







目录
四.Motivation and High Level Considerations
 一.Abstract
一.Abstract

GoogleNet提出了一种Inception的神经网络架构,主要特点是提高了网络内计算资源的利用率并且允许增加网络深度。决策架构基于Hebbian原则和多尺度处理优化质量,最终在ILSVRC14提交了GoogLeNet-22
二.Introduction

简述了一下神经网络的发展,提出了一种代号Inception的网络架构并在ILSVRC2014得以证实其性能
三.Related Work

1.从LeNet开始,CNN有了一种标准-n*(卷积-激活-池化)+m*全连接(Dropout解决过拟合),并且在诸多比赛上取得了很好的结果。
2.VggNet中提过,池化层会导致特征丢失,为了解决这个问题,使用1*1卷积核和Relu激活函数,这样不仅可以降维消除计算瓶颈,还可以增加网络深度。
3.前沿的目标检测方法是R-CNN,主要思想是将目标检测问题划分为两个子问题:首先利用低级的特征比如颜色和超像素的一致性来得到潜在的object proposals。然后利用CNN分类器对这些位置上的proposals进行分类识别。GoogLeNet对这两步分别进行了优化,取得了令人惊喜的结果。
四.Motivation and High Level Considerations


 正常来说,提高网络性能最直接的方法就是增加网络的深度或宽度,但同时也意味着要增加更多的参数,大量参数就会带来两个缺点
正常来说,提高网络性能最直接的方法就是增加网络的深度或宽度,但同时也意味着要增加更多的参数,大量参数就会带来两个缺点
1.过拟合
2.增加训练和测试的计算成本
为了更好的解决这些问题,GoogLeNet引入稀疏链接代替全连接提高网络效果
稀疏链接优点
1.减少计算量:神经网络主要计算是矩阵乘法和非线性函数激活,如果输出为0则不参与计算
2.减少过拟合:由于神经元减少可减少过拟合风险
3.提高泛化能力:稀疏表达可让模型更加关注数据中的重要特征,提高模型对新数据的适应能力
4.更好的可解释性:输出为0的神经元结果没有贡献,可认为此神经元不重要
稀疏链接缺点
1.计算机对与不均匀稀疏矩阵计算效率低,反而CPU和GPU对密集矩阵有优化早期神经网络使用随机系数链接,后期都改回了全连接。但现有一文献表明,对于大规模稀疏神经网络,可以通过分析激活值统计特性和高度相关的输出进行聚类来逐层构建出一个最优网络。虽然只在严格条件下成立,但在直觉上符合Hebbian principle的,GoogLeNetichuInception架构,即利用卷积核级别的系数链接,又充分利用现有设备对密集矩阵计算快的特点
Hebbian准则-“neurons that fire together, wire together”
指出突触的联结强度随着突触前后神经元的活动而变化,变化的量与
两个神经元的活性之和成正比,也就是说,同时激活的神经元连接得
会更紧密五.Architectural Detail

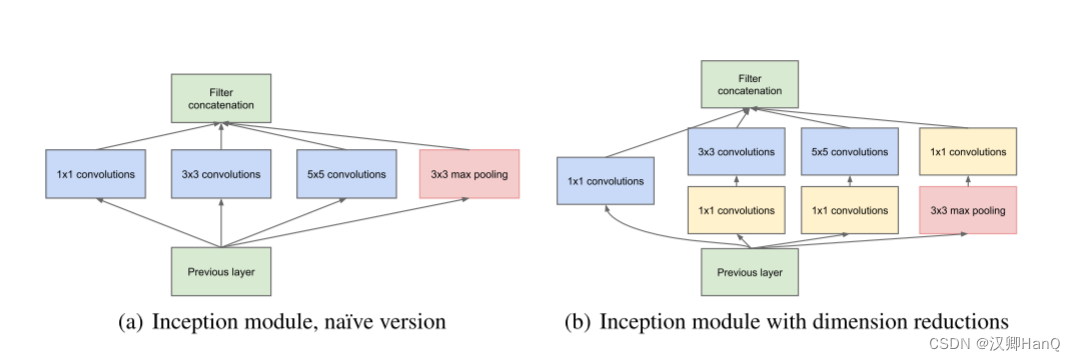
Inception的主要观点是弄明白卷积视觉网络中的一个局部最优稀疏结构是如何被一个可轻易获取的密集结构去逼近和覆盖的。
左边是初期版本,这里使用三个不同的patch size,1*1 3*3 5*5,主要是为了避免patch alignment问题和减少计算量。比如对三个patch分别使用padding=0,1,2进行卷积就可以让卷积后的输出具有相同的尺寸,而patch size较小的时候对应的参数相应也小一些。由于池化层在卷积神经网络中的作用往往都是起关键作用的,所以Inception model里也加入了一个池化层。但这种设计不是必须的,只是为了更方便。
但是初级的版本有个很大的缺点就是参数量和计算量会很大,而且将三个卷积层和一个池化层的输出拼接后的feature map数量会变得很大,随着网络层数的增加,模型会变得很复杂,变得难以训练
在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量,左图pooling后feature map是不变的,再加卷积层得到的feature map,会使输出的feature map扩大到416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道为32的1×1卷积,使得输出的feature map数降到了256。GoogLeNet利用1×1的卷积降维后,得到了更为紧凑的网络结构,虽然总共有22层,但是参数数量却只是8层的AlexNet的十二分之一(当然也有很大一部分原因是去掉了全连接层)。
为了避免网络过深引起的浅层梯度消失问题,GoogLenet在中间层的Inception module加入了两个辅助分类器(softmax),训练时在进行梯度下降求导的时候,将辅助分类器的损失函数(cost function)乘以0.3的权重加到总的损失函数上,这样可以有效避免梯度消失的问题。做预测的时候就不管这两个辅助分类器。
六.GoogLeNet
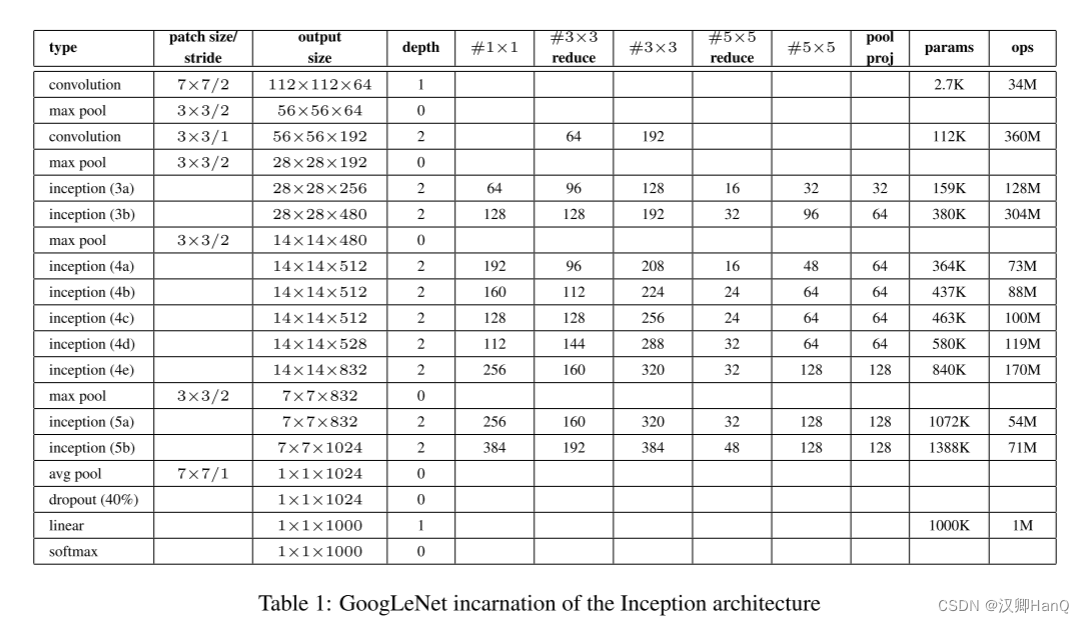
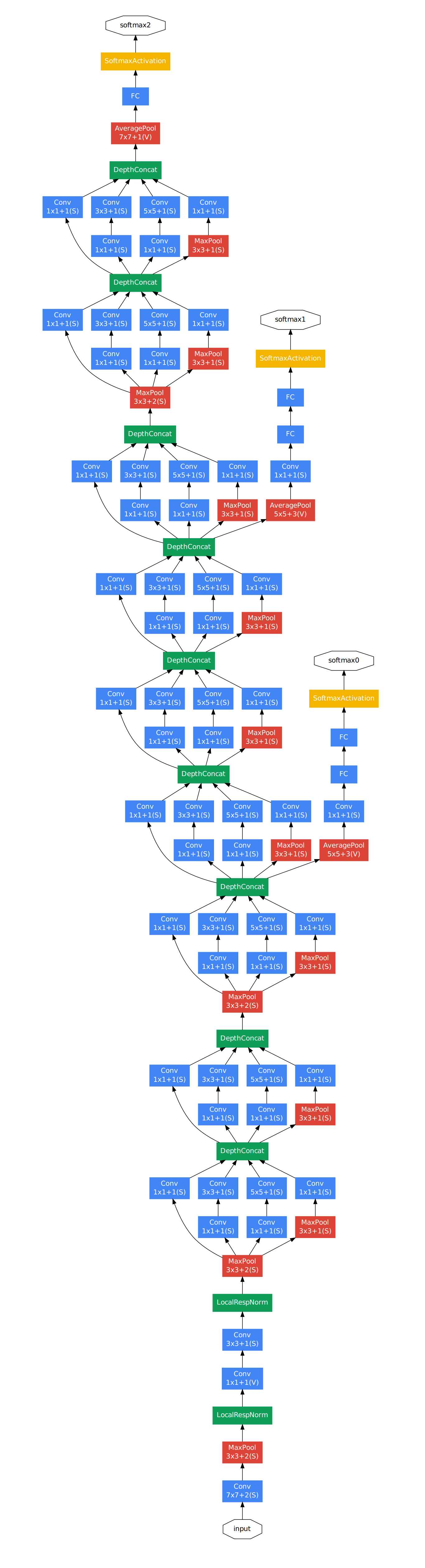
GoogleNet的结构就是3+3+3总共九个inception模块组成的,每个Inception有两层,加上开头的3个卷积层和输出前的FC层,总共22层!然后每3层的inception之后都会有一个输出结果,这个网络一共有三个输出结果
七.Training Methodology

GoogLeNet没有在GPU训练,在分布式机器学习系统上用CPU实现,但又一个粗略估计在CPU会节省更多时间
八.Conclusions

 GoogLeNet最终在2014年的ILSVRC Classification & Detection均斩获冠军,取得了惊人的成绩。相比第二名的VGGNet,GoogLeNet拥有更深的网络结构和更少的参数和计算量,主要归功于在卷积网络中大量使用了1×1卷积,以及用AveragePool取代了传统网络架构中的全连接层,当然这需要精心设计Inception architecture 才能取得最后这优异的成绩。
GoogLeNet最终在2014年的ILSVRC Classification & Detection均斩获冠军,取得了惊人的成绩。相比第二名的VGGNet,GoogLeNet拥有更深的网络结构和更少的参数和计算量,主要归功于在卷积网络中大量使用了1×1卷积,以及用AveragePool取代了传统网络架构中的全连接层,当然这需要精心设计Inception architecture 才能取得最后这优异的成绩。
九.Innovation point
1.使用更多的1*1 3*3 5*5卷积核,降低参数量,减轻过拟合,增强网络非线性能力
2.Inception模块丰富网络表达能力,提高网络深度
3.去掉最后的全连接层,用1*1卷积核代替
4.Inception模块允许网络同时从不同尺度的特征图中学习信息,这有助于更好地捕捉图像中的细节和全局信息
5.GoogleNet引入了辅助分类器来帮助梯度传播。在网络的中间部分添加了两个辅助分类器,这些分类器有助于在训练期间向较早的层传播梯度,有助于缓解梯度消失问题,进一步提高了训练效率。















 4944
4944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









