







1. 作者 来源
UC Berkeley 与 UMass Lowell, 的Eric Tzeng, Judy Hoffman, Ning Zhang
,Kate Saenko,Trevor Darrell
2014 年的一篇paper 好像没有说什么期刊会议上的 链接地址
2.Motivation
在大规模数据集上训练的通用监督深度CNN模型可以减少但不能消除在标准基准测试上的数据集偏差。也就是我们所说的domain adaptation。
3.Model
其提出的架构如图所示他的思想也是非常自然的
- 一部分是希望source domain 和 target domain 通过特征提取的网络可以得到其不变的特征 所以设计的domain loss 应该是让其提取的特征非常接近那么很明显可以使用MSEor L1 loss
- 就是为了保证其分类性能提出的classification loss

目的就是由图像化的解释如下:

Summary:
- 为了让source domain 和 target domain尽量靠近(domain loss)
- 为了保证分类器可以正确分类 (classification loss )
其实 想一想可以发现很多的问题都是在提升第二个目标,大家都是在这个基础上进行修改,因为不管是降维还是风格转换相对来说比较容易进行但是如果保证风格转化或者是降维之后依然可以有比较好的分类效果才是真正的比较困难和值得探究的问题。
4.contribution
- 提出了共同优化也就是上述的结构,取得了当时sota的结果
- 使用的混淆距离是maximum mean discrepancy(MMD)
原文的思考过程
仅使用源数据直接训练分类器往往会导致对源分布的过拟合,导致在目标域中识别时在测试时的性能降低。我们的直觉是,如果我们能学习一种使源分布和目标分布之间的距离最小化的表示,那么我们就可以在源标记数据上训练一个分类器,并直接将其应用于目标域,且精度损失最小。
其实重点就是MMD是什么?
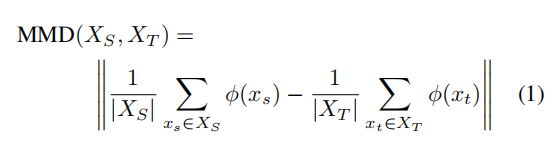
视频介绍
我也只是一只半懂,感谢GAN的提出,为我们做迁移学习的减少了痛苦。
5.Results
结果当然是比较好的了 因为时间比较久远 我就不详细分析了















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









