









摘要
由于成本低廉且易于部署,侧扫声呐是最广泛使用的水下探测仪器之一。然而,海洋环境的复杂性以及目标获取的困难限制了侧扫声呐的检测精度。为了解决这些问题,本研究提出了一种基于Cycle-Consistent Generative Adversarial Network(CycleGAN)模型和改进YOLOv8模型的少样本目标检测方法。首先,考虑到获取侧扫声呐目标图像的困难,所提方法利用CycleGAN模型从光学图像生成伪侧扫声呐图像进行数据增强。其次,通过添加注意力机制、采用可变形卷积网络并更新损失函数,修订了原始YOLOv8模型,以提高侧扫声呐图像的目标检测精度。实验结果表明,CycleGAN模型在生成伪侧扫声呐图像方面有效,并且改进后的YOLOv8模型在侧扫声呐图像目标检测中表现更好。此外,数据增强与改进YOLOv8模型的结合显著提高了侧扫图像的目标检测精度。所提方法能够有效提高水下声呐在海洋勘测中的目标检测效率。
引言
随着声学传感技术和声纳设备的不断发展,利用声纳图像进行水下目标检测已成为一个日益重要的研究领域。全球的军事专家、学者和研究人员对这一领域表现出极大的兴趣,水下目标检测具有广阔的应用前景 [1]。传统的声纳图像目标检测算法主要包括基于统计数学、数学形态学和像素级方法 [2]。然而,这些方法的检测性能较差,且检测时间较长。因此,需要更好的方法来提高声纳图像的检测精度,并减少检测时间。近年来,随着深度学习目标检测模型的快速发展,越来越多的研究人员采用深度学习方法进行水下目标检测 [3]。目前,基于深度学习的目标检测方法在声纳图像领域取得了卓越的表现并得到了广泛应用。这些方法主要分为单阶段方法和两阶段方法,也分别称为候选区域基础和回归基础的目标检测方法。单阶段方法以“你只看一次”(YOLO)系列为代表,直接获得目标类别的概率和位置坐标 [4],与两阶段方法相比,表现出显著更快的性能。检测结果提供了一个反映目标是否存在的置信度参数和一个描述边界框位置的坐标参数。然而,单阶段方法通过主干网络直接提供目标类别和位置的相关信息,而没有使用区域提议网络,因此其精度略低于两阶段方法。因此,单阶段检测更适用于需要高实时性和检测效率的任务,并且对于水下目标检测是有效的。
许多研究表明,YOLO系列算法在水下目标检测中表现良好。王等人 [5] 提出了基于YOLOv3网络的水下目标检测系统,表明YOLOv3是提高侧扫声呐目标检测精度的有效方法。范等人 [6] 提出了一种改进的基于YOLOv4的声呐目标检测与分类算法,极大地减少了网络参数冗余并提高了模型效率。此外,余等人 [7] 提出了结合变换器与YOLOv5s的实时自动目标检测方法,进一步提高了侧扫声呐目标的检测精度。YOLOv7和YOLOv8模型也已得到改进,并在侧扫声呐图像中取得了更高的检测精度 [8,9]。然而,由于声呐数据集的限制和图像样本的不足,目前声呐图像目标检测方法的精度仍有待提高。
为了解决小样本问题,数据增强方法被广泛应用。现有的数据增强方法包括时域和频域增强方法。时域增强方法包括直方图均衡化、对比度拉伸、灰度变换、平滑滤波和锐化滤波。频域增强方法包括傅里叶变换、小波变换、高频增强滤波和低频增强滤波。现代数据增强方法利用深度学习算法,如生成对抗网络(GAN),通过生成伪图像来增强目标图像样本。
GAN的应用也推动了声呐目标图像生成的研究。Sung等人 [10] 提出了使用GAN生成伪声呐图像的方法。无需配对声呐和其他源图像,Cycle Consistent Generative Adversarial Network(CycleGAN)模型继承了GAN的对抗训练思想,采用双重训练学习方法实现源领域和目标领域之间的映射 [11]。因此,当面临小样本侧扫声呐数据集时,CycleGAN模型可以实现从光学遥感图像到侧扫声呐图像的风格转移任务。刘等人 [12] 提出了一种基于CycleGAN模型生成伪前视声呐图像的方法,该方法基于声呐图像建模软件生成的数据集,成功生成了逼真的前视声呐数据。周等人 [13] 提出了基于CycleGAN模型的改进风格转移模型,该模型使用光学图像生成声呐图像,并在增强真实声呐数据后提高了目标检测模型的精度。尽管许多研究者已证明使用GAN生成声呐图像的有效性,但相关研究在侧扫声呐图像目标检测领域的应用仍然较少。
为了提高仅有少量样本的侧扫图像的底部检测精度,本研究结合了最新的数据增强方法和目标检测模型。我们提出的方法的主要贡献如下:
为了提高侧扫图像的检测精度,原始YOLOv8模型进行了修订,具体通过在主干网络和颈部添加注意力机制,使用C2f-DCNv3模块替换C2f模块,并采用EIoU损失更新损失函数。
2.
结合使用CycleGAN进行数据增强和改进后的YOLOv8模型,增强了在仅有少量样本的情况下,侧扫声呐图像目标检测的精度和鲁棒性。
在接下来的部分中,使用CycleGAN模型从光学遥感图像生成侧扫声呐图像,以解决小样本问题。然后,对原始YOLOv8模型进行修订,以提高声呐图像目标的检测精度。在实验中,验证了数据增强模型和改进后的YOLOv8模型的有效性,且与现有方法相比,所提方法取得了更好的检测精度。
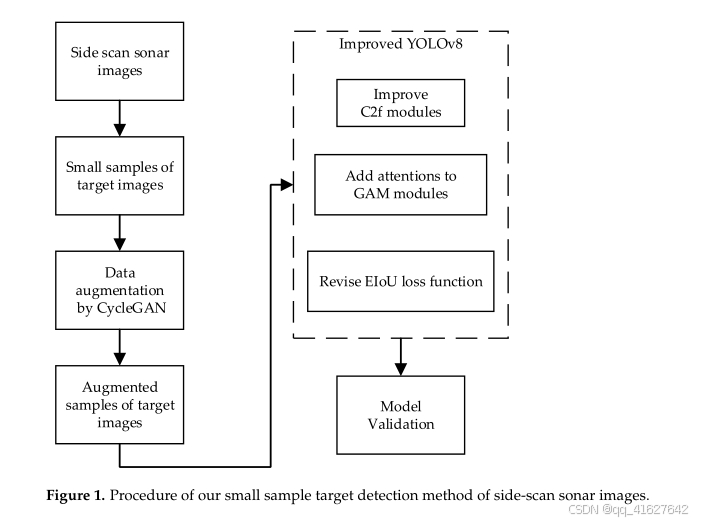
2.1. 使用CycleGAN模型进行数据增强
除了CycleGAN模型,其他风格迁移模型(如Pix2Pix)通常需要成对的训练图像数据集。然而,使用侧扫声呐图像时,几乎不可能找到成对的光学–声呐图像集。由于CycleGAN模型仅需无配对图像,因此从光学遥感图像到侧扫声呐图像的风格转移变得可行。
2.1.1. CycleGAN模型结构
CycleGAN模型基于GAN使用两个生成器和两个判别器网络,实现两个图像数据集X和Y之间的互映射。CycleGAN结构是由两个对称的GAN组成的循环网络,如图所示。该模型有两对GAN,每对包含一个生成器和一个判别器。生成器用于在光学图像和声呐图像之间进行风格转移。光学图像C作为输入,生成器Gc将C转换为伪声呐图像Gc©。然后,生成器Gs将Gc©转换为伪光学图像C′。对称地,侧扫声呐图像 (S) 作为输入,生成器Gs将S转换为伪光学图像Gs(S),然后生成器Gc将Gs(S)转换为伪声呐图像S′,判别器则用于区分真实图像和生成的伪图像(Gc©和Gs(S))。
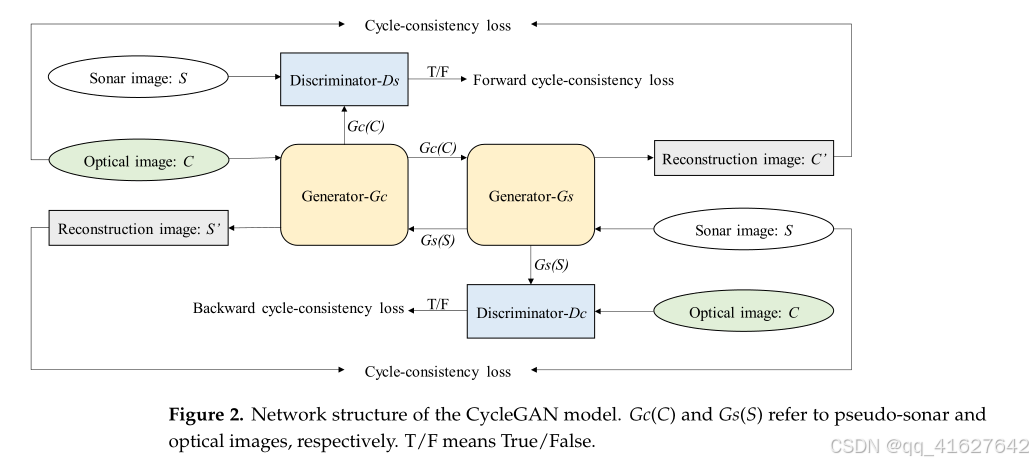
CycleGAN的目标是最小化生成图像和真实图像之间的差异,以保持S到S′和C到C′在图像风格转移中的一致性,因此引入了循环一致性损失。由此,CycleGAN模型的损失函数由对抗损失LossGAN和循环一致性损失Losscycle组成,如下所示。
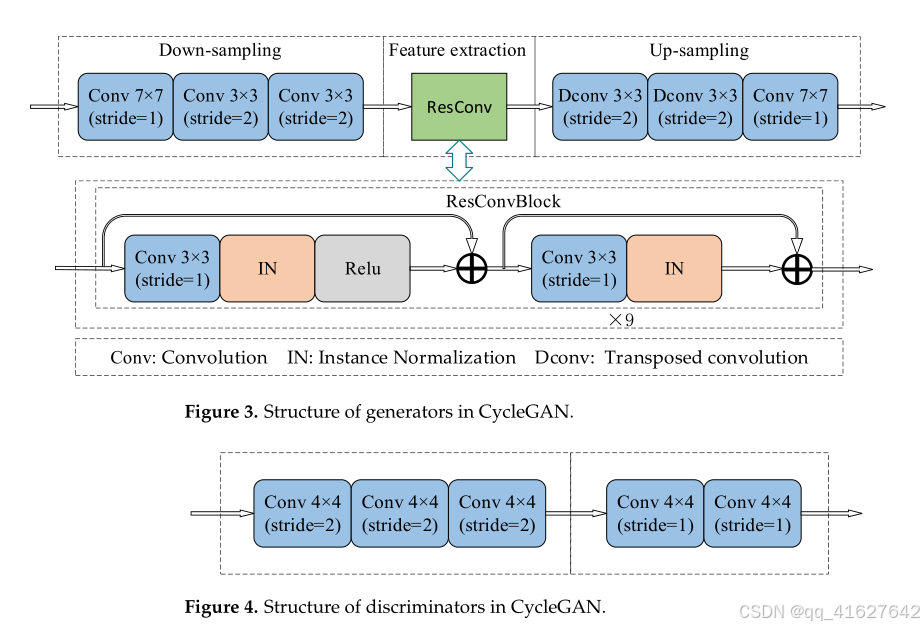
2.1.2. CycleGAN模型的生成器和判别器
在所提CycleGAN模型中,每个生成器由三个部分组成:下采样、特征提取和上采样,如图3所示。
下采样:由三个卷积层组成,旨在减少图像尺寸并扩大感受野。
特征提取:由九个堆叠的残差卷积块构成,每个块有助于学习更复杂的特征,从而提高生成图像的质量。
上采样:由三个卷积层组成,旨在将特征图恢复到与输入图像相同的尺寸。
我们CycleGAN模型中使用的判别器是PatchGAN [14,15],它是一个全卷积网络,如图4所示。PatchGAN的感受野设置为70 × 70像素,对应于输入图像中的一个小区域,使训练模型能够更专注于图像细节。
实验与结果
原始数据集包含164张侧扫声呐图像(其中101张为沉船目标图像,63张为飞机目标图像),所有图像均从网络上收集,如图6所示。
实验平台配置如下:AMD Ryzen 5 2600X CPU,NVIDIA GeForce RTX 2070 GPU(8 GB显存),操作系统为Ubuntu 22.04(美国加利福尼亚州圣克拉拉)。实验在PyTorch框架下进行,使用CUDA 12.2和Python 3.10。
3.1. 伪侧扫声呐图像生成实验
从网络上收集了500张光学遥感图像(包含飞机和船舶目标)和123张侧扫声呐目标图像。然后,使用CycleGAN模型将光学图像转换为声呐图像进行风格迁移。训练期间,CycleGAN的参数设置如下:批量大小为1,输入图像尺寸为256×256像素,初始动量为0.5,学习率为0.0002,前150个epoch保持不变,接下来的100个epoch线性下降至0。其他参数使用默认值。
实验共生成448张伪侧扫声呐图像,其中204张为飞机目标图像,244张为沉船目标图像。如图7所示,CycleGAN模型在将光学遥感图像转换为侧扫声呐图像的风格迁移方面表现良好。

为了验证CycleGAN的有效性,将生成的图像与其他风格迁移模型(PhotoWCT、AdaAttN和AdaIN)在相同数据集上的结果进行了比较,如图8所示。

3.2. 目标检测实验
在本实验中,使用了164张真实和394张伪侧扫声呐图像,每张图像仅包含一个目标。使用LabelImg软件(v1.8.6)对图像中的目标位置进行了标注。沉船和飞机目标图像分别标记为0(“船”)和1(“飞机”),分类和检测框信息保存在XML文件中。实验中采用了早停机制,以防止过拟合并节省训练时间。训练参数设置如下:输入图像尺寸为640×640像素,批量大小为16,初始学习率为0.01,动量为0.937,权重衰减为0.0005。优化器使用随机梯度下降,训练周期设置为200。
3.2.1. 仅使用改进的YOLOv8进行目标检测
为了扩大样本量,采用了传统的数据增强方法,包括镜像、翻转、旋转、缩放和去噪。在此部分实验中,没有使用CycleGAN进行数据增强。每个分类的样本数量如表1所示。

为验证对原始YOLOv8模型的改进效果,进行了消融实验,通过逐步添加改进模块(即C2f-DCNv3、GAM和EIoU损失),比较不同模型的结果,具体结果见表2。
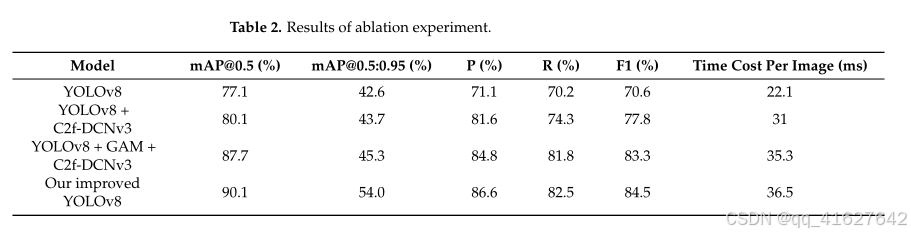
在原始YOLOv8模型的基础上,依次引入C2f-DCNv3、GAM和EIoU损失后,mAP@0.5的准确率分别提高了3%、10.6%和13%。这些结果表明,所提出的改进有效提升了YOLOv8模型的检测精度。
改进后的YOLOv8模型对单张图像的处理时间为36.5毫秒,高于原始YOLOv8模型的22.1毫秒。然而,改进后的模型仍能满足侧扫声呐图像目标检测的实时性要求。
综上所述,改进后的YOLOv8模型在检测精度和实时性方面均表现出色,证明了所提出的改进方法的有效性。
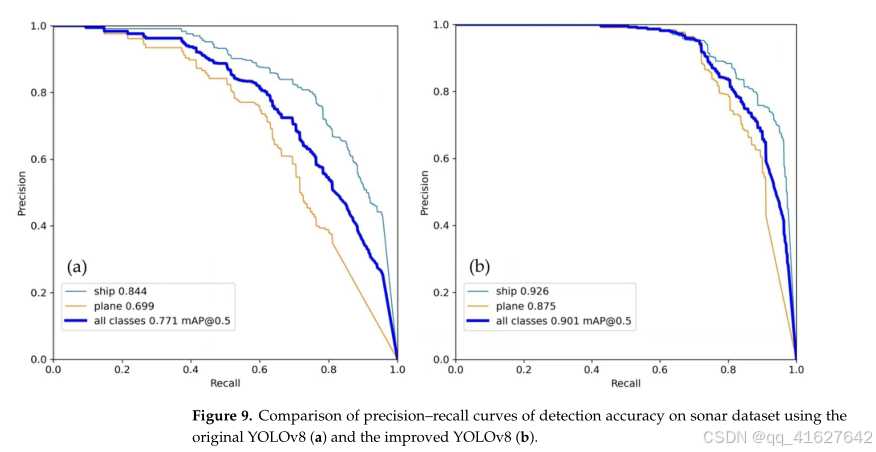
在原始YOLOv8模型和改进后的YOLOv8模型在数据集上的目标检测结果(未使用伪侧扫声呐图像数据增强)如图9所示。 原始YOLOv8模型存在较多漏检,mAP@0.5为0.771,而改进后的YOLOv8模型将mAP@0.5提高至0.901。 改进后,整体检测精度提高了13%,其中沉船和飞机目标的检测精度分别提高了8.2%和17.6%。 为了进一步验证改进模型的性能,我们将其与其他现代目标检测模型在相同数据集上的结果进行了比较,结果如表3所示。 DETR [32]是一个两阶段目标检测模型,其mAP@0.5仅为41.2%;原始YOLOv8、YOLOv9 [33]、YOLOv10 [34]和YOLOv11 [35]的mAP@0.5分别为77.1%、82.5%、82.5%和82.5%。 改进后的YOLOv8模型的mAP@0.5为90.1%,比原始YOLOv8和YOLOv9高出13%和7.6%,比最新的YOLOv10和YOLOv11高出15.6%和13.6%。 此外,我们的模型在mAP@0.5:0.95、精度(P)、召回率(R)和F1分数方面也表现最佳。 这些结果显示了我们改进后的YOLOv8模型相较于其他模型的优势。
在本实验中,使用CycleGAN生成伪图像,以分析真实图像与伪图像的不同比例对目标检测精度的影响。 我们设置了六个不同的数据集,具体比例如表4所示。 训练集F仅包含伪图像。 从数据集A到D,训练集中的伪图像数量依次为真实图像数量的1到4倍。 对于飞机目标,随着伪图像数量的增加,分类精度在数据集A到C中有所提高,但在数据集D中有所下降。 对于船舶目标,分类精度在数据集A到D中略有提高。 此外,如果仅使用数据集F中的伪图像进行训练,并在真实声呐图像上评估,目标检测性能将低于在数据集A到D上的表现。 基于上述数据集,在数据集E中,包含飞机目标的伪图像数量是实际图像的三倍。
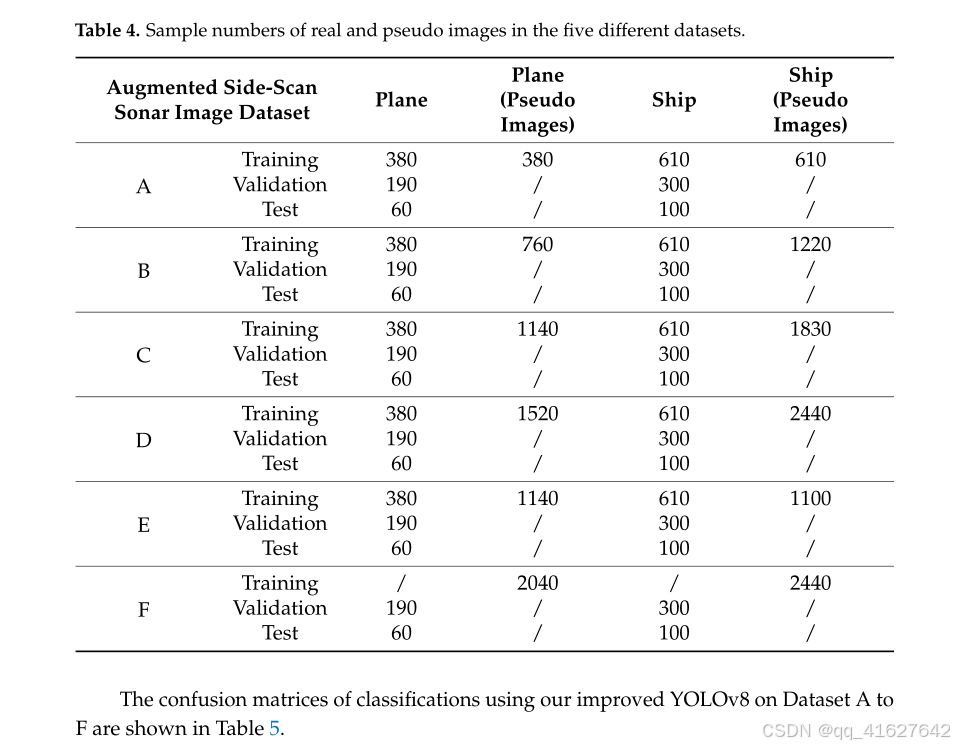
根据上述数据集,在数据集E中,包含飞机目标的伪图像数量是实际图像的三倍。为了平衡训练集中飞机和船只的样本数量,包含船只目标的伪图像数量是实际图像的1.8倍。因此,YOLOv8模型在数据集E上的分类准确率最高(飞机目标为0.91,船只目标为0.97)
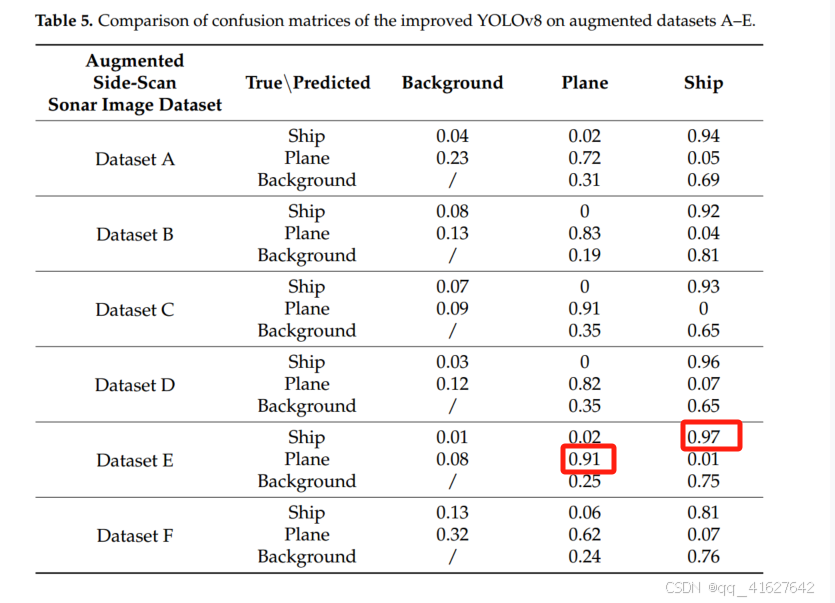
为了展示结合CycleGAN和改进的YOLOv8模型的优势,我们在数据集E上进行了底部检测实验,结果如图10所示。整体检测准确率mAP@0.5为0.924,比初始数据集上的结果(图9,表1)高出2.3%。此外,船只和飞机目标的检测准确率mAP@0.5分别为0.961和0.886,分别比结果高出3.5%和1.1%(图9)
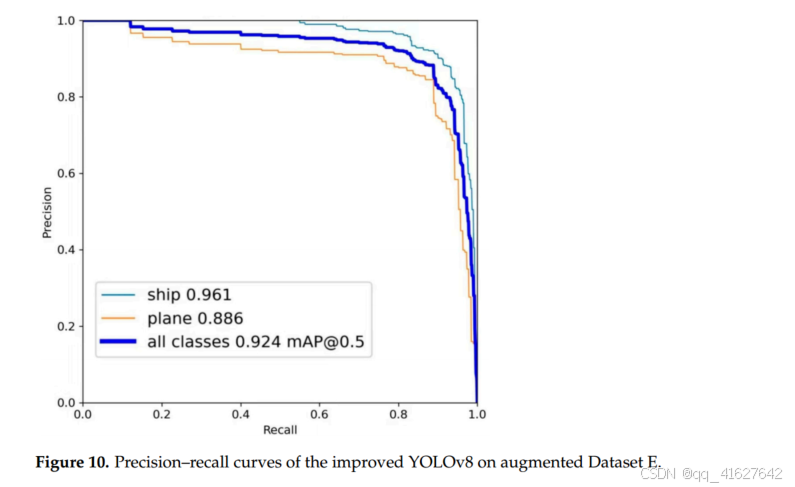
这些结果证明了CycleGAN数据增强在提高小样本侧扫声纳图像目标检测精度方面的有效性。
3.2.3 可视化分析
为了直观地比较不同方法之间的差异(原始YOLOv8模型、改进后的YOLOv8模型和使用CycleGAN进行数据增强的改进模型),这些方法的目标检测结果以图像和检测框的形式展示在图11中。
对于图11中的A列和B列图像(图11),图像A©和B©的检测准确率(mAP@0.5)最高,其次是图像A(b)和B(b)的结果,图像A(a)和B(a)的结果最差。
对于C列的图像,原始YOLOv8模型未能检测到目标(图像C(a)),而图像C(b)和C©的检测结果是成功的。图像C©的mAP@0.5为0.89,高于图像C(b)的0.70。
对于D列的图像,图像D(a)和D(b)存在误检,错误地将飞机目标检测为船目标,而图像D©的检测结果依然正确。
对于E列的图像,尽管三种方法都未漏检飞机目标,图像D©仍然发生了误检,将岩石目标误检测为飞机目标。
对于F列的图像,图像F(a)发生了误检,将飞机目标误检测为船目标。图像F(a)漏检了目标。在图像F(a)中,尽管存在误检,但飞机目标得到了正确的检测。
对于G列和H列的小目标图像,三种方法均正确检测了目标。图像G(b)和G©的mAP@0.5分别为0.85和0.89,都高于图像G(a)的0.79。此外,H列的图像噪声较大。图像H©的mAP@0.5为0.88,高于图像H(a)的0.81,并略低于图像H(b)的0.93。
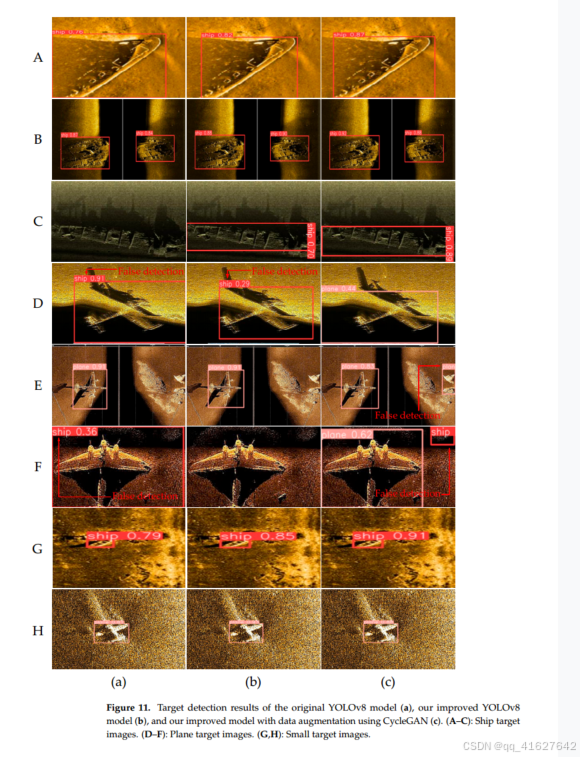
对比结果表明,本文提出的CycleGAN与改进的YOLOv8相结合的检测方法在小样本侧扫声纳图像的目标检测中具有更高的精度和鲁棒性。
4.1 改进YOLOv8模型在通用数据集上的验证
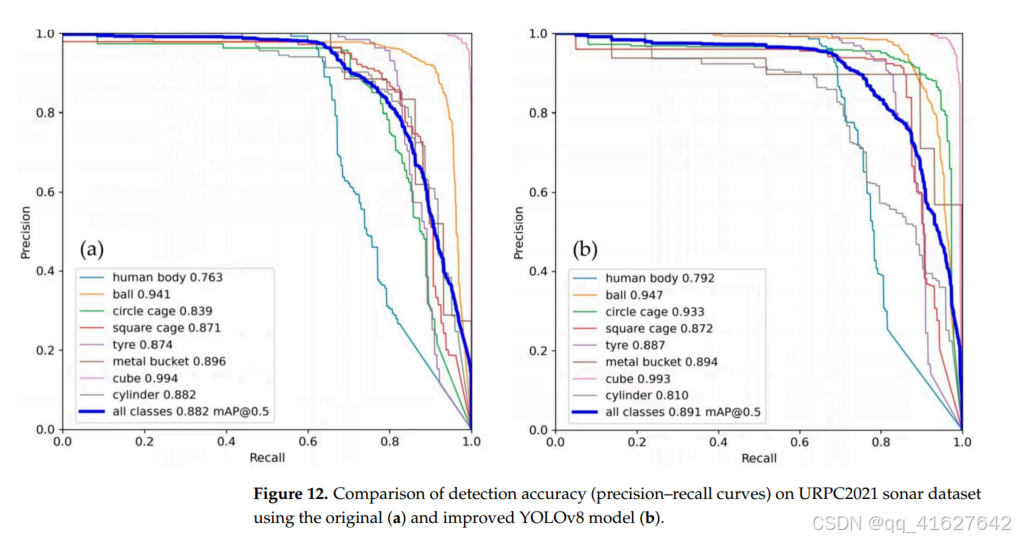
为了验证改进后的YOLOv8模型的泛化能力,本文在官方竞赛数据集URPC2021 [36]上进行了验证。该数据集是我们训练模型未见过的声纳数据。该数据集的特点是,声纳图像通常具有较低的分辨率、高噪声水平、模糊的目标和复杂的背景。原始YOLOv8模型和改进YOLOv8模型的检测结果如图12所示。
改进后的YOLOv8模型的整体mAP@0.5为89.1%,相比原始YOLOv8模型提高了0.9%。这些结果表明,改进后的模型不仅在侧扫声纳图像上有所增强,而且在其他声纳数据集上也表现良好,进一步证明了模型改进的有效性。
在当前的伪侧扫声纳图像生成方法中,侧扫声纳图像被视为一种图像风格,但忽略了其成像机制。例如,尽管我们生成的图像中保留了阴影部分(如图7和图8所示),但阴影的方向是随机的。此外,根据声纳数据采集的特性,阴影通常伴随着目标强度的明显增加。然而,CycleGAN的像素级转换无法完全复制侧扫声纳的成像物理过程。
真实的侧扫声纳图像能够反映声波频率、声波散射角度与海底材料散射特性之间的物理关系。为了增强生成图像的物理一致性,可以在损失函数中引入物理驱动的约束,或在生成器中嵌入模拟物理过程(如声波传播)的模块。此外,还可以将物理参数(如声波频率、入射角度和水深)添加到输入参数中。然而,简化的物理模型可能仍会导致生成图像与真实数据之间的偏差,且增加的计算复杂性可能影响训练效率。
在未来的研究中,可以探索将物理模型与深度学习相结合的混合框架,使模型能够生成具有与真实声纳图像相似物理特征的伪侧扫声纳图像。通过不断扩展侧扫声纳数据集、更新目标检测模型和优化模型轻量化,可以进一步提高侧扫声纳图像中目标检测的有效性、准确性和速度。
结论
本研究提出了一种结合CycleGAN和改进YOLOv8模型的水下小样本目标检测方法,以解决水下目标检测中的限制。 为提高侧扫声纳图像的检测精度,原始YOLOv8模型通过在主干和颈部模块中添加GAM,使用C2f-DCNv3模块替代C2f模块,并采用EIoU作为损失函数进行了改进。 伪图像生成实验结果通过与其他风格迁移模型的比较,验证了CycleGAN的有效性和优势。 在目标检测实验中,通过消融研究验证了改进方法的有效性。 实验结果显示,与原始YOLOv8模型相比,检测模型的mAP@0.5提高了13%。 此外,结合使用CycleGAN进行数据增强和改进的检测模型,进一步将检测精度(mAP@0.5)提高到0.924,证明了方法的有效性。

















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









