







AAAI2020 南京大学+腾讯优图实验室
1 摘要
在视频动作识别的架构设计中,效率是一个重要的问题。3D CNNs在视频动作识别方面取得了显著的进展。然而,与二维卷积相比,三维卷积往往引入大量的参数,导致计算量大。为了解决这个问题,我们提出了一个有效的时序模块,称为Temporal Enhancement-and-Interaction(TEI模块),它可以插入到现有的2D CNNs中。TEI模块通过分离通道相关和时间交互的建模,提出了一种不同的学习时间特征的范式。首先,它包含一个运动增强模块(MEM),该模块在抑制无关信息(例如背景)的同时增强与运动相关的特征。
然后,介绍了一个时序交互模块(TIM),它以通道方式补充时序上下文信息。该两阶段建模方案不仅能够灵活有效地捕捉时间结构,而且能够有效地进行模型推理。我们进行了大量的实验来验证TEINet在Something-Something V1&V2, Kinetics, UCF101 and HMDB51几个基准上的有效性。TEINet可以在这些数据集上达到很好的识别精度,同时保持很高的效率。
2 相关背景
视频处理中,数据量太大是当前这一领域发展的一大主要瓶颈。从图像领域目标识别迁移过来的2DCNN在早期工作中主要是将视频当成一帧一帧的图片来做,缺乏时序信息的处理,因为准确率较低。
随后结合了时序信息的3DCNN成为另一主流方案,准确率提升了,但是参数量也上去了,训练代价很大。为此,很多工作都集中在对这两张方案的融合,即构造一种位于2D和3D之间的架构。代表工作有我之前组会介绍过的P3D(伪3D)、R(2+1)D等。
TEINet是这一方向新的思路和方案,由南京大学和腾讯优图实验室联合完成。
3 方案原理
TEINet也是设计2D Module的工作,包括MEM和TIM两个部分。MEM利用动作信息实现注意力机制,加强重要特征;TIM对时序信息建模。将两个模块先后拼接形成TEINet,在各个数据集上都得到了不错的效果。


3.1 Motion Enhanced Module (MEM)
MEM目的在于通过使用相邻帧特征的差异来在通道上增强运动相关的特征。

输入序列:
,

首先通过全局平均池化(GAP),聚合输入的空间特征,卷积输出的结果为:

再通过一层卷积,获得channel间的权重,且输出通道为C/r,r在实验中设置为8。
为了使用相邻帧特征的差异,设计了两路卷积(图中的蓝色和黄色),分别对应输入的前后相邻两帧: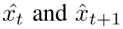 ,分别通过各自卷积之后的结果进行相减得到差异信息,即为运动信息。
,分别通过各自卷积之后的结果进行相减得到差异信息,即为运动信息。

接着,再通过一层卷积(图中的conv3),将通道数从C/r变回到C,目的是为了保持和输入Xt通道一致。
最后再通过sigmoid层,得到0~1范围的激活,即对应的通道权重:

将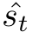 与原来的特征
与原来的特征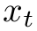 进行通道点乘,获得运动显著(motion-salient)的特征。
进行通道点乘,获得运动显著(motion-salient)的特征。

3.2 Temporal Interaction Module (TIM)
通过MEM获得了运动显著的特征,但是模型仍然不能捕捉时序信息,因而设计了TIM模块,希望以较低的计算成本获取时序文本信息。

对于输入U=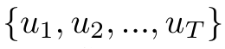
首先将维度从
变为

然后对每一个通道单独进行通道级卷积操作来学习每个通道的时序变化。

V是通道级卷积的卷积核,与3DCNN相比,计算量大幅降低。V的大小设计为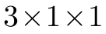 ,使得特征只和相邻时间的特征相关,但是时序接收场会随着特征图的越来越深而逐步增大。
,使得特征只和相邻时间的特征相关,但是时序接收场会随着特征图的越来越深而逐步增大。
卷积之后,再将Y的维度变为
3DCNN的计算量为:
TIM的计算量为:
此外,作者在论文中提到,TIM可学习,可以看做TSM(看成是[0,1,0][1,0,0][0,0,1]的卷积)的泛化版(TSM:Temporal shift module for efficient video understanding. CoRR 2018)
4 实验效果
4.1 Something-Something V1数据集

4.2 Something-Something V2数据集

4.3 Kinetics-400数据集

4.4 UCF101 and HMDB51数据集

5 结论
作者设计了两个模块分别捕捉运动信息和时序信息,都是2D模块的巧妙设计,可以直接插入现有的2DCNN结构。同时因为是2D,所以可以使用ImageNet的预训练模型,值得后期借鉴。对视频研究的基本框架仍有改进空间。
也欢迎感兴趣的朋友关注公。众号StrongerTang更多交流讨论,相互学习!
推荐阅读:
P-GCN:Graph Convolutional Networks for Temporal Action Localization 2019 ICCV
G-TAD: Sub-Graph Localization for Temporal Action Detection
ActivityNet数据集简介及下载分享(百度网盘)















 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









