






MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
基本信息
博客贡献人
燕青
作者
Andrew G. Howard, Menglong Zhu, Bo Chen, et al.
标签
Depthwise separable convolutions, Light weight deep neural networks
摘要
本文为移动和嵌入式视觉应用提供了一类称为MobileNets的高效模型。MobileNets基于一种精简的架构,使用深度可分离卷积构建轻量级深度神经网络。本文引入了两个简单的全局超参数,可以有效地权衡延迟和准确性。这些超参数允许模型构建者根据问题的约束条件选择合适大小的模型进行应用。本文提供了关于资源和准确性权衡的大量实验,并与其他流行的ImageNet分类模型相比,显示了强大的性能。此外,本文展示了MobileNets在广泛的应用和用例中的有效性,包括目标检测、细粒度分类、人脸属性和大规模地理定位。
问题定义
为了在图像分类领域实现更高的精度,总的趋势是制作更深更复杂的网络。然而,这些提高准确性的进步并不一定使网络在规模和速度方面更加有效。在机器人、自动驾驶汽车和增强现实等许多现实世界的应用中,识别任务需要在计算有限的平台上及时进行。
本文描述了一种高效的网络架构和一组两个超参数,以构建非常小的、低延迟的模型,这些模型可以很容易地匹配移动和嵌入式视觉应用的设计要求。

方法
方法描述
深度可分离卷积
MobileNet模型基于深度可分离卷积,这是一种分解卷积的形式,它将一个标准卷积分解为一个深度卷积和一个称为点卷积的1 × 1卷积。对于MobileNets,深度卷积将单个过滤器应用于每个输入通道。然后使用1 × 1卷积对深度卷积的输出进行合并。一个标准的卷积在一个步骤中将输入滤波并合并成一组新的输出。深度可分离卷积将其分成两层,一个单独的层用于滤波,另一个单独的层用于合并。这种因子分解具有大幅减少计算量和模型规模的效果。
标准卷积层将DF × DF × M特征图F作为输入,生成DF × DF × N特征图G,其中DF为正方形输入特征图1的空间宽度和高度,M为输入通道数(输入深度),DG为正方形输出特征图的空间宽度和高度,N为输出通道数。
标准卷积层采用大小为DK × DK × M × N的卷积核K进行参数化,其中DK为假设为正方形的核的空间维度,M为输入通道数,N为前面定义的输出通道数。
对于标准卷积,假设步长为1和填充,输出特征图的计算公式如下:
G
k
,
l
,
n
=
∑
i
,
j
,
m
K
i
,
j
,
m
,
n
⋅
F
k
+
i
−
1
,
l
+
j
−
1
,
m
G_{k,l,n}=\sum_{i,j,m}K_{i,j,m,n}\cdot F_{k+i-1,l+j-1,m}
Gk,l,n=i,j,m∑Ki,j,m,n⋅Fk+i−1,l+j−1,m
标准卷积计算代价如下:
D
K
⋅
D
K
⋅
M
⋅
N
⋅
D
F
⋅
D
F
D_K\cdot D_K\cdot M\cdot N\cdot D_F\cdot D_F
DK⋅DK⋅M⋅N⋅DF⋅DF
其中,计算成本乘性地依赖于输入通道数M、输出通道数N、卷积核尺寸Dk × Dk和特征图尺寸DF × DF。MobileNet首先使用深度可分离卷积来打破输出通道数和核大小之间的相互影响。
深度可分离卷积由两层组成:深度卷积和点卷积。本文使用深度卷积对每个输入通道应用单个卷积核。然后使用点卷积,简单的1 × 1卷积,创建深度层输出的线性组合。MobileNets对两层都使用批范数和ReLU非线性。
对每个输入通道应用单个卷积核的深度卷积可以写作:
G
^
k
,
l
,
m
=
∑
i
,
j
K
^
i
,
j
,
m
⋅
F
k
+
i
−
1
,
l
+
j
−
1
,
m
\hat{G}_{k,l,m}=\sum_{i,j}\hat{K}_{i,j,m}\cdot F_{k+i-1,l+j-1,m}
G^k,l,m=i,j∑K^i,j,m⋅Fk+i−1,l+j−1,m
深度卷积计算代价如下:
D
K
⋅
D
K
⋅
M
⋅
D
F
⋅
D
F
D_K\cdot D_K\cdot M\cdot D_F\cdot D_F
DK⋅DK⋅M⋅DF⋅DF
相对于标准卷积,深度卷积极其高效。但是它只是对输入通道进行过滤,并没有将它们结合起来产生新的特征。因此,为了生成这些新的特征,需要一个额外的层,通过1 × 1卷积计算深度卷积输出的线性组合。
则深度可分离卷积计算代价如下,即深度卷积和点卷积代价之和:
D
K
⋅
D
K
⋅
M
⋅
D
F
⋅
D
F
+
M
⋅
N
⋅
D
F
⋅
D
F
D_K\cdot D_K\cdot M\cdot D_F\cdot D_F+M\cdot N\cdot D_F\cdot D_F
DK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DF
通过将标准卷积表示为卷积和合并的两步过程,减少了计算量。下图显示了标准卷积 ( a ) 如何分解为深度卷积 ( b ) 和1 × 1点卷积 ( c ) 。
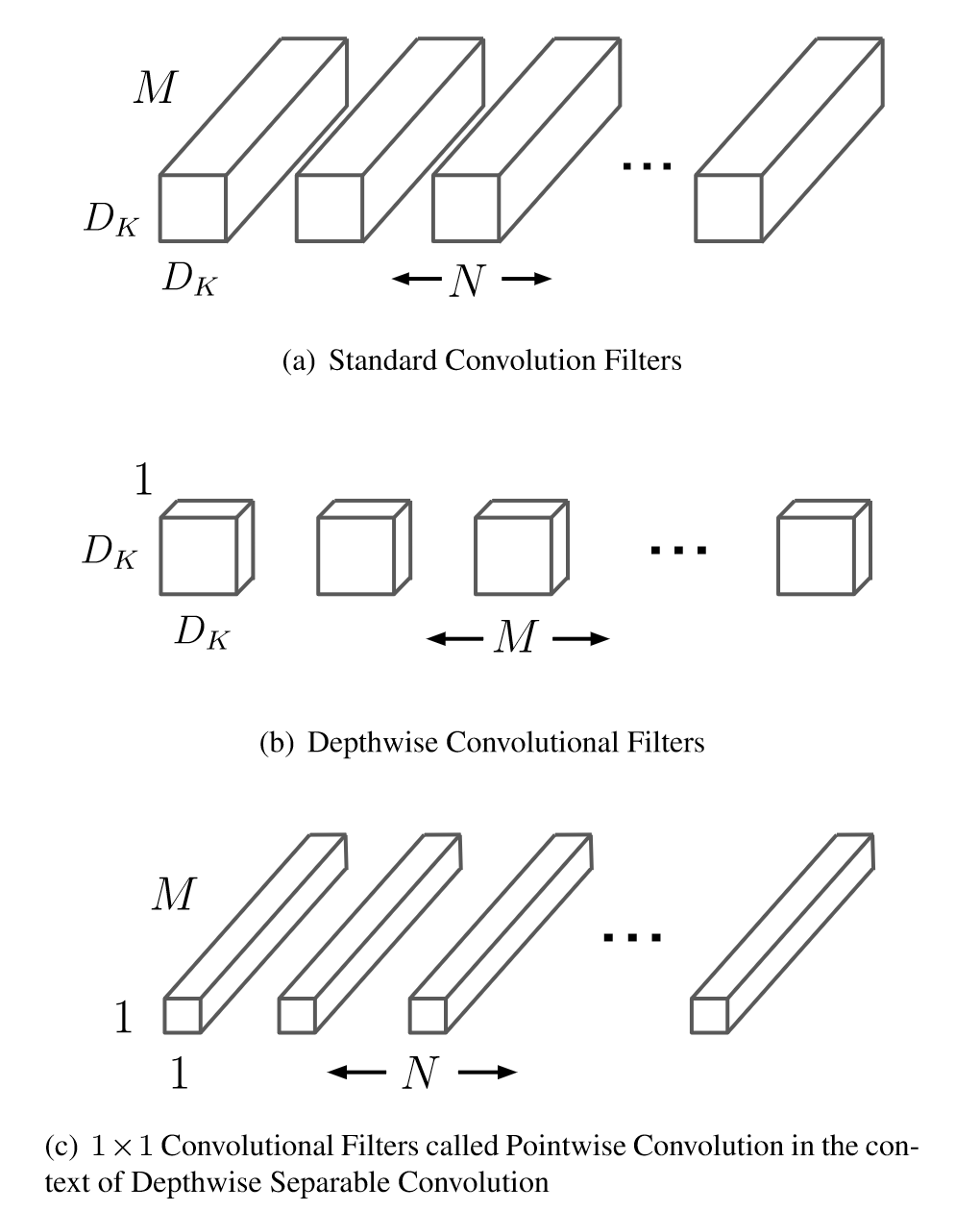
MobileNet使用了3 × 3的深度可分离卷积,其计算量比标准卷积减少了8 ~ 9倍,只是精度略有下降。
下图左侧为带batchnorm和ReLU的标准卷积层。右侧为Depthwise和逐点的层的深度可分离卷积,后接batchnorm和ReLU。
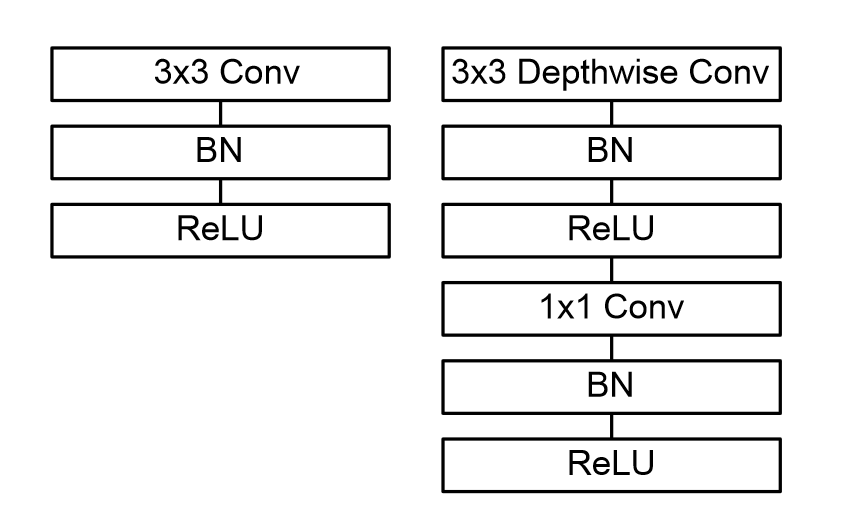
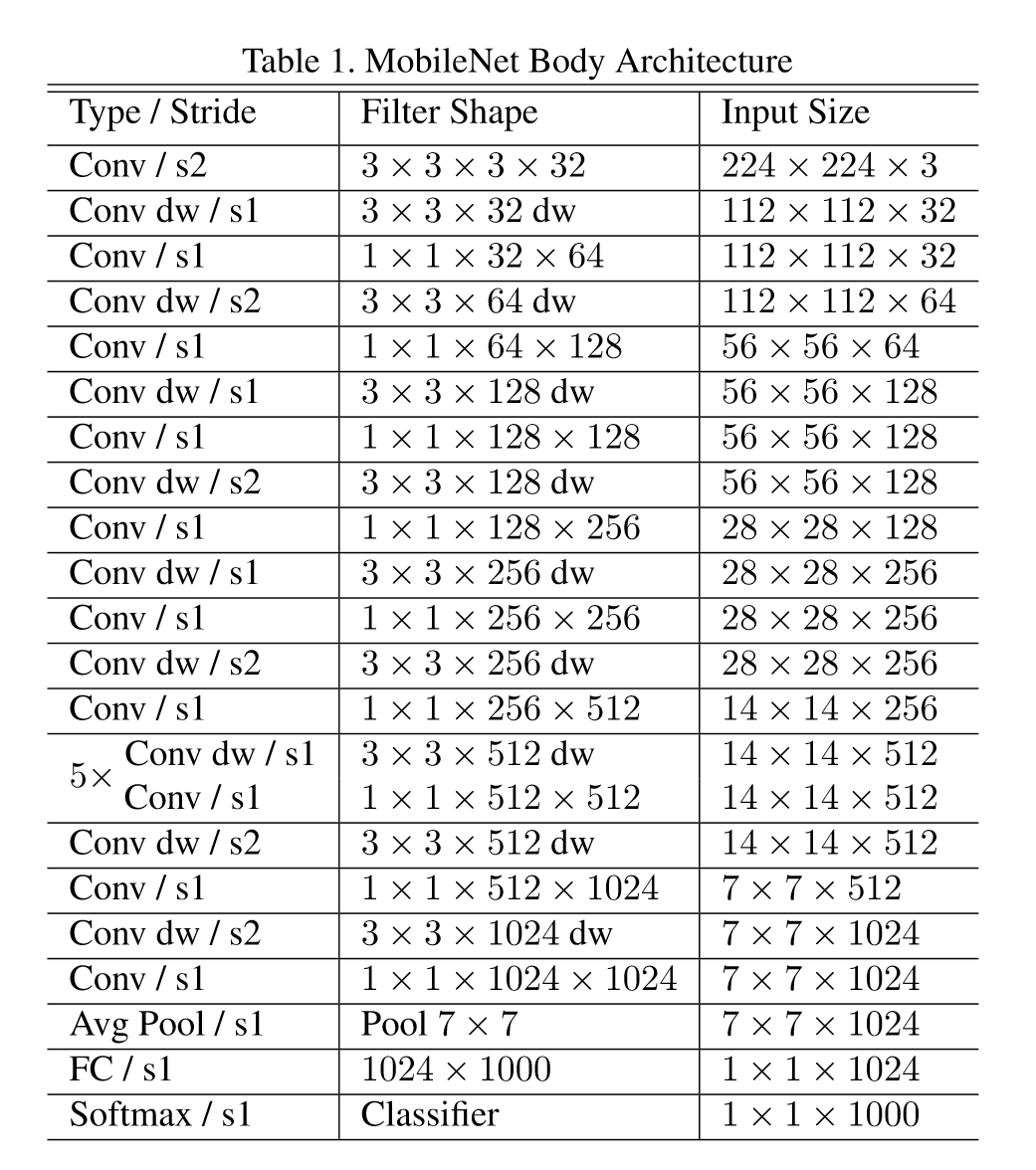
通过用如此简单的形式定义网络,可以很容易地探索网络拓扑以找到一个好的网络。下图为MobileNet网络结构。
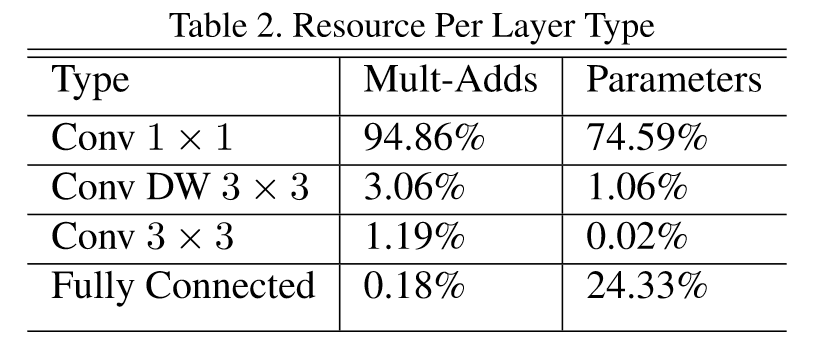
MobileNet中的资源分配:
宽度乘子
虽然基础MobileNet架构已经很小,延迟也很低,但很多时候一个特定的用例或应用可能要求模型更小、更快。为了构造这些更小、计算量更小的模型,本文引入一个非常简单的参数α,称为宽度乘子。宽度乘子α的作用是在每一层均匀稀疏一个网络。对于一个给定的层和宽度乘子α,输入通道数M变为α M,输出通道数N变为α N。
对于带宽度乘子α的深度可分离卷积的计算代价为:
D
K
⋅
D
K
⋅
α
M
⋅
D
F
⋅
D
F
+
α
M
⋅
α
N
⋅
D
F
⋅
D
F
D_K\cdot D_K\cdot \alpha M\cdot D_F\cdot D_F+\alpha M\cdot \alpha N\cdot D_F\cdot D_F
DK⋅DK⋅αM⋅DF⋅DF+αM⋅αN⋅DF⋅DF
其中α∈( 0,1 ],典型设置为1,0.75,0.5和0.25。α = 1为基准MobileNet,α < 1为简化MobileNet。宽度乘子具有将计算成本和参数个数大致减少
α
2
\alpha^2
α2 的效果。宽度乘子可以应用于任何模型结构,以合理的精度、延迟和大小权衡来定义一个新的更小的模型。它用于定义新的缩减结构,需要从头开始训练。
分辨率乘子
降低神经网络计算成本的第二个超参数是分辨率乘子ρ。将其应用于输入图像,每一层的内部表示随后被相同的乘子减少。在实践中,可以通过设置输入分辨率来隐式地设置ρ。
现在可以将网络核心层的计算成本表示为宽度乘子α和分辨率乘子ρ的深度可分离卷积:
D
K
⋅
D
K
⋅
α
M
⋅
ρ
D
F
⋅
ρ
D
F
+
α
M
⋅
α
N
⋅
ρ
D
F
⋅
ρ
D
F
D_K\cdot D_K\cdot \alpha M\cdot \rho D_F\cdot \rho D_F+\alpha M\cdot \alpha N\cdot \rho D_F\cdot \rho D_F
DK⋅DK⋅αM⋅ρDF⋅ρDF+αM⋅αN⋅ρDF⋅ρDF
其中ρ∈( 0,1 ]是典型的隐式设置,使得网络的输入分辨率为224、192、160或128。ρ = 1是基准MobileNet,ρ < 1是减少计算量的MobileNet。分辨率乘法器具有降低计算成本
ρ
2
\rho^2
ρ2 的效果。
实验
本文在实验中首先研究了深度卷积的影响,以及通过减少网络的宽度而不是层数来选择收缩。然后展示了基于两个超参数:宽度乘子和分辨率乘子减少网络的权衡,并将结果与一些流行的模型进行比较。
实验设置
数据集
ImageNet
基准方法
-
VGG16
-
GoogleNet
-
Squeezenet
-
AlexNet
实验结果
参数权衡:
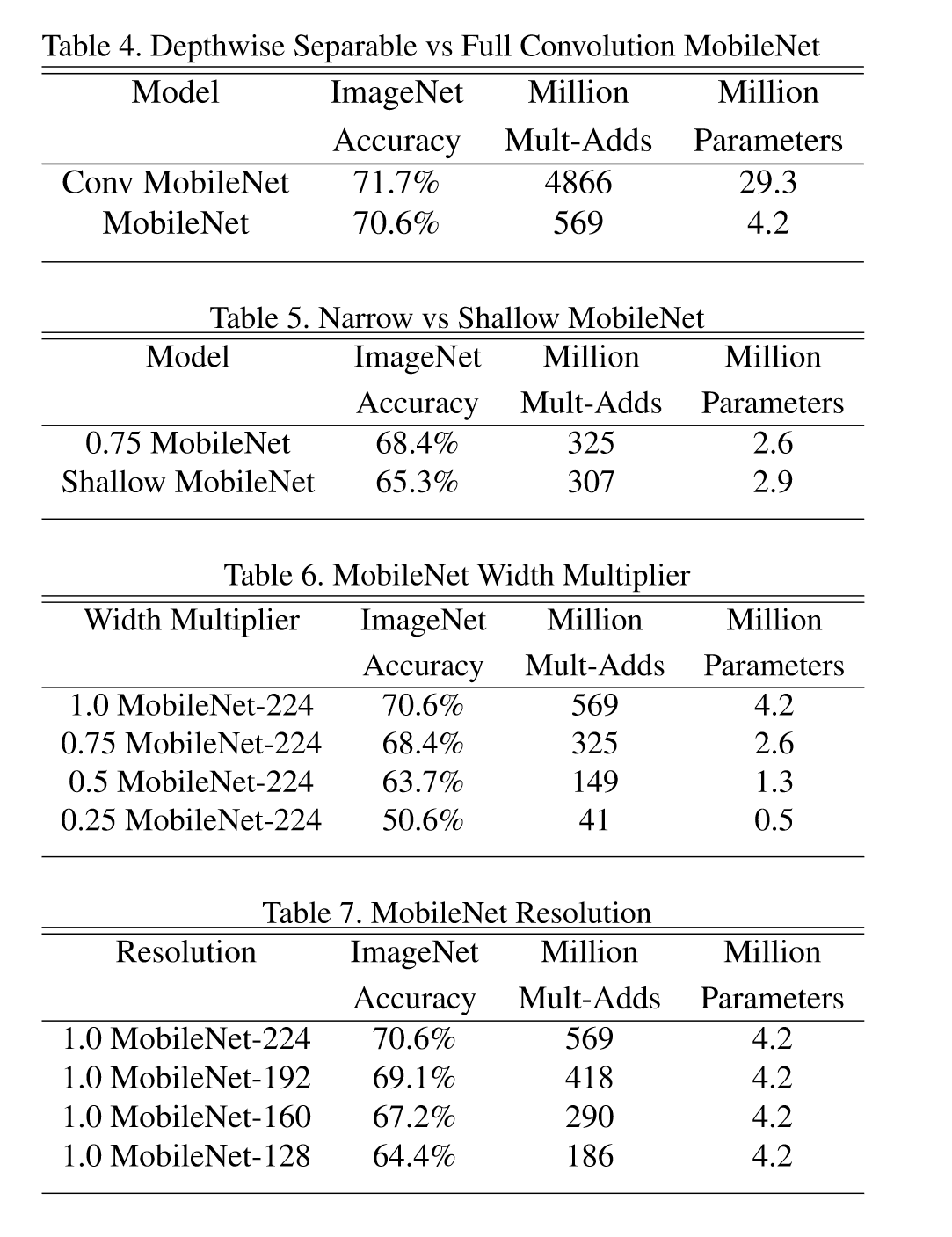
与其它网络对比:
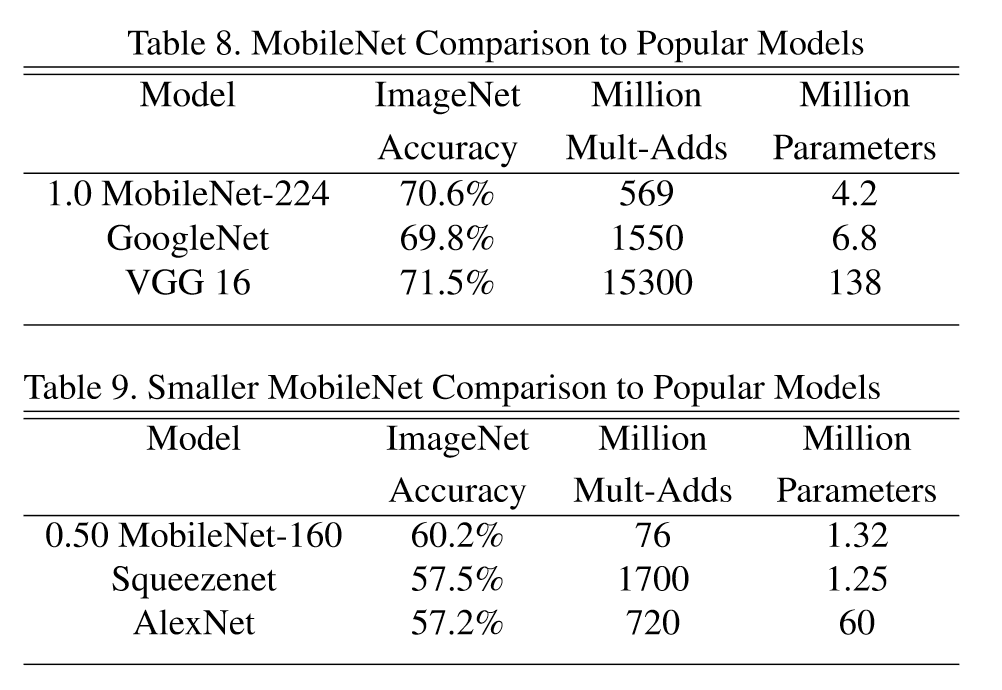
相关知识链接
下载
数据集:ImageNet
基准实验涉及的论文
GoogleNet:Going deeper with convolutions
VGG16:Very Deep Convolutional Networks for Large-Scale Image Recognition
Squeezenet:Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 1mb model size
Alexnet:Imagenet classification with deep convolutional neural networks
相关工作涉及的论文
Rigid-motion scattering for image classification
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Flattened convolutional neural networks for feedforward acceleration
Xception: Deep learning with depthwise separable convolutions
后续研究涉及的论文
V2:MobileNetV2: Inverted Residuals and Linear Bottlenecks
总结
亮点
- 提出深度可分离卷积,将标准卷积分解为深度卷积和点卷积,极大减少卷积计算量和参数量
- 引入2个简单超参数宽度乘子 α \alpha α 和分辨率乘子 ρ \rho ρ ,可以将模型应用于速度更快、参数量更少的场景
[不足]
MobileNet V1是类似于VGG一样的直筒结构。这种结构的性价比其实不高,后续一系列的 ResNet, DenseNet 等结构已经证明通过复用图像特征,使用 Concat/Eltwise+ 等操作进行融合,能极大提升网络的性价比
[启发]
- 深度可分离卷积可以应用于需要提升卷积速度且对性能要求不严格的网络中
- 对于提升网络速度,可以考虑宽度、分辨率两方面的因素
BibTex
@inproceedings{howard2017mobilenets,
Author = {Howard, Andrew G and Zhu, Menglong and Chen, Bo and Kalenichenko, Dmitry and Wang, Weijun and Weyand, Tobias and Andreetto, Marco and Adam, Hartwig},
Title = {Mobilenets: Efficient convolutional neural networks for mobile vision applications},
Booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
Year = {2017}
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









