







一个随机过程的自相关函数
我们按照如下定义计算一个随机过程的自相关函数:
R
(
t
1
,
t
2
)
=
E
{
X
(
t
1
)
X
(
t
2
)
}
=
∫
−
∞
+
∞
∫
−
∞
+
∞
x
1
x
2
f
(
x
1
,
x
2
,
t
1
,
t
2
)
d
x
1
d
x
2
R(t_1,t_2)=E\{X(t_{1})X(t_{2})\}=\int^{+\infty}_{-\infty}\int^{+\infty}_{-\infty}x_{1}x_{2}f(x_{1},x_{2},t_{1},t_{2})dx_{1}dx_{2}
R(t1,t2)=E{X(t1)X(t2)}=∫−∞+∞∫−∞+∞x1x2f(x1,x2,t1,t2)dx1dx2
这个表达式说明,即使是同一个连续时间过程,
X
(
t
1
)
X(t_{1})
X(t1)和
X
(
t
2
)
X(t_{2})
X(t2)之间的相关关系仍然需要用一个联合概率分布描述。
但当我们令
t
1
=
t
2
t_{1}=t_{2}
t1=t2时
R
(
t
1
,
t
1
)
=
E
{
X
(
t
1
)
X
(
t
1
)
}
=
∫
−
∞
+
∞
∫
−
∞
+
∞
x
1
x
2
f
(
x
1
,
x
2
,
t
1
,
t
2
)
d
x
1
d
x
2
R(t_1,t_1)=E\{X(t_{1})X(t_{1})\}=\int^{+\infty}_{-\infty}\int^{+\infty}_{-\infty}x_{1}x_{2}f(x_{1},x_{2},t_{1},t_{2})dx_{1}dx_{2}
R(t1,t1)=E{X(t1)X(t1)}=∫−∞+∞∫−∞+∞x1x2f(x1,x2,t1,t2)dx1dx2
上式是否正确?
回答是否定的,它实际上应该写作:
R
(
t
1
,
t
1
)
=
E
{
X
(
t
1
)
X
(
t
1
)
}
=
E
{
X
2
(
t
1
)
}
=
∫
−
∞
+
∞
x
2
f
(
x
,
t
1
)
d
x
R(t_1,t_1)=E\{X(t_{1})X(t_{1})\}=E\{X^{2}(t_{1})\}=\int^{+\infty}_{-\infty}x^{2}f(x,t_{1})dx
R(t1,t1)=E{X(t1)X(t1)}=E{X2(t1)}=∫−∞+∞x2f(x,t1)dx
对于
X
(
t
1
)
X(t_{1})
X(t1)的自乘取期望,那么在期望号中的
X
(
t
1
)
X
(
t
1
)
X(t_{1})X(t_{1})
X(t1)X(t1)如果考察前面一项的变化,那么后面一项的取值将是确定的。
数学期望与自由度
观察数学期望的定义:
E
{
X
}
=
∫
−
∞
+
∞
x
f
(
x
)
d
x
E
{
X
Y
}
=
∫
−
∞
+
∞
∫
−
∞
+
∞
x
y
f
(
x
,
y
)
d
x
d
y
\begin{aligned} E\{X\}&=\int^{+\infty}_{-\infty}xf(x)dx\\ E\{XY\}&=\int^{+\infty}_{-\infty}\int^{+\infty}_{-\infty}xyf(x,y)dxdy \end{aligned}
E{X}E{XY}=∫−∞+∞xf(x)dx=∫−∞+∞∫−∞+∞xyf(x,y)dxdy
我们发现其实可以用类似“自由度”的概念来判断期望的积分该积几次,对于
E
{
X
2
}
E\{X^{2}\}
E{X2}只有一个自由变量,所以和
E
{
X
}
E\{X\}
E{X}一样只对
x
x
x的所有可能取值积分一次,而对于
E
{
X
Y
}
E\{XY\}
E{XY}有两个自由变量,要对
x
,
y
x,y
x,y的所有可能分别积分。这里的“自由”指的应该指变量间没有函数关系。
联合分布的意义
为什么我们需要定义联合分布
f
(
x
,
y
)
f(x,y)
f(x,y)?或者更根本的说,我们为什么要定义联合分布函数
F
(
x
,
y
)
F(x,y)
F(x,y)?联合分布在描述什么?我们从定义入手去研究:
F
(
x
,
y
)
=
P
(
X
≤
x
,
Y
≤
y
)
F(x,y)=P(X\leq x,Y\leq y)
F(x,y)=P(X≤x,Y≤y)
有一个很关键的问题需要区分,这也是在《信息论与编码》课上出现的一个问题,就是
P
(
X
≤
x
,
Y
≤
y
)
P(X\leq x,Y\leq y)
P(X≤x,Y≤y)这种写法该如何理解?
也即
{
X
≤
x
}
\{X\leq x\}
{X≤x}和
{
Y
≤
y
}
\{Y\leq y\}
{Y≤y}这两个东西是什么,它们之间的逗号又做如何解释?
- { X ≤ x } \{X\leq x\} {X≤x}和 { Y ≤ y } \{Y\leq y\} {Y≤y}这两个东西是事件,或者说是基本事件集
- 逗号应该解释为基本事件集的交
- 研究联合分布其实研究的是两个不同的概率映射之间的关系
随机变量其实是为每个基本事件指定的一个数,两种映射之间其实有一定的相关关系,而非函数定义下的决定关系,这种相关关系可以用条件概率描述:
P
(
X
≤
x
,
Y
≤
y
)
=
P
(
X
≤
x
)
P
(
Y
≤
y
∣
X
≤
x
)
P(X\leq x,Y\leq y)=P(X\leq x)P(Y\leq y|X\leq x)
P(X≤x,Y≤y)=P(X≤x)P(Y≤y∣X≤x)
如果:
P
(
Y
≤
y
∣
X
≤
x
)
=
P
(
Y
≤
y
)
P(Y\leq y|X\leq x)=P(Y\leq y)
P(Y≤y∣X≤x)=P(Y≤y),
X
X
X与
Y
Y
Y独立
离散随机过程的二维概率分布
随机过程的定义如下:

对于离散的随机变量,它的样本空间中的基本事件有可列多个,因此我们制定了可列多个函数
X
i
(
t
)
X_{i}(t)
Xi(t)给样本空间中的每一个元素
e
i
e_{i}
ei。
离散随机过程的二维概率密度有如下的定义:
F
X
(
x
1
,
x
2
,
t
1
,
t
2
)
=
∑
i
∑
j
P
(
X
(
t
1
)
=
X
i
(
t
1
)
≤
x
1
,
X
(
t
2
)
=
X
j
(
t
2
)
≤
x
1
)
F_{X}(x_1,x_2,t_1,t_2)=\sum_{i}\sum_{j}P(X(t_1)=X_{i}(t_1)\leq x_1,X(t_2)=X_{j}(t_2)\leq x_1)
FX(x1,x2,t1,t2)=i∑j∑P(X(t1)=Xi(t1)≤x1,X(t2)=Xj(t2)≤x1)
接下来的问题是我们要理解基于如下解释的简化:
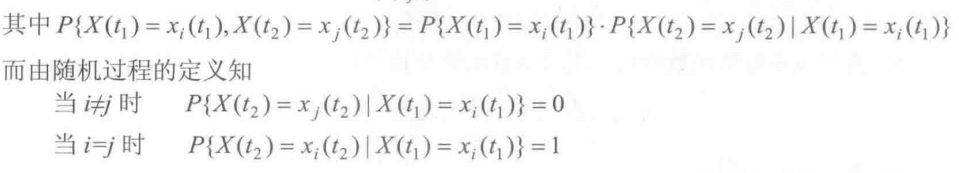
于是可以简化为:
F
X
(
x
1
,
x
2
,
t
1
,
t
2
)
=
∑
i
P
(
X
(
t
1
)
=
X
i
(
t
1
)
≤
x
1
,
X
(
t
2
)
=
X
i
(
t
2
)
≤
x
1
)
=
∑
i
P
(
X
(
t
1
)
=
X
i
(
t
1
)
)
u
(
x
1
−
X
i
(
t
1
)
,
x
2
−
X
i
(
t
2
)
)
\begin{aligned} F_{X}(x_1,x_2,t_1,t_2)&=\sum_{i}P(X(t_1)=X_{i}(t_1)\leq x_1,X(t_2)=X_{i}(t_2)\leq x_1)\\ &=\sum_{i}P(X(t_1)=X_{i}(t_1))u(x_1-X_{i}(t_1),x_2-X_{i}(t_2)) \end{aligned}
FX(x1,x2,t1,t2)=i∑P(X(t1)=Xi(t1)≤x1,X(t2)=Xi(t2)≤x1)=i∑P(X(t1)=Xi(t1))u(x1−Xi(t1),x2−Xi(t2))
理解的关键在于承认取定一个基本事件 e i e_{i} ei对应的函数 X i ( t ) X_{i}(t) Xi(t)后,我们想要保证集合的交 X ( t 1 ) = X i ( t 1 ) ≤ x 1 , X ( t 2 ) = X j ( t 2 ) ≤ x 1 X(t_1)=X_{i}(t_1)\leq x_1,X(t_2)=X_{j}(t_2)\leq x_1 X(t1)=Xi(t1)≤x1,X(t2)=Xj(t2)≤x1的非空,则需要在 X ( t 2 ) X(t_2) X(t2)处义无反顾的选择 X i ( t ) X_{i}(t) Xi(t)并取其 t 2 t_2 t2时刻的值,这样才能仍然取基本事件 e i e_{i} ei,使集合的交的结果为 { e i } \{e_i\} {ei},这是个非零概率事件,我们就得到了非零概率。
换种说法,在 X ( t 1 ) = X i ( t 1 ) X(t_1)=X_{i}(t_1) X(t1)=Xi(t1)取出的集合 { e i } \{e_{i}\} {ei}中 X ( t 2 ) = X j ( t 2 ) , j ≠ i X(t_2)=X_{j}(t_2),j\neq i X(t2)=Xj(t2),j̸=i对应的事件 { e j } \{e_{j}\} {ej}出现的概率为 P ( X ( t 2 ) = X j ( t 2 ) ∣ X ( t 1 ) = X i ( t 1 ) ) = 0 P(X(t_2)=X_{j}(t_2)|X(t_1)=X_{i}(t_1))=0 P(X(t2)=Xj(t2)∣X(t1)=Xi(t1))=0
随机变量与其自身的联合概率
随机变量
X
X
X和
X
X
X之间的关系,两者在取数时永远会取同一个数,记
X
X
X是定义在基本事件空间为
Ω
=
⋃
i
=
1
n
{
a
i
}
\Omega=\bigcup^{n}_{i=1}\{a_{i}\}
Ω=⋃i=1n{ai}因此
P
(
X
≤
x
,
X
≤
y
)
=
∑
i
∑
j
P
(
X
=
x
i
≤
x
,
X
=
x
j
≤
y
)
=
∑
i
P
(
X
=
x
i
≤
x
,
X
=
x
i
≤
y
)
\begin{aligned} P(X\leq x,X\leq y)&=\sum_{i}\sum_{j}P(X=x_{i}\leq x,X=x_{j}\leq y)\\ &=\sum_{i}P(X=x_i\leq x,X=x_i\leq y) \end{aligned}
P(X≤x,X≤y)=i∑j∑P(X=xi≤x,X=xj≤y)=i∑P(X=xi≤x,X=xi≤y)
这里解释一下
X
=
x
i
≤
x
X=x_{i}\leq x
X=xi≤x这种写法的意义,
X
=
x
i
X=x_{i}
X=xi表明我在X的各种取值中选择了
x
i
x_{i}
xi这一个取值,并用该取值与
x
x
x进行比较,如果满足
x
i
≤
x
x_{i}\leq x
xi≤x,则
a
i
∈
{
X
≤
x
}
a_{i}\in \{X\leq x\}
ai∈{X≤x},写成这种形式是为了考察单次实现的情况。
相同变量看做两个不同的单次实现时,在联合分布下两个单次实现只有实现的结果相同(两个相同的随机变量取相同的值)下集合的交才不为空集;而不同变量对应的两个单次实验则没有这项硬性要求。我们的实现确定了概率,而我们考察不等式 x i ≤ x x_{i}\leq x xi≤x只是带着概率研究我们赋予的数(或函数)的分布。
(上面这段话我觉得我自己对随机实验的实验结果和随机变量的关系之间还有不清楚的地方)














 1588
1588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









