







1 强化学习的概述
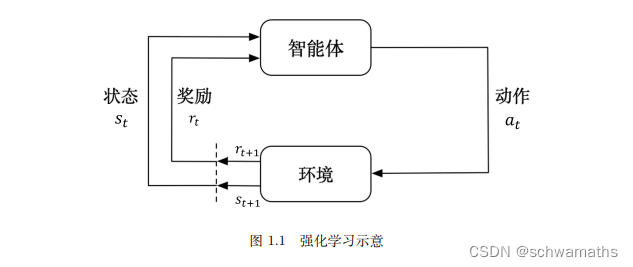
**强化学习(reinforcement learning,RL)**讨论的问题是智能体(agent)怎么在复杂、不确定的环境(environment)里面去最大化它能获得的奖励。如图 1.1 所示,强化学习由两部分组成:智能体和环境。在强化学习过程中,智能体与环境一直在交互。智能体在环境里面获取某个状态后,它会利用该状态输出一个动作(action),这个动作也称为决策(decision)。然后这个动作会在环境之中被执行,环境会根据智能体采取的动作,输出下一个状态以及当前这个动作带来的奖励。智能体的目的就是尽可能多地从环境中获取奖励。
2序列决策
当智能体能够观察到环境的所有状态,这个环境是完全可观测(fully observed)。在这种情况下面,强化学习通常被建模成一个马尔可夫决策过程(Markov decision process,MDP)的问题。
当智能体只能看到部分的观测,这个环境是部分可观测的(partially observed)。强化学习通常被建模成部分可观测马尔可夫决策过程(partially observable Markov decision process, POMDP)的问题。
3 动作空间
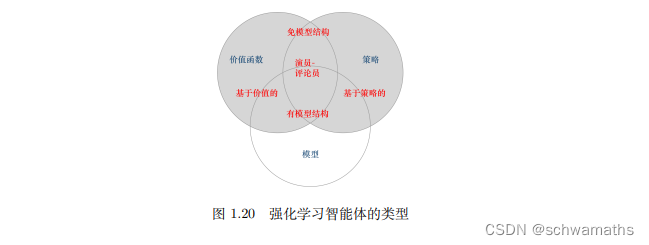
4 强化学习智能体的类型
4.1学习的准则
基于价值的智能体(value-based agent:显式地学习价值函数,隐式地学习它的策略。策略是其从学到的价值函数里面推算出来的。
基于策略的智能体(policy-based agent):直接学习策略,我们给它一个状态,它就会输出对应动作的概率。基于策略的智能体并没有学习价值函数。
演员-评论员智能体(actor-critic agent):这一类智能体把策略和价值函数都学习了,然后通过两者的交互得到最佳的动作。
基于价值的强化学习算法有 Q 学习(Q-learning)、Sarsa
等,而基于策略的强化学习算法有策略梯度(Policy Gradient,PG)算法等
4.2对环境建模
有模型强化学习的智能体与免模型强化学习智能体.
5 学习与规划
学习(learning)和规划(planning)是序列决策的两个基本问题。
习题
1、智能体-环境
2、没有标签,只有奖励信号,并且是延迟奖励(delayed reward)。 因为我们要判断该动作的正确与否,可能需要等游戏结束之后才可能知道。
3、特征:会不断试错和探索,通过搜索环境来获取对环境的理解。从环境中获得延迟的奖励。数据是存在关联的,不是独立的。智能体的动作会影响它后面得到的数据,很多时候数据是来自智能体和环境的交互。
4、硬件GPU的提升,给予智能体更多的试错的机会。
5、状态是对世界的完整描述。观测是对状态的部分描述。
6、强化学习智能体由策略(policy)、价值函数(value functio)、模型(model).
7、根据学习的准则不同,可以分为基于价值的智能体,基于策略的智能体。根据是否对环境进行建模,有模型强化学习的智能体与免模型强化学习智能体。
8、基于价值的学习方法会隐式地优化策略,通过获得更高的价值来确定更有的决策。但是基于策略的迭代,智能体会直接优化策略,从而获得最大的奖励。
9、有模型强化学习是指根据环境中的经验,构建一个虚拟世界,同时在真实环境和虚拟世界中学习;免模型强化学习是指不对环境进行建模,直接与真实环境进行交互来学习到最优策略。
10、智能体(agent)怎么在复杂、不确定的环境(environment)里面去最大化它能获得的奖励。如
10 面试题(简略回答)
1、训练一个智能体能够及时对环境做出在最后哦阶段获得更高价值的决策。
2、个人认为最大区别是数据是否是独立同分布的。
3、游戏,机器人,元宇宙。
4、从本质上看都是优化问题,但是强化学习中该损失函数的反馈是不及时,有延时存在的。
5、对环境是否进行建模。














 3015
3015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









