






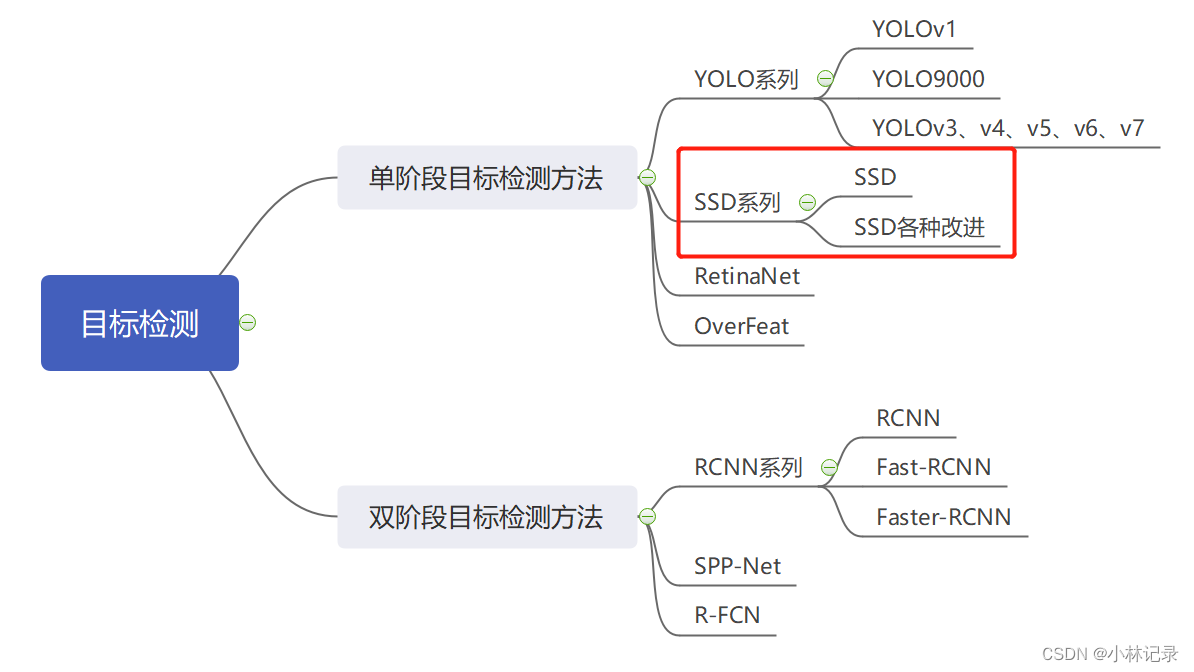
 本文介绍了SSD单阶段目标检测方法,对比了单阶段和双阶段目标检测的优缺点。详细阐述了SSD的模型结构,包括backbone用于提取特征,neck对特征二次加工,head进行最终预测,还说明了head部分预测框处理的具体过程。
本文介绍了SSD单阶段目标检测方法,对比了单阶段和双阶段目标检测的优缺点。详细阐述了SSD的模型结构,包括backbone用于提取特征,neck对特征二次加工,head进行最终预测,还说明了head部分预测框处理的具体过程。
SSD(single shot multi-box detector)
1. 简介
SSD是一种单阶段目标检测方法,如下图所示目标检测方法。
单阶段和双阶段的区别:
- 双阶段第一阶段, 主要是找出目标物体出现的位置,初步得到建议框,这一部分时间花费较长;双阶段第二阶段, 对建议框,进行精确位置回归,和物体的分类。
- 单阶段:不需要建议框,直接进行类别概率和位置坐标值的回归。
因此双阶段的优缺点就是位置更准确,准确率更高;但是时间更久。
单阶段的优缺点就是速度快,但是精确率会有损失。
2. 模型结构
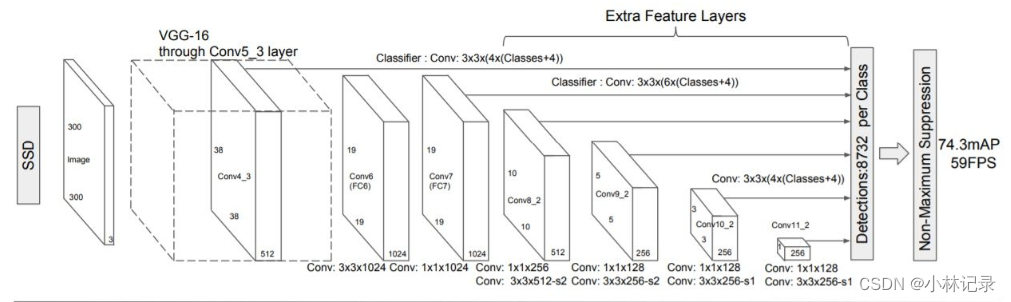
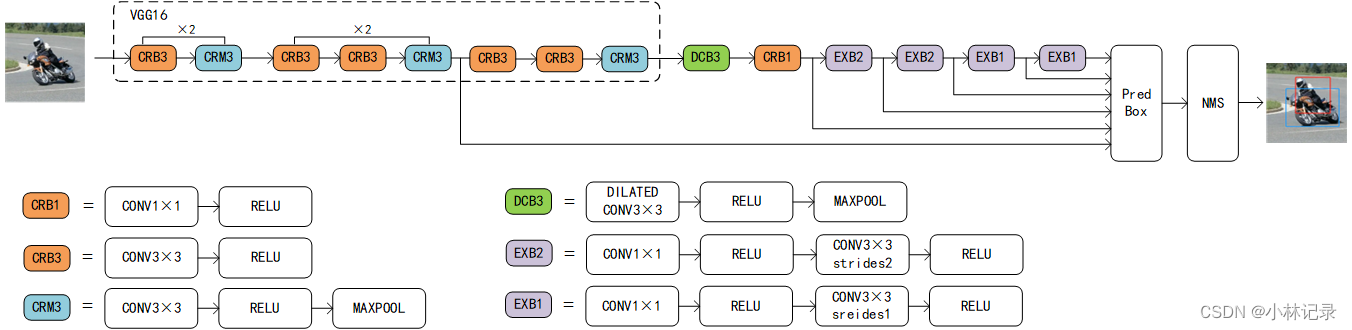
原来的图更突出(上),我重新画了一个图(下),为了突出网络结构内容。
backbone
(1)位置
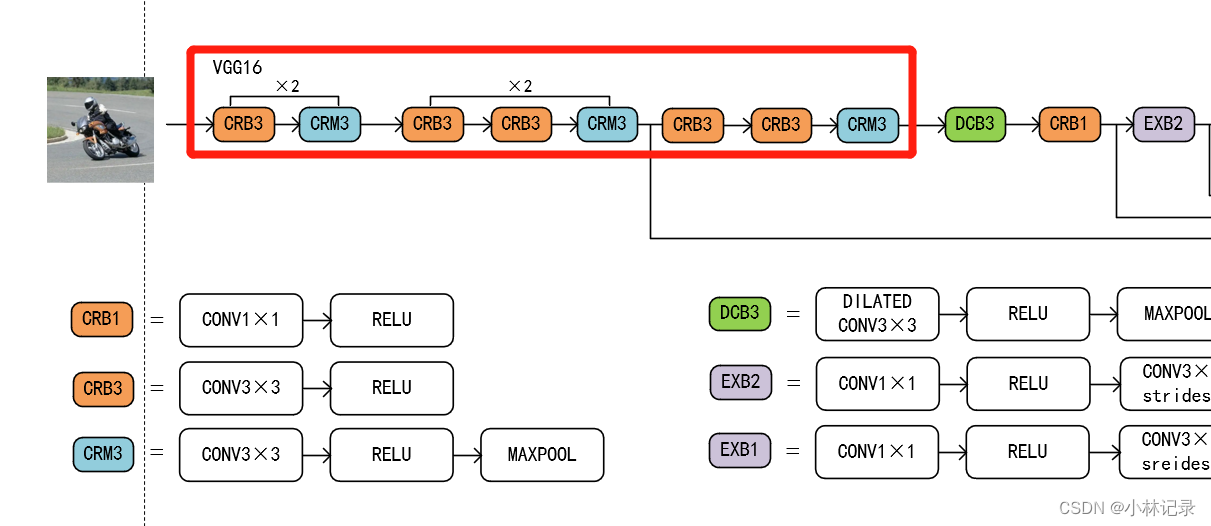
backbone就是背脊的意思,就是上图红框标出的部分。
(2)作用
这一部分的作用就是提取特征,后面预测框位置回归和分类回归,都是基于这一部分提取的特征进行的。
(3)详细信息(以VGG16为例)
这一部分其实就是一个深度卷积神经网络。原始的SSD是以VGG16的conv4_3层输出到预测部分,然后把conv5_3层特征图层输出到下一层。
neck
(1)位置
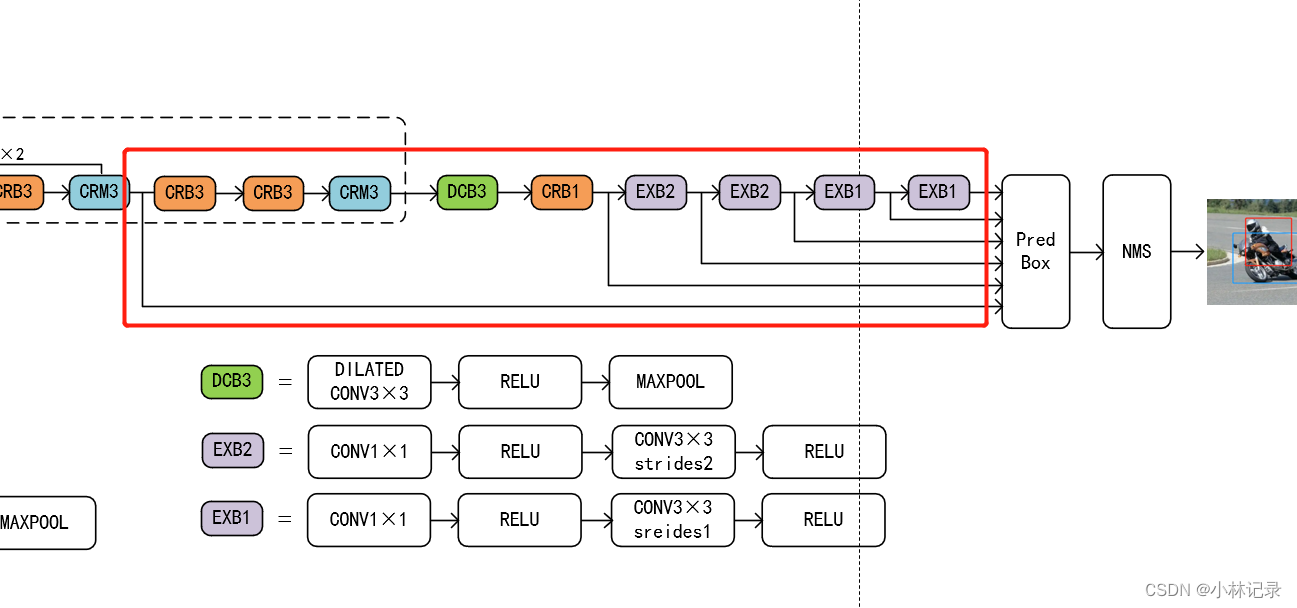
提取特征输出到预测部分之间的部分均可称为Neck。
(2)作用
主要是对提取的特征进行二次加工再给预测部分。这里说的二次加工,如FPN、PAN、深浅层特征融合等。
(3)详细信息
SSD在这一部分主要是对backbone输出的特征进行下采样(1×1的卷积对通道进行压缩,步长为2的3×3卷积进行下采样,相比maxpooling保留更多细节信息),并将各个下采样的特征图层输入到预测部分。
head
(1)位置
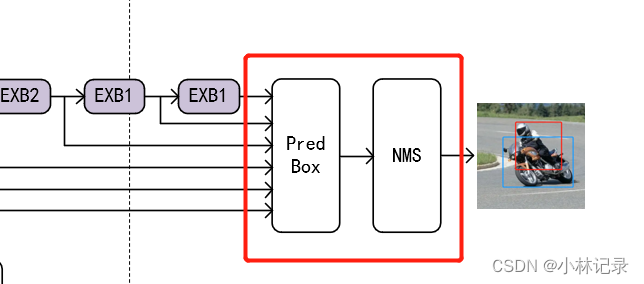
head就是最终的预测部分,输出预测结果。
(2)过程
- 对于每个预测框,首先根据置信度确定类别,并去除类别是背景的框;
- 去除类别置信度低于阈值(自己设定,如0.6)的框;
- 对剩下的预测框进行解码。根据预测的偏置(回归的是位置偏置,不是位置)与先验框位置大小得到位置参数(做clip,防止预测框位置超出图片);
- 对预测框根据置信度进行排列,保留前k个预测框;
- 最后就是进行NMS算法,过滤掉那些重叠度较大的预测框;
- 剩余的预测框就是检测结果。
(3)详细信息
直接对位置偏执和类别置信度进行回归,这就需要卷积出来的特征图层满足大小为 n×n×(a×(4+k))
- n×n就是特征图层每个通道上的大小,因为是以每个像素为锚框进行先验框的标定;
- (a×(4+k))就是通道量:
(1)a就是预测框的数量;
(2)4就是各个偏置 (x,y,w,h);
(3)k就是需要预测的类别数量;

















 4074
4074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









