







PSO的算法配置
粒子的速度更新公式: v i ( t + 1 ) = v i ( t ) + c 1 ⋅ r 1 ( t ) ⋅ [ y i ( t ) − x i ( t ) ] + c 2 ⋅ r 2 ( t ) ⋅ [ y ^ i ( t ) − x i ( t ) ] \mathbf v_{i}(t+1)=\mathbf v_{i}(t)+c_1\cdot \mathbf r_{1}(t)\cdot [\mathbf y_{i}(t)-\mathbf x_{i}(t)]+c_2\cdot \mathbf r_{2}(t)\cdot [\hat \mathbf y_{i}(t)-\mathbf x_{i}(t)] vi(t+1)=vi(t)+c1⋅r1(t)⋅[yi(t)−xi(t)]+c2⋅r2(t)⋅[y^i(t)−xi(t)]。
粒子初始化
PSO的第一步便是对粒子群和控制参数的初始化,即对加速度常数 c 1 , c 2 c_1,c_2 c1,c2、初始速度、粒子位置及个体最优位置的指定,对于 l − b e s t l-best l−bestPSO,还需确定邻居的规模。
通常,粒子的初始位置均匀分布在整个搜索空间的,这对确保初始解的多样性,即覆盖更多的搜索空间是很重要的;粒子群优化算法只有在粒子的动量携带粒子进入未被发现的区域时才能发现这种最优解,前提是粒子要么获得一个新的个体最优解,要么获得一个新的全局最优解。假定最优解位于两个向量 x m i n , x m a x \mathbf x_{min},\mathbf x_{max} xmin,xmax之间,其代表每个维度上的最大值和最小值,那么一个有效的初始化方法是: x j ( 0 ) = x m i n , j + r j ⋅ ( x m a x , j − x m i n , j ) , ∀ j = 1 , ⋯ , n x x_j(0)=x_{min,j}+r_j\cdot(x_{max,j}-x_{min,j}),\;\;\forall j=1,\cdots,n_x xj(0)=xmin,j+rj⋅(xmax,j−xmin,j),∀j=1,⋯,nx,其中 r j ∼ U ( 0 , 1 ) r_j\sim U(0,1) rj∼U(0,1)。
初始速度可设置为 0 或一个随机值(需注意)。当初始速度为 0 时,类比与物理空间即对象是静态的;当非 0 时,随机初始的速度不能太大,因为粒子的初始位置和方向也是随机的,大的初始速度则表示有一个大的动量,这就会造成在迭代早起就会产生大步的位置更新,这样有可能使得粒子越过搜索空间的边界,使得解决一个简单的问题但却需要更多次迭代。
初始时粒子个体的最佳位置是在 t=0 时的粒子位置: y i ( 0 ) = x i ( 0 ) \mathbf y_i(0)=\mathbf x_i(0) yi(0)=xi(0)。粒子的初始位置均匀分布在整个搜索空间的,但在解决实际问题是,使用均匀分布却并不一定是好的,在此不做详细叙述。
终止条件
在确定终止条件时需要考虑以下两个方面:
1.终止条件不能使PSO过早收敛,陷入局部最优解;
2.终止条件应当预防适应度的过采样。如果终止条件需要频繁计算适应度,那么整个搜索过程的计算复杂度就会大大增加。
因此,终止条件可设置为:
- 最大迭代次数(需要评估算法取得最优解所需的时间);
- 当得到一个可接受的解(即在一个可接受的误差范围之内),记 x ∗ \mathbf x^* x∗ 为最优解,若搜索到一个解 x i \mathbf x_i xi,使得 f ( x i ) < ∣ f ( x ∗ ) − ϵ ∣ f(\mathbf x_i)<|f(\mathbf x^*)-\epsilon| f(xi)<∣f(x∗)−ϵ∣ ,其中误差阈值 ϵ \epsilon ϵ 需小心选择,但在一般情况下,最优解 x ∗ \mathbf x^* x∗ 是未知的;
- 当观察到超过一定次数且算法结果不再提升时。可以用以下方法进行改进的测量:粒子的平均位置变化很小时;粒子平均速度趋近于0时;经过一定次数的迭代,但不再提升时等,而这些终止条件对于两个参数是很敏感的:(1)性能监测的次数;(2)构成不可接受的表现的阈值;
- 当正则化群落半径趋近于0时。正则化半径: R n o r m = R m a x d i a m e t e r ( S ) \displaystyle R_{norm}=\frac{R_{max}}{diameter(S)} Rnorm=diameter(S)Rmax,其中 d i a m e t e r ( S ) diameter(S) diameter(S)是初始化群落半径, R m a x = ∣ ∣ x m − y ^ ∣ ∣ R_{max}=||\mathbf x_m-\hat\mathbf y|| Rmax=∣∣xm−y^∣∣是当前代的最大群落半径, m = 1 , 2 , ⋯ , n s m=1,2,\cdots,n_s m=1,2,⋯,ns,而 ∀ i = 1 , 2 , ⋯ , n s , 有 ∣ ∣ x m − y ^ ∣ ∣ ≥ ∣ ∣ x i − y ^ ∣ ∣ \forall i=1,2,\cdots,n_s\;,有 ||\mathbf x_m-\hat\mathbf y||\ge||\mathbf x_i-\hat\mathbf y|| ∀i=1,2,⋯,ns,有∣∣xm−y^∣∣≥∣∣xi−y^∣∣。当 R n o r m R_{norm} Rnorm 趋于 0 时,则种群失去了提升的潜力。该方法的终止条件是 R n o r m < ϵ \displaystyle R_{norm}<\epsilon Rnorm<ϵ,对 ϵ \epsilon ϵ 的选择需要仔细当心。
- 当目标函数的斜率趋于 0 时。上述方法考虑的是粒子在搜索空间的位置分布,而未考虑目标函数斜率的相关信息,基于目标函数的改变量,计算其斜率
f
′
(
t
)
=
f
(
y
^
(
t
)
)
−
f
(
y
^
(
t
−
1
)
)
f
(
y
^
(
t
)
)
\displaystyle f'(t)=\frac{f(\hat\mathbf y(t))-f(\hat\mathbf y(t-1))}{f(\hat\mathbf y(t))}
f′(t)=f(y^(t))f(y^(t))−f(y^(t−1))。在连续几次迭代后,若
f
′
(
t
)
<
ϵ
f'(t)<\epsilon
f′(t)<ϵ
,则表示种群收敛。但这种方法有一定问题,即当一部分粒子陷入局部最优,但其他粒子在搜索其他空间时,解决方法是,先判断是否所有粒子都聚集在一定的群落半径或是否都向同一点收敛,再使用目标函数的斜率进行判断。
上述终止条件,以群落收敛为准则,但这并不意味着达到最优解,而是群落达到了一个平衡稳定状态。
PSO的社会网络结构
PSO的社会结构有邻居的重叠形式决定,一个邻居内的粒子对彼此相互影响。社会网络结构对PSO的性能影响很大,而社会网络中的信息流通,依赖与:(1)网络中节点的连通程度;(2)集群(当一个节点的邻居也是彼此的邻居时,就会产生集群)的数量和一个节点到另一节点的平均最短距离。
高连通性的社会网络,大多数个体之间彼此相连,最优成员的相关信息会很快通过网络传递到整个社会,这意味着可以达到更快的收敛速度;但是这也意味着它能覆盖的搜索空间相对于低连通性的社会网络要更小,因此可能不足以去寻找最优解。而对于稀疏连接的网络,其存在着大量的集群,也有可能发生搜索空间得不到充分覆盖的情况。每个集群包含的个体在一个紧密的邻居中,他们只覆盖搜索空间的一部分区域。社会网络机构都会存在一些集群,集群之间保持低连通性,因此,只有搜索空间的有限部分信息在集群之间可以缓慢的进行信息流共享。
典型的社会网络结构如下:
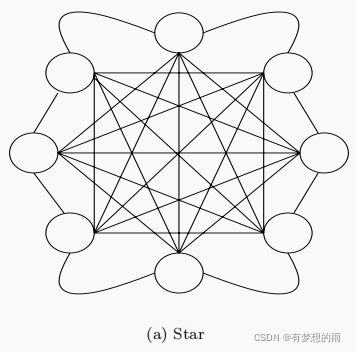
星型社会结构
其中所有的粒子都彼此相连。这种结构中,所有粒子都会向整个群落已发现的最优解移动,收敛速度快,但容易达到局部最优,通常用于
g
−
b
e
s
t
g-best
g−best PSO的网络结构。
g
−
b
e
s
t
g-best
g−best PSO在解决单峰问题时表现很好。
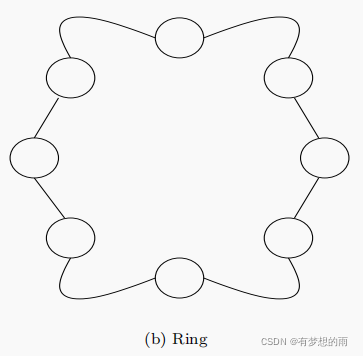
环形社会结构
每个粒子只与他即时的
n
N
n_{\mathcal N}
nN 个邻居交流,每个粒子向其邻居中的最优个体移动。环形结构中,社区是重叠的,这有利于社区之间的信息交换,并最终汇聚成一个单一的解决方案。其信息沿着社会网络以一个较低的速率流通,因此收敛较慢,可以覆盖更多的搜索空间。从而使得环形网络在解决多峰问题时性能比星型网络要好,通常用于
l
−
b
e
s
t
l-best
l−best PSO。
当
n
N
=
2
n_{\mathcal N}=2
nN=2 时,其网络结构如下所示。
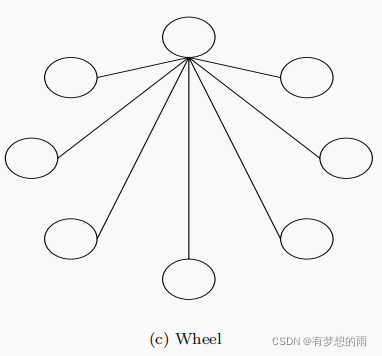
轮型社会结构
这种结构中,一个邻居中的个体但是彼此孤立的,一个粒子作为一个焦点,所有信息通过焦点进行传递。焦点粒子会对邻居中的所有粒子信息进行比较,对是否向最优邻居移动做出判断,如果焦点粒子的新位置得到了更好的性能,那么改进将传递给邻近的所有成员。轮型网络减缓了最优解在群落中的传播速度。
金字塔型社会网络结构
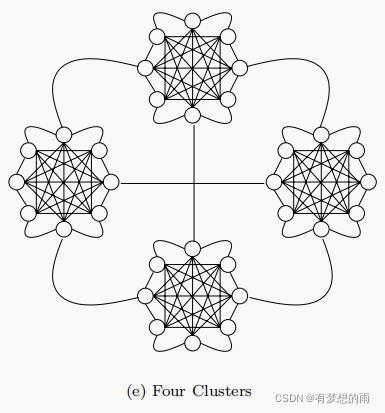
4-集群式社会网络结构
该结构中,4个集群之间两两相连,每个集群内部粒子以星型方式链接。
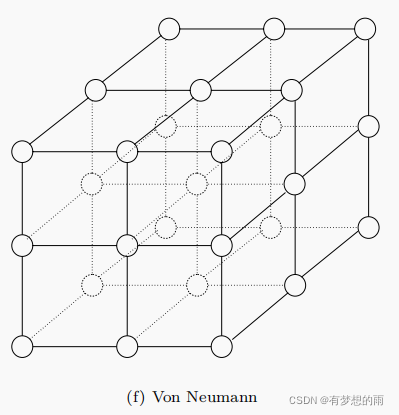
冯诺依曼社会网络结构
粒子以网格形式进行链接。在大量的实证研究中证明,冯 · 诺依曼社交网络在许多问题上比其他网络更胜一筹。
还存在着许多种拓扑结构,但没有一种结构对所有问题都是最好的。一般的,低连通的网络更适用于解决多峰问题,全连通的网络适用于解决单峰问题。
关于PSO的其他讨论,请看:
粒子群算法(PSO)——总体概述
粒子群算法(PSO)——算法详解(二)

















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









