










1.IMDB数据集:
IMDB数据集是keras内置的数据集之一,共有50000条严重两级分化的评论,其中训练集和测试集都有25000条,且二者的正负评论各占50%(数据极为平衡,真实数据可能不会如此,对于类别不平衡数据需要进行一定处理)。IMDB数据集已经过预处理,评论(即单词序列)已被转换为整数序列,其中每个整数代表字典中的某个单词。
注:正常情况下,数据集是文字的情况应该先调用keras中preprocessing文件的text类,实例化(实例化时可输入参数num_words决定考虑频率最高的多少个单词)后构建字典(fit_on_texts),单词序列转换为数字序列(test_to_sequences),然后再使用preprocessing中的sequence类截断长度(pad_sequences)
from keras.preprocessing import text,sequence
tokenizer = text.Tokenizer(num_words=50000) # 实例化对象
tokenizer.fit_on_texts(Label_list) # 参数是一个列表,列表元素可以是句子,最终得到列表元素中单词元素对应的字典
word_sequences = tokenizer.text_to_sequences(Label_list) # 参数仍然可以为列表,得到的结果是二维列表,每一个子列表是数字序列,代表了某段文字。
word_sequences = sequence.pad_sequences(word_sequences,maxlen=200) # 截断或补0,使得每段文字所转化后的数字向量长度相同,补0的内容可以在后续embedding层设置参数mask_zero = True屏蔽。2.引入IMDB数据集:
from keras.datasets import imdb
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000)keras内置的imdb数据集都是经过预处理的数据集,其中有些数字在默认配置中是固定下来的,比如start_char=1代表某段文字的开始,oov_char=2代表超出字典最大索引后使用的数字,index_from=3代表从3开始对单词分配字典对。
3.查看某影评:
word_index = imdb.get_word_index() # 获取字典,字典值从0开始
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()]) # 倒转字典
decode_review = ' '.join([reverse_word_index.get(i-3,'?') for i in train_data[0]]) # 字典在转化为序列时每个值都加了3,为0:padding,1:序列起始和2:未知让位置,这里减回来。遇到0,1,2都会以?代替。4.将数字序列编码:
这里输入神经网络的不能是数字序列,处理方法有使用词嵌入,这个需要在网络中加入Embedding层,还有一种方法是将整数序列转化为one-hot向量,代码如下:
def seq_to_one_hot(sequences,dimention=10000):
results = np.zeros(len(sequences),dimention)) # 创建容纳的向量
for i,seq in enumerate(sequences):
results[i,seq] = 1 # results一般是形如results[0,[1,2,3,4]]的形式
return results标签向量化:
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32') # 类标也要以浮点型式存在,这是由于神经网络最终输出的也是浮点型概率,这里不转换类型有一定问题。注:由于这是个二分类的问题,类标可不转化为one_hot形式,如果是多分类,就要借助keras中的utils的to_categorical转换。
5..创建神经网络:
这里创建一个简单的全连接网络解决
from keras import models,layers
network = models.Sequential()
network.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
network.add(layers.Dense(16,activation='relu'))
network.add(layers.Dense(1,activation='sigmoid'))6.编译
from keras import optimizers,losses,metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001)),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy]) # 自定义损失函数时,注意将损失作为函数返回值7.割出验证集,训练
x_val = x_train[:10000]
y_val = y_train[:10000]
partial_x_train = x_train[:10000]
partial_y_train = y_train[:10000]
history = model.fit(partial_x_train,
partial_y_train,
epoches=20,
batch_size=512,
validation_data=(x_val,y_val)) # 使用history接收训练记录,history的history是一个字典,内含有训练数据及验证数据的损失和准确率 8.作图查看训练情况
import matplotlib.pyplot as plt
epoches = [i for i in range(1,len(history.history['loss'])] # 生成横轴数值列表
plt.plot(epoches,history.history['loss'],'bo',label='train_loss')
plt.plot(epoches,history.history['val_loss'],'b',label='val_loss')
plt.title('train and validation loss')
plt.xlabel('epoches')
plt.ylabel('loss')
plt.legend()
plt.show()根据训练情况确定最优训练轮数和其他超参数,然后使用整个25000个训练数据进行训练。
再对测试集评估
network.evaluate(x_test,y_test)也可以进行预测
pred = network.predict_classes(x_test)
pred = pred.reshape(-1) # 二维张量转化为一维张量9.混淆矩阵评估
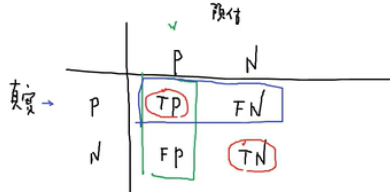


import pandas as pd
pd.crosstab(y_test,pred,rownames=['label'],conames=['predict'] # 统计数量
from sklearn.metrics import classfication_report
print(classfication_report(y_test,pred)) # 打印混淆矩阵















 2098
2098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









