









接上文,
通过将DRL插入到CNN中,我们提出了用于3D物体识别的DRCNN算法。而且,每个3D物体视图的特征都是被同一个CNN1提取出来的。然后这些特征点通过提出的DRL形成新的特征从而代表3D物体。然后,作为输入,新的特征传播到CNN2中生成相应的形状描述符来完成分类或检索工作。
论文第三部分C部分,讲述MVCNN中的视图层和DRCNN中DRL的关系 作者一上来先说,经过研究发现,MVCNN中的视图池化层是DRL的一种特例。在MVCNN中,视图池化层通过视图用元素级的最大化来进行操作。通过CNN1,我们得到了m个视图对应的m个特征图。相比于同样位置的m个特征图的值,(MVCNN中视图池化层)将最大值作为新特征。和视图池化层相比,我们的DRL主要由四部分组成。当这四个部分相互协调时,DRL就退化为了视图池化层。具体来说,对于每一组,假定高层级胶囊的数量是1,它的维度是H*W。通过下面的式子:
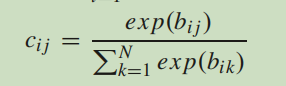
我们得到耦合系数都是1。然后我们设置一个特殊的系数矩阵,如图:
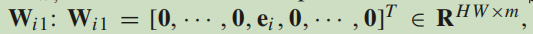
ei是Wi1的第i行,且定义如下:
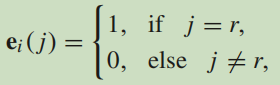
ei(j)是ei中第j个元素的值,r是输出中第i个最初胶囊ui中最大值的位置。以此类推,我们将同样的操作放在每组上,动态路径层就变成了MVCNN中的视图池化层。然而,系数矩阵Wij是通过BP算法得到的,耦合系数是由修改后的动态路径规划算法决定的。也就是说,通过BP,仿射变换可以将视图中的特征转换为转换后的特征。然后,修改后的动态路径规划算法对于每个样品动态的选择转换后的特征。基于以上两点,我们提出的DRL比起MVCNN中的视图池化层可以使用更多视图中的信息。
论文第三部分D部分,简述怎么做到分类和检索的功能 在分类任务中,当给了C个类别,DRCNN最后一层的输出就是一个向量有C个元素。每个元素的值代表了这个物体属于这个种类的可能性。哪个种类的值最大就代表模型预测这个物体应该属于这个种类。
在3D形状检索任务中,假定有一个搜索请求X,目标物体是Y,它们的描述符为x、y。目标物体的描述符来自于DRCNN中倒数第二层的特征,这些特征已经集聚了多视图图像的信息。请求物体的描述符同样也是通过DRCNN获取的,如果是2D的则通过CNN获取。然后通过计算两个描述符的欧式距离去检索。通过计算出的所有的欧式距离,我们可以将其排序,然后给出检索结果。
实验
论文第四部分前言,作者说了这部分要测DRCNN在识别和检索方面的能力。识别方面,实验在ModelNet10和ModelNet40的数据集上进行,并研究了参数对结果的影响。在检索方面,证明了DRCNN在SHREC’14和ModelNet40的数据集上的潜在优势。
论文第四部分A部分,3D形状识别 作者一上来先说自己用的数据集的详细情况,这里就不细翻了。总之用的是论文23中的数据集ModelNet10和ModelNet40。后面就开始介绍数据集有多少图片怎么样怎么样的,这里不赘述,感兴趣的可以看原文。后面作者说为了评估3D形状识别的性能,他们用了平均实例准确率和平均分类准确率。平均实例准确率就是在所有被测样本中正确辨识到特定样本的概率。平均分类准确率就是在所有类别中正确分到所属类别的概率。
对于网络核心,作者采用了论文28中VGG-M和论文29中ResNet50去评判在ImageNet预先训练过的模型的效率。和原MVCNN相似,作者把DRL放在了VGG-M的第五层或者ResNet50的倒数第二层。而且,修改后的路径规划算法的迭代次数大多数时候是1。所以模型都用论文30中提出的Adam optimizer训练。视图的数量在实验中通常设为12,如果没有特别要求的话。学习率被设置为1e-5,在识别任务中还用了交叉熵损失。至于仿射变换中变换矩阵的大小,VGG-M中用的是12×36,ResNet50中用的是12×1。
下来作者说了自己的实验和哪些其他的前沿模型作比较,这里就不再赘述了,详细见表。

下来作者又对视图的数量这个参数进行了实验,具体结果见表:

下来作者又对迭代次数这个参数进行了实验,具体结果见表:

下来作者说了对动态路径规划算法修改的影响,一上来就说融入修改后的动态路径规划算法的DRCNN可以在多视图方面更好的混合利用。下来就是说实验结果,在VGG-M基础上进行实验,结果原算法的实例准确率在ModelNet40上只有4.05%,在ModelNet10上只有11.01%。这意味着原算法不能很好的混合多视图的特征。然后就说自己的算法不仅仅在结果上比原算法好,时间效率上也比原算法好,几乎效率是原算法的两倍。
下来作者又对训练层数这个参数进行了实验,具体结果见表:

其中MVCNN+是和DRCNN有一样训练层数的神经网络。加的两层位于视图池化层之前,且加的两层和DRL有一样多的参数。
下来作者又对高层级胶囊的链接方式进行了实验。在作者提出的DRL中,他们修改了动态路径规划算法去获得高层级胶囊的特征。当高层级胶囊的数量大于1时,他们用预先通过ImageNet数据集训练好的系数矩阵在求和池化中将这些高层级胶囊融合。作者不仅做了求和池化,还做了平均池化和最大池化,实验结果如下:

下来作者对高层级胶囊数量这个参数进行了实验,结果如下:

下来作者对重排步骤中组的规模这个参数进行了实验,结果如下:

这部分每个小部分作者基本都是在阐述实验结果,所以这里就没再译,直接放的实验结果。基本都是说根据实验结果什么时候最高什么时候最好,然后对这个实验结果进行一个猜想性的解释。















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









