







Grounding DINO 是一种基于深度学习的模型,它在计算机视觉领域内用于实现图像中的目标检测与定位任务。特别地,Grounding DINO 结合了自然语言处理(NLP)的能力,可以理解文本描述并据此在图像中定位和识别相应的对象。
多模态理解:Grounding DINO 能够同时处理文本和图像两种不同形式的数据,这使得它能够根据给定的文本描述来识别和定位图像中的特定目标。这种能力在许多应用中非常有用,比如视觉问答系统、图像标注等。
细粒度定位:除了能够识别图像中的目标,Grounding DINO 还能够提供更加精确的目标边界框,这对于需要高精度定位的应用尤为重要。
开放词汇表检测:与传统的目标检测模型相比,Grounding DINO 不仅限于检测预定义类别列表中的对象,而是可以根据输入的文本描述检测任何对象,这大大扩展了模型的应用范围。
高效性:尽管具有强大的功能,但 Grounding DINO 在设计上考虑到了效率问题,旨在提供快速而准确的检测结果。
-
技术细节
Grounding DINO 建立在 Transformer 架构之上,这是一种在自然语言处理任务中表现出色的神经网络架构。通过使用 Transformer,模型能够有效地捕捉文本和图像之间的复杂关系,从而提高目标检测的准确性。
此外,该模型通常会经过大量的图像-文本对数据集训练,以便学会如何将文本描述与图像中的实际位置对应起来。这样的训练过程要求有高质量的数据支持,以确保模型能够学习到正确的映射关系。
1 Introduction
传统的对象检测系统通常是在一组预定义的对象类别上进行训练,这意味着它们只能识别这些已知类别的对象。然而,“开放集对象检测”(open-set object detection)的目标是开发一个系统,它可以识别并定位图像中由人类语言输入指定的任意对象,无论这些对象是否属于预先定义的类别集合。换句话说,这个系统旨在具备理解新概念的能力,即能够识别训练过程中未见过的新对象。
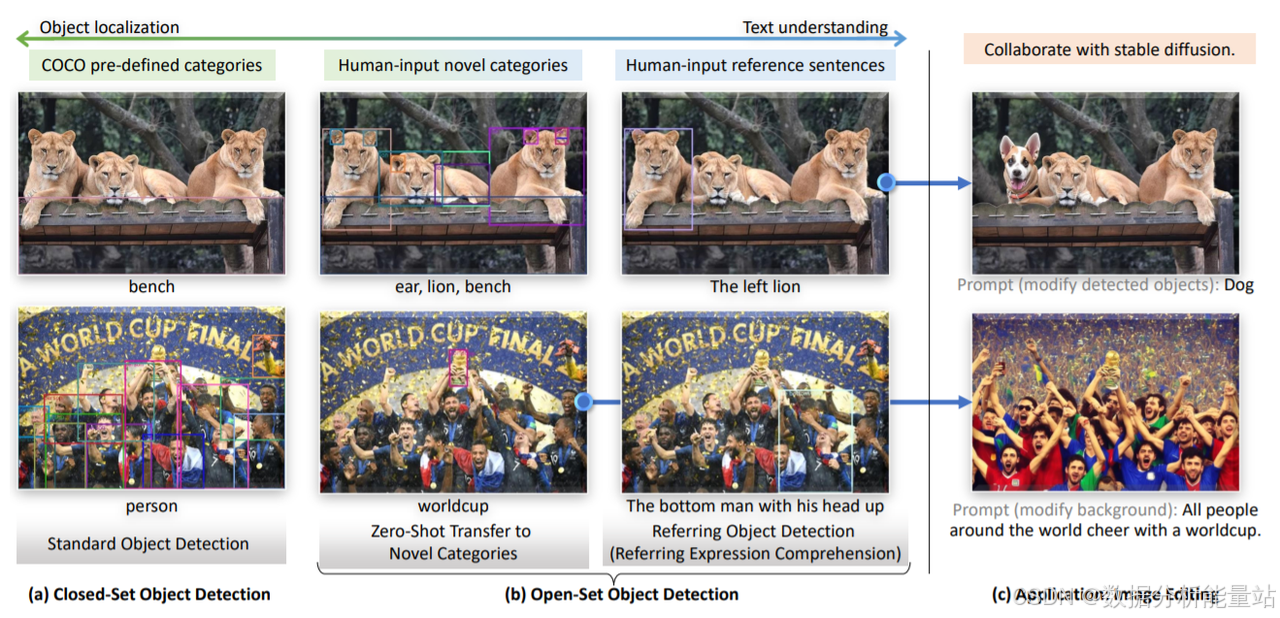
开放集对象检测的核心挑战之一是如何让模型识别和定位那些在训练过程中未曾见过的对象。为了解决这个问题,研究人员引入了自然语言作为额外的信息源,帮助模型理解和泛化新的对象类别。通过这种方式,模型不仅依赖于视觉特征,还能利用文本描述来指导对象检测过程。
示例:GLIP:GLIP(Grounded Language-Image Pre-training)是一个典型的开放集对象检测模型,它通过以下几个关键步骤实现了未见过对象的泛化:
重新定义任务:GLIP将传统的对象检测任务重新定义为短语定位任务。这意味着模型不仅要识别图像中的对象,还要将这些对象与给定的文本短语相对应。
对比训练:为了实现这一目标,GLIP引入了对象区域与语言短语之间的对比训练。具体来说,模型会学习将图像中的每个候选区域与文本短语进行匹配,并最大化正确匹配的得分,同时最小化错误匹配的得分。这种对比训练方法有助于模型学习到更丰富的视觉和语言表示。
异构数据集上的灵活性:GLIP在多种异构数据集上进行了训练和测试,展示了其在不同场景下的灵活性和泛化能力。这些数据集可能包括不同的对象类别、背景和拍摄条件,从而提高了模型的鲁棒性。
GLIP的性能表现
-
封闭集检测:在传统的封闭集对象检测任务中,GLIP表现出色,能够准确地识别和定位已知类别的对象。
-
开放集检测:在开放集对象检测任务中,GLIP同样表现出色,能够根据文本描述识别和定位未见过的对象。
GLIP的局限性
尽管GLIP取得了令人印象深刻的结果,但它仍然存在一些局限性:
基于单阶段检测器:GLIP是基于传统的单阶段检测器(如Dynamic Head)设计的。单阶段检测器虽然速度快,但在某些复杂场景下的检测精度可能不如两阶段检测器(如Faster R-CNN)。因此,GLIP的性能可能会受到这些基础检测器的限制。
鉴于开放集和封闭集检测任务之间的密切关系,研究人员认为一个更强大的封闭集对象检测器可以进一步提升开放集检测的性能。
近年来,基于Transformer的检测器在各种视觉任务中取得了显著的进展。这些模型不仅在封闭集对象检测任务中表现出色,还在处理大规模数据集方面展现了优越的能力。受这些进展的启发,研究人员提出了一个新的模型——Grounding DINO,旨在构建一个强大的开放集对象检测器。
Grounding DINO 的优势
基于Transformer的架构
-
与语言模型相似:Grounding DINO 使用基于Transformer的架构,这使得处理图像和语言数据变得更加容易。由于所有图像和语言分支都是用Transformers构建的,可以轻松地在整个流程中融合跨模态特征。
-
多模态特征融合:Transformer架构的灵活性使得在不同阶段融合图像和语言特征变得更加直观和有效。
利用大规模数据集
-
优越的数据利用能力:基于Transformer的检测器已经证明了利用大规模数据集的优越能力。这意味着Grounding DINO可以从大量图像和文本数据中学习,从而提高其泛化能力和鲁棒性。
端到端优化
-
简化模型设计:作为一个类似于DETR的模型,DINO可以不使用任何硬编码模块(如NMS,Non-Maximum Suppression)进行端到端优化。这极大地简化了整体定位模型的设计,使其更加高效和易于训练。
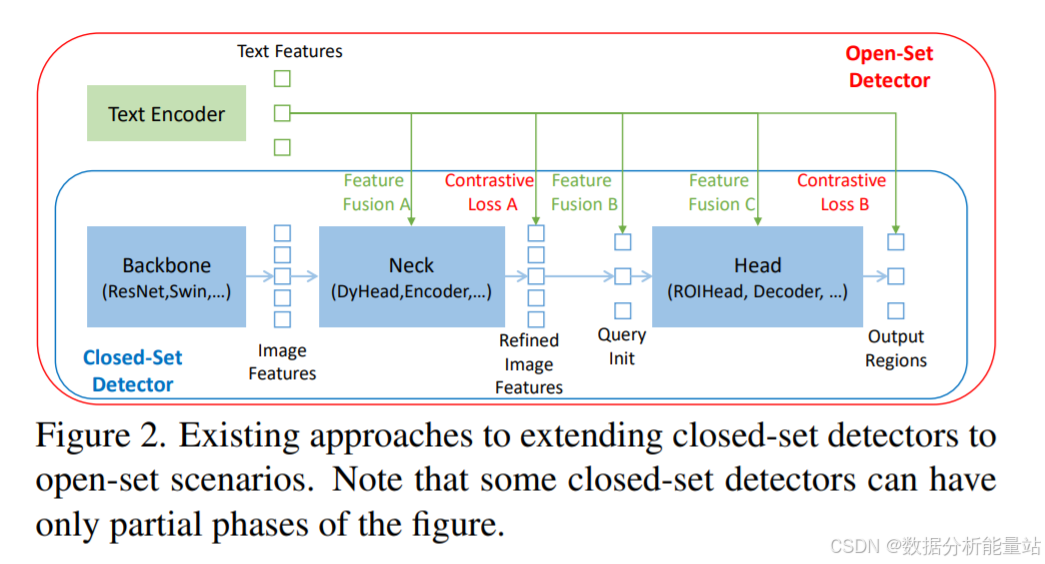
现有开放集检测器的结构
大多数现有的开放集检测器都是通过对封闭集检测器进行扩展并引入语言信息来开发的。这些模型通常包含以下三个重要模块:
-
主干网络(Backbone):用于特征提取,常见的主干网络包括ResNet、EfficientNet等。
-
颈部网络(Neck):用于特征增强,常见的颈部网络包括FPN(Feature Pyramid Network)等。
-
头部网络(Head):用于区域细化或框预测,常见的头部网络包括RPN(Region Proposal Network)等。
泛化到新对象的方法
为了使封闭集检测器泛化到检测新对象,一个关键方法是学习语言感知的区域嵌入。具体来说,每个区域在语言感知的语义空间中被分类到新类别。实现这一目标的关键是使用颈部和/或头部输出的区域输出与语言特征之间的对比损失。
特征融合的阶段
特征融合可以在三个不同的阶段进行,以帮助模型对齐跨模态信息:
-
颈部(阶段A):
-
早期融合:在颈部模块中进行特征融合,例如GLIP[26]就是这样做的。这种方法可以在较早的阶段将图像和语言特征结合起来,有助于模型更好地理解多模态信息。
-
-
查询初始化(阶段B):
-
语言感知查询:在查询初始化阶段使用语言感知的查询作为头部输入,例如OV-DETR[56]就是这样做的。这种方法可以在生成初始查询时就引入语言信息,有助于提高后续检测的准确性。
-
-
头部(阶段C):
-
后期融合:在头部模块中进行特征融合,这种方法可以在最终的检测阶段结合图像和语言特征,进一步提升检测性能。
-
主干网络(Backbone)、 颈部网络(Neck)、 头部网络(Head)详细解释:
主干网络(Backbone)
定义:
主干网络是深度学习模型中负责从输入图像中提取特征的部分。它的主要任务是从原始像素数据中学习有用的特征表示,这些特征将在后续的检测、分类、分割等任务中被进一步处理。
常见架构:
ResNet:残差网络(Residual Networks)是一类非常流行的主干网络,通过引入残差连接解决了深层网络中的梯度消失问题。
VGG:VGGNet 是一个经典的卷积神经网络,以其简单的结构和良好的性能著称。
MobileNet:MobileNet 是一种轻量级的网络,适用于资源受限的设备,通过深度可分离卷积减少了计算量。
EfficientNet:EfficientNet 是一种高效的网络架构,通过复合缩放(compound scaling)技术在模型深度、宽度和分辨率之间找到最佳平衡。
作用:
主干网络的主要作用是从输入图像中提取多尺度的特征图。这些特征图包含了图像的局部和全局信息,为后续的特征增强和目标检测提供了基础。
颈部网络(Neck)
定义:
颈部网络位于主干网络和头部网络之间,负责对主干网络提取的特征进行进一步的处理和增强。它的目的是改善特征的质量,使其更适合后续的任务。
常见架构:
FPN(Feature Pyramid Network):特征金字塔网络是一种常用的颈部网络,通过自顶向下的路径和横向连接将不同尺度的特征图融合在一起,提高了多尺度目标检测的性能。
PANet(Pat
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1564
1564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











