







TEINet: Towards an Efficient Architecture for Video Recognition 论文阅读
文章信息;

原文链接:https://arxiv.org/abs/1911.09435
无源码
发表于:AAAI 2020
Abstract
在设计用于动作识别的视频架构时,效率是一个重要问题。3D卷积神经网络在视频动作识别方面取得了显著进展。然而,与其2D对应物相比,3D卷积往往引入了大量参数并导致高计算成本。为了缓解这个问题,我们提出了一种高效的时间模块,称为时间增强和交互(TEI)模块,它可以插入到现有的2D卷积神经网络中(称为TEINet)。TEI模块通过解耦通道相关性建模和时间交互学习了不同的范例来学习时间特征。首先,它包含一个增强运动模块(MEM),用于增强与运动相关的特征,同时抑制不相关的信息(例如,背景)。然后,它引入了一个时间交互模块(TIM),以通道级的方式补充时间上下文信息。这种两阶段建模方案不仅能够灵活有效地捕获时间结构,而且对模型推断而言也是高效的。我们进行了大量实验证明了TEINet在几个基准数据集(如Something-Something V1&V2,Kinetics,UCF101和HMDB51)上的有效性。我们提出的TEINet在这些数据集上能够取得良好的识别准确率,同时保持高效率。
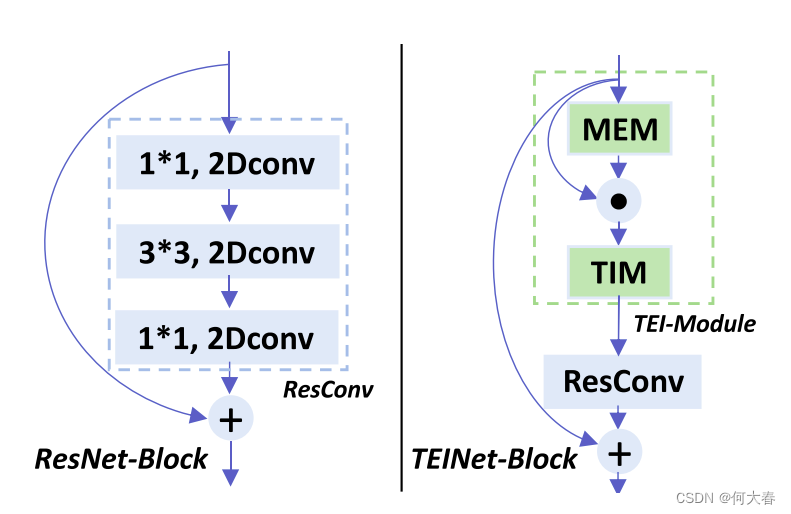
图1:TEINet构建块。我们提出了一个有效的TEI模块,将时间建模解耦为MEM以增强运动相关特征和TIM捕获时间上下文信息。该TEI模块可以插入到2D ResNet块中,构建一个高效的TEINet视频架构。
1 Introduction
视频理解是计算机视觉中最重要的问题之一(Simonyan和Zisserman 2014; Tran等人 2015; Wang等人 2016)。动作识别是视频理解中的一个基本任务,因为它不仅能够从视频中提取语义信息,还能为其他任务(如动作检测和定位)提供通用的视频表示(Feichtenhofer等人 2018; Zhao等人 2017)。与静态图像不同,动作识别的核心问题是如何有效地建模时间信息。时间维度通常在空间域上表现出不同的特性。以适当的方式建模时间信息对于动作识别至关重要,这引起了研究的极大兴趣。
最近,卷积网络(LeCun等人 1998)已经成为动作识别中的主流方法(Simonyan和Zisserman 2014; Carreira和Zisserman 2017; Tran等人 2018)。TSN(Wang等人 2016)是一种高效的方法,它忽略了对时间顺序信息的约束,只在最终分类器层聚合时间信息。为了更加缓慢和早期地捕获时间信息,一些基于新型高效2D卷积神经网络的架构被开发出来,例如StNet(He等人 2019)和TSM(Lin,Gan和Han 2018)。然而,它们涉及一些手工设计,缺乏明确的解释,并且可能不够理想用于时间建模。3D卷积神经网络(Tran等人 2015; Carreira和Zisserman 2017)是直接从RGB帧学习时空特征的更为原理性的架构。不幸的是,从2D卷积简单地扩展到其3D版本会导致一个关键问题:当密集地用3D卷积替换2D卷积时,会导致计算成本高。因此,我们希望设计一个灵活的时间建模模块,它具有学习时空表示的能力,但仍保持2D卷积神经网络的高效性。
直观地,视频中的时间结构可以从多个方面有助于动作识别。首先,运动信息能够帮助我们聚焦于对动作识别有区分性的移动物体或人物。这些区分性特征可以针对每个输入视频自动确定。其次,视觉特征的时间演变使我们能够捕获视频中的动态变化,并将相邻帧级特征联系起来进行动作识别。基于这些分析,我们提出了一种新的时间建模范式,称为增强与交互。这种新设计将时间模块分解为两个阶段:首先增强区分性特征,然后捕获它们的时间交互。这种独特的设计使我们能够以更为原理性和高效的方式分别捕获通道级的相关性和时间关系。结果表明,这种分离的建模方案不仅能够灵活有效地捕获时间结构,而且在实践中还保持了较高的推断效率。
具体地,我们首先介绍了Motion Enhanced Module (MEM),它利用运动信息作为指导,聚焦于重要特征。为了使这种增强更加高效和有效,我们将特征图压缩到仅关注通道级重要性,并利用时间差异作为近似运动图。然后,为了捕获相邻帧之间的时间交互,我们提出了Temporal Interaction Module (TIM),它对视觉特征的局部时间变化进行建模。为了控制模型复杂度并确保推断效率,我们在一个局部时间窗口中采用了时间通道级卷积。这两个模块按顺序连接,形成了一种新颖的时间模块,即Temporal Enhancement and Interaction (TEI module),它是一个通用的构建模块,可以插入到现有的2D CNNs中,如ResNets,如图1所示。
在实验中,我们使用2D ResNet在大规模数据集(如Kinetics(Kay等人,2017年)和Something-Something(Goyal等人,2017年))上验证了TEI块的有效性。最终的视频架构,被称为TEINet,在保持快速推断速度的同时,明显提高了性能。特别地,我们的TEINet在Something-Something数据集上实现了最先进的性能,并且在Kinetics数据集上以更低的计算成本实现了与之前基于3D CNN的方法相当的性能。我们还通过在UCF101和HMDB51数据集上进行微调来展示TEINet的泛化能力,其中也获得了具有竞争力的识别准确率。这项工作的主要贡献总结如下:
- 我们提出了一种新的时间建模模块,称为TEI模块,通过将时间特征学习的任务分解为通道级增强和局部时间交互。
- 我们在各种大规模数据集上验证了提出的TEINet,结果表明它能够在较低的计算成本下明显改善先前的时间建模方法。
2 Related Work
2D CNNs in Action Recognition.传统的2D CNNs被广泛应用于视频动作识别领域(Simonyan和Zisserman 2014; Feichtenhofer,Pinz和Wildes 2016; Wang等人 2016; Lin,Gan和Han 2018; Gan等人 2015)。两流方法(Simonyan和Zisserman 2014; Feichtenhofer,Pinz和Zisserman 2016; Zhang等人 2016)将光流或运动向量视为运动信息,以构建一个时间流CNN。TSN(Wang等人 2016)利用平均池化来聚合一组稀疏采样帧的时间信息。为了提高TSN的时间推理能力,TRN(Zhou等人 2018)通过关注采样帧之间的多尺度时间关系而被提出。为了高效建模时间结构,TSM(Lin,Gan和Han 2018)在原始特征图上提出了一个时间偏移模块。与TSM具有相同的动机,我们的TEINet也基于具有高效性的2D骨干,但更擅长捕捉视频识别的时间线索。
3D CNNs in Action Recognition.3D卷积(Tran等人,2015年;Carreira和Zisserman,2017年)是对2D版本的直接扩展,以直接从RGB图像中学习时空表示。I3D(Carreira和Zisserman,2017年)将所有2D卷积核扩展为3D卷积核,并直接利用在ImageNet上预训练的权重。ARTNet(Wang等人,2018a)通过更高阶的关系建模改进了原始的3D卷积,以明确捕获运动信息。3D卷积是一种自然且简单的建模时间特征的方法,但在实践中计算量大。与3D CNN不同,我们的TEINet纯粹基于2D CNNs的新型时间模块用于视频识别。
Efficient Temporal Modules.一些高效的时间模型通过组合2D和3D卷积提出。ECO(Zolfaghari,Singh和Brox 2018)将2D卷积和3D卷积组合成一个网络,以在2D CNNs和3D CNNs之间实现平衡。为了分解空间和时间特征的优化,伪3D卷积,例如P3D(Qiu,Yao和Mei 2017)、S3D(Xie等人 2018)和R(2+1)D(Tran等人 2018),将时空3D卷积分解为空间2D卷积和时间1D卷积。我们的TEINet将一个新的时间块集成到纯粹的2D骨干中,赋予网络在视频中建模时间结构的能力。
Attention in Action Recognition.注意力机制(Hu,Shen和Sun 2018;Li,Hu和Yang 2019)被广泛应用于图像分类中,可以利用少量额外的参数来提升性能。类似地,也有一些与动作识别相关的工作(Wang等人 2018b;Girdhar和Ramanan 2017)涉及到注意力。非局部网络将非局部均值操作形式化为非局部块,以捕获视频中的长程依赖关系。我们方法中的运动增强模块(MEM)与这些注意力方法不同。MEM通过局部运动趋势构建时间注意力权重,可以通过端到端训练而不使用额外的监督,并在准确性上获得可观的提升。
3 Method
在本节中,我们将介绍我们提出的TEI模块。首先,我们描述了运动增强模块,并解释了如何学习通道级别的注意力权重。然后,我们介绍了时间交互模块的技术细节。最后,我们将这两个模块结合起来作为TEINet的构建模块,并将此模块集成到现有的2D CNN架构中。
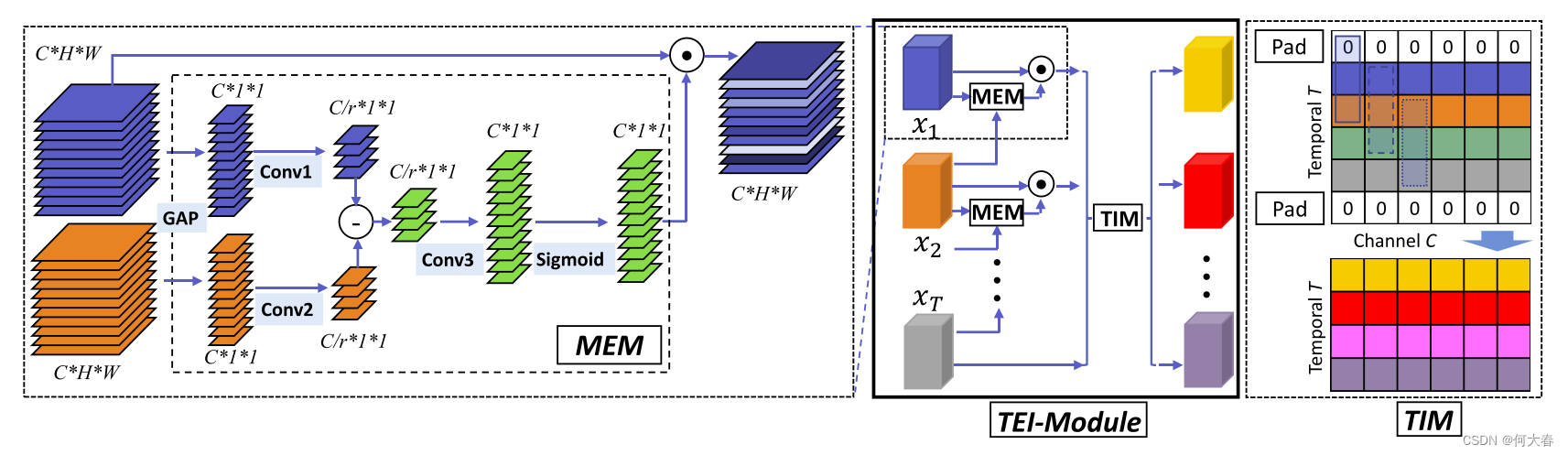
图2:TEI模块的流程。我们在左侧展示了增强运动模块(MEM),右侧展示了时间交互模块(TIM)。其中 ⊙ \odot ⊙表示逐元素乘法, ⊖ \ominus ⊖表示逐元素减法。值得注意的是,在TIM中,我们使用不同的框表示卷积核权重,这意味着每个通道不共享卷积核权重。
3.1 Motion Enhanced Module
我们的方法是通过使用相邻帧级特征的时间差异以通道级方式增强与运动相关的特征。为了降低计算成本,我们首先为每个通道构建全局表示,然后在通道级进行特征增强。如图2所示,给定一个输入序列 X = { x 1 , x 2 , . . . , x T } X=\{x_1,x_2,...,x_T\} X={x1,x2,...,xT},其中 x t ∈ R C × H × W x_t\in\mathbb{R}^{C\times H\times W} xt∈RC×H×W,我们首先通过全局平均池化在它们的空间维度 ( H × W ) (H\times W) (H×W)上聚合特征图 x t x_t xt,得到 x ^ t ∈ R C × 1 × 1 \hat{x}_t\in\mathbb{R}^{C\times1\times1} x^t∈RC×1×1。然后,这些池化特征经过后续处理操作生成通道重要性权重。
基本上,我们观察到整体外观信息随着时间逐渐缓慢变化。运动显著区域的像素值变化速度比静态区域的像素值更快。在实践中,我们利用相邻帧之间的特征差异来近似表示运动显著性。为了减少模型复杂度,
x
t
^
\hat{x_t}
xt^和
x
^
t
+
1
\hat{x} _{t+ 1}
x^t+1被输入到两个不同的2D卷积中,其卷积核大小为
1
×
1
1\times1
1×1,其中
x
t
^
\hat{x_t}
xt^的通道将被压缩。这种维度缩减和差值计算可以表示为:
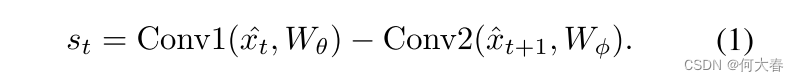
这里的 W θ W_\theta Wθ和 W ϕ W_\phi Wϕ是卷积的可学习参数,将 X ^ \hat{X} X^中的通道数从 C C C减少到 C r \frac Cr rC。在我们的实验中,减少比率 r r r设为8。
然后,另一个2D卷积应用于
s
t
s_t
st,旨在恢复与输入
s
t
s_t
st相同的通道维度。注意力权重通过以下方式获得:
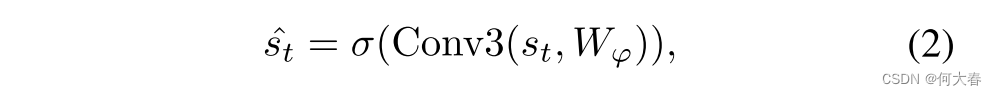
其中,
σ
(
∗
)
\sigma(*)
σ(∗)表示sigmoid函数,
W
φ
W_\varphi
Wφ是Conv3的可学习参数。最后,我们获得了不同通道的注意力权重
s
^
∈
R
C
×
1
×
1
\hat{s}\in\mathbb{R}^{C\times1\times1}
s^∈RC×1×1。我们利用通道级乘法来增强运动显著特征:
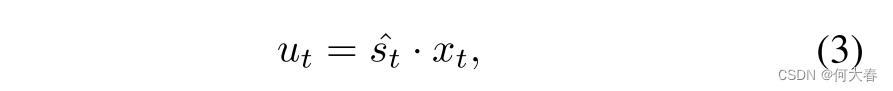
这里
t
∈
[
1
,
T
−
1
]
t\in[1,T-1]
t∈[1,T−1],
u
t
u_t
ut是我们最终增强的特征图。为了保持时间尺度与输入
X
X
X一致,我们简单地将
x
T
x_T
xT复制为
u
T
u_T
uT,即
u
T
=
x
T
u_T=x_T
uT=xT。
Discussion.我们注意到我们的MEM与(Hu, Shen, and Sun 2018)中的SE模块类似。然而,SE模块和MEM之间的根本区别在于,SE模块是一种自注意机制,通过使用自己的全局特征来校准不同的通道,而我们的MEM是一种运动感知注意模块,通过增强与运动相关的特征。为了证明MEM的有效性,我们在第4.3节进行了比较实验。在相同的设置下,我们的MEM比视频数据集中的SE模块更擅长增强用于动作识别的时间特征。
3.2 Temporal Interaction Module
在MEM中,我们增强了与运动相关的特征,但我们的模型仍然无法在局部时间窗口内捕获时间信息,即随时间变化的视觉模式的时间演变。因此,我们提出了时间交互模块(TIM),旨在以较低的计算成本捕获时间上下文信息。更具体地说,我们在这里使用通道级卷积来独立地学习每个通道的时间演变,这保留了模型设计的低计算复杂度。
如图2所示,给定输入
U
=
{
u
1
,
u
2
,
.
.
.
,
u
T
}
U=\{u_1,u_2,...,u_T\}
U={u1,u2,...,uT},我们首先将其形状从
U
T
×
C
×
H
×
W
U^{T\times C\times H\times W}
UT×C×H×W转换为
U
^
C
×
T
×
H
×
W
\hat{U}^{C\times T\times H\times W}
U^C×T×H×W(记为
U
^
\hat{U}
U^以避免歧义)。然后,我们对
U
^
\hat{U}
U^应用通道级卷积操作如下:
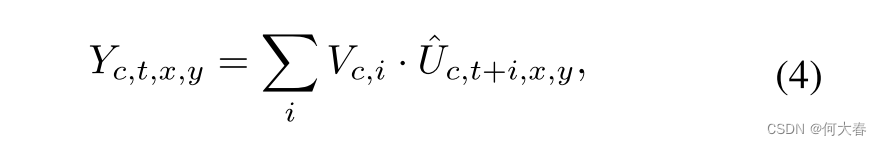
其中,
V
V
V是通道级卷积核,
Y
c
,
t
,
x
,
y
Y_{c,t,x,y}
Yc,t,x,y是经过时间卷积后的输出。与3D卷积相比,通道级卷积极大地降低了计算成本。在我们的设置中,通道级卷积的卷积核大小为
3
×
1
×
1
3\times1\times1
3×1×1,这意味着特征只与相邻时间的特征进行交互,但当特征图通过网络的深层时,时间感知场将逐渐增长。卷积后,我们将输出
Y
Y
Y的形状转换回
T
×
C
×
H
×
W
T\times C\times H\times W
T×C×H×W。普通3D卷积的参数为
C
o
u
t
×
C
i
n
×
t
×
d
×
d
C_{out}\times C_{in}\times t\times d\times d
Cout×Cin×t×d×d,而(Tran et al.,2018)中的时间1D卷积为
C
o
u
t
×
C
i
n
×
t
C_{out}\times C_{in}\times t
Cout×Cin×t,但是TIM的参数为
C
o
u
t
×
1
×
t
C_{out}\times 1\times t
Cout×1×t。与其他时间卷积算子相比,TIM的参数数量大大减少。
Discussion.我们发现我们的TIM与最近提出的TSM(Lin, Gan, and Han 2018)有关。实际上,TSM可以被视为一种通道级时间卷积,其中时间核对于非移位固定为[0, 1, 0],向后移位固定为[1, 0, 0],向前移位固定为[0, 0, 1]。我们的TIM将TSM操作推广为一个具有可学习卷积核的灵活模块。在实验中,我们发现这种可学习的方案比随机移位更有效地捕获了用于动作识别的时间上下文信息。
通道级卷积的卷积核大小为 3 × 1 × 1 3\times1\times1 3×1×1表示卷积核在空间维度上的大小为 1 × 1 1\times1 1×1,在通道维度上的大小为 3 3 3。这种卷积核的设计使得卷积操作仅在时间维度上进行,而在空间维度上保持不变,从而可以在保留时间关系的同时,不改变空间信息。在视频数据中,这种卷积操作可以用来捕获相邻帧之间的时间变化特征,而不引入额外的空间维度上的卷积操作,从而减少了模型的计算复杂度。
3.3 TEINet
在介绍了MEM和TIM之后,我们准备描述如何构建时间增强和交互模块(TEI),并将其整合到现有的网络架构中。如图1所示,TEI模块由上述介绍的MEM和TIM组成,可以高效实现。首先,输入特征图将被送入MEM中,以学习不同通道的注意力权重,旨在增强与运动相关的特征。然后增强的特征将被送入TIM中,以捕获时间上下文信息。我们的TEI模块是一个通用且高效的时间建模模块,可以插入任何现有的2D CNN中以捕获时间信息,生成的网络称为时间增强和交互网络(TEINet)。
我们的TEI模块直接插入到2D CNN主干中,而其他方法(如Tran等人2018年;邱等人2017年;谢等人2018年)则将2D卷积替换为更昂贵的3D卷积或(2+1)D卷积。这种新的集成方法不仅能够使用预训练的ImageNet模型进行初始化,而且与3D CNN相比,还带来更少的额外计算FLOPs。在我们的实验中,为了在性能和计算成本之间取得平衡,我们使用ResNet-50(He等人,2016年)作为主干来实例化时间增强和交互网络(TEINet)。我们在第4节中进行了大量实验,以找出TEINet在动作识别中的最佳设置。
Discussion.我们的论文提出的增强和交互是一种分解建模方法,赋予网络在视频中学习时间特征的强大能力。我们发现我们的模块对两种类型的视频数据集都有效:以运动为主的数据集,如Something-Something V1&V2,以及以外观为主的数据集,如Kinetics-400。MEM和TIM在捕获时间信息时关注不同的方面,其中MEM旨在学习通道级别的重要性权重,而TIM则试图学习相邻特征的时间变化模式。正如表1a所示,这两个模块相互合作且互补。
4 Experiments
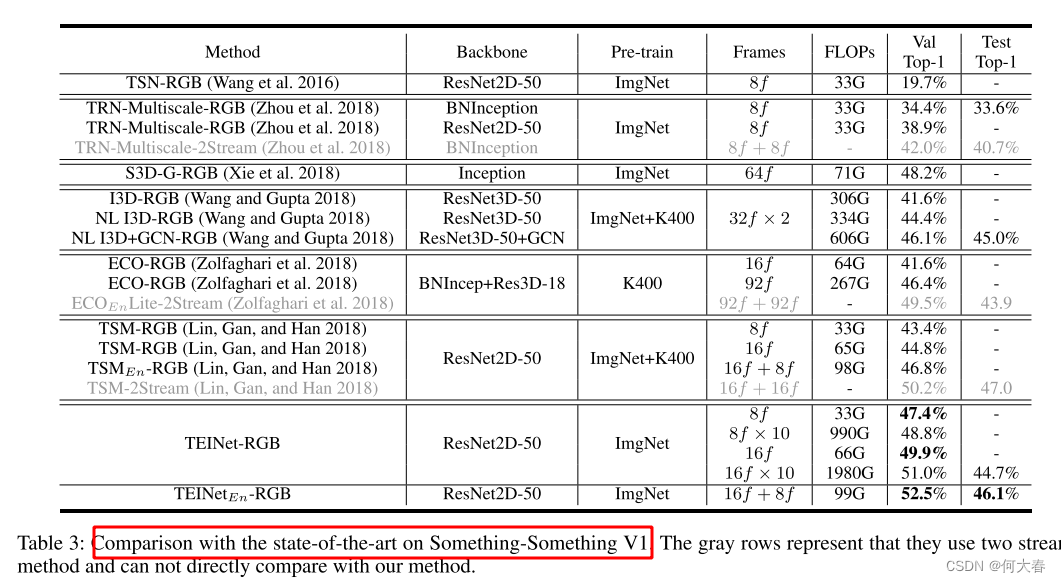
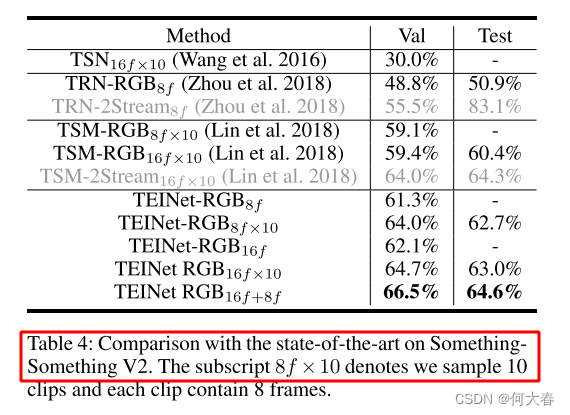
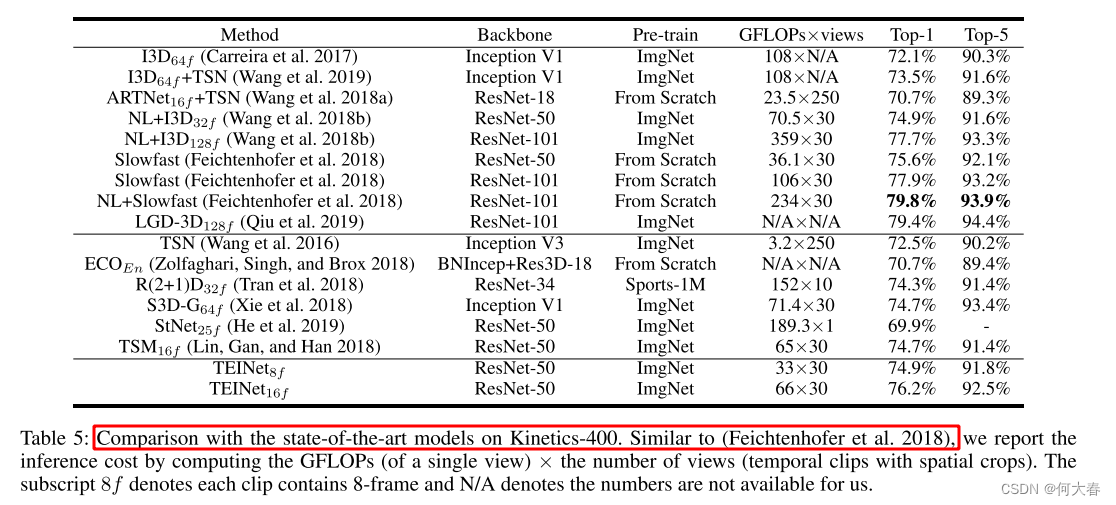
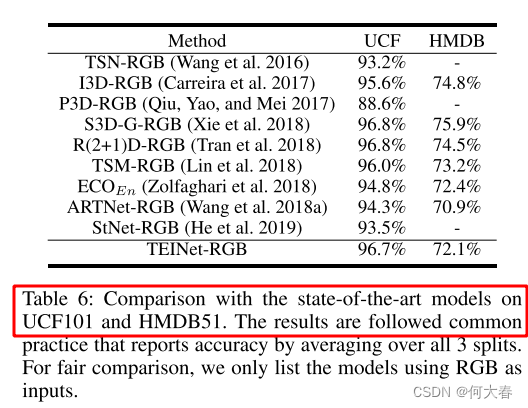
消融实验不看了,学习思路就行,毕竟算起来也是比较老的论文了,2024的都过完一半了,2020也是四年前了,时间真快。
5 Conclusion
在这项工作中,我们提出了一种高效的时间建模方法,即TEINet,用于捕获视频帧中的时间特征,以进行动作识别。通过插入由运动增强模块(MEM)和时间交互模块(TIM)组成的TEI块,可以将普通的ResNet转换为TEINet。MEM通过计算时间注意力权重来专注于增强与运动相关的特征,而TIM则通过通道级时间卷积来学习时间上下文特征。我们进行了一系列实证研究,以证明TEINet在视频动作识别中的有效性。实验结果表明,我们的方法在SomethingSomething V1&V2数据集上取得了最先进的性能,并且在Kinetics数据集上表现出了高效率的竞争性能。
阅读总结
通过特征差来得到注意力感觉还是可以借鉴的。
也就是这个模块
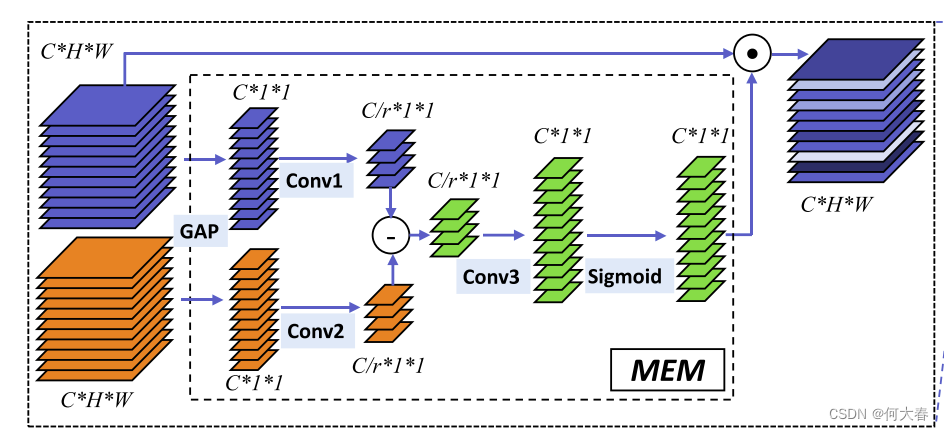
代码没开源,不过感觉还是个听简单的模块。














 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









