







pandas教程07 - pandas处理数据NaN缺失值
pandas一站式学习->: pandas一站式学习,创建,索引使用,运算,pd可视化柱状图等,csv,hdf5,json格式数据读取存储,NaN值处理,数据离散化,数据合并,交叉表与透视表
python一站式学习->: python一站式学习,python基础,数据类型,numpy,pandas,机器学习,NLP自然语言处理,deepseek大预言模型,Tensorflow,CV视觉
准备数据
import pandas as pd
# 准备的数据有年龄缺失,实际工作中,数据量巨大,就需要后续得处理
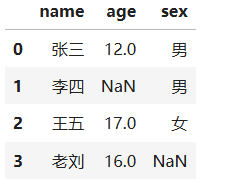
p1 = pd.DataFrame([{"name":"张三","age":12,"sex":"男"},
{"name":"李四","sex":"男"},
{"name":"王五","age":17,"sex":"女"},
{"name":"老刘","age":16}])
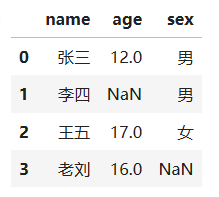
isnull()/ notnull() 判断是否有缺失值
方法一:使用numpy all()、any()判断
import numpy as np
# 缺失值位置数据为True,其他为False
new_p = p1.isnull()
# p1.notnull() 结果相反而已,缺失值位置数据为False,其他为True
# 所有为true才为true
f1 = np.all(p1.isnull())
print(f1)
# 结果 false
# 全都为false才返回false
f2 =np.any(p1.isnull())
print(f2)
# 结果 True
方法二:使用pandas的any,all判断,可以判断每一列NaN情况
# isnull() 缺失值位置数据为True,其他为False
# notnull() 结果相反而已,缺失值位置数据为False,其他为True
# any() # 有一个是True,就返回True
# all() 所有为True,才返回True
new_p = p1.isnull().any() # 有一个是True,就返回True

new_p = p1.isnull().any()

缺失值处理
- 方法一: 删除缺失值的对象
new_p1 = p1.dropna(
axis=0, # 操作方向:0 或 'index' 删除行,1 或 'columns' 删除列
how='any', # 触发删除的条件:'any'(存在 NaN 就删除)或 'all'(全部为 NaN 才删除)
inplace=False # 默认False返回新对象,True直接修改原对象
)
new_p1
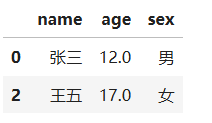
- 方法二: fillna() 缺失值替换
使用平均值,或者中位数等替换
# pd.fillna(num) 替换
# mean()求平均值
# inplace=False # 默认False返回新对象,True直接修改原对象(后续版本可能会删除该操作,推荐使用赋值方式)
p1["age"] = p1["age"].fillna(p1["age"].mean())
p1
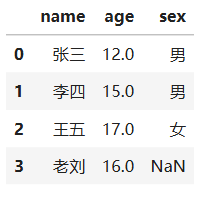
假如缺失值不是NaN,而是一个默认标记
- 处理步骤,先把缺失值替换成NaN,然后再根据NaN,进行后续操作
准备数据
import pandas as pd
p2 = pd.DataFrame([{"name":"张三","age":12,"sex":"男"},
{"name":"李四","age":"?","sex":"男"},
{"name":"王五","age":17,"sex":"女"},
{"name":"老刘","age":16,"sex":"?"}])
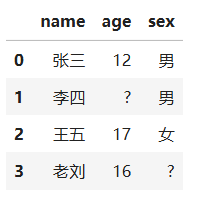
替换自定义缺失值成为NaN
替换完后,按照前面,处理NaN的方式处理缺失值
import pandas as pd
import numpy as np
# to_replace要替换的值,value=替换成为的值
p1.replace(to_replace="?",value=np.nan)

















 1147
1147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









