









🐧大模型系列篇章
💖 多模态大模型 🔎 GroundingDINO 论文总结
💖 端到端目标检测 🔎 从DETR 到 GroundingDINO
💖 多模态大模型 👉 CLIP论文总结
💖 多模态大模型 👉 EVA-CLIP
💚 生成模型 👉 从 VAE 到 Diffusion Model (上)
💚 生成模型 👉 从 VAE 到 Diffusion Model (下)
💧 天气大模型
| 欢迎订阅专栏,第一时间掌握最新科技 专栏链接 |
文章目录
先来看一下WiSE-FT微调的能力。很鲁棒是不是!
| 微调代码仓库链接 wise-ft 论文链接 |
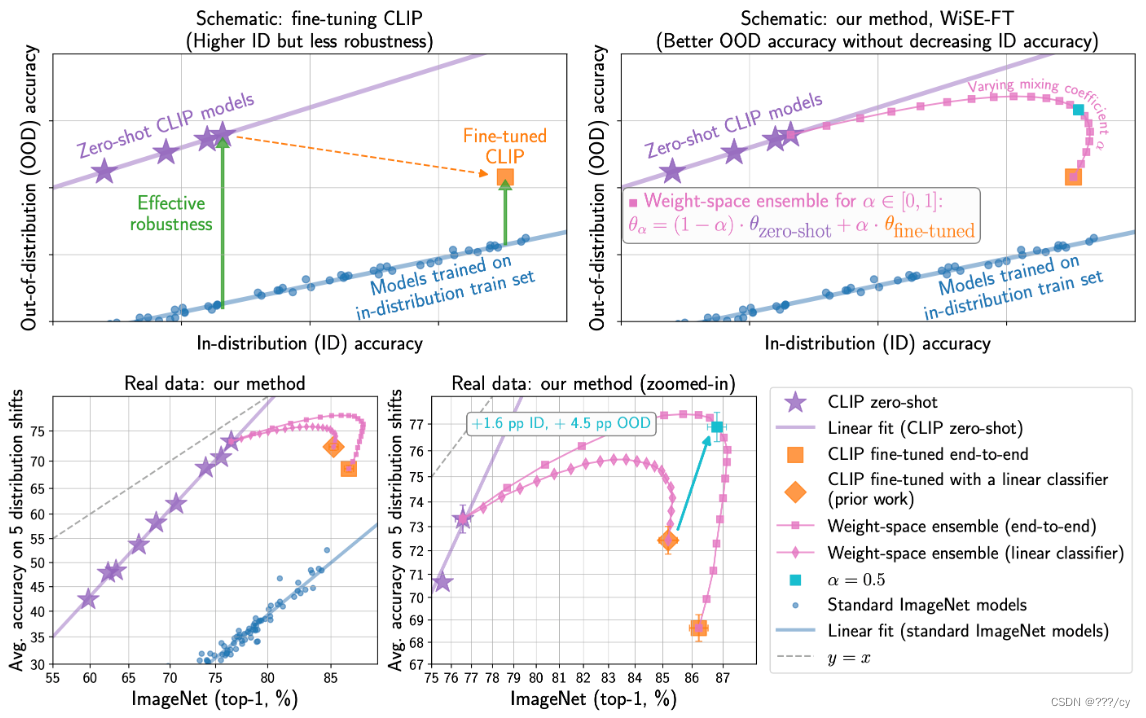
1. 核心问题
零样本模型在未进行微调的情况下表现出色,但在实际应用中,为了提高在特定目标分布上的准确性,通常需要进行微调。然而,传统的微调方法往往会降低模型对分布偏移的鲁棒性。
2. 研究目标
探索如何微调零样本模型,使其在保持或提高目标分布准确性同时,增强对分布偏移的鲁棒性。
3. 主要方法
3.1 WiSE-FT (Weight-space ensembles for fine-tuning)
- 第一步:在目标分布上对零样本模型进行微调。
- 第二步:通过线性插值的方式,将微调后的模型与原始零样本模型进行权重空间集成。
- 这种方法避免了传统微调方法的鲁棒性下降问题,同时简化了超参数的选择。
3.2 主要发现
- 标准微调方法的局限性:
- 超参数的微小变化会对模型的鲁棒性产生显著影响,但最佳超参数无法仅通过目标分布上的准确性来推断。
- 更激进的微调方法(如使用更大的学习率)会提高目标分布上的准确性,但会大幅降低模型的鲁棒性。
- WiSE-FT 的优势:
- 在 ImageNet 和五个基于 ImageNet 的分布偏移数据集上,WiSE-FT 相比于其他方法,在分布偏移数据集上的平均准确性提高了 4 到 6 个百分点,同时在 ImageNet 上的准确性也提高了 1.6 个百分点。
- WiSE-FT 在六个其他分布偏移数据集上也取得了类似的鲁棒性提升,并在七个常用的迁移学习数据集上实现了 0.8 到 3.3 个百分点的准确性提升。
- WiSE-FT 在低数据场景下也能提升模型性能。
- WiSE-FT 的理论基础:
- 零样本模型和微调后的模型在预测上具有互补性,在目标分布上,微调模型更自信,而在分布偏移数据集上,零样本模型更自信。
- WiSE-FT 在权重空间中进行线性插值,可以有效地利用两种模型的优点,并找到在损失表面上更优的解。
- WiSE-FT 的适用性:
- WiSE-FT 不仅可以应用于 CLIP 模型,还可以应用于其他零样本模型,例如 ALIGN、BASIC 和基于 JFT 预训练的 ViT 模型。
3.3 未来研究方向
- 探索 WiSE-FT 在其他领域(如目标检测和自然语言处理)中的应用。
- 研究如何找到特定目标分布下最优的权重混合系数 α。
- 探索 WiSE-FT 的理论基础,例如损失表面形状和目标与偏移分布之间误差关系的精确描述。
4. 总结
WiSE-FT 是一种简单有效的微调方法,可以显著提高零样本模型对分布偏移的鲁棒性,同时保持或提高目标分布上的准确性。这种方法为微调零样本模型提供了一种新的思路,并有望在更多领域得到应用。
5. 代码实现(超简单!)
其实就是这个公式:

# Load models
zeroshot = ImageClassifier.load(zeroshot_checkpoint)
finetuned = ImageClassifier.load(finetuned_checkpoint)
theta_0 = zeroshot.state_dict()
theta_1 = finetuned.state_dict()
# make sure checkpoints are compatible
assert set(theta_0.keys()) == set(theta_1.keys())
# interpolate between checkpoints with mixing coefficient alpha
theta = {
key: (1-alpha) * theta_0[key] + alpha * theta_1[key]
for key in theta_0.keys()
}
# update the model acccording to the new weights
finetuned.load_state_dict(theta)
# evaluate
evaluate(finetuned, args)
GroundingDINO的finetune中用到了wise-ft的微调技术。















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









