







异构联邦学习的设备采样: 理论,算法,实现
一、文章介绍
这篇文章被INFOCOM2021接收,解决的是异质联邦学习的设备采样问题。基于网络拓扑和设备性能限制,作者尝试在“节点采样”和“数据分流”中寻找一个最优组合。通过理论分析,作者提出了一个基于GCN的设备采样方法,探索“网络属性”、“采样节点”、“结果分流”之间的关系,最大化FL的精度。IoT设备上的实验表明了方法的有效性。
二、背景和目的
联邦学习会采样部分节点进行聚合,这些节点的性能和数据各异。我们希望(1)减少这些被采样的节点数据之间的相似性(更能代表全局数据信息),同时又(2)提升联邦学习的训练运行速度。
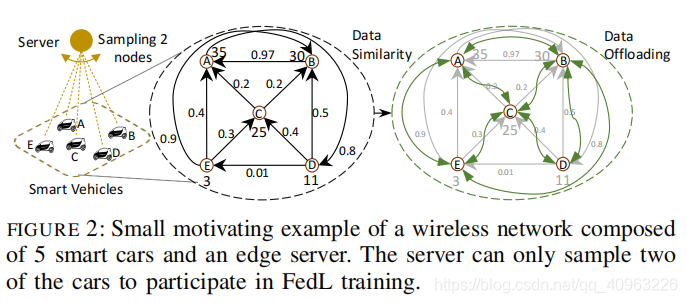
如图2所示,有 ABCDE 五个设备,“边”代表设备间数据的相似性,“顶点”代表设备性能。显然A(35)、B(30)性能相对更高,但A、B数据很相似(0.97),同时选A和B是不合适的。E和D数据差异大,但性能低,同时选择E和D也不合适。C(25)性能适中,利用D2D将E和D的数据分流到C,C的数据就包含了三个设备的数据信息。
作者利用这个例子,想说明:节点采样需要同时考虑“数据”和“性能”,数据分流是个可利用的方案。
三、建模
1、边缘设备模型
一组设备 N = { 1 , ⋯ , N } \mathcal{N}=\{1, \cdots, N\} N={1,⋯,N}与服务器连接。对设备 i ∈ N i \in \mathcal{N} i∈N来说:
- 数据处理能力 P i ( t ) ≥ 0 P_i(t)\ge0 Pi(t)≥0,单位数据处理成本 p i ( t ) ≥ 0 p_i(t)\ge0 pi(t)≥0(异质、时变);
- 数据传输预算 Ψ i ( t ) > 0 \Psi _i(t)>0 Ψi(t)>0,单位数据传输成本 ψ i , j ( t ) > 0 \psi _{i,j}(t)>0 ψi,j(t)>0(与带宽,信道干扰有关),距离更近的设备可能 ψ i , j ( t ) > 0 \psi _{i,j}(t)>0 ψi,j(t)>0更小;
- 局部数据集 D i ( t ) \mathcal{D}_i(t) Di(t)(会因数据分流随t改变),数据样本数 D i ( t ) = ∣ D i ( t ) ∣ {D}_i(t)=|\mathcal{D}_i(t)| Di(t)=∣Di(t)∣;
2、网络拓扑
- 时变网络图 G = ( N , E ( t ) ) G=(\mathcal{N}, \mathcal{E}(t)) G=(N,E(t)) , N N N表示可用的D2D拓扑, E ( t ) \mathcal{E}(t) E(t)表示图的边;
- 图的邻接矩阵定义为 A ( t ) = [ A i , j ( t ) ] 1 ≤ i , j ≤ N \mathbf{A}(t)=\left[A_{i, j}(t)\right]_{1 \leq i, j \leq N} A(t)=[Ai,j(t)]1≤i,j≤N,当 ( i , j ) ∈ E ( t ) (i,j)\in \mathcal{E}(t) (i,j)∈E(t) 表示 t 时刻 节点 i i i 可以传输数据给 j j j,有 A i , j ( t ) = 1 A_{i, j}(t)=1 Ai,j(t)=1,反之为0;
- Φ i , j ( t ) ∈ [ 0 , 1 ] \Phi_{i, j}(t) \in[0,1] Φi,j(t)∈[0,1] 表示节点 i i i 给 j j j 数据分流的比例(根据数据相似度来决定);
- 相似度矩阵 λ ( t ) ≜ [ λ i , j ( t ) ] 1 ≤ i , j ≤ N \boldsymbol{\lambda}(t) \triangleq\left[\lambda_{i, j}(t)\right]_{1 \leq i, j \leq N} λ(t)≜[λi,j(t)]1≤i,j≤N,其中 0 ≤ λ i , j ( t ) ≤ 1 0\le\lambda_{i, j}(t)\le1 0≤λi,j(t)≤1;
- 连接-相似度矩阵 Λ ( t ) ≜ λ ( t ) ∘ A ( t ) = [ Λ i , j ( t ) ] \boldsymbol{\Lambda}(t) \triangleq \boldsymbol{\lambda}(t) \circ \mathbf{A}(t) = \left[\Lambda_{i, j}(t)\right] Λ(t)≜λ(t)∘A(t)=[Λi,j(t)],其中 ∘ \circ ∘ 表示哈达玛积;
3、联邦学习模型
联邦学习中,每 τ \tau τ个周期聚合一次,有聚合公式:
w S ( k τ ) = ∑ i ∈ S Δ i ( k τ ) w i ( k τ ) ∑ i ∈ S Δ i ( k τ ) \mathbf{w}_{\mathcal{S}}(k \tau)=\frac{\sum_{i \in \mathcal{S}} \Delta_{i}(k \tau) \mathbf{w}_{i}(k \tau)}{\sum_{i \in \mathcal{S}} \Delta_{i}(k \tau)} wS(kτ)=∑i∈SΔi(kτ)∑i∈SΔi(kτ)wi(kτ)
其中, S \mathcal{S} S 表示被选择的设备集合, Δ i ( k τ ) ≜ ∑ t = ( k − 1 ) τ + 1 k τ D i ( t ) \Delta_{i}(k \tau) \triangleq \sum_{t=(k-1) \tau+1}^{k \tau} D_{i}(t) Δi(kτ)≜∑t=(k−1)τ+1kτDi(t) 表示节点 i i i 在第 k − 1 k-1 k−1 到 k k k次聚合期间的局部总数据量。
联邦学习的目标是最小化基于所有设备的全局损失:
F ( w S ( t ) ∣ D N ( t ) ) = ∑ i ∈ N D i ( t ) F ( w S ( t ) ∣ D i ( t ) ) D N ( t ) F\left(\mathbf{w}_{\mathcal{S}}(t) \mid \mathcal{D}_{\mathcal{N}}(t)\right)=\frac{\sum_{i \in \mathcal{N}} D_{i}(t) F\left(\mathbf{w}_{\mathcal{S}}(t) \mid \mathcal{D}_{i}(t)\right)}{D_{\mathcal{N}}(t)} F(wS(t)∣DN(t))=DN(t)∑i∈NDi(t)F(wS(t)∣Di(t))
4、建模总结
我们定义 x ≜ ( x 1 , ⋯ , x N ) \mathbf{x} \triangleq\left(x_{1}, \cdots, x_{N}\right) x≜(x1,⋯,xN) 表示设备选择状态(被选择则 x i = 1 x_i=1 xi=1),要最优化两个目标(1)采样设备集 S ∗ \mathcal{S^*} S∗ 和 (2)分流比例 Φ i , j ∗ ( t ) \Phi^*_{i, j}(t) Φi,j∗(t),以此最小化全局损失,即,将优化问题 P \mathcal{P} P 表示为:
( P ) : minimize x , { Φ ( t ) } t = 1 T 1 T ∑ t = 1 T F ( w S ( t ) ∣ D N ( t ) ) . . . . . . . . . . . ( 1 ) (\mathcal{P}): \underset{\mathbf{x},\{\boldsymbol{\Phi}(t)\}_{t=1}^{T}}{\operatorname{minimize}} \frac{1}{T} \sum_{t=1}^{T} F\left(\mathbf{w}_{\mathcal{S}}(t) \mid \mathcal{D}_{\mathcal{N}}(t)\right) \quad...........\quad(1) (P):x,{Φ(t)}t=1TminimizeT1∑t=1TF(wS(t)∣DN(t))...........(1)
约束条件:
- 节点 i i i 在 t 时刻的数据量为 D i ( t ) = D i ( t − 1 ) + R i ( t ) , i ∈ N D_{i}(t)=D_{i}(t-1)+R_{i}(t), i \in \mathcal{N} Di(t)=Di(t−1)+Ri(t),i∈N;
- 数据计算开销要在设备承受范围内 p i ( t ) D i ( t ) ≤ P i ( t ) p_{i}(t) D_{i}(t) \leq P_{i}(t) pi(t)Di(t)≤Pi(t);
- 节点 k k k 传给 i i i 的数据量 R i ( t ) = ∑ k ∈ N D k ( t − 1 ) Φ k , i ( t ) ( 1 − Λ k , i ( t − 1 ) ) , i ∈ N R_{i}(t)=\sum_{k \in \mathcal{N}} D_{k}(t-1) \Phi_{k, i}(t)\left(1-\Lambda_{k, i}(t-1)\right), i \in \mathcal{N} Ri(t)=∑k∈NDk(t−1)Φk,i(t)(1−Λk,i(t−1)),i∈N;
- 要满足(1) R i ( t ) ≤ θ i ( t ) R_{i}(t) \leq \theta_{i}(t) Ri(t)≤θi(t),后者为节点 i i i 的设备接收容量,(2) ∑ i ∈ N Φ k , i ( t ) ≤ 1 \sum_{i \in \mathcal{N}} \Phi_{k, i}(t) \leq 1 ∑i∈NΦk,i(t)≤1,节点 k k k 分流出去的数据量不超过自己的数据量;
- 数据传输开销要在设备承受范围内 D k ( t − 1 ) ∑ i ∈ N x i Φ k , i ( t ) ψ k , i ( t ) ≤ Ψ k ( t ) , k ∈ N D_{k}(t-1) \sum_{i \in \mathcal{N}} x_{i} \Phi_{k, i}(t) \psi_{k, i}(t) \leq \Psi_{k}(t), k \in \mathcal{N} Dk(t−1)∑i∈NxiΦk,i(t)ψk,i(t)≤Ψk(t),k∈N;
- 更新连接-相似度 Λ k , i ( t ) = Λ k , i ( t − 1 ) + ( 1 − Λ k , i ( t − 1 ) ) Φ k , i ( t ) , i , k ∈ N \Lambda_{k, i}(t)=\Lambda_{k, i}(t-1)+\left(1-\Lambda_{k, i}(t-1)\right) \Phi_{k, i}(t), i, k \in \mathcal{N} Λk,i(t)=Λk,i(t−1)+(1−Λk,i(t−1))Φk,i(t),i,k∈N;
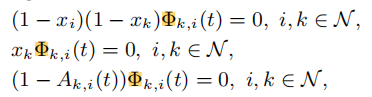
保证数据分流只发生在相互信任的未采样节点 k ∈ S ^ k \in \hat{\mathcal{S}} k∈S^ 到采样节点 i ∈ S i\in \mathcal{S} i∈S 之间;
四、方法
1、数据分流
作者基于若干定义和假设,推导得到了目标(1)的近似(对于 x \mathbf{x} x已知的情况):
( P ) : min { Φ ( t ) } t = 1 T 1 T ∑ t = 1 T ( D N ( t ) − D S ( t ) D N ( t ) ) ∇ F ( t ) ‾ ⏟ ( a ) + 1 ∣ S ∣ ∑ i ∈ S γ D i ( t ) ⏟ ( b ) , (\mathcal{P}): \underset{\{\boldsymbol{\Phi}(t)\}_{t=1}^{T}}{\operatorname{min}}\frac{1}{T} \sum_{t=1}^{T} \underbrace{\left(\frac{D_{\mathcal{N}}(t)-D_{\mathcal{S}}(t)}{D_{\mathcal{N}}(t)}\right) \overline{\nabla F(t)}}_{(a)}+\frac{1}{|\mathcal{S}|} \sum_{i \in \mathcal{S}} \underbrace{\frac{\gamma}{\sqrt{D_{i}(t)}}}_{(b)}, (P):{Φ(t)}t=1TminT1∑t=1T(a) (DN(t)DN(t)−DS(t))∇F(t)+∣S∣1∑i∈S(b) Di(t)γ,
进一步将实时梯度近似为服务器上观察到的梯度:
∇ F ( t ) ‾ ≈ ∇ F ( k τ ) ‾ / α k + 1 t − k τ \overline{\nabla F(t)} \approx \overline{\nabla F(k \tau)} / \alpha_{k+1}^{t-k \tau} ∇F(t)≈∇F(kτ)/αk+1t−kτ
其中 α k + 1 = ∇ F ( ( k − 1 ) τ ) ‾ / ∇ F ( k τ ) ‾ τ \alpha_{k+1}=\sqrt[\tau]{\overline{\nabla F((k-1) \tau)} / \overline{\nabla F(k \tau)}} αk+1=τ∇F((k−1)τ)/∇F(kτ)。
作者将以上问题作为随时间变化的凸优化问题来解决,采用了CVXPY凸优化库进行了求解,得到了 t t t 时刻最优数据分流解 Φ ( t ) ∗ \boldsymbol{\Phi}(t)^* Φ(t)∗。
2、设备采样
(1)核心思想
 上图为基于GCN的设备采样方案,作者采用两层GCN:
上图为基于GCN的设备采样方案,作者采用两层GCN:
- 节点特征向量 π i ≜ [ D i ( 0 ) , P i ( 0 ) , p i ( 0 ) , θ i ( 0 ) ] \boldsymbol{\pi}_{i} \triangleq\left[D_{i}(0), P_{i}(0), p_{i}(0), \theta_{i}(0)\right] πi≜[Di(0),Pi(0),pi(0),θi(0)]
- 增广连接-相似度矩阵 A ~ ≜ Λ ( 0 ) + I N \tilde{\mathbf{A}} \triangleq\mathbf{\Lambda}(\mathbf{0})+\mathbf{I}_{N} A~≜Λ(0)+IN
GCN输出得到每个节点被采样的概率 Γ ∈ [ 0 , 1 ] N \mathbf{\Gamma} \in[0,1]^{N} Γ∈[0,1]N。
(2)GCN训练过程
- 随机生成若干组采样网络和节点数据 e = 1 , ⋅ ⋅ ⋅ , E e = 1, · · · , E e=1,⋅⋅⋅,E;
- 对每一组生成,我们可以基于 π e \boldsymbol{\pi}_{e} πe 和 A ~ e \tilde{\mathbf{A}}_{e} A~e凸优化求解得到最优分流比例;
- 计算FL的损失,损失最小的组 x e ⋆ \mathbf{x}_{e}^{\star} xe⋆ 作为GCN的输出标签;
上述操作为GCN提供了训练样本 [ ( π e , A ~ e , x e ⋆ ) ] e = 1 E \left[\left(\boldsymbol{\pi}_{e}, \tilde{\boldsymbol{A}}_{e}, \mathbf{x}_{e}^{\star}\right)\right]_{e=1}^{E} [(πe,A~e,xe⋆)]e=1E ,以此训练好GCN。
3、联邦学习训练过程
对于一个目标图网络,我们已知它的 π \boldsymbol{\pi} π 和 A ~ \tilde{\mathbf{A}} A~,将其输入到训练好的GCN中得到概率输出 Γ = H ( π , A ~ ) , Γ = [ Γ i ˉ ] 1 ≤ i ≤ N \boldsymbol{\Gamma}=H(\boldsymbol{\pi}, \tilde{\mathbf{A}}), \boldsymbol{\Gamma}=\left[\Gamma_{\bar{i}}\right]_{1 \leq i \leq N} Γ=H(π,A~),Γ=[Γiˉ]1≤i≤N,接下来
- 首先根据概率最大选择第一个节点 S = S ∪ { s 1 } S=S \cup\left\{s_{1}\right\} S=S∪{s1},即 s 1 = arg max i ∈ N p s_{1}=\arg \max _{i \in \mathcal{N}_{p}} s1=argmaxi∈Np,其中 N p \mathcal{N}_{p} Np 是初始数据量98th百分点集合;
- 然后基于采样概率最高、聚合数据相似度最小选择后续采样节点 S = S ∪ { s n } S=S \cup\left\{s_{n}\right\} S=S∪{sn},具体来说, s n = arg max i ∈ R s n − 1 Γ i s_{n}=\arg \max _{i \in \mathcal{R}_{s_{n-1}}} \Gamma_{i} sn=argmaxi∈Rsn−1Γi,其中 R s n − 1 \mathcal{R}_{s_{n-1}} Rsn−1表示 s n − 1 s_{n-1} sn−1的数据不相似度98th百分点邻居节点集合;
- 一旦采样节点被确定后,求解最优数据分流方案并分流数据;
- FL训练并聚合模型。
五、总结
这篇文章知识量很大,考虑了D2D场景下的联邦学习,提出数据分流方案,并对数据分流提供了严密的理论分析,利用理论求得最优分流解(这里我没有细看理论推导过程)。同时,采用GCN来最优化设备采样方案。无论是在方法、理论、工作量这几个方面上都很强。















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









