







目录
drop_duplications():去除重复id/去除同类项
strip():去除空格(lstrip():去左空格;rstrip():去右空格)
contains(): 判断是否包含尾缀/前缀/数字/...
pandas工具包:把numpy中很多命令整合在了一起。
一、Pandas工具包使用
df:DataFrame (矩阵。行:样本;列:特征)
 .head():可以读取前几条数据,指定前几条都可以(默认前五条)
.head():可以读取前几条数据,指定前几条都可以(默认前五条)
.tail():同.head(),可以读取后几条数据。
 帮助文档:
帮助文档:

二、数据信息读取与展示
.info:返回当前的信息

.index: 索引
 .coulums :列名。每列第一个是列名,后面是数据。
.coulums :列名。每列第一个是列名,后面是数据。

.types:数据类型

.value :打印列名,结构是数组格式。

创建dataframe结构
- 指定一个字典结构,key:当前列名;value:对应key的值,是list结构。
注:格式对应起来。空值:np.nan

取指定的数据:
series:dataframe中的一行/列


索引我们可以自己指定
未指定前:
 指定后:
指定后:
 通过名字定位:
通过名字定位:

.describe():可以得到数据的基本统计特性 (只有数值数据计算得到的结果。包括计数、均值、方差等)

三、索引方法
Pandas索引结构
- loc 用label来去定位
可以定位人名、非位置的时候使用loc。传入的是描述。
- iloc 用position来去定位
传入的是值。
bool类型的索引
用ture或这false来取数

定位到ture的值

找到男性:
 性别为男性的平均年龄:
性别为男性的平均年龄:

四、groupby函数使用方法
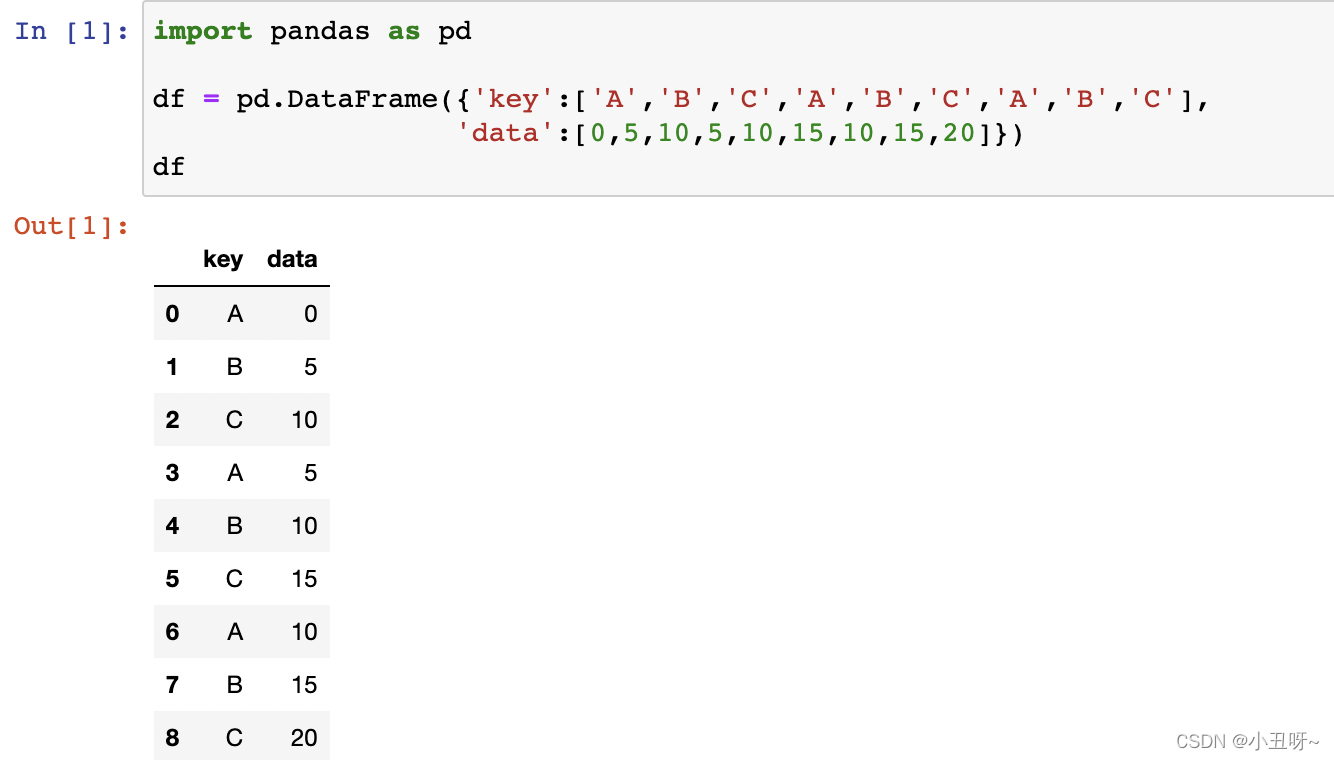
eg:找到所有A的data之和
python

groupby

取均值

groupby:统计数据
- 统计数据文件中男女的平均年龄

- 统计数据文件中不同性别获救的可能性

五、数值运算
与numpy中本质上没有区别。

求和



平均数

最大最小值

二元统计

协方差

相关系数(对角阵,对角线是1)

value_counts(): 统计数有多少个
(升序:ascending=true;降序:ascending=false)


bins:划分情况

六、对象操作
Series结构的增删改查(Series:一列数据)

查操作:

改操作(.copy防止改错了)

增操作

删操作

DataFrame结构的增删改查

查操作是类似的

改操作
 增操作
增操作

删操作

七、merge合并操作



合并:
 默认情况下,会把合并两个表中共有的传入。
默认情况下,会把合并两个表中共有的传入。
 为了不丢失数据,(how='outer' :显示所有;how=‘left’:显示左表;how=‘right’:显示右表)
为了不丢失数据,(how='outer' :显示所有;how=‘left’:显示左表;how=‘right’:显示右表)
 八、pivot数据透视表
八、pivot数据透视表
显示设置
pandas API文档:pandas.set_option — pandas 1.4.1 documentation
美观展示


精度设置:(默认取6位)

pivot操作
设置一个数据透视表

每一项花费在每个月的平均是多少,使用pivot(index:想统计的指标;columns:想通知指标的属性;values:按着什么方式统计)
 求和:
求和:
 统计不同性别在不同船舱等级上的花费
统计不同性别在不同船舱等级上的花费
 求最大:
求最大:
把年龄小于18的赋值给Underaged

九、时间操作

.to_datetime():转换成时间的标准格式

Series():构建时间序列:
 通过时间指出当前数据:
通过时间指出当前数据:
 取月份:
取月份:

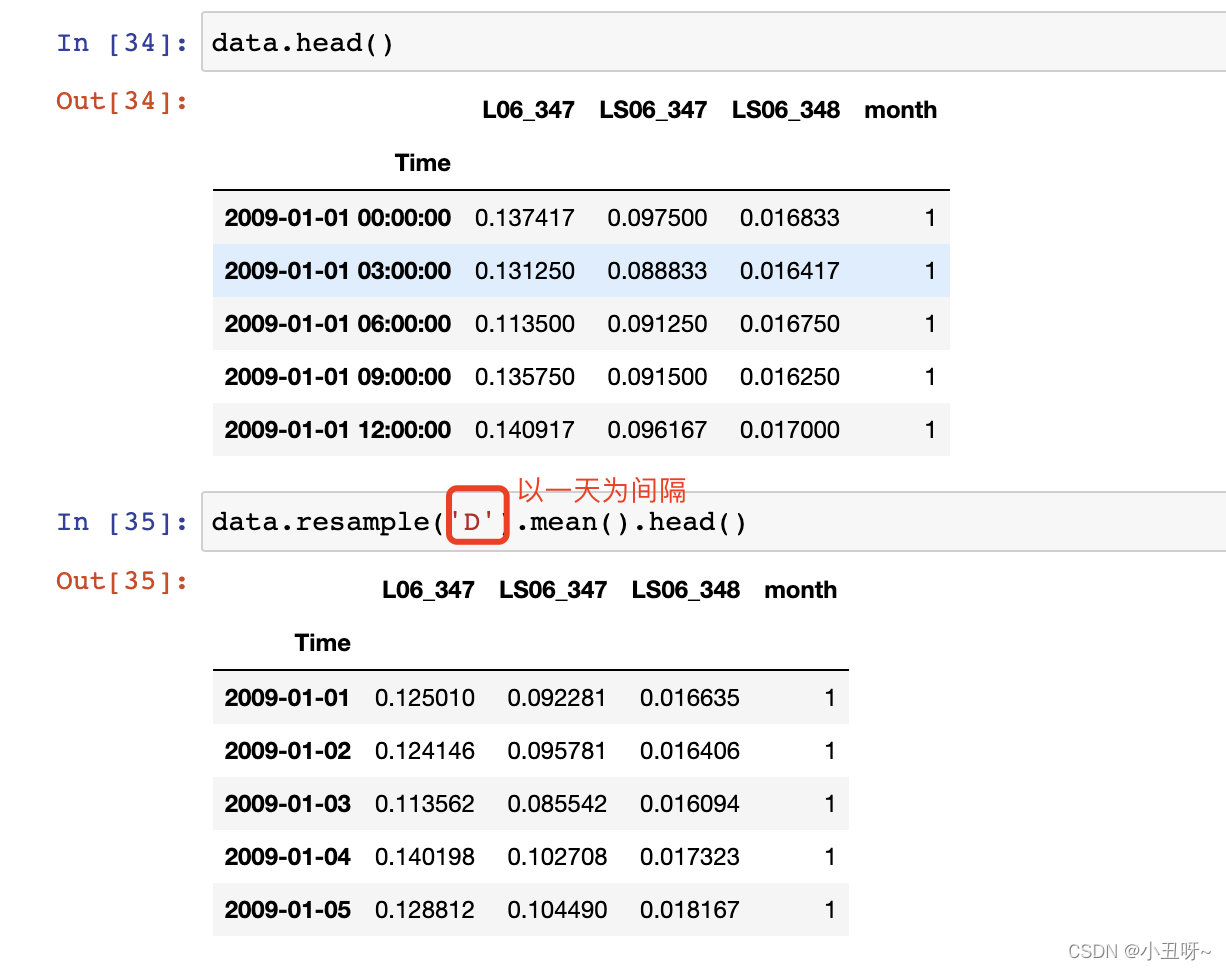
resample:时间重采样
画图操作

十、apply自定义函数
自定义apply()函数
优点:可以自己指定当前对那哪个样本执行什么操作。

统计每一列的缺失值:

统计不同的船舱等级

判断年龄

十一、常规操作
 sort_values(): 排序
sort_values(): 排序

sort_values(by=‘’) :按照哪个列进行排序

drop_duplications():去除重复id/去除同类项

replace:替换操作

cut:自定义取数据(对连续值进行离散化)


cut属性值替换

.isnull():空值判断

.fillna():缺值填充(将所有缺失值填充为5)

定位到缺失值,带有缺失值的样本

十二、字符串操作

lower():小写转换

upper():大写转换

len():计算字符的长度

strip():去除空格(lstrip():去左空格;rstrip():去右空格)

replace():替换/字符数据的预处理

split():切分

contains(): 判断是否包含尾缀/前缀/数字/...

get_dummies(): 经常在关联分析时使用















 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









