








论文:A Siamese CNN for Image Steganalysis
源码:https://github.com/SiaStg/SiaStegNet
Siamese网络:
参考链接:https://blog.csdn.net/ybdesire/article/details/84072339
背景
人脸识别中的one-shot问题:公司员工进行人脸识别,每个员工只给一张照片(训练集样本少),并且员工会离职、入职(每次变动都要重新训练模型)。有这样的问题存在,就没办法直接训练模型来解决这样的分类问题(是不是同一个人)。
为了解决one-shot问题,训练一个模型来输出给定两张图像的相似度,模型学习得到的是similarity函数。Siamese网络(模型)能通过学习得到similarity函数。
Siamese网络原理
给出两个图像X1和X2的相似度,输出一个向量(比如一维向量)。
- 若两张图为同一个人,两个模型输出的一维向量的欧式距离较小,否则较大
Siamese网络训练
代价函数:

A是某人,P是某人的另一张图,N是其他的人。
遍历所有三元组(A,P,N),求其L的最小。公式中的参数α,是一个超参数,用于做margin,能避免模型输出的都是零向量。
用梯度下降法找到模型最优值。
SRM滤波器
https://blog.csdn.net/c_chuxin/article/details/103981255
SRM指是《 Rich models for steganalysis of digital images》中提出来的,富隐写分析模型,34671维。论文中使用下面3个滤波器获得噪声图片:

论文整理
假设:自然图像不同子区域的噪声是相似的,但隐写图像对不同子区域进行修改,造成子区域噪声不再相同。
现有工作:
常见隐写方法:
自适应隐写(最实用):结合编码(STC)
基于深度学习的:综合型(GAN);生成修改概率图;欺骗CNN隐写分析器;3-player对抗。
现有CNN隐写分析方法局限性:无法直接对大图像进行训练。
目的:针对任意大小图像进行隐写分析。
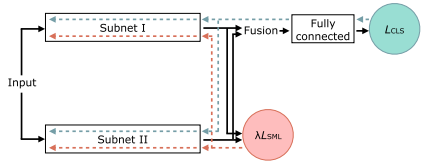
提出方法

把原始图像分成左右两部分,分别进行预处理、特征提取,得到两个信号,一个是分类/融合信号,用于判断是否为隐写图像,一个是相似度信号。
分类/融合信号:四个非线性矩阵:最大值,最小值,均值,方差。
方差和最大-最小的值在自然图像中更小,最大和最小值更接近均值
代价函数:
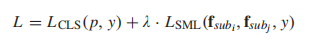
论文中λ设为0.1,对比损失的m设为1,训练500epoch,15h
预处理:用5*5 的SRM kernels 进行卷积
特征提取:残差连接?最后获得一个128维的向量
实验结果:

代码运行bug:
undefined symbol: PySlice_Unpack(使用conda install python==3.6)版本不兼容no module named cv2(使用pip install opencv-python)AttributeError: module 'torch._C' has no attribute '_cuda_setDevice'
(在python命令后面加上 --gpu_ids -1)
参考https://blog.csdn.net/weixin_39450145/article/details/104797786os.makedirs(args.ckpt_dir, exist_ok=False)
报错:FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: ‘…’
把False改成True
能够成功运行,用MATLAB的WOW加密1000个图片(训练集:交叉验证:测试集=6:1:3),0.2bpp,训练迭代100次后正确率并不理想。(原因是数据量太小了,使用论文中的数据集准确率就能上升)

















 9412
9412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











