







Deep Unfolding Network for Image Super-Resolution 论文阅读
超分问题是 低级视觉领域中的经典的病态问题
基于模型的方法可以通过统一的最后后验框架来解决不同种类的病态问题,具有灵活性
基于学习的方法训练速度快,但是缺乏一定的灵活性。
本文提出了一种端到端的可训
练的网络模型,将两者结合起来。
根据贝叶斯最大后验,退化公式可以得到该能量函数:
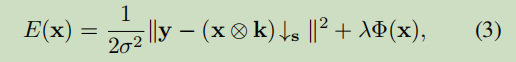
使用半二次分裂方法HQS,将上述式子分解为数据项和正则项,数据项保证解符合退化过程,而正则化项强制输出的期望属性。
引入变量Z,μ是惩罚参数。
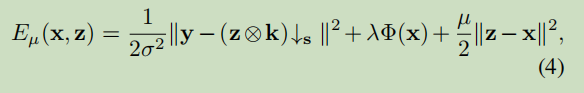
式子4可以通过迭代求解x和z得到解决。
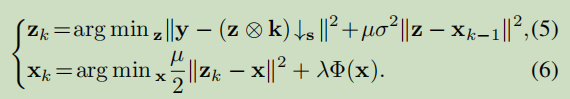
μ应该逐渐增加,以平衡迭代速度和x,z的相似性,
假设在圆形边界条件下,通过FFT快速傅里叶变换进行卷积利用,得到封闭形式的解
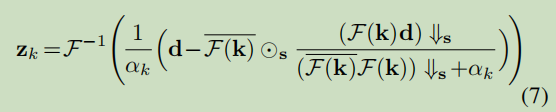
d被定义为
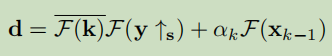
with α k ≜ μ k σ 2 \alpha_{k} \triangleq \mu_{k} \sigma^{2} αk≜μkσ2 and where the F ( ⋅ ) \mathcal{F}(\cdot) F(⋅) and F − 1 ( ⋅ ) \mathcal{F}^{-1}(\cdot) F−1(⋅) denote FFT and inverse FFT, F ( ⋅ ) ‾ \overline{\mathcal{F}(\cdot)} F(⋅) 是复共轭物of F ( ⋅ ) , ⊙ s \mathcal{F}(\cdot), \odot_{\mathbf{s}} F(⋅),⊙s 表示具有元素级乘法的不同的块处理运算符,, i.e., applying elementwise multiplication to the s × s \mathbf{s} \times \mathbf{s} s×s distinct blocks of F ‾ ( k ) \overline{\mathcal{F}}(\mathbf{k}) F(k), ↓ s \downarrow_{s} ↓s 表示不同的块降采样器,, i.e., 平均 the s × s \mathbf{s} \times \mathbf{s} s×s 不同的块, ↑ s \uparrow_{\mathrm{s}} ↑s 表示标准的s倍上采样器,, i.e., 通过用零填充新的条目来对空间大小进行上采样.特别值得注意的是 that Eq. (7) also works for the special case of deblurring when s = 1 \mathbf{s}=1 s=1. For the solution of Eq. (6), it is known that, 从贝叶斯的角度来看,它实际上对应于一个噪声水平的去噪问题 β k ≜ λ / μ k [ 10 ] \beta_{k} \triangleq \sqrt{\lambda / \mu_{k}}[10] βk≜λ/μk[10].
深度展开网络
Unfolding SuperResolution Network:

网络中左侧的输入的含义分别为y:输入的低分辨率图像;k:模糊核;$ \sigma$ :噪声水平;s:缩放比例。网络中的三个模块含义分别为 D:基于模型的超分;P:基于学习的去噪;H:对于超参数的预测。
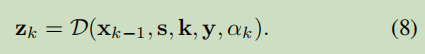
注意,x0是通过最简单的最近邻插值与尺度因子s插值y来初始化的。应该注意的是,公式(8)不包含可训练的参数,由于数据项和前一项之间的完全解耦,这反过来又具有更好的可推广性。
Xk-1:k-1轮的输出图像;s:尺寸;k:轮次;y:输入图像; α \alpha αk:超参数.

该模块旨在通过Zk通过噪声级为βk的去噪器,获得更干净的HR图像Xk.去噪器涉及四个图像尺度,每一个都在降尺度和升尺度操作之间有一个身份跳过连接;第一个比例到第四个比例被设置为64、128、256和512,
ResUNet以连接的zk和噪声级图作为输入,输出去噪图像xk。通过这样做,ResUNet可以通过单个模型来处理不同的噪声级别,这大大减少了参数的总数。
为了继承ResNet的优点,在每个尺度的缩小和升级中采用了2组残余块。如[36]所示,每个残差块由两个3×3的卷积层组成,中间是ReLU激活,以及一个身份跳过连接求和到其输出

α k \alpha_{k} αk由 σ \sigma σ和 μ k \mu_{k} μk决定, β k \beta_{k} βk由 λ \lambda λ和 μ k \mu_{k} μk决定;虽然可以学习一个固定的λ和μk,但我们认为,如果λ和μk随两个关键元素而变化,就可以获得性能增益,即尺度因素s和噪声水平 σ \sigma σ;
端到端的训练
端到端训练的目的是通过在大型训练数据集上最小化损失函数来学习USRNet的可训练参数。
使用 DIV2K and Flickr2K 为数据集
比例因子从{1、2、3、4}中选择。
我们将内核大小固定为25×25。对于噪声水平,我们将其范围设置为[0,25]
我们采用L1损失作为PSNR性能
我们将这种微调的模型称为USRGAN。和往常一样,USRGAN只考虑比例因子4。我们不使用额外的损失来限制中间输出,因为上述损失工作得很好。一个可能的原因是,之前的模块在整个迭代中共享参数。
Adam与小批量大小128。
学习速率从1次×10−4开始,每4次×104次迭代衰减0.5倍,最后以3次×10−6结束
值得指出的是,由于对不同尺度因子的并行计算不可行,每个最小批只涉及一个随机尺度因子。对于USRGAN,其学习率固定为1×10−5。
USRNet和USRGAN的HR图像的补丁大小都设置为96×96。
在亚马逊AWS云中的4台英伟达特斯拉V100gpu上使用PyTorch对模型进行训练。获得USRNet模型大约需要两天的时间。














 5520
5520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









