






 本文详细介绍了如何在AdobePhotoshop中处理中文、日语和朝鲜语等东亚语言文字,涉及字体显示、文字比例、直排与横排、对齐方式、行距调整、避头尾规则和溢出标点等特性。
本文详细介绍了如何在AdobePhotoshop中处理中文、日语和朝鲜语等东亚语言文字,涉及字体显示、文字比例、直排与横排、对齐方式、行距调整、避头尾规则和溢出标点等特性。
Photoshop 提供了多种处理中文、日语和朝鲜语(简称为 CJK)等东亚语言文字的选项。
字体名称显示方式
可在“首选项/文字”中控制字体名称的显示方式,是用英语还是用本国语言。
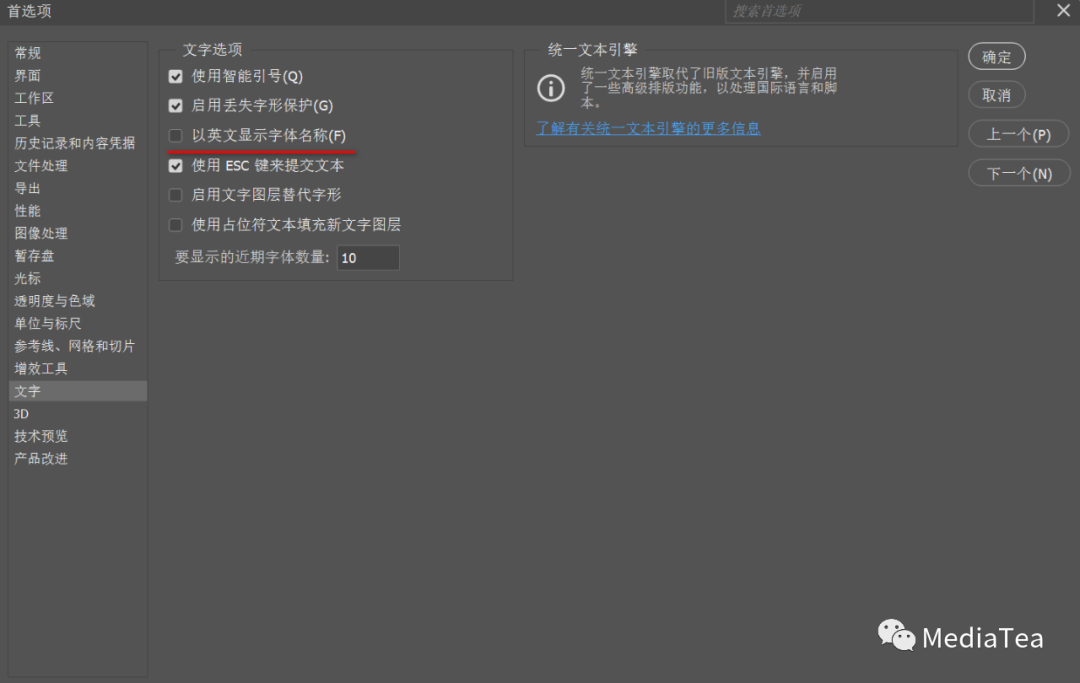
设置文字比例间距
在“字符”面板和文本图层的“属性”面板中,可指定按多少百分比减少 CJK 字符周围的空间。
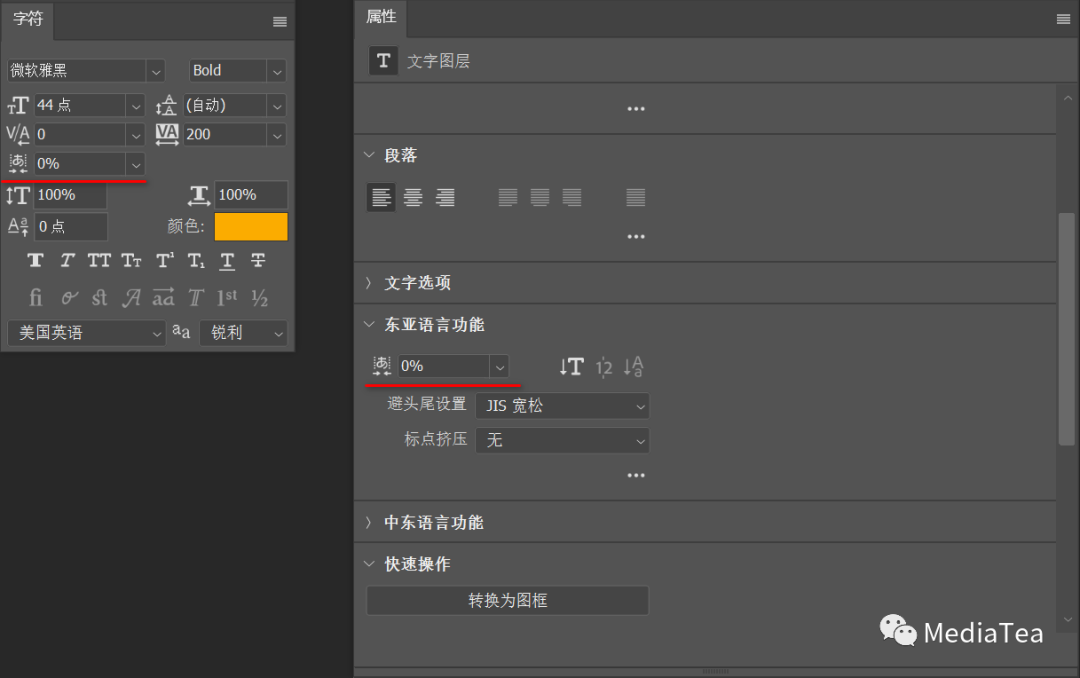
字符本身并不会被伸展或挤压。相反,字符的外框和全角字框之间的间距将被压缩。
使用直排内横排
在“字符”面板的控制菜单和文本图层的“属性”面板中,可将选定的文字块指定在直排文字行中进行横排 Tate-chu-yoko。
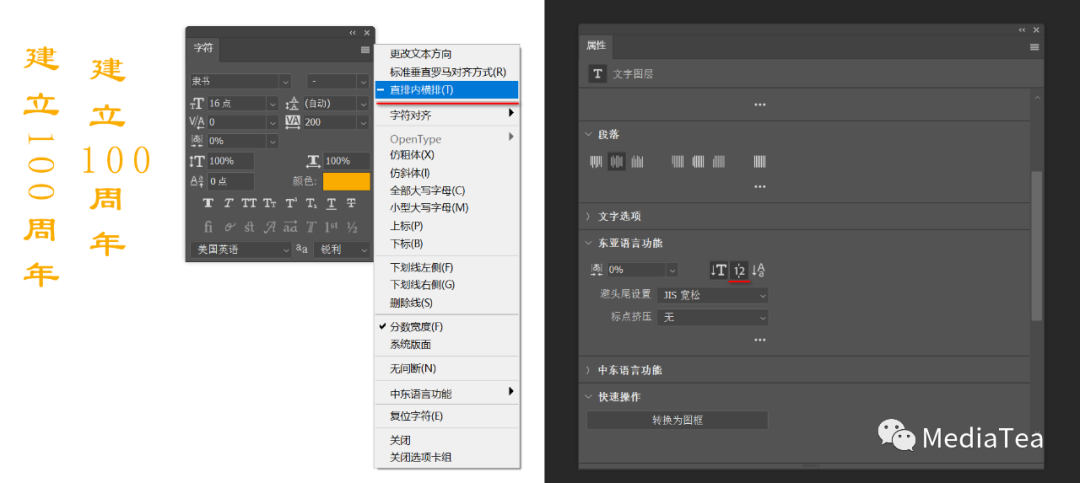
使用直排内横排让在直排文本中阅读半角字符(如数字、日期和简略外文单词)更为轻松。
对齐 CJK 字符
CJK 文字采用的是 Mojisoroe 字符对齐方式。
文本行中包含不同大小的字符时,可以指定文本与行中最大字符的对齐方式。
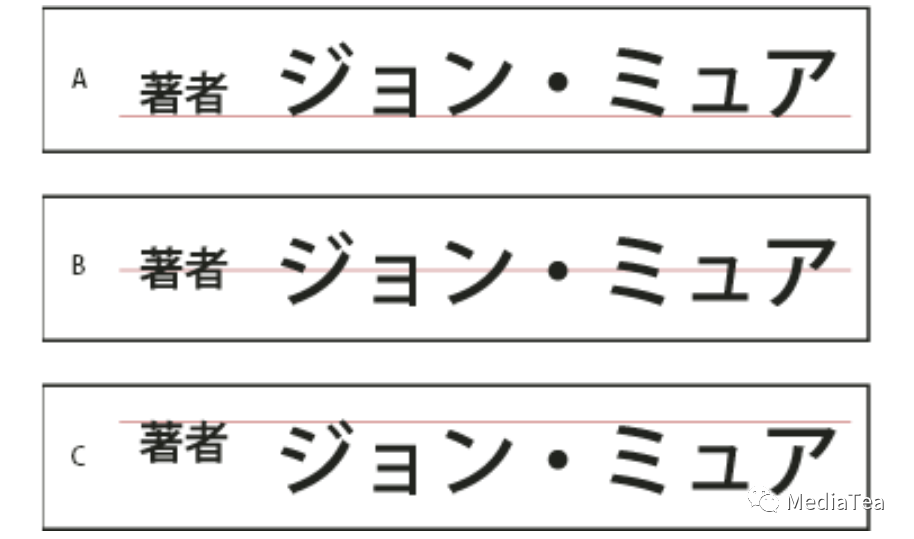
A. 与底边对齐的小字符 B. 居中对齐的小字符 C. 与顶边对齐的小字符
在“字符”面板的控制菜单和文本图层的“属性”面板进行设置。
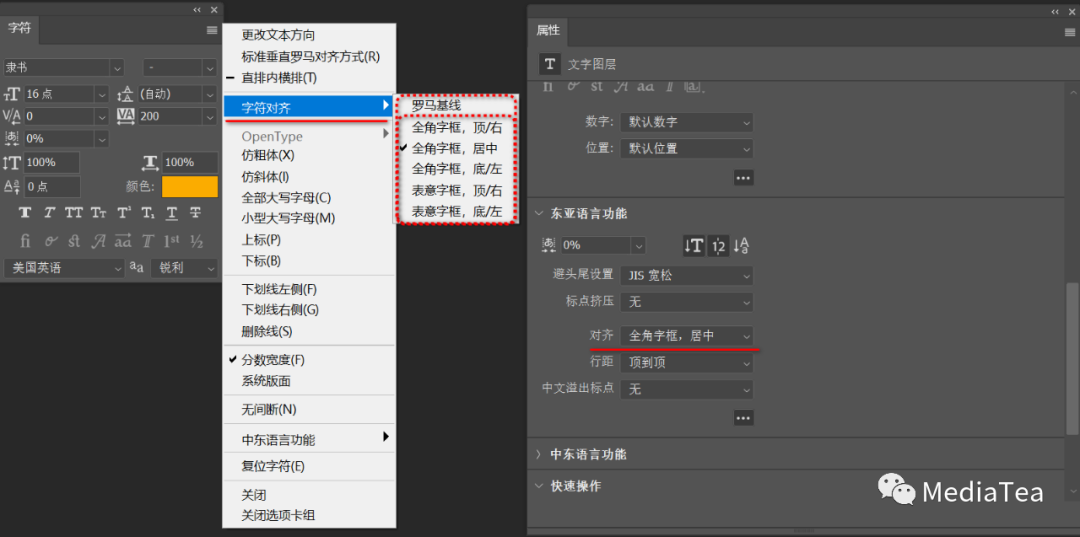
“全角字框” EM Box指的是将文本行中的小字符与大字符全角字框的指定位置对齐。
“表意字框” ICF Box指的是将文本行中的小字符与由大字符指定的表意字框对齐。
提示:
所谓“表意字框”是指字体设计者用于设计构成字体的表意字时所采用的平均高度和宽度。
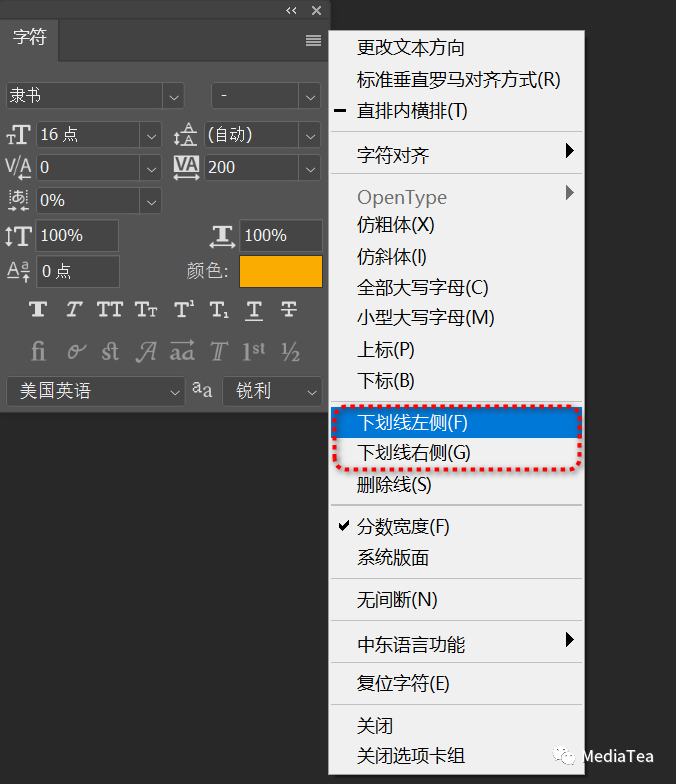
左右下划线
可以在“字符”面板控制菜单中指定直接排文字时的下划线是在左侧还是在右侧。
使用字形面板
可在“字形”面板中设置亚洲 OpenType 字体选项,以及选用替代字形。
请参阅:
《Ps:字形面板》
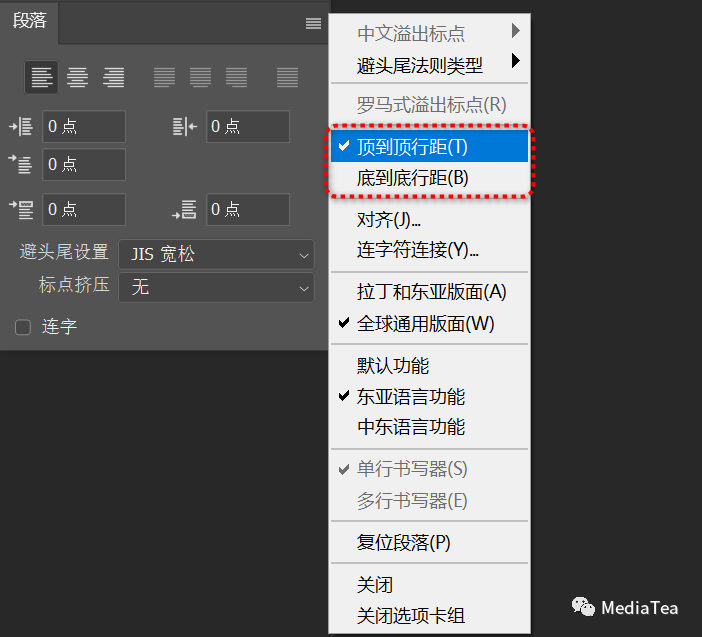
指定测量行距
在“段落”面板控制菜单中,可指定如何在 CJK 文字中测量行距。
提示:
选取的行距选项不影响行距的量,只影响行距的测量方法。
顶到顶行距
Top-to-Top Leading
从一行的顶部到下一行的顶部测量文字行之间的间距。
使用“顶到顶行距”时,段落中的第一行文字会与定界框顶部对齐。
底到底行距
Bottom-to-Bottom Leading
对于横排文字,用于测量行间文字基线之间的间隔。
使用“底到底行距”时,第一行文字与边框之间会出现一定的空白。
间距组合
间距组合为日语字符、罗马字符、标点、特殊字符、行开头、行结尾和数字的间距指定日语文本排版。
Photoshop 包括基于日本行业标准 (JIS) X 4051-1995 的若干预定义间距组合集。
可在“段落”面板控制菜单和文本图层的“属性”面板进行设置。
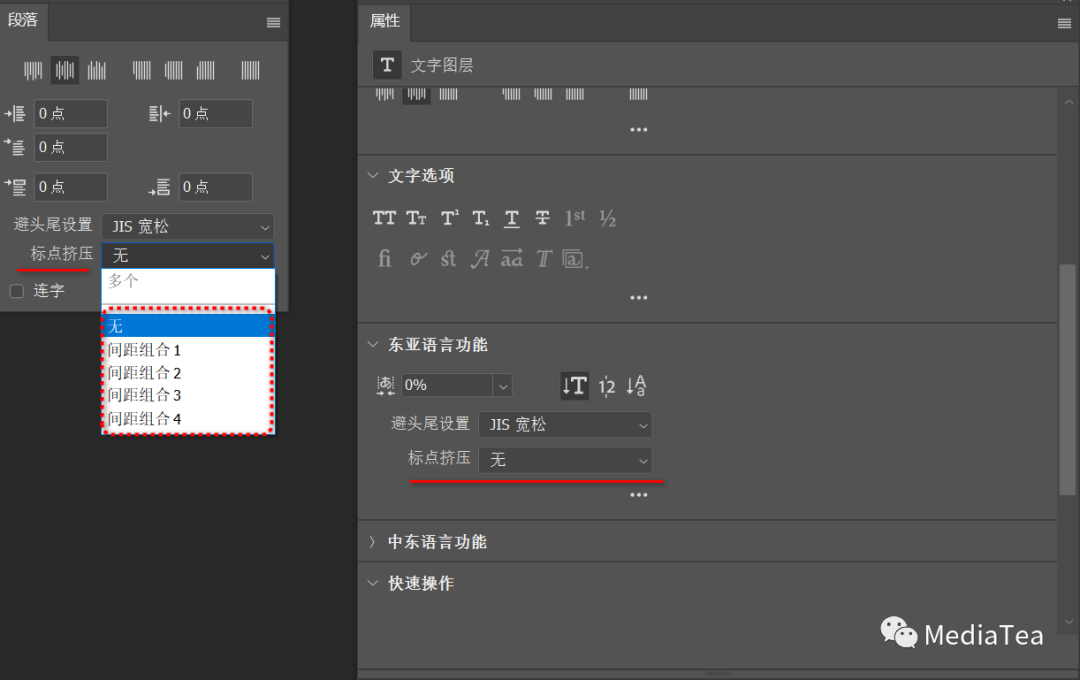
--无
None
不使用间距组合。
--间距组合 1
Mojikumi Set 1
对标点使用半角间距。
--间距组合 2
Mojikumi Set 2
对行中除最后一个字符外的大多数字符使用全角间距。
--间距组合 3
Mojikumi Set 3
对行中的大多数字符和最后一个字符使用全角间距。
--间距组合 4
Mojikumi Set 4
对所有字符使用全角间距。
为段落禁用或启用避头尾法则
避头尾 Kinsoku法则指定日语文本的换行方式。不能出现在一行的开头或结尾的字符称为“避头尾字符”。
Photoshop 提供了基于日本行业标准 (JIS) X 4051-1995 的宽松和严格的避头尾集。
可在“段落”面板控制菜单和文本图层的“属性”面板进行设置。
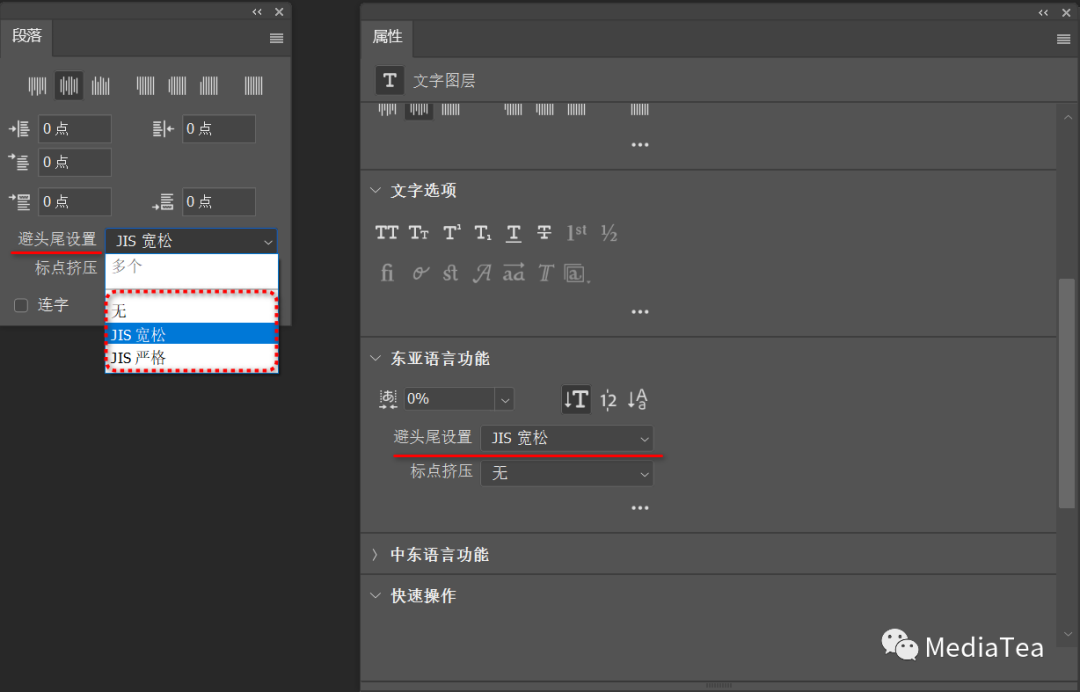
--无
None
不使用避头尾法则。
--JIS 宽松
JJS Weak
--JIS 严格
JJS Maximum
防止在一行的开头或结尾出现指定的字符。相对于 “JJS 宽松”(默认),“JJS 严格”有更多的不能用于行首和行尾的字符。
指定避头尾换行选项
必须选择避头尾法则或间距组合以使用以下的换行选项。
可在“段落”面板控制菜单中进行指定。
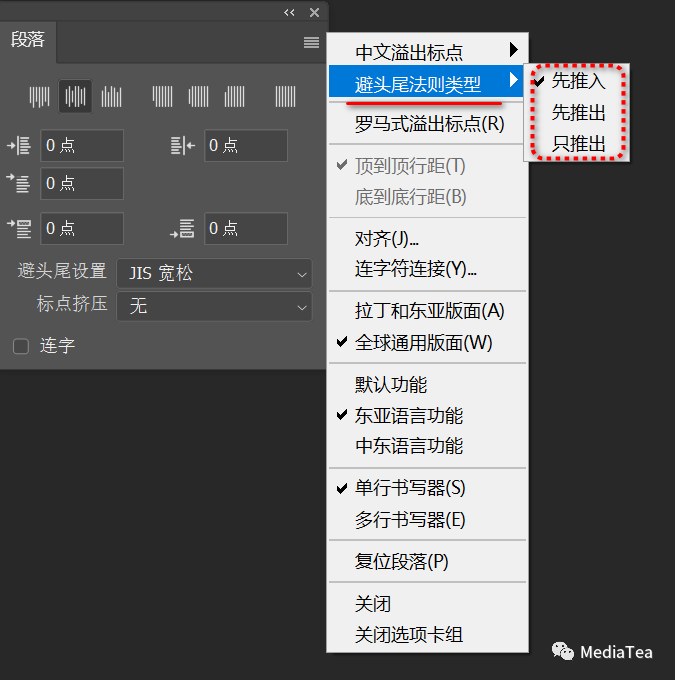
--先推入
Push In First
将字符向上移到前一行,以防止禁止的字符出现在一行的结尾或开头。
--先推出
Push Out First
将字符向下移到下一行,以防止禁止的字符出现在一行的结尾或开头。
--只推出
Push Out Only
总是将字符向下移到下一行,以防止禁止的字符出现在一行的结尾或开头。不会尝试推入。
指定溢出标点选项
溢出标点允许单字节句号、双字节句号、单字节逗号和双字节逗号位于段落定界框外。
可在“段落”面板控制菜单和文本图层的“属性”面板进行设置。
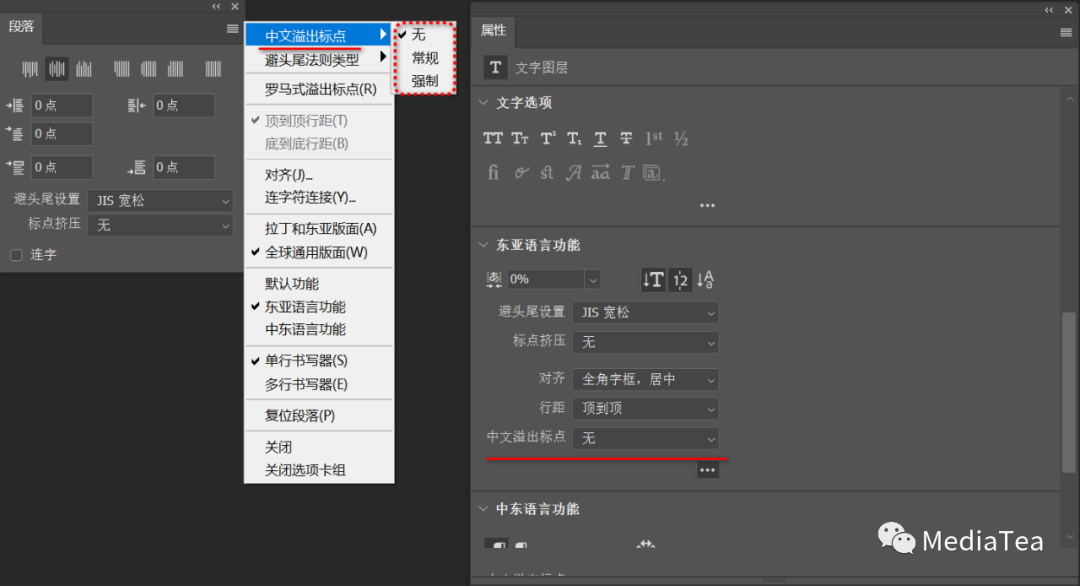
--无
None
关闭溢出标点。
--常规
Regular
打开溢出标点,但对于参差不齐的行,不强制使其位于定界框内。
--强制
Force
通过扩展在定界框内结束的行与以任一溢出字符结束的行,强制使标点符号位于定界框外。
提示:
若将“避头尾法则类型”设置为“无”时,“溢出标点”选项将不可用。

“点赞有美意,赞赏是鼓励”

















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









