始数据进行操作,而不是对图形表示。此外,我们提出的用于fMRI生成多视图数据的增强方法是一个通用的解决方案,可以与任何模型体系结构相结合。
B. Graph embedding
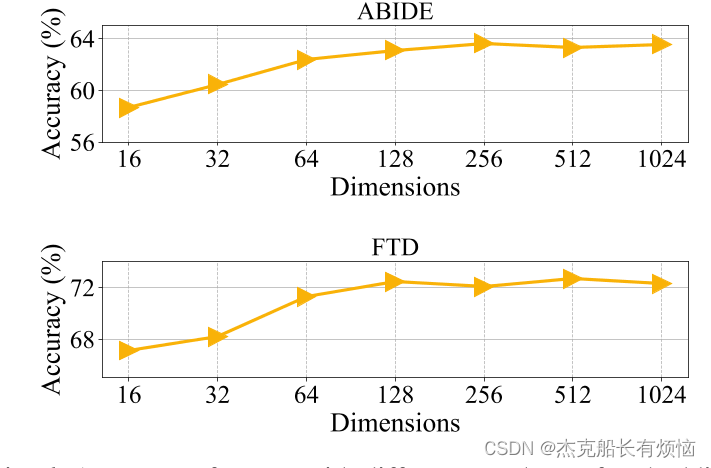
使用来自两个视图 ( G A = X a , A a 和 G b = X b , A b ) (G^A={X^a,A^a}和G^b={X^b,A^b}) (GA=Xa,Aa和Gb=Xb,Ab)的图形数据,我们执行编码器来学习数据的模式。由于GCN[49]及其变体已被广泛用于捕捉图形数据中的语义信息(即X)和结构信息(即A),在本研究中,我们采用GCN模型作为编码器 f ( ⋅ ) f(·) f(⋅),以获得所有主题在每个视图中的嵌入。值得注意的是,图编码器 f ( ⋅ ) f(·) f(⋅)对于应用其他功能强大的图学习编码器(例如,GAT[50]和GIN[51])是通用的。为了便于比较和应用,我们采用了常用的GCN模型作为本研究的编码。更具体地说,第 l l l个隐藏层上的GCN操作被定义为:
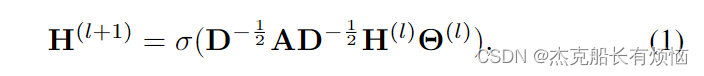
其中D为A的对角矩阵, H ( l ) H^{(l)} H(l)为所有被试在第 l l l层的输出特征, Θ ( l ) Θ^{(l)} Θ(l)为训练的权值矩阵,σ(·)表示一个激活函数。式(1)的输入特征为特征向量fMRI特征(即通过S-A或M-A得到的 X X X)。为了使嵌入具有可比性,我们使用相同的GCN编码器(权重共享)将两个视图投影到相同的嵌入空间。由此,我们得到两个视图的归一化嵌入矩阵,即 Z a = f ( X a , A a ) 和 Z b = f ( X b , A b ) Z^a =f(X^a, A^a)和Z^b =f(X^b, A^b) Za=f(Xa,Aa)和Zb=f(Xb,Ab)。
C. Objective function
为了优化模型,基于对比的SSL方法[41]、[42]分别对正对和负对进行对比损失,这在样本数量有限、类数较少的情况下并不适用。基于重建的SSL方法[16]采用重建损失(即MSE)来重建输入上下文,这是不切实际的,因为拟合低信噪比的fMRI特征可能会导致对虚假特征的过拟合。因此,我们提出GATE来避免采样负样本或重建fMRI时间序列。相反,我们设计了新的增强方法和相应的相似度损失来利用未标记数据,同时防止特征在嵌入空间中的崩溃。一旦计算了两个视图的嵌入矩阵,下一步就是最大化这两个嵌入矩阵的相关性,正如CCA所做的(见第IV节)。此外,我们定义输入一致性正则化损失为:
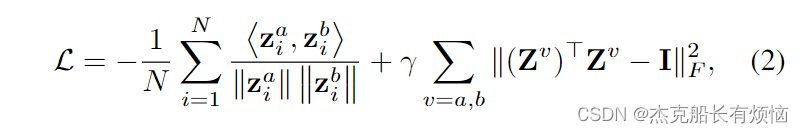
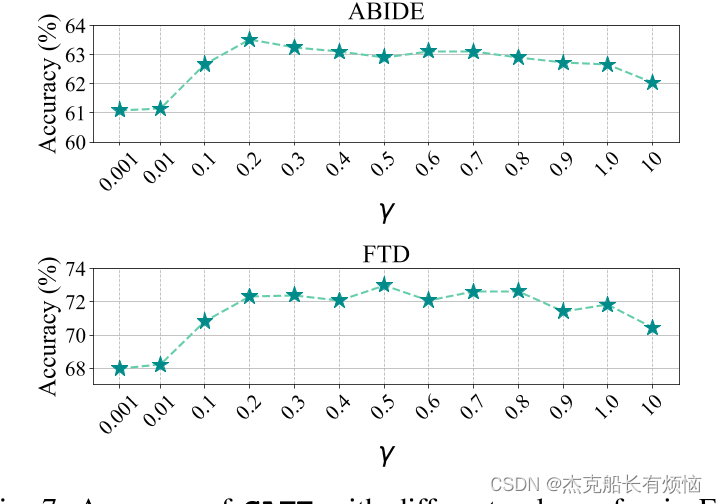
式中 < ⋅ , ⋅ > <·,·> <⋅,⋅>为点积算子, γ γ γ为权衡系数。 v v v是视图之一(例如视图a和视图b), Z v Z^v Zv是这个视图的嵌入矩阵。在式(2)中,第一项可以看作是对嵌入特征的正则化,保证了低维特征能够保持表示能力。式(2)中的第二项保证特征的各个维度是不相关的,以避免出现不合常理的解,即模型的所有输出都是相等的。
1. Performing downstream task
在对GCN编码器进行训练后,由于许多GNN编码器(如GCN和GAT)属于转导学习,因此在临床实践中不需要保持大的图结构的微调步骤,这意味着需要在涉及新样本后重建A。因此,我们在没有图形信息的情况下对编码器进行了微调(即,通过用单位矩阵 I 替换 A I替换A I替换A),然后在一小部分标记数据上使用交叉熵损失对特定临床预测任务使用ELU激活函数的线性层(表示为 ψ ( ⋅ ) : Z ↦ R ψ(·):Z\mapsto\R ψ(⋅):Z↦R)。在推理过程中,所有滑动窗口都输入到模型中。为此,我们给出了GATE的伪码。

4. THEORETICAL MOTIVATION AND ANALYSIS ON CCA LOSS
如果机器学习模型依赖于伪特征来进行决策,那么它可能无法很好地概括测试数据。加入输入一致性正则化可以减轻伪特征与标签之间的相关性,提高测试性能[23],[52]。CCA用于匹配两种表示的相似性,已被广泛用于多视图融合和fMRI分析[53],而在SSL中利用CCA还有待探索。虽然[48]使用CCA作为规则,但它只是隐式地将视图增强与信息瓶颈[54]连接起来。在这里,我们通过建立基于深度学习的非线性CCA和SSL之间的联系来改进理论分析。此外,我们暗示它们将如何影响下游任务。深度CCA的总体目标表示为
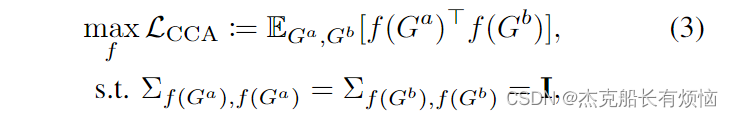
其中 f f f为归一化的非线性嵌入: G ↦ Z G\mapsto Z G↦Z和 f ← f ‖ f ‖ 2 f←\frac {f}{‖f‖_2} f←‖f‖2f 其中两个视图 G a 和 G b G^a和G^b Ga和Gb, Σ 为 Σ f , f = E G a [ f ( G a ) f ( G a ) ] Σ为Σ_{f,f} = \mathbb E_{G^a} [f(G^a)f(G^a)] Σ为Σf,f=EGa[f(Ga)f(Ga)]的协方差矩阵。在这里,我们陈述了输入一致SSL调节和非线性CCA优化之间的可识别性。
定理1(CCA loss)::
考虑到Eq.(2)和Eq.(3)的优化,Eq.(2)是Eq.(3)的拉格朗日形式的对偶问题,满足KKT条件[55]。
然后,我们建立CCA正则化与下游任务泛化误差边界之间的联系。设变量 G a 和 G b G^a和G^b Ga和Gb为一个数据的两种视图,即 G a G^a Ga为一个样本, G b G^b Gb为其变体。表示表示操作 T \mathcal T T,低秩近似算子 R R R和 h : x ↦ R h:x\mapsto \R h:x↦R。对 T \mathcal T T进行SVD:找到k个标准正交向量 U = [ u 1 , … , u k ] , V = [ v 1 , … , v k ] U = [u_1,…,u_k], V = [v_1,…,v_k] U=[u1,…,uk],V=[v1,…,vk],标量 s = σ 1 , … , σ k ∈ R s = σ_1,…,σ_k∈\R s=σ1,…,σk∈R,使:
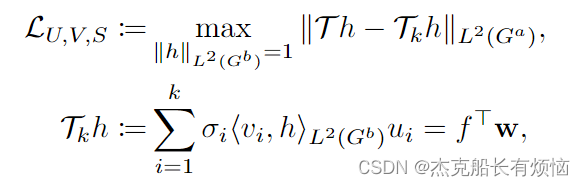
其中 w = < v i , h > w=<v_i,h> w=<vi,h>。我们将非线性CCA关于近似误差的一般定理表述如下:
引理2(General theorem for non-linear CCA [56]):
设 f f f是Eq(3)的解, h ∗ h^* h∗是预测 Y Y Y的最优函数, y y y是标签 Y Y Y的单热编码器。 σ i : = E G a , G b [ f i ( G a ) f i ( G b ) ] σ_i:= \mathbb E_{G^a,G^b}[f_i(G^a)f_i(G^b)] σi:=EGa,Gb[fi(Ga)fi(Gb)]。近似误差满足
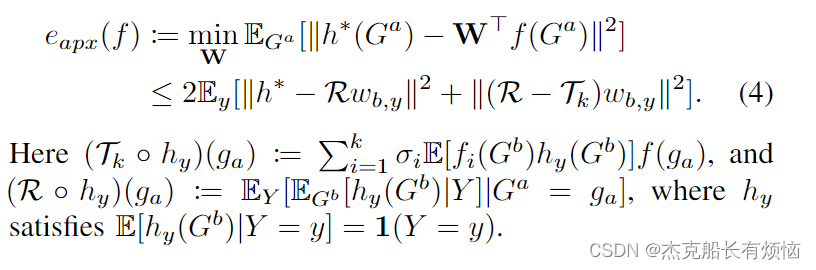
定理3(Upper bound of excess risk of downstream task):
设 G a 和 G b G^a和G^b Ga和Gb为同一个训练实例随机生成的两个视图, Y Y Y为实例标签。考虑通过最小化Eq. (2) f ∗ : = a r g m i n L f^∗:= argmin L f∗:=argminL来学习嵌入并使用 f ( ⋅ ) 对 Y f(·)对Y f(⋅)对Y进行下游线性模型,即 h ( G ) : = ( W ∗ ) T > f ( G ) , W ∗ ← a r g m i n W E G , Y [ ‖ Y − W T > f ( G ) ‖ 2 ] h(G):= (W^∗)^T>f(G), W^∗←argmin_W\mathbb E_{G,Y}[‖Y−W^T>f (G)‖^2] h(G):=(W∗)T>f(G),W∗←argminWEG,Y[‖Y−WT>f(G)‖2],用于分析简单性 W ∈ R k × k 。设 Y = h ∗ ( G ) + N W∈R^{k×k}。设Y = h^∗(G) + N W∈Rk×k。设Y=h∗(G)+N,其中N为 σ 2 σ^2 σ2-亚高斯, E [ N ] = 0 \mathbb E[N] = 0 E[N]=0。如果多视图条件独立假设成立,概率至少为 1 − δ 1- δ 1−δ,我们有额外风险:
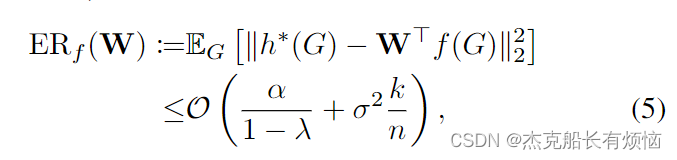
其中 n n n是下游任务中标记样本的数量, k 是 Y k是Y k是Y中的类的数量, α α α是贝叶斯误差, λ λ λ是表示操作 t t t的第 k k k个奇异值。在我们的上下文SSL ( T h ) : = E [ ( h y ( G b ) > f ( G b ) ∣ f ( G a ) ] (Th):=\mathbb E[(h_y (G^b)>f (G^b)|f (G^a)] (Th):=E[(hy(Gb)>f(Gb)∣f(Ga)]。
证明4:
设变量 G a 和 G b G^a和G^b Ga和Gb为一个数据的两个视图,即, G a G^a Ga为一个样本, G b G^b Gb为其变体。令函数 w i , y ( G a ) = 1 ( h ∗ ( G a ) = y ) w_{i,y}(G^a) =1(h^*(G^a)=y) wi,y(Ga)=1(h∗(Ga)=y)对于 i ∈ { a , b } i∈\{a, b\} i∈{a,b}。在条件独立性条件下, T = R , G a 和 G b T = R, G^a和G^b T=R,Ga和Gb的(k−1)第一个最大相关是 T T T[57]的第 k k k个奇异值。我们有
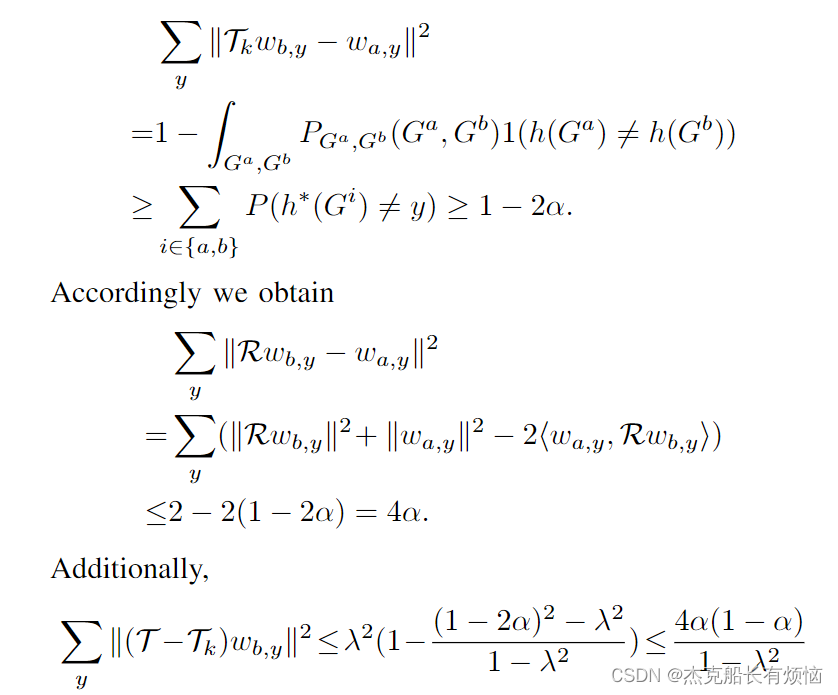
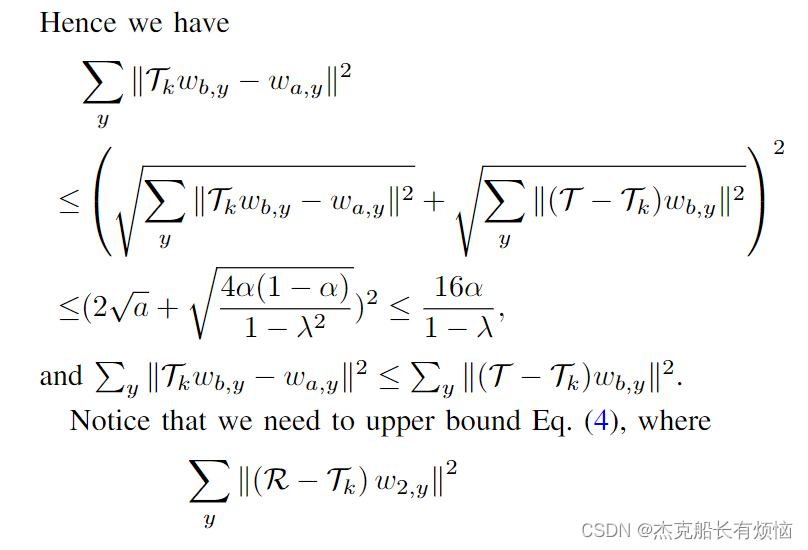

因此我们可以很容易地得出定理3成立的结论
备注5:
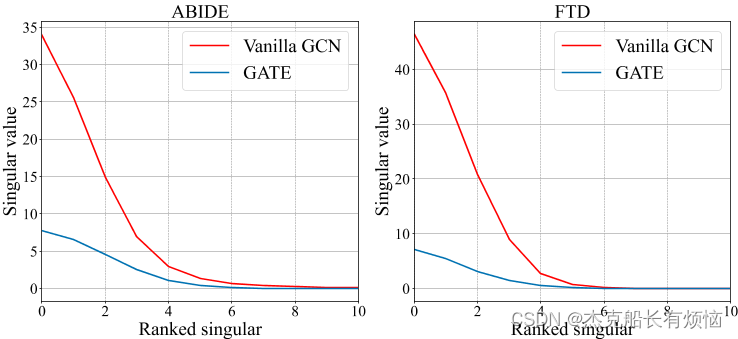
注意,根据定理3提供的边界,下游任务中标记样本n的数量越大, λ λ λ的值越小,超额风险越低。 λ λ λ的小值可以通过 T T T的低秩表示来实现,例如,通过优化Eq.(3)[56]。
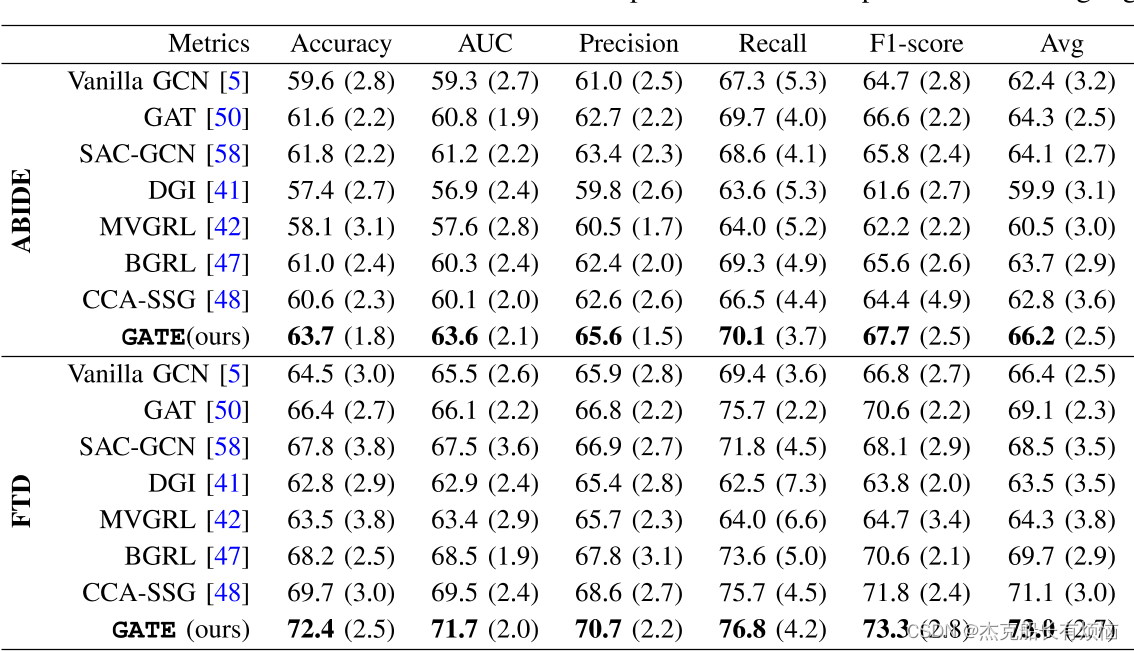
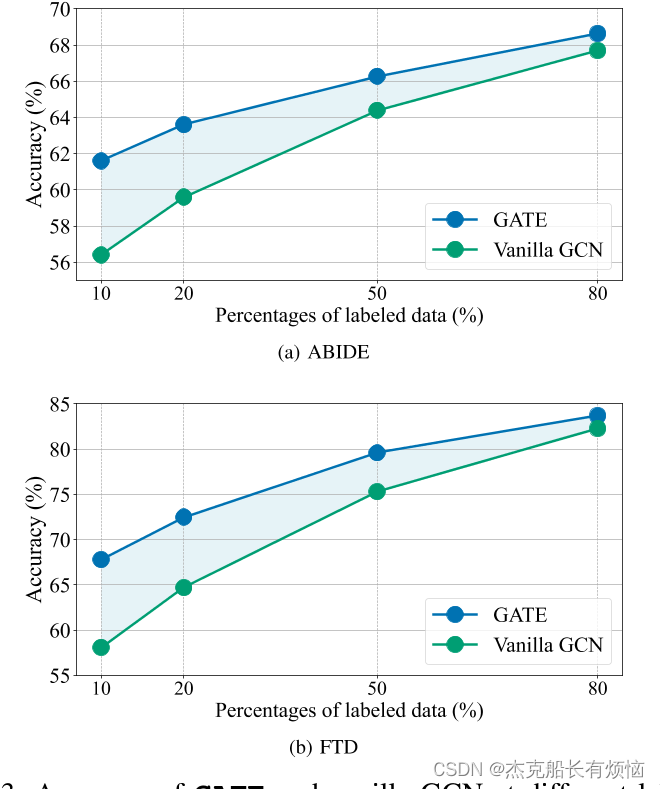
5. 实验















 1473
1473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









