







Transformer Tracking
一、贡献
- 提出了一种新的Transformer跟踪框架,包括特征提取、基于Transformer的特征融合网络和预测头模块。
- 基于具有自我注意的自我上下文增强模块和具有交叉注意的交叉特征增强模块开发了特征融合网络。与基于相关的特征融合相比,我们的注意力融合方法自适应地聚焦于边缘和相似目标等有用信息,并在距离较远的特征之间建立关联,使跟踪器获得更好的分类和回归结果。
二、网络框架

在这里我将就整个框架进行介绍:
首先特征提取我们修改了ResNet50网络结构,具体是移除看网络的最后一阶段并将第四阶段的结果作为最后的结果,并且将第四阶段的降采样单元的卷积步幅由2改变为1,以获得更大的特征分辨率,以及3×3卷积修改为步长为2的扩张卷积以获得更大的感受野。
特征提取后的1×1卷积主要是为了减少通道数,减少运算量,之后压缩其维度由
C
×
H
×
W
C×H×W
C×H×W到
C
×
H
W
C×HW
C×HW,使其为HW个维度为C的向量。
截下来就是特征融合网络了,这部分也是核心部分了,将transformer中的自我注意力和交叉注意力应用在该网络中来融合模板信息。
最后就是预测头网络了,该网络包括分类分支和回归分支,分别预测HW个分别得分和边界框,跟踪器直接预测的边界框的归一化坐标。
ECA和CFA
结构:

首先先说一下多头注意力机制,给出注意力函数
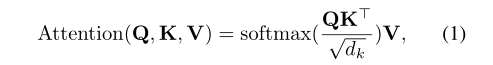
其中由于要对矩阵进行softmax归一化,破坏了原来的标准正态分布,因此要除以
s
q
r
t
(
d
k
)
sqrt(d_k)
sqrt(dk)使其满足标准正态分布。
紧接着给出多头注意力公式:
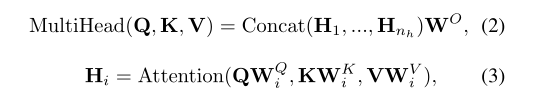
大致的思路就是根据原有的Q,K,V,分别划分出i个矩阵,然后按照上面的注意力公式分别求出i个结果,在将这i个矩阵合并得到最后的输出结果。这样可以考虑各种注意分布,使模型关注信息的不同方面。
下面将介绍ECA
由于注意力机制对于特征序列的位置信息没有区分能力,所以加入了位置编码,ECA的数学公式如下:

最后就是CFA
这里和ECA基本一致,为了增强模型的拟合能力,所以加入了一个FFN模块,它是由两个线性变换组成的全连通前馈网络,中间有一个relu函数,数学表达如下:

CFA的数学表达如下:
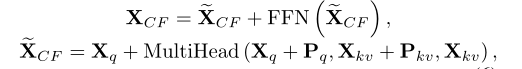
三、损失函数
分类损失:
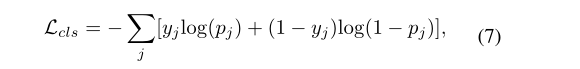
回归损失:
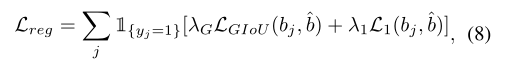
四、实验结果
















 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









