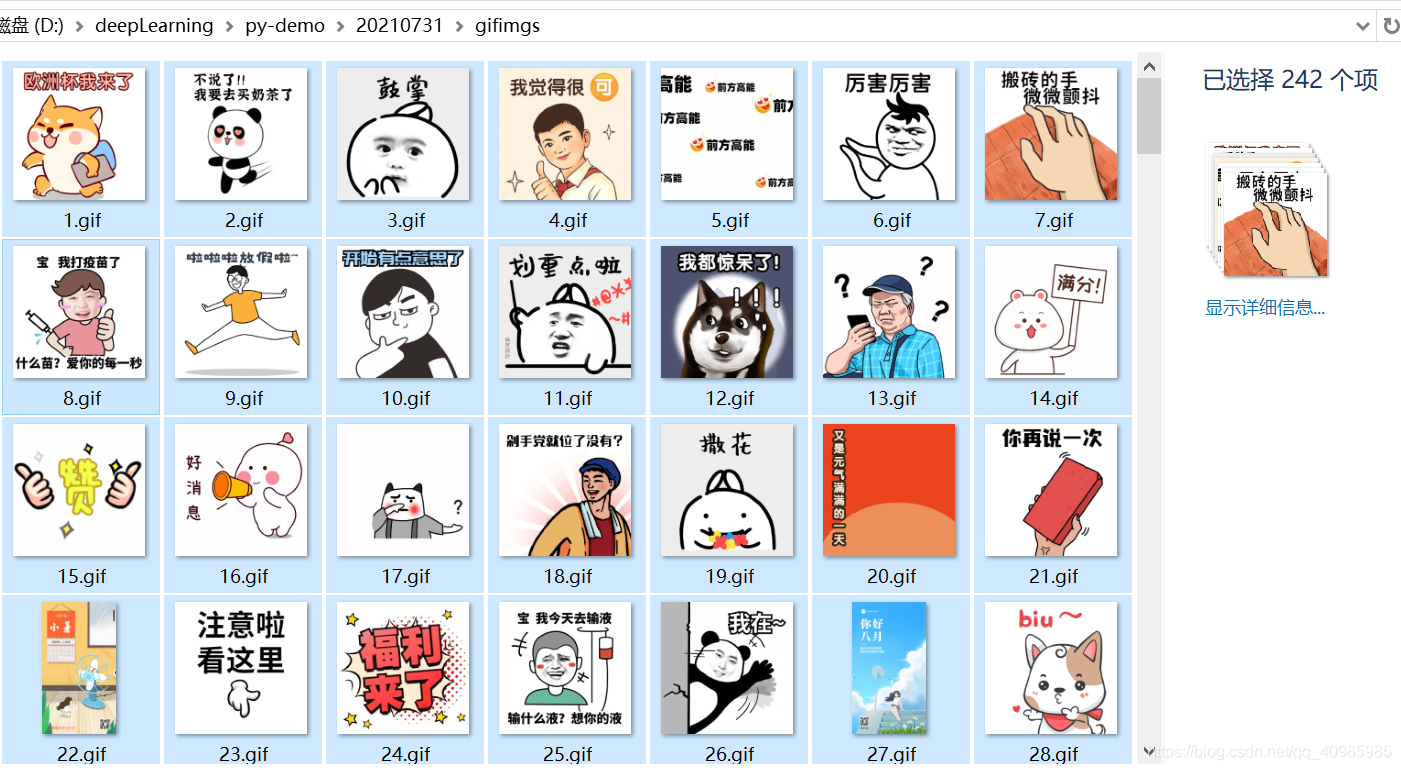
10000+ gif表情包不是梦,get这一篇文就够了!!!小哥哥快到碗里来,再也不怕斗图没有表情包了 1. 依赖模块及安装 2. 查找网页规律 3. 源码 最近看的爬虫的博客太多,小小的学习了下。主要是http请求,分析网页的http请求拼接(分页),返回值html 或者json的解析(用到正则表达式re或者json模块); 先上一张成果图: 1. 依赖模块及安装 pip install request pip install json pip install re









 超级会员免费看
超级会员免费看


 本文介绍了如何使用Python进行爬虫操作,通过分析网页HTTP请求和HTML结构,获取GIF动图。重点讲述了依赖模块的安装、分页规律的查找以及源码实现,帮助读者实现快速获取大量动图,解决斗图无图的困扰。
本文介绍了如何使用Python进行爬虫操作,通过分析网页HTTP请求和HTML结构,获取GIF动图。重点讲述了依赖模块的安装、分页规律的查找以及源码实现,帮助读者实现快速获取大量动图,解决斗图无图的困扰。




 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








