









目录
四.YOLOV4

1.Abstract

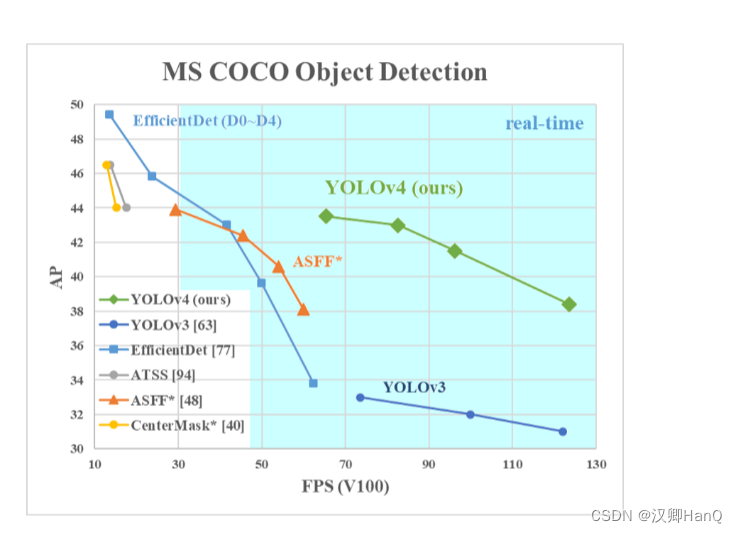
作者AlexeyB结合一些新技术和理念对V3进行改进,并且大大提高了FPS和Ap
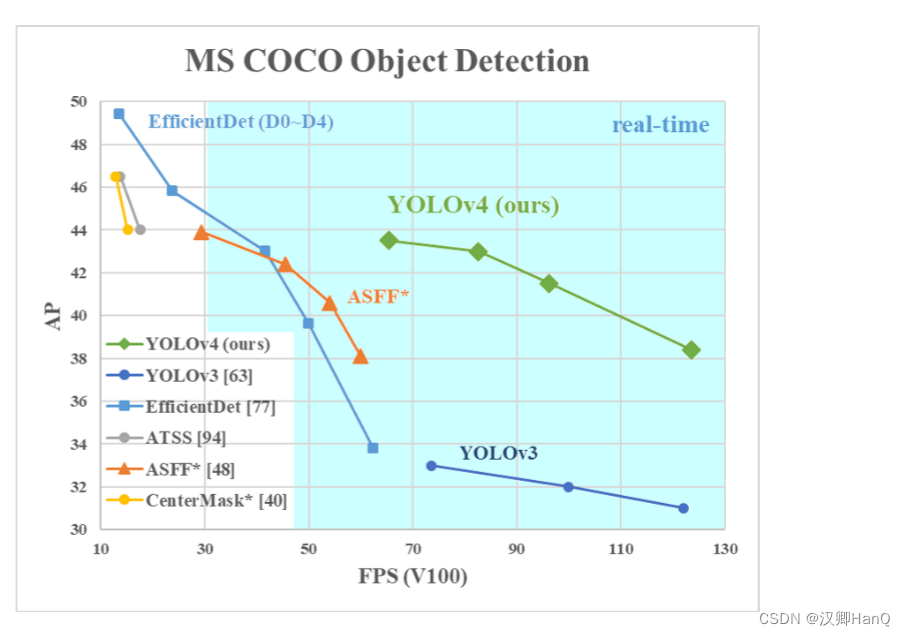
2.Bag
1>BoF
(Bag of Freebies):是指既不增加模型复杂度也不增加推理计算量的方法技巧来提高模型准确度
1)数据增强:图像几何变化,Cutmix,Mosaic等
2)网络正则化:Dropout,Dropblock
3)损失函数设计
2>BoS
(Bag of Specials):是指增加少许模型复杂度或计算量的训练技巧来提高模型准确度
1)增大模型感受野 SPP,ASPP
2) 引入注意力机制:SE,SAM
3)特征集成:PAN,BiFPN
4)激活函数改进:Swish,Mish
5)后处理方法改进:soft NMS,DIoU NMS
3.Architecture


1>CSPDarkNet53
作者借鉴2019年《CSPNet》在DarkNet-53基础上改进主干网络为CSPDarkNet53
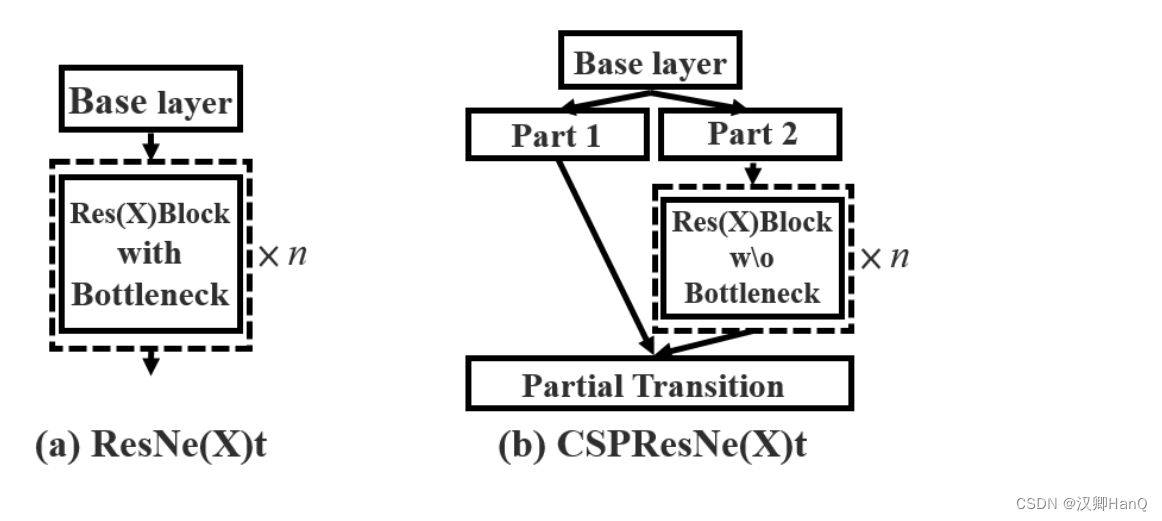
CSP作者在论文中提出推理计算过高的问题是由网络优化(类似DenseNet更新权重的BP会重复计算梯度)中的梯度信息重复导致的,因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将他们合并,在减少计算量的同时还可以保证准确率。
2>Mish


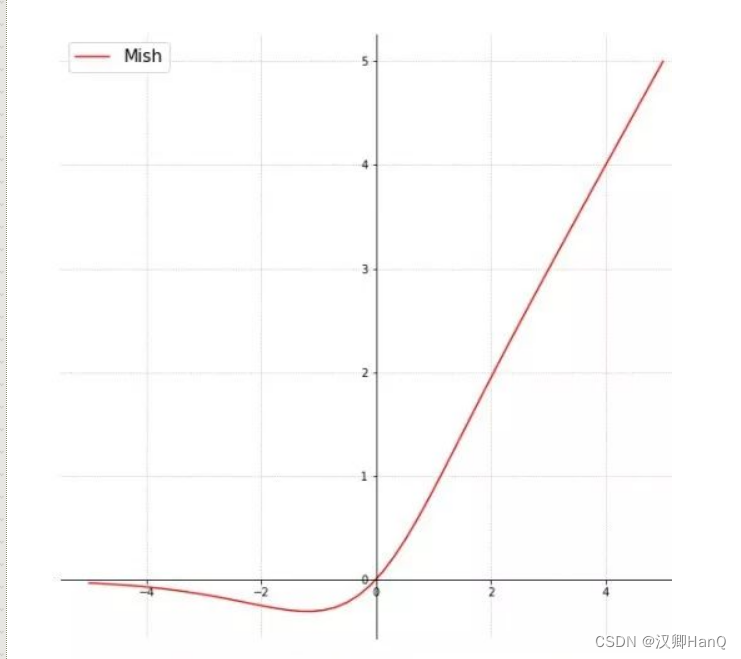
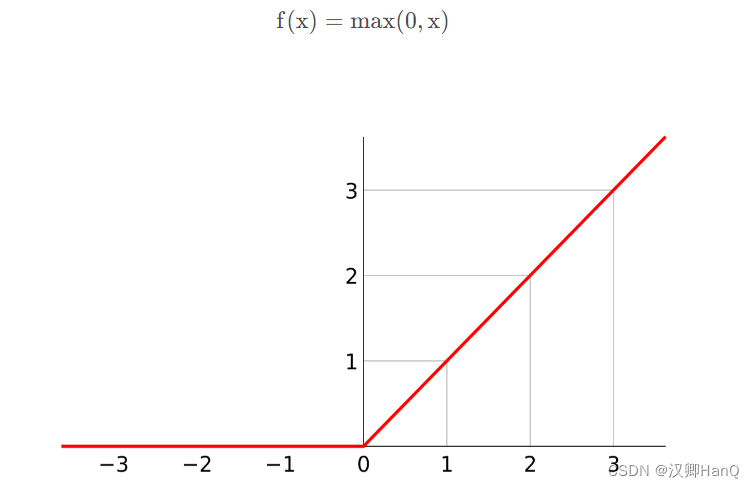
相比relu,Mish更加平滑,允许比较小的负梯度(负梯度relu大多数神经元没有更新)流入而保证了信息的流动,且relu激活函数无边界,让其避免了饱和且每一点连续平滑非单调,从而使梯度下降更好
3>Dropblock
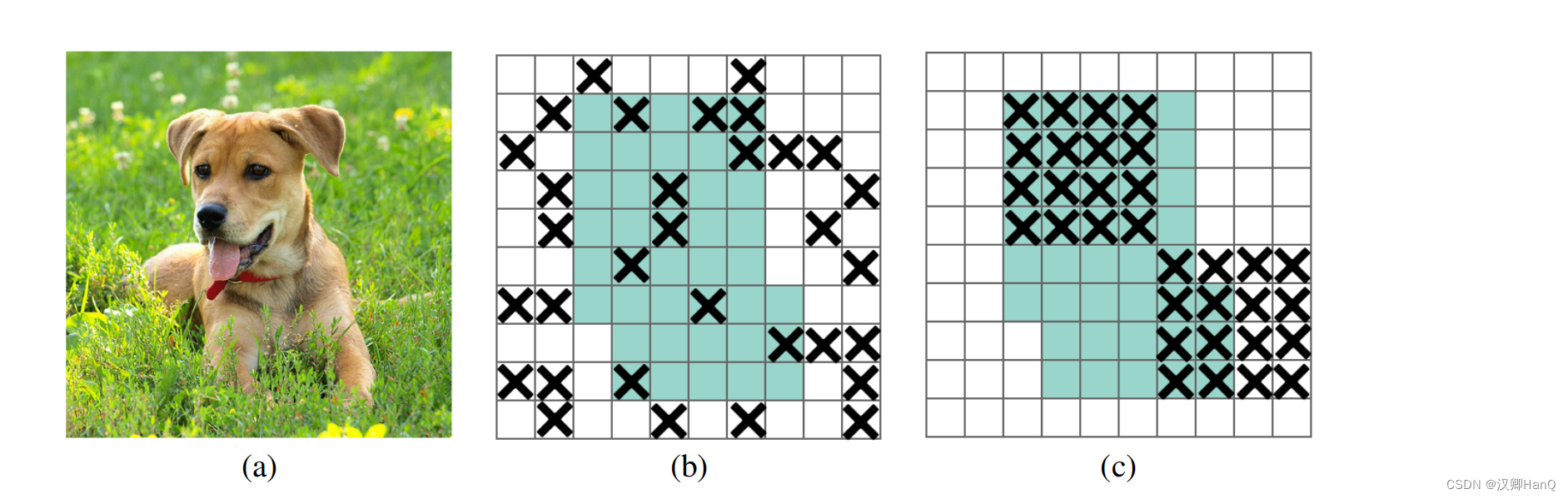
与传统的Dropout类似,Dropblock也随机减少神经元数量,缓解过拟合的一种正则化方式,不同的使Dropblock可以作用在任何卷积层之上
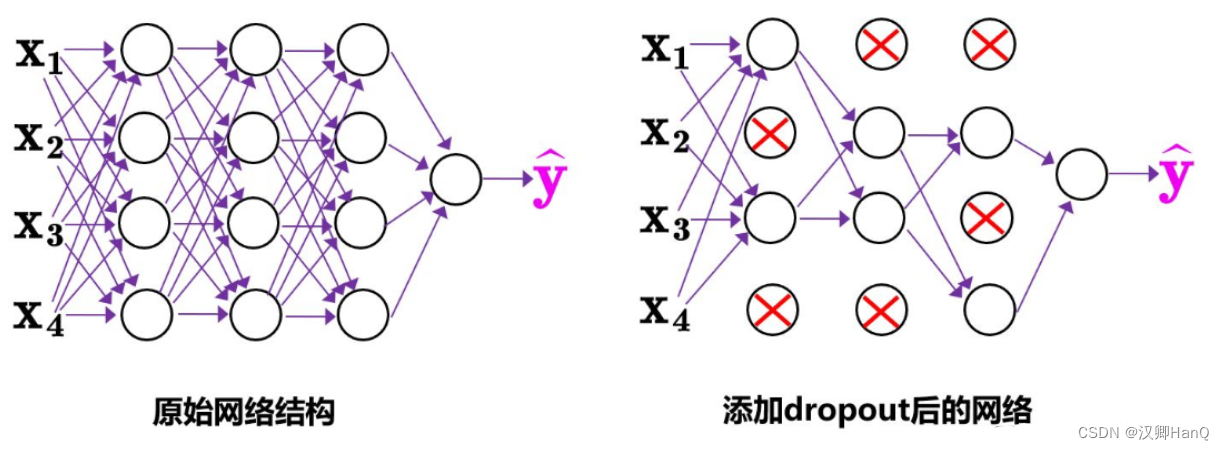
4>SPP
 增加主干特征接收范围,显著分离上下文特征
增加主干特征接收范围,显著分离上下文特征
4>PANet(FPN+PAN)

V3中FPN自顶向下,V4中结合图像分割领域PANet拆分结合FPN做拼接操作

4.Additional improvements

1>Mosaic
Mosaic是参考CutMix数据增强的方式(CutMix用来两张,Mosaic用了四张随机缩放,随机裁剪,随机排布的方式拼接)
训练两目时,小目标的AP必中大目标AP低很多,针对coco数据集中小目标占比较低(41.4%)的分布不均匀问题,使用Masaic大大丰富了检测数据集,让其网络鲁棒性更好,且batch不允许很大,因此一个GPU训练就可以达到较好的效果
2>SAT(自对抗训练)
 第一阶段改变原始图像而不是改变网络权值,通过这种方式神经网络对自己执行一种抗性攻击
第一阶段改变原始图像而不是改变网络权值,通过这种方式神经网络对自己执行一种抗性攻击
第二阶段神经网络以正常的方式对这个修改后的图像进行检测
3>CmBN
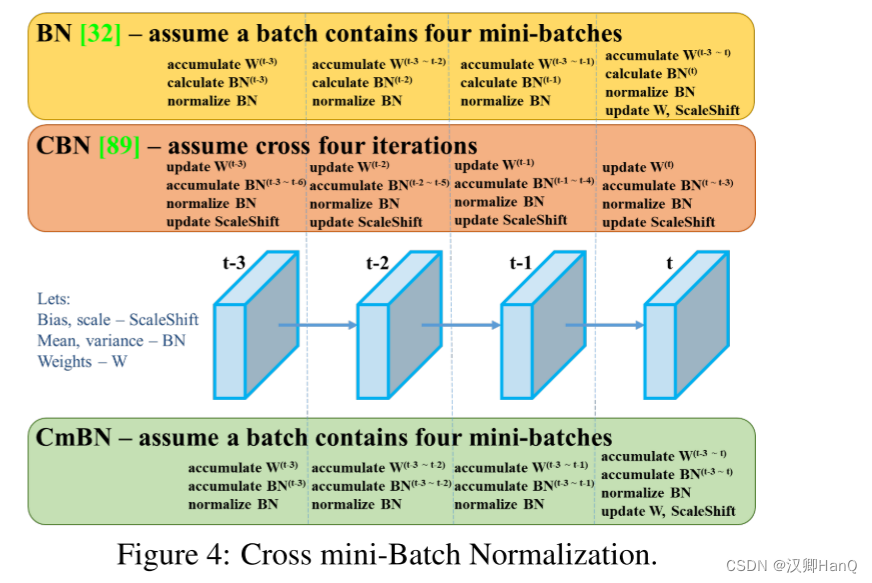
CmBN是对CBN的一种改进,定义为交叉微批标准化(Cross min-Batch Normalization) -后续会对BN,CBN和CMBN进行详细学习qaq,现在看不懂,这里等一个学习链接
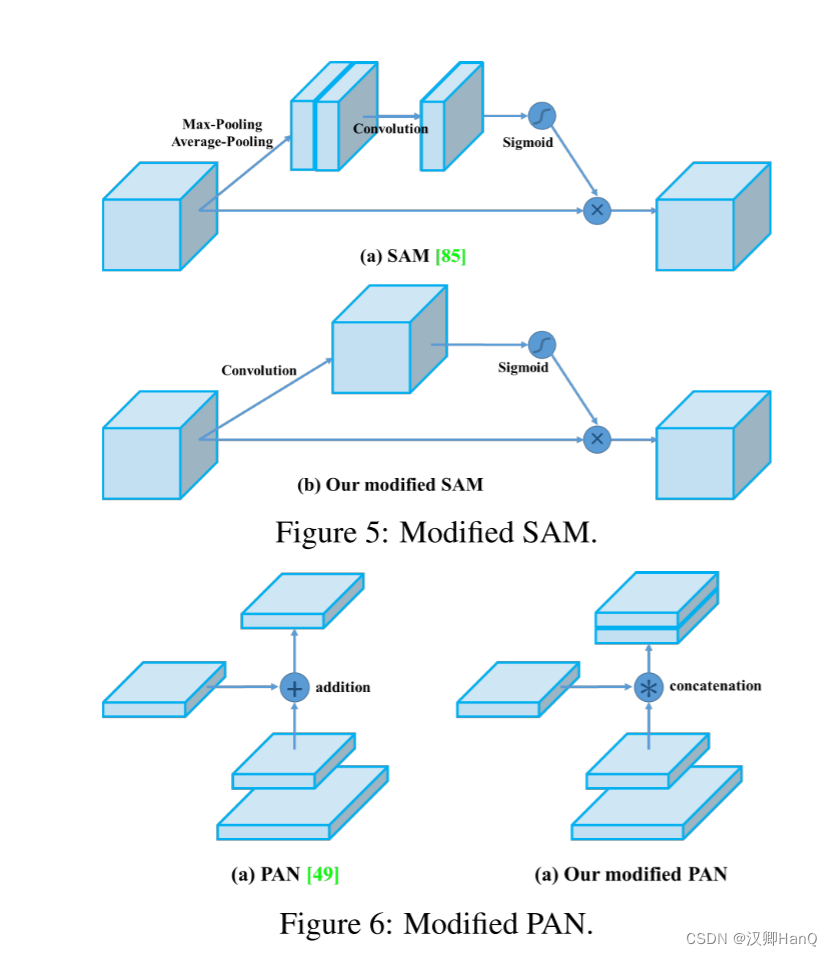
4>SAM

V4对SAM的spatial-wise attention改变为pointwise attention,将PAN的shortcut connection该为concatenation
5.Loss fuction
 摘要和文中部分地方提出了使用CIOU代替V3中box位置损失,取代了预测框和真实框中心点坐标和宽高信息设定MSE(均方误差)
摘要和文中部分地方提出了使用CIOU代替V3中box位置损失,取代了预测框和真实框中心点坐标和宽高信息设定MSE(均方误差)
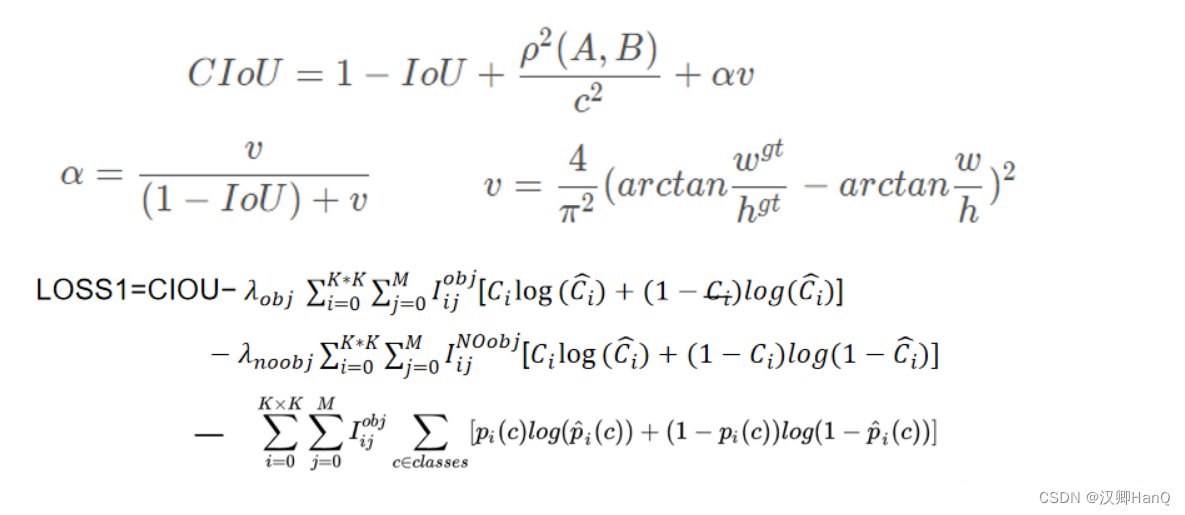
6.Conclusions

7.Innovation point
1>在数据输入端通过Mosiac数据增强,SAT自对抗训练,CmBN
2>主干网络结合CSPNet改进Darknet-5,激活函数由relu更换为Mish,将Dropblock加入网络中使网络避免过拟合
3>改进了预测框损失函数
4>改进了SAM
5>先验框特征融合结合PANet思想进行改进
6>YOLOV4在单显卡训练性能也不错















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









