






记录一下学习过程,总结得不对的地方还请指正!!
DETR:
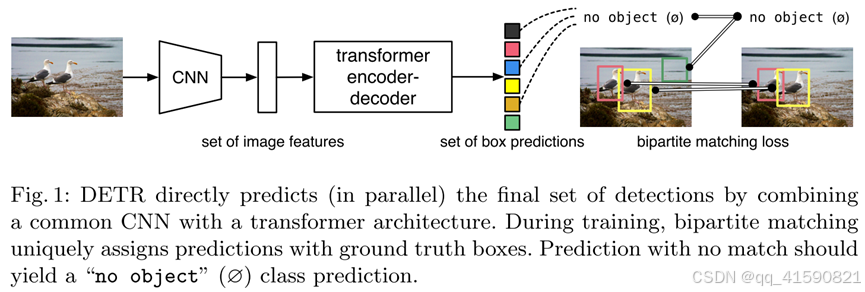
1、不需要预定义的先验anchor,也不需要NMS的后处理策略,就可以实现端到端的目标检测。
2、DETR大目标检测上性能是最好的,而小目标上稍差,而且基于match的loss导致学习很难收敛(即难以学习到最优的情况)。
3、DETR的总体框架,先通过CNN提取图像的特征;再送入到transformer encoder-decoder中,该编码器解码器的结构基本与transformer相同,主要是在输入部分和输出部分的修改;最后得到类别和bbox的预测,并通过二分匹配计算损失来优化网络。
代码:
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
# 使用 ResNet-50 作为特征提取网络,并截取它的所有卷积层(去掉全连接层和全局池化层)。
# children() 方法获取 ResNet 中的所有子层,[:-2] 移除最后两层。pretrained=True 加载预训练参数。
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
# 定义一个 1×1 卷积层,将 ResNet-50 输出的特征图从 2048 通道压缩到 hidden_dim 维度。
self.conv = nn.Conv2d(2048, hidden_dim, 1)
# 使用 nn.Transformer 模块定义Transformer,它包含编码器和解码器。
# hidden_dim 是 Transformer 的隐藏层维度。
# nheads 指定多头注意力机制中的头数。
# num_encoder_layers 和 num_decoder_layers 指定编码器和解码器的层数。
self.transformer = nn.Transformer(hidden_dim, nheads,num_encoder_layers, num_decoder_layers)
# 线性层进行预测:
# linear_class 是分类头,用于预测物体类别。
# num_classes + 1 包含了一个额外的 “no object” 类别,用于标记无物体的情况。
# linear_bbox 是边界框预测头,用于预测边界框的 4 个坐标值 (x, y, w, h)。
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
# 定义查询位置编码 (query_pos):
# query_pos 是用于解码器的对象查询向量,这里定义了 100 个查询向量。
# 这些查询帮助 Transformer 生成候选框位置。
# nn.Parameter 表示该参数是可训练的。
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
# 行和列的可学习位置嵌入 (row_embed 和 col_embed):
# row_embed 和 col_embed 分别用于生成特征图的行和列位置编码。
# hidden_dim // 2 表示将 hidden_dim 分成两半,行列各用一半。
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
# self.col_embed[:W] 生成列方向的嵌入并扩展为 (H, W, hidden_dim // 2)。
# self.row_embed[:H] 生成行方向的嵌入并扩展为 (H, W, hidden_dim // 2)。
# torch.cat(..., dim=-1) 将行和列的编码拼接得到 (H, W, hidden_dim) 维度的编码。
# .flatten(0, 1).unsqueeze(1) 将其转换成 (H * W, 1, hidden_dim) 以适配 Transformer。
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
# 将编码器输入pos + h.flatten(2).permute(2, 0, 1)和解码器输入self.query_pos.unsqueeze(1)传入 Transformer 模块。
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),self.query_pos.unsqueeze(1))
# 输出self.linear_class(h)和self.linear_bbox(h).sigmoid(),分别表示每个查询的类别概率和边界框坐标。
return self.linear_class(h), self.linear_bbox(h).sigmoid()Deformable DETR:
DCN(Deformable Convolution Networks):在卷积当中引入了学习空间几何形变的能力,不再是使用常规的领域矩阵卷积,而是让卷积自动的去学习需要需要卷积的周围像素,以此可以适应更加复杂的几何形变任务。
作者这里将DCN和DETR相结合,DETR收敛慢和计算量大,其主要的原因是transformer模块带来的频繁计算(每个位置需要计算和其他所有位置的相似度,而且不像卷积那样共享参数),那么很朴素的想法就是:让每个位置不必和所有位置交互计算,只需要和部分(学习来的,重要的部分)进行交互即可。所以作者结合DCN和DETR提出Deformable Attention模块,并且将这个模块很方便的应用到多尺度特征上。
1、多尺度特征,并且使用scale-level pos embedding,用于区分不同的特征层;
在backbone中提取的4个不同尺度的特征送入transformer中的encoder中,但是,DETR的使用的是单尺度特征,而且使用的是三角函数,不同位置的(x、y)坐标会生成不同的位置编码。 但是Deformable DETR是使用了4个不同尺度的特征,如果还是用原来的方法,那么在这些不同尺度的特征中,位于相同位置(x、y)坐标的位置会产生相同的位置编码,所以这个方法就无法区分这些不同特征相同位置的位置编码了。
针对这个问题,作者提出了一个’scale-level embedding’的变量,可以用来解决这个问题:区分不同特征相同位置的位置编码。不同层的特征图会有不同的level_embed 再让原先的每层位置编码+每层的level_embed。这样就很好的区分不同层的位置编码了 而且这个level_embed是可学习的
2、提出多尺度可变形注意力代替Encoder中的自注意力和Decoder中的交叉注意力;
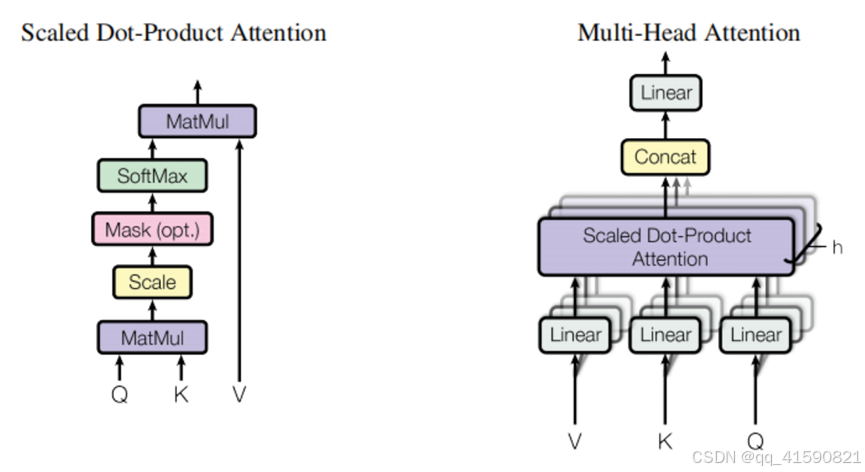
(1)普通多头注意力机制:
![]()
其中,x是输入特征;![]() 表示query;由x经过
表示query;由x经过![]() 线性变换得来;k是key的索引;q是query的索引;M表示多头注意力的头数;m代表第几注意力头部;
线性变换得来;k是key的索引;q是query的索引;M表示多头注意力的头数;m代表第几注意力头部;![]() 表示第m头注意力权重;
表示第m头注意力权重;![]() 是value;整个[ ]内的过程就是图a的全过程;
是value;整个[ ]内的过程就是图a的全过程;![]() 是注意力施加在value之后的结果经过线性变换(图b的Linear)从而得到不同头部的输出结果,
是注意力施加在value之后的结果经过线性变换(图b的Linear)从而得到不同头部的输出结果,![]() 表示所有key的集合。
表示所有key的集合。
普通的transfomer的多头注意力计算过程中,对每个头:每个位置的query会和所有位置的key计算注意力权重,并且施加在所有位置的value上。
(2)可变形多头注意力:DeformAttn
query不是和全局每个位置的所有key都计算注意力权重,而是对每个query,仅在全局位置中采样 局部/部分 位置的key(自学习的方式),并且value也是局部位置的value,最后把这个局部/稀疏的注意力权重和局部value进行计算。
![]()
①采样局部的key,即k的范围缩小了。原始的k是所有key的集合,而这里的k是只采样K 个位置。具体点说:每个头:每个query只在key中采样K个位置,计算他们的注意力,即![]() 。
。
②value也是采样局部的value(基于采样点插值出来的value)。即公式2中的![]() 。其中
。其中![]() 表示代表query的位置
表示代表query的位置![]() ,可以理解为2d坐标,
,可以理解为2d坐标,![]() 是采样点相对于参考点的位置偏移(可学习的)。
是采样点相对于参考点的位置偏移(可学习的)。
(3)多尺度可变形多头注意力:MSDeformAttn
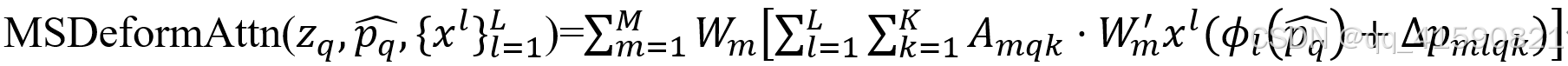
①多尺度,即L代表总共有L层特征,l代表第l层特征。
②pq![]() 代表归一化的参考点坐标,ϕl
代表归一化的参考点坐标,ϕl![]() 表示将归一化后特征坐标映射到第l层特征上去,所以ϕlpq
表示将归一化后特征坐标映射到第l层特征上去,所以ϕlpq![]() 之后,每个参考点在第l ll层上都会有一个对应归一化后的坐标,从而方便我们计算出在不同特征层哪些采样点的位置。
之后,每个参考点在第l ll层上都会有一个对应归一化后的坐标,从而方便我们计算出在不同特征层哪些采样点的位置。
3、引入了参考点,某种程度上起到先验的作用;
4、检测头部的回归分支预测的是bbox偏移量而非绝对坐标值;
DAB-DETR: 将Anchor box重新引入DETR,提供query可解释性并加速收敛
DETR存在两个问题,一是query含义并不清楚,不可解释,二是模型收敛慢。作者发现,DETR收敛慢很大程度上来自于query含义的不明。
改进:
1、直接学习anchor box作为query
引入anchor box的好处有①query有了可解释性。②为模型提供了位置先验,加速收敛。③anchor box中的位置信息可以用来调制注意力图。④anchor box可以层与层进行更新。
为什么DETR中去掉了anchor box,这里又要引用?
并没有重新引入之前需要手动设计的anchor generation,RPN等模块,只是借用anchor的形式来建模query。
2、使用正余弦编码后的x,y作为positional query
3、使用w,h调制注意力图
4、层与层更新anchor box
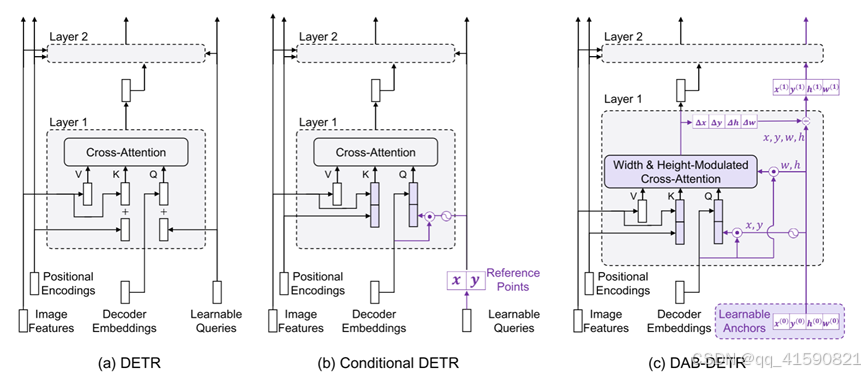
Transformer解码器中的交叉注意部分。
(a)DETR对所有层使用可学习查询而不进行任何调整,这是其训练收敛缓慢的原因。
(b) Conditional DETR主要是为了提供一个更好的参考查询点,以从图像特征映射中汇集特征,从而为每一层调整可学习查询。
(c)DAB-DETR直接使用动态更新的锚框来提供参考查询点(x,y)和参考锚大小(w,h)以改进交叉注意力计算。紫色标记为有差异的模块。
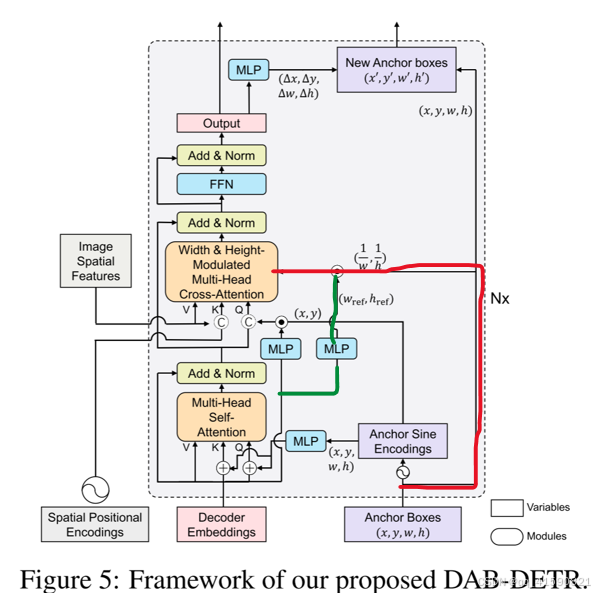
其相比于conditional DETR的区别为
①实际上就是Query作为positional embedding分别concat到feature上。因为每层Decoder都有self-attn和cross-attn,所以用了两次(图中绿线部分)
②在anchor的Embedding上乘个系数(anchor的w和偏移量的w的比值),来调整anchor的宽高—扩大anchor关注的位置(图中红线部分)
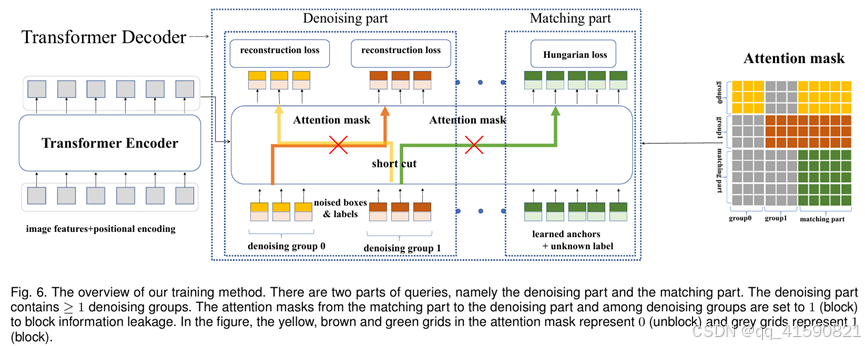
DN-DETR: 去噪训练加速DETR收敛
贡献:
1、设计了一种新的训练方法来加速 DETR 训练。 实验结果表明,本文的方法不仅加速了训练收敛,而且训练结果明显更好——在所有检测算法中取得了最好的结果,并且可以很容易地集成到其他类似 DETR 的方法中。
2、从一个新颖的角度分析了 DETR 的缓慢收敛,并对 DETR 训练进行了更深入的理解。 设计了一个度量来评估二分匹配的不稳定性,并验证本文的方法可以有效地降低不稳定性。
3、本文进行了一系列消融研究来分析本文模型的不同组件的有效性,例如噪声、标签嵌入和注意力掩码。
之前DAB-DETR 认为DETR收敛慢--没有提供位置先验的learnable queries(in Decoder)。DN-DETR指出,导致 DETR 慢收敛另一个原因--匈牙利匹配。
由于匈牙利匹配的离散性和模型训练的随机性,导致了query对gt的匹配变成了一个动态的、不稳定的过程。我们知道,匈牙利算法是一种全局最优的思想,计算出的cost矩阵只要有些许差异,其匹配结果就可能大相径庭。
于是,就同一张图片来说,在不同的训练周期(epoch),同一个query通常会匹配到不同的gt,也就是说它的目标在频繁地切换,特别是在训练的早期。这使得模型的优化有二义性,进而造成优化困难、不稳定,最终的结果就是收敛慢。
由于DN-DETR是延续DAB-DETR的工作,认为decoder在学习两个东西:
good anchors(anchor位置)、relative offset(相对偏移)
使用一个denoising task作为一个shortcut来学习相对偏移,它跳过了匹配过程直接进行学习。通过在真实框附近添加一个微小的扰动作为噪声,这样denoising task就有了一个清晰的目标--直接重建真实框而不需要匈牙利匹配。
label noise: 我们以一定概率随机把真实label翻转为其余的任何一个label。如COCO中有80个类别,我们以一定概率将其翻转为80个中的其他label。加入label的方法类似NLP中的word embedding,把80个类别进行embedding即可。
box noise:box的noise可以分为两类,即中心点漂移(center shifting)和框缩放(box scaling)。对于中心点漂移,我们可以保证中心点仍然在真实框内部并进行漂移。对于框缩放,可以随机缩放框的长和宽。漂移的强度和缩放的大小控制都由超参数进行控制。
Attention mask: 除了加noise之外,在decoder的self attention我们需要加一个额外的attention mask防止信息泄露。因为denoising部分包含真实框和真实标签的信息,直接让matching part看到denoising part会导致信息泄漏。因此,训练的时候matching part不能看到denoising part,像原始模型一样训练。额外增加的denoising part看或者不看到matching part对结果影响不大,因为denosing部分含有最多的真实框和标签。
①匈牙利匹配任务的 queries 不能看到 DN任务的 queries;
②DN任务中,不同组的 queries 不能相互看到;
③其它情况均可见
DINO
Deformable DETR、DAB-DETR、DN-DETR的结合体,但在其基础之上又有了一点改进。
1、Contrastive DeNoising Training
DN-DETR通过去噪训练解决DETR因为匈牙利匹配而导致收敛慢的问题,但是其只学习基于附近有GT框的锚进行预测,缺乏对附近没有对象的锚预测" no object "的能力。为了解决这个问题,提出了一种对比去噪( Contrastive DeNoising:CDN )方法来拒绝无用的锚。
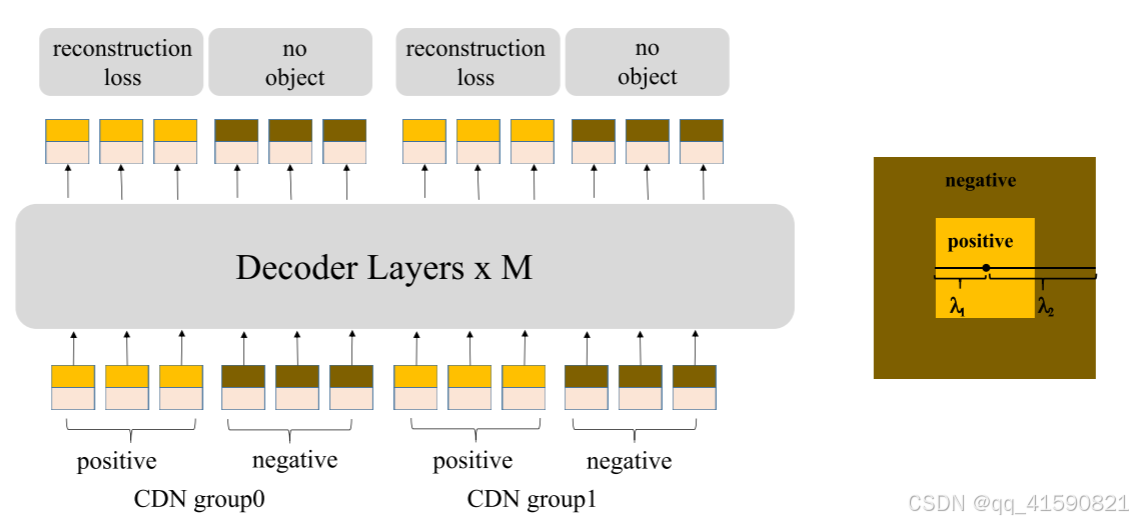
添加了负样本,通过提高模型对背景的识别能力,提高模型的性能。
2、Look Forward Twice
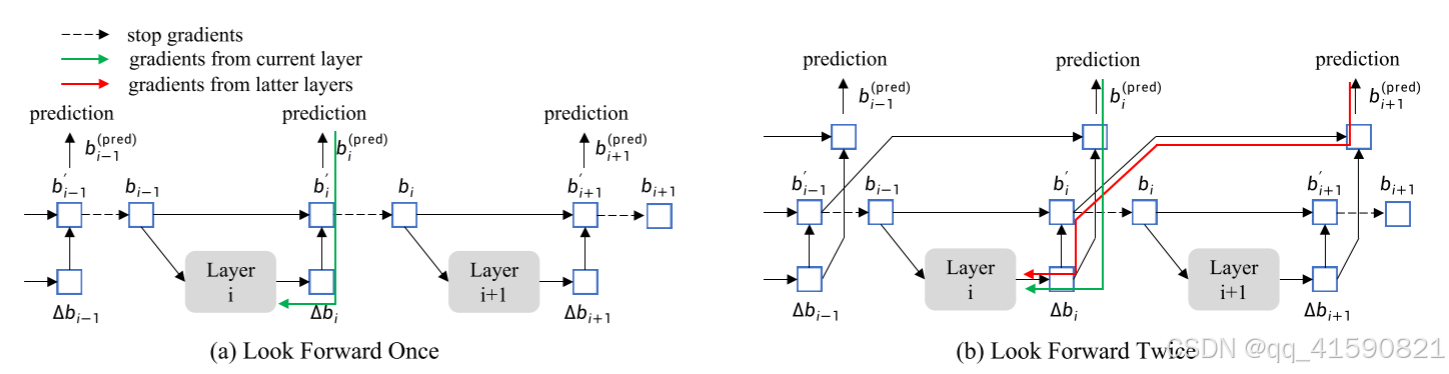
Deformable DETR 的迭代框优化(iterative box refinement)方法可以阻止梯度反向传播来稳定训练-- Look Forward once。decoder每一层都会预测bbox偏移量,使用这一层bbox偏移量对上一层的预测输出进行矫正
Look Forward Twice--用下一层![]() 的输出来监督第i层的最终框
的输出来监督第i层的最终框![]() ,使用
,使用![]() 和
和![]() 作为( i + 1 )层的预测框。
作为( i + 1 )层的预测框。
3、Mixed Query Selection
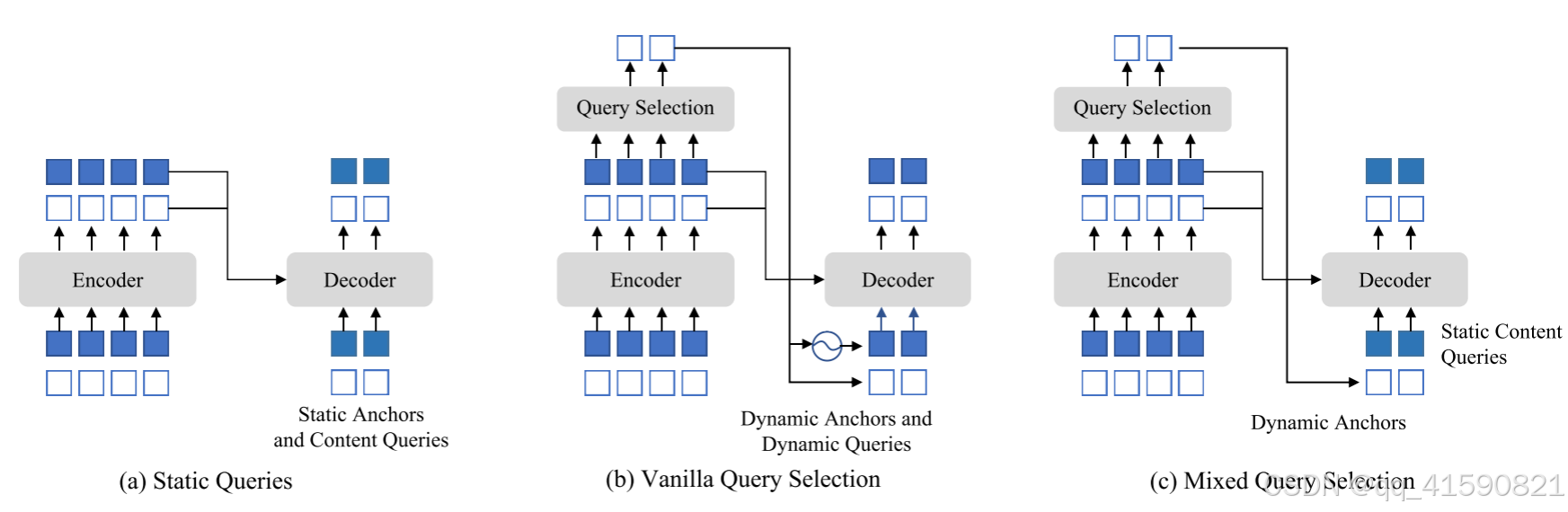
Deformable DETR 同时学习位置查询和内容查询,是静态查询初始化的另一种实现。从最后一个编码器层选择前 K 个编码器特征作为先验来增强解码器查询。Deformable DETR利用top - K特性不仅增强了位置查询,还增强了内容查询。
Mixed Query Selection只增强了具有top - K选择特征的位置查询,并保持了内容查询的可学习性。这有助于模型利用更好的位置信息从编码器中汇集更全面的内容特征。
GROUNDING-DINO
提出了一种开放集对象检测器,通过将基于Transformer的检测器DINO与真值预训练相结合,可以通过人类输入(如类别名称或指代表达)对任意物体进行检测。
优势:
1、基于Transformer的架构类似于语言模型,使它能够轻松的处理图像和语言数据。
2、基于Transformers的检测器在利用大规模数据集方面表现出卓越的能力。
3、DINO可以端到端优化,而无需使用任何手工设计的模块,如NMS(非极大值抑制),这大大简化了整个grounding模型的设计。
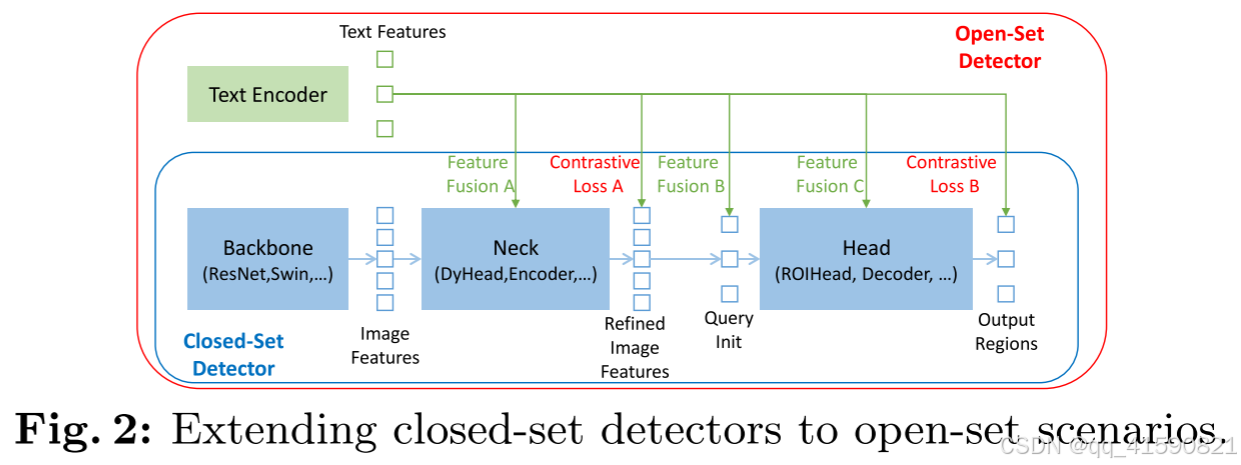
在颈部、query初始化和head阶段设计了三种特征融合方法。更具体地说,我们通过堆叠自注意力、文本到图像的交叉注意力和图像到文本的交叉注意力作为颈部模块来设计特征增强器。然后,我们开发了一种语言引导的查询选择方法来初始化head的查询。我们还为头部阶段设计了一个具有图像和文本交叉注意力层的交叉模态解码器,以增强查询表示。
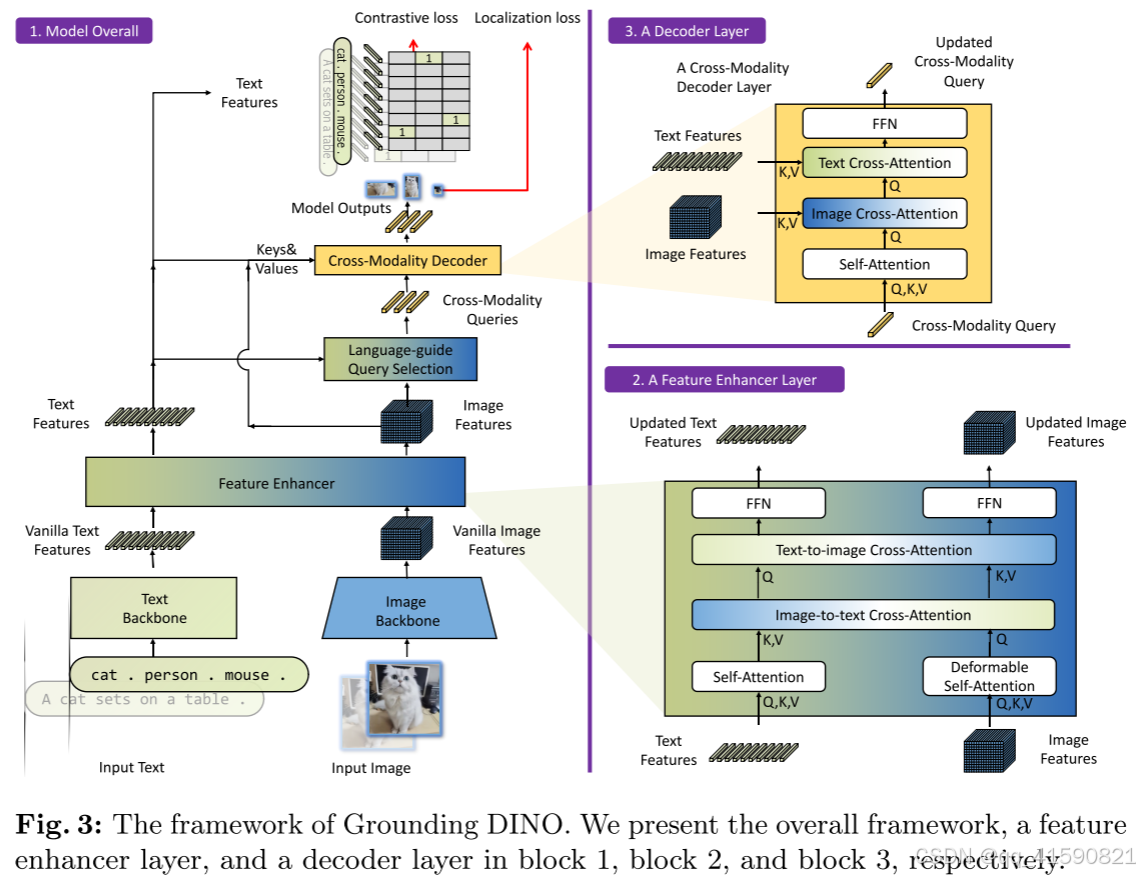
Feature Extraction and Enhancer (特征提取和增强器)
通过不同的主干网络的不同块儿提取多尺度图像特征与文本特征之后,将它们输入到特征增强器中进行跨模态特征融合。可变形的自注意力来增强图像特征,并利用普通的自注意力增强文本特征。添加了一个图像到文本的交叉注意力和一个文本到图像的交叉注意力来进行特征融合。
Language-Guided Query Selection (语言引导的查询选择器)
Grounding DINO旨在从图像中检测输入文本指定的对象。为了有效地利用输入文本来指导对象检测,设计了一个语言引导的查询选择模块,以选择与输入文本更相关的特征作为解码器查询。语言引导查询选择模块输出num_query的多个索引。我们可以根据选择的索引提取特征来初始化查询。
Cross-Modality Decoder
在DINO解码器层基础上,每个解码器层添加一个额外的文本交叉注意力层,将文本信息注入查询中,以实现更好的模态对齐。
Sub-Sentence Level Text Feature
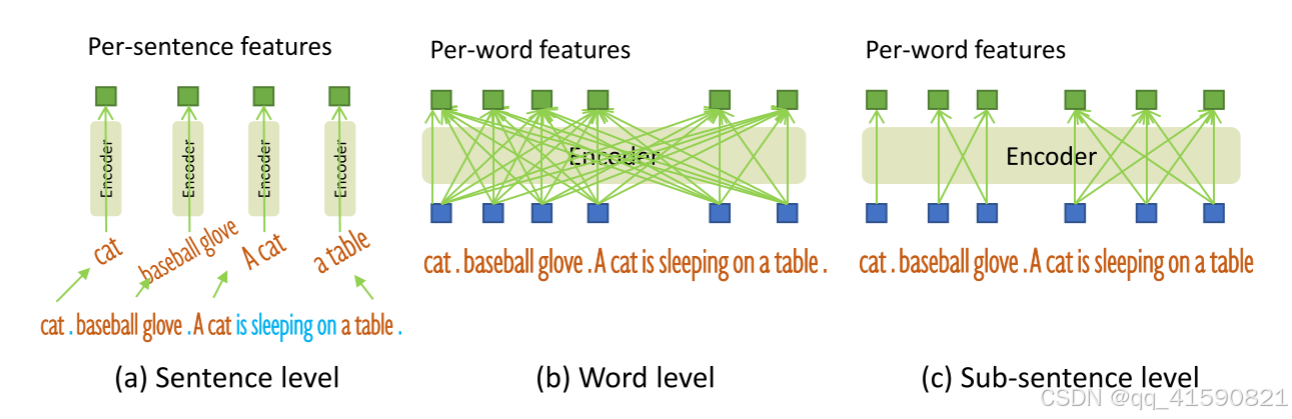
句子级表示将整个句子编码为一个特征。如果一些句子有在短语基础数据库中的多个短语,它会提取这些短语并丢弃其他单词。通过这种方式,它消除了单词之间的影响,同时丢失了句子中的细粒度信息。单词级表示允许用一个正向forward编码多个类别名称,但在类别之间引入了不必要的依赖性,尤其是当输入文本是多个类别名按任意顺序串联时。为了避免不必要的单词交互,我们引入了注意力masks来阻断不相关类别名称之间的注意力,称为“子句”级表示。它消除了不同类别名称之间的影响,同时保留了每个单词的特征,以便进行细粒度的理解。
大模型微调
参数高效微调是指微调少量或额外的模型参数,固定大部分预训练模型(LLM)参数,从而大大降低了计算和存储成本,同时,也能实现与全量参数微调相当的性能。参数高效微调方法甚至在某些情况下比全量微调效果更好,可以更好地泛化到域外场景。
高效微调技术可以粗略分为以下三大类:增加额外参数(A)、选取一部分参数更新(S)、引入重参数化(R)。而在增加额外参数这类方法中,又主要分为类适配器(Adapter-like)方法和软提示(Soft prompts)两个小类。
Prefix Tuning
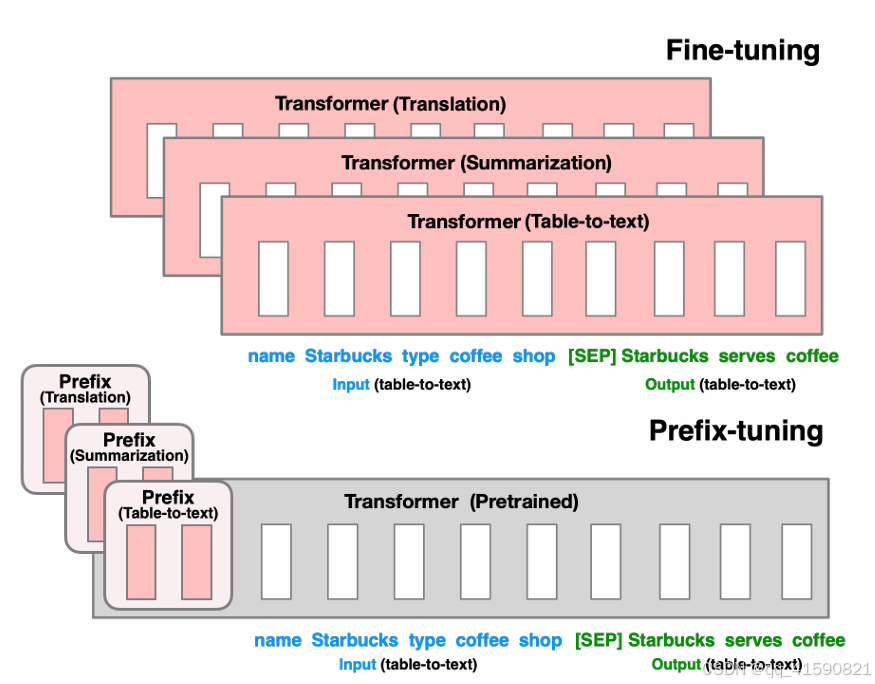
冻结了LM参数,只优化了prefix(红色prefix块)。因此,只需要存储每个任务的prefix,使prefix调优模块化和空间效率。
针对不同的模型结构,需要构造不同的Prefix:
针对自回归架构模型:在句子前面添加前缀,得到 z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如:GPT3的上下文学习)。
针对编码器-解码器架构模型:Encoder和Decoder增加了前缀,得到 z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。
该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
P-TUNING
该方法将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。
相比Prefix Tuning,P-Tuning加入的可微的virtual token(相比于离散的virtual token,更加灵活了),并且只加在了输入层(疑似把其余工作留在了P-TUNING V2);virtual token的位置也不一定是前缀,插入的位置是可选的。
P-TUNING V2
相比于P-TUNING,在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,好处:
(1)更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。
(2)加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
相比于Prefix Tuning移除重参数化的编码器。以前的方法利用重参数化功能来提高训练速度和鲁棒性(如:Prefix Tuning中的MLP、P-Tuning中的LSTM))。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。
针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,我们发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与Prefix-Tuning中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。
引入多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。
多任务学习对我们的方法来说是可选的,但可能是相当有帮助的。一方面,连续提示的随机惯性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。我们的实验表明,在一些困难的序列任务中,多任务学习可以作为P-tuning v2的有益补充。
回归传统的分类标签范式,而不是映射器。标签词映射器(Label Word Verbalizer)一直是提示优化的核心组成部分,它将one-hot类标签变成有意义的词,以利用预训练语言模型头。尽管它在few-shot设置中具有潜在的必要性,但在全数据监督设置中,Verbalizer并不是必须的。它阻碍了提示调优在我们需要无实际意义的标签和句子嵌入的场景中的应用。因此,P-Tuning v2回归传统的CLS标签分类范式,采用随机初始化的分类头(Classification Head)应用于tokens之上,以增强通用性,可以适配到序列标注任务。

















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









