








 超级会员免费看
超级会员免费看


 本文详细介绍了图像内核的概念,展示了如何通过Python和OpenCV实现卷积操作,包括平滑、锐化、边缘检测等。重点讲解了卷积神经网络在深度学习中的角色,以及它们如何自动学习过滤器。通过实例展示了自定义卷积函数和OpenCV内置函数cv2.filter2D的对比。
本文详细介绍了图像内核的概念,展示了如何通过Python和OpenCV实现卷积操作,包括平滑、锐化、边缘检测等。重点讲解了卷积神经网络在深度学习中的角色,以及它们如何自动学习过滤器。通过实例展示了自定义卷积函数和OpenCV内置函数cv2.filter2D的对比。
这篇博客将介绍图像内核和卷积。如果将图像视为一个大矩阵,那么图像内核只是一个位于图像顶部的微小矩阵。从左到右和从上到下滑动内核,计算输入图像和内核之间的元素乘法总和——称这个值为内核输出。内核输出存储在与输入图像相同 (x, y) 坐标的输出图像中(在考虑任何填充以确保输出图像具有与输入相同的尺寸后)。
鉴于对卷积的新了解,定义了一个OpenCV和Python函数来将一系列内核应用于图像。包括平滑模糊图像、锐化图像、拉普拉斯内核并检测边缘,sobel_x,y内核查找图像的梯度变化等操作。
最后,简要讨论了核/卷积在深度学习中扮演的角色,特别是卷积神经网络,以及如何自动学习这些过滤器,而不是需要先手动定义它们。手动实现卷积函数是为了明白卷积是怎么计算的,以及opencv自带的卷积函数cv2.filter2D。
1. 效果图
将图像视为大矩阵,将内核视为小矩阵(至少相对于原始的“大矩阵”图像):
内核是一个小矩阵,在较大的图像上从左到右和从上到下滑动。在输入图像中的每个像素处,图像的邻域与内核卷积并存储输出。
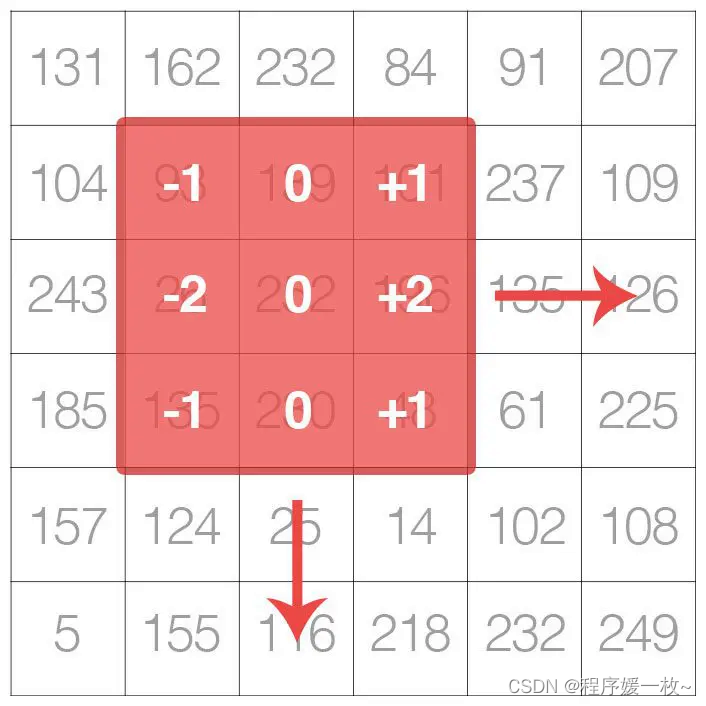
卷积运算符可以应用于 RGB(或其他多通道图像),但为简单起见,这篇博客中仅将过滤器应用于灰度图像。调用 cv2.filter2D将内核应用于灰色图像。cv2.filter2D 函数是opencv自带的,自定义卷

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3056
3056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











