






Labelme 脊柱椎体关键点数据集标注 项目 教程
- 一、-------------Lebelme 的安装(基于anaconda)与使用---------------
- 二、--------------脊柱 数据集 介绍 以及需要标注的关键点--------------------
- 三、--------------labelme 如何标注脊柱数据 关键点 --------------------------
- 1、 根据一.2启动labelme
- 1.2 标记之前把这个关掉(这个地方每次打开labelme软件是默认勾选的,所以注意一下)
- 2、开始标注(以冠状位为例,其他方位是一样的操作,视频教程)
- 3、冠状位标注结果
- 4、标注过程注意事项
- 5、标注结果注意
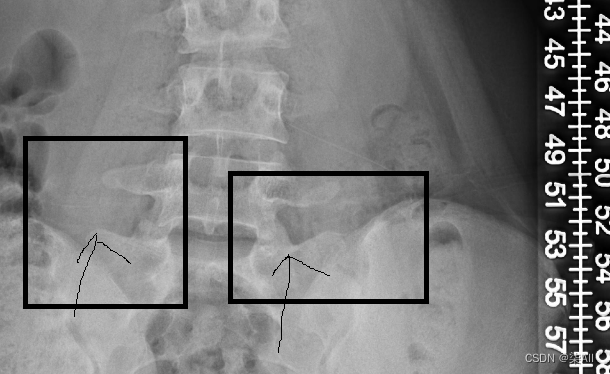
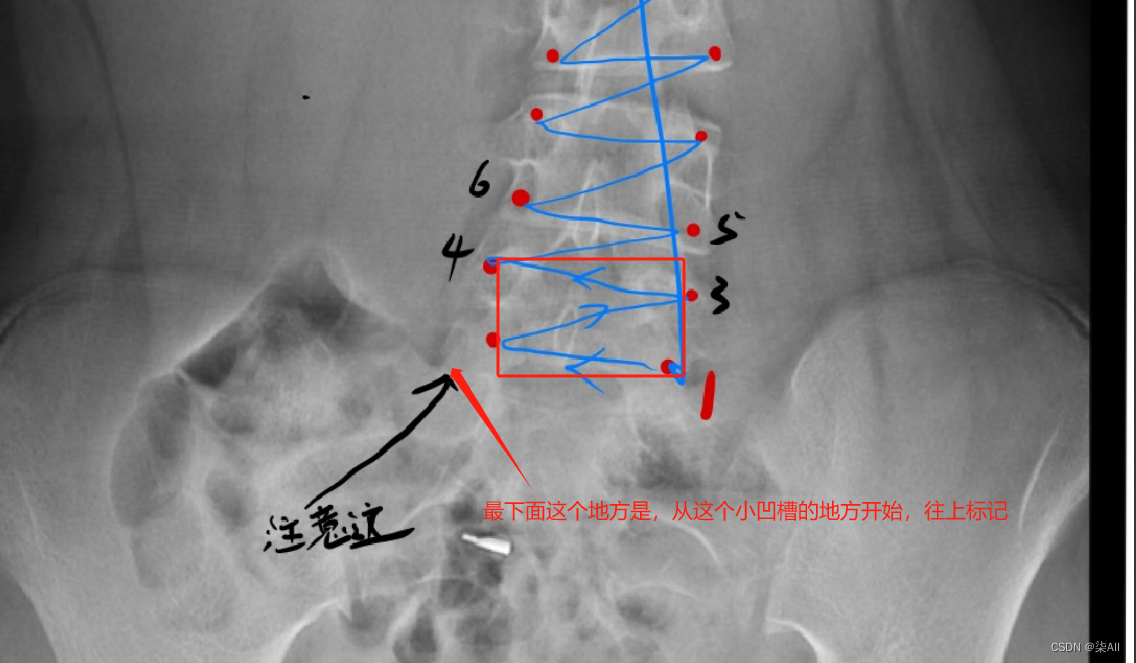
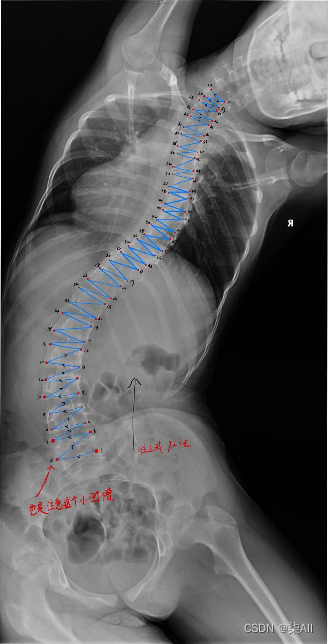
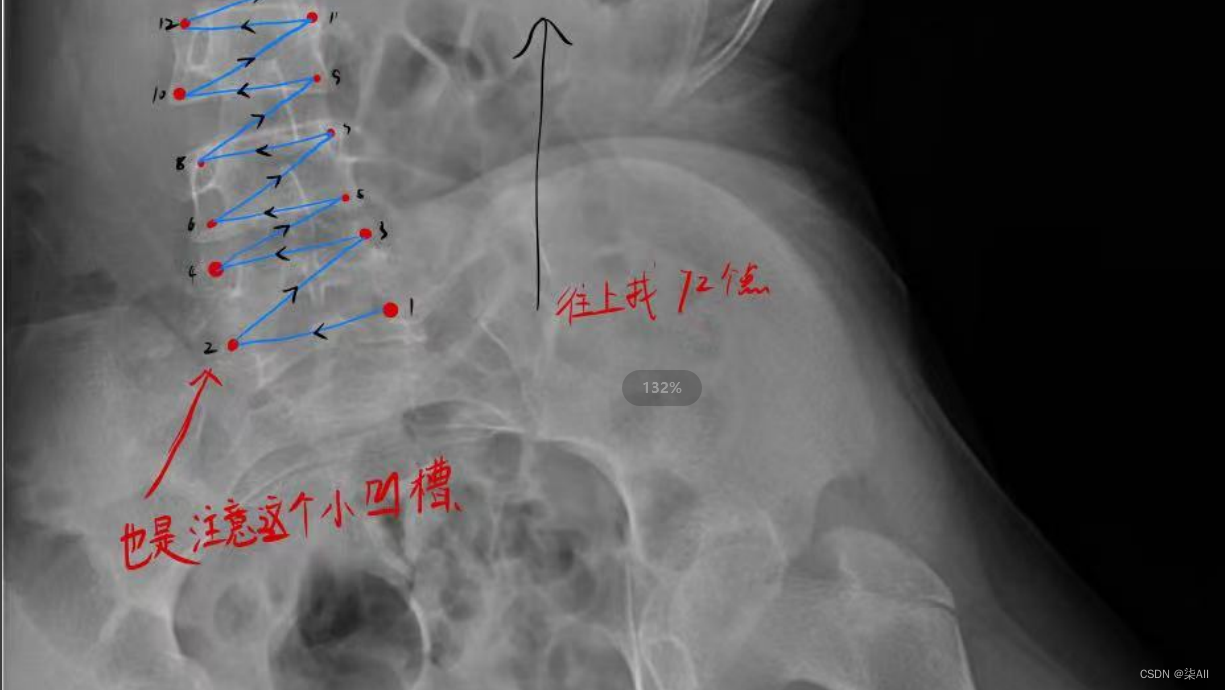
- (0) 最后一个椎体看不清的话,最后一个肋骨连接的就是胸12 也就是T 12 ,下面那个就是L1(腰椎1),往下数五个就是 最后一个腰椎
- (1)标注的椎体应该近似是一个矩形,而不是梯形 如下图
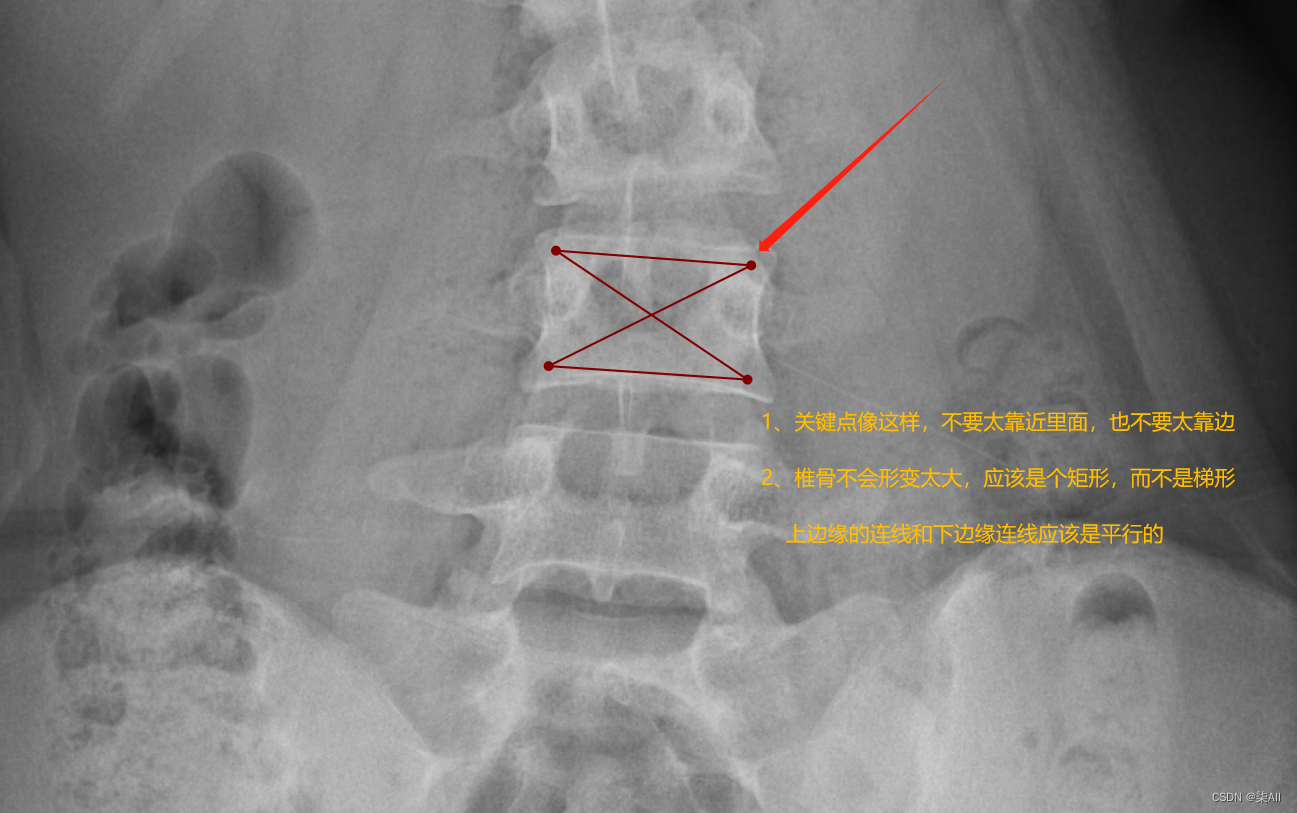
- (2)标注的时候关键点 不要(X)标记的太靠 边 ,但是 也不要往内收的太厉害
- 下图这个就不太行
- (3)像这种椎骨不要变化太大,一般都是底下的椎骨大一些,往上逐渐减少,就因为看不清,所以得这样表
- (4)还是有很多问题的,这种计算cobb角肯定有问题,最后一个椎骨看不清,那画的线就与上一个椎骨平行,尽量平行标,要不然后面自动生成cobb角,误差很大,这样肯定不行,注意一下,认真一些,要不然得返修几次,不如好好弄,还节省时间
- (6)你看这种58这种点,咱们可以往外标一点,或者把60缩一些
- 四、数据筛查代码
- 五、参考链接
一、-------------Lebelme 的安装(基于anaconda)与使用---------------
1. Labelme 安装
前提:我默认你已经装过Anaconda,如果没有——那就装一下呗
1、进入Anaconda Prompt对话窗口
按住 win+r ---->cmd
2、输入 进入conda 的 base 环境
conda activate

3、输入:conda create --name=labelme python=3.7 # 创建一个叫labelme的环境
conda create --name=labelme python=3.7
注:python的版本根据自己conda支持的来进行选择
过程中会遇见 Proceed([y]/n),输入y即可
4、激活新建的环境,进入
输入:activate labelme #激活环境
activate labelme

因为labelme是用Python编写的,并使用Qt作为其图形界面,而pyqt5是 Python 编程语言和 Qt 库的成功融合,所以此处还需再安装pyqt5
5、.安装pyqt5
输入:pip install pyqt5 #安装pyqt5这个包
pip install pyqt5

忽略我这里已经装过了,所以你只要跟着这个操作就行了
5、安装labelme(终于进入正题了)
输入:pip install labelme #安装labelme软件
pip install labelme
这个过程就是稍微等等就可以了正常来说如果你网还可以的话就基本安装结束了,如果你网不好还报错。这里还有一招你试试:
不用pip install labelme 改成pip --default-timeout=100 install labelme。
至此,labelme就装好了,在这个环境下只要输入labelme就可以进入软件了
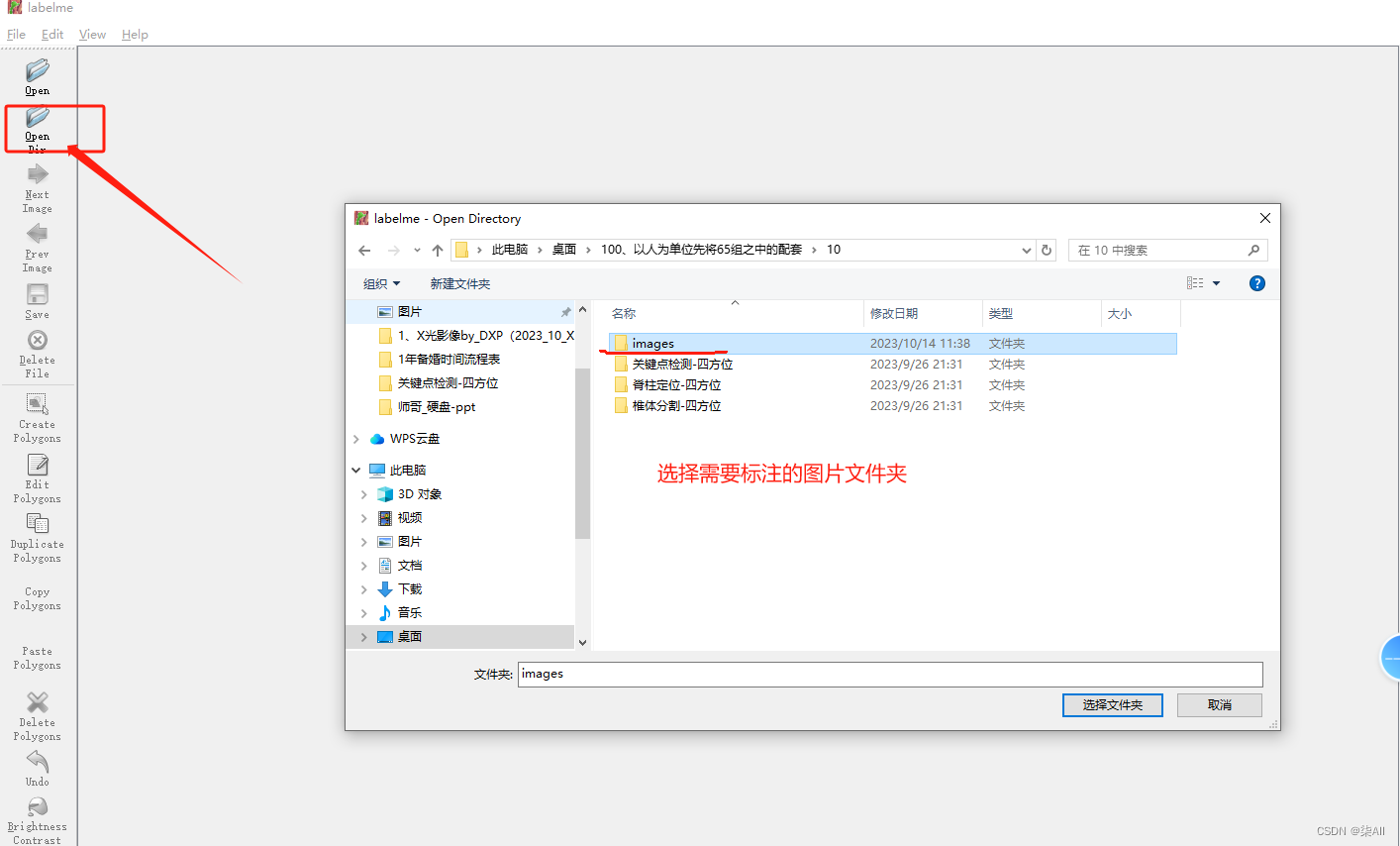
2. Labelme 启动
1、输入:conda activate labelme 进入安装lableme 的环境
注:这个 labelme 是我安装labelme的环境名

2、然后 输入 labelme 进入labelme

3、QT界面如下
二、--------------脊柱 数据集 介绍 以及需要标注的关键点--------------------
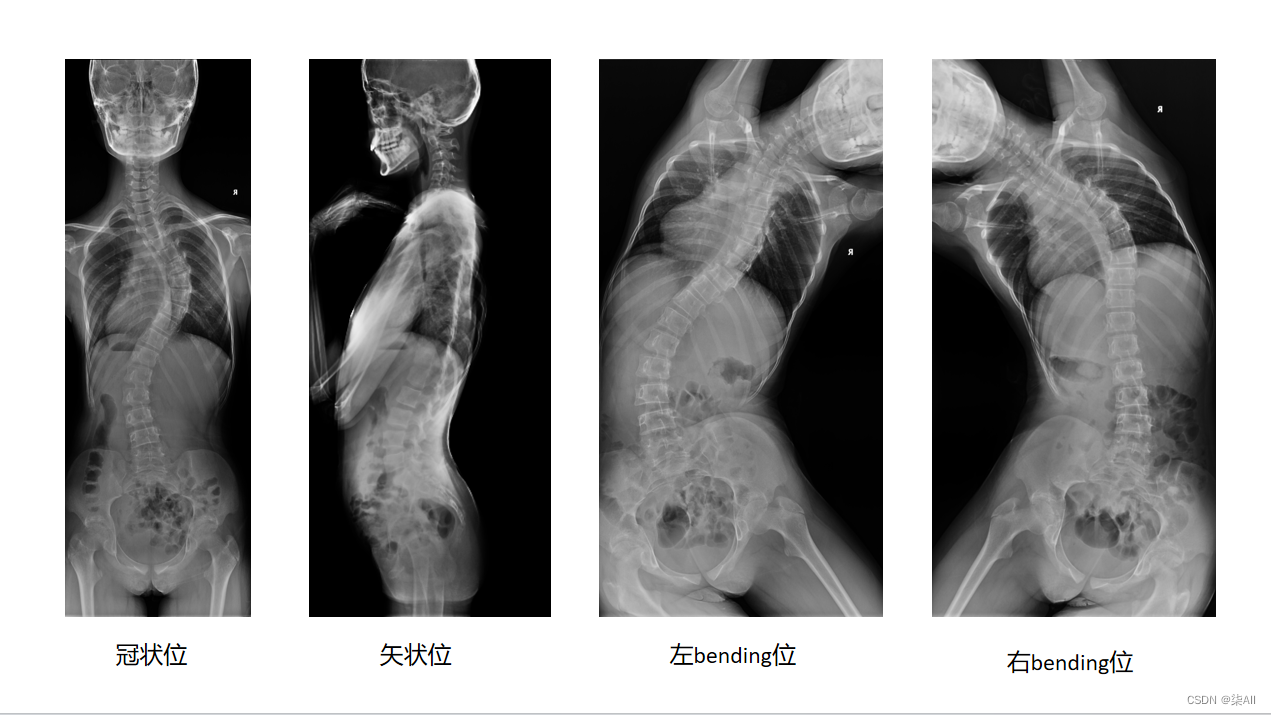
脊柱数据有四方位的数据,冠状位、矢状位、左bendin、右bending
脊柱畸形角度测量:链接:https://zhuanlan.zhihu.com/p/384394520
1、数据显示如图
注意:
2、需要标注的关键点(冠状位、左右bending位)
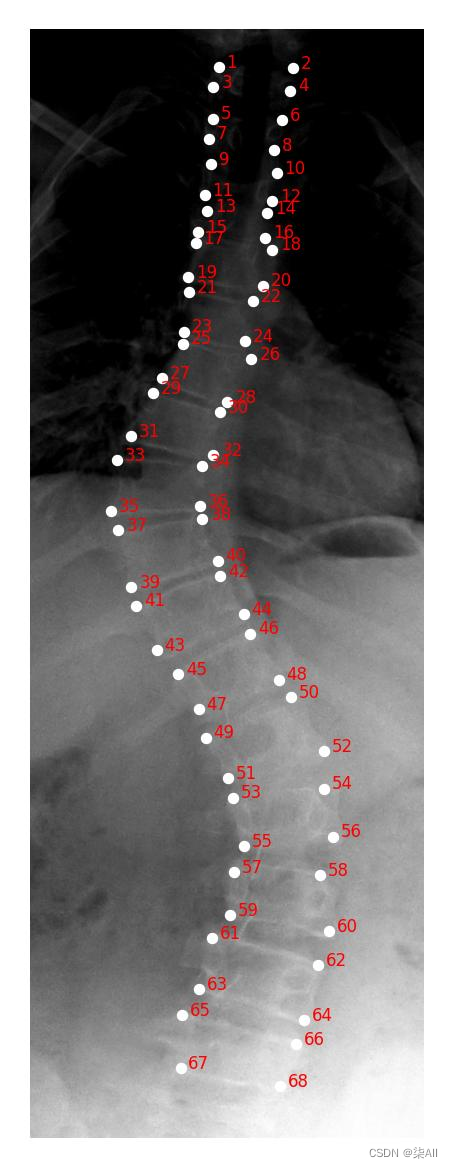
冠状位(一共是标记72个关键点)
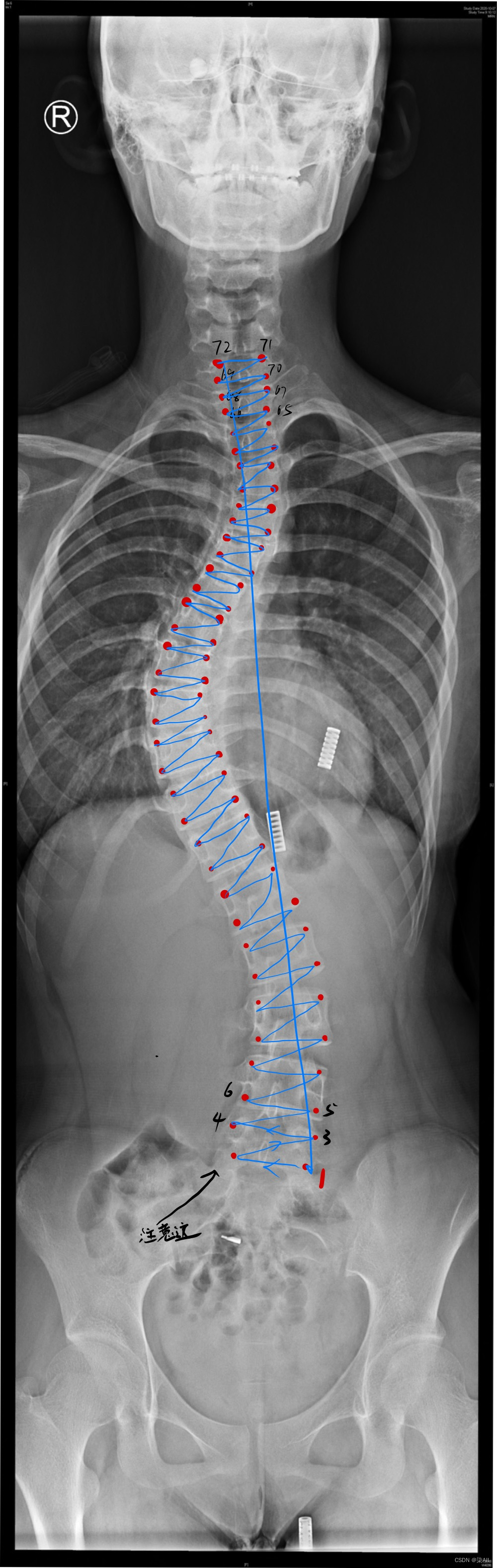

左右bending(一共也是标记72个关键点)
左bending和右bending是一样的,这里就做一个示范
三、--------------labelme 如何标注脊柱数据 关键点 --------------------------
1、 根据一.2启动labelme
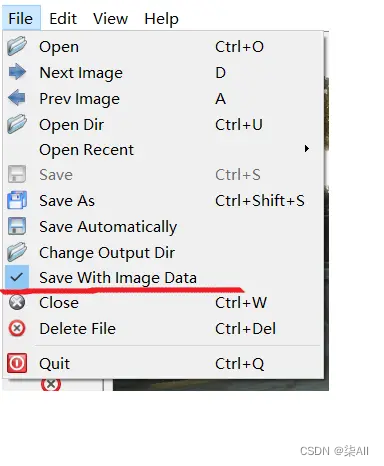
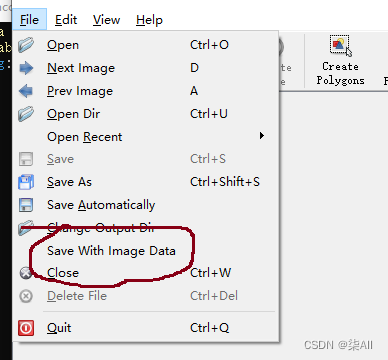
1.2 标记之前把这个关掉(这个地方每次打开labelme软件是默认勾选的,所以注意一下)
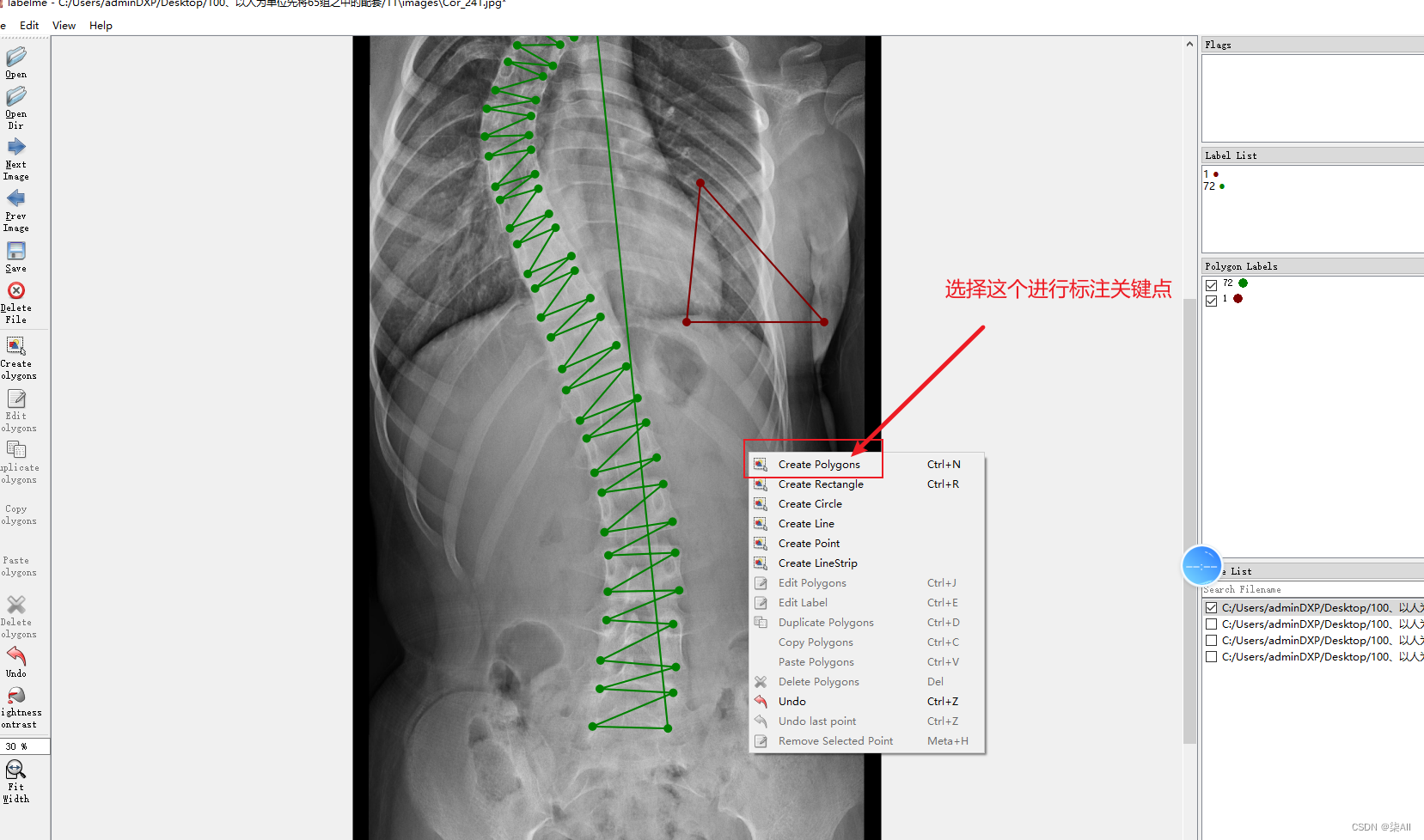
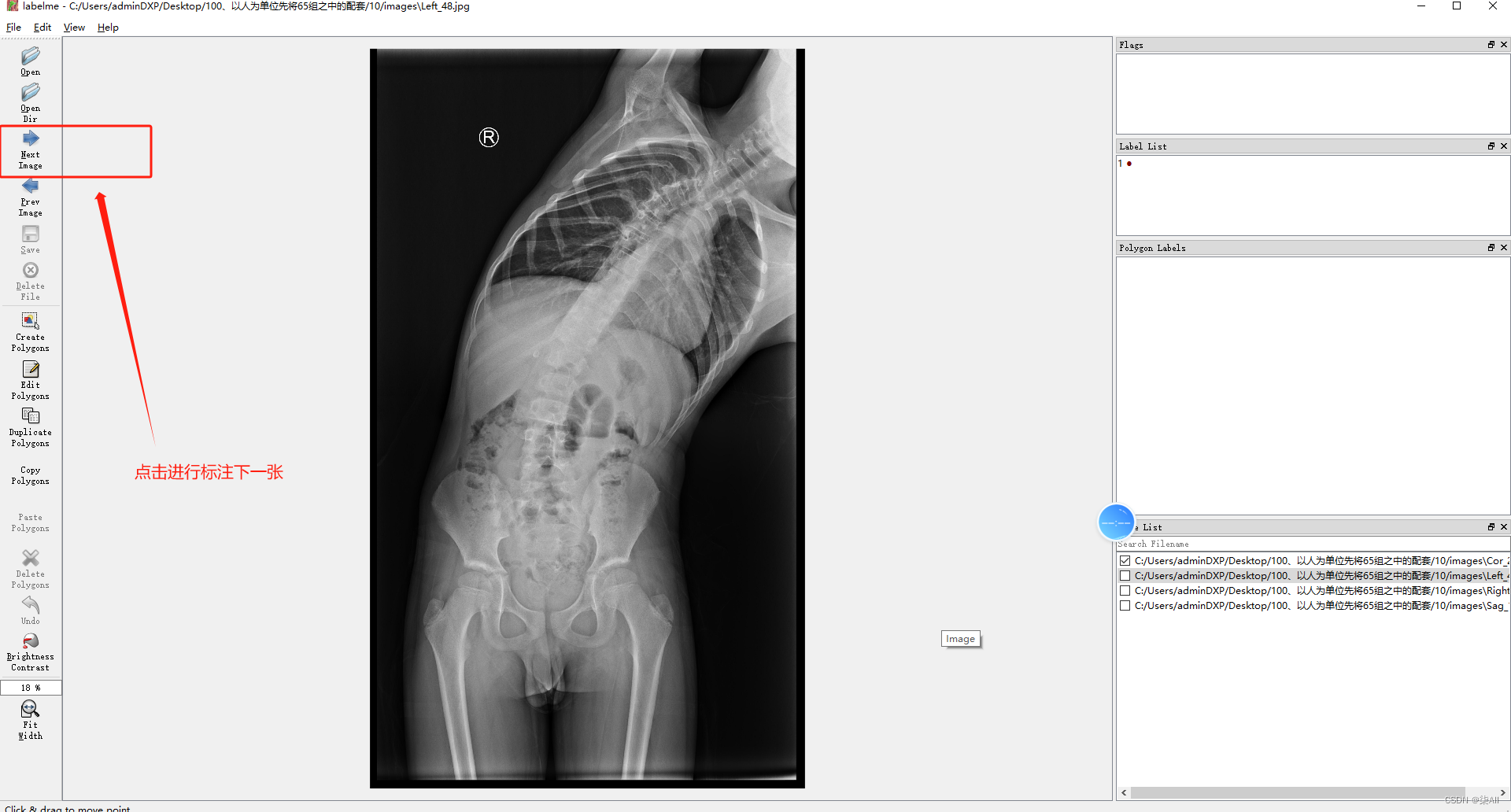
2、开始标注(以冠状位为例,其他方位是一样的操作,视频教程)
冠状位关键点标注教程
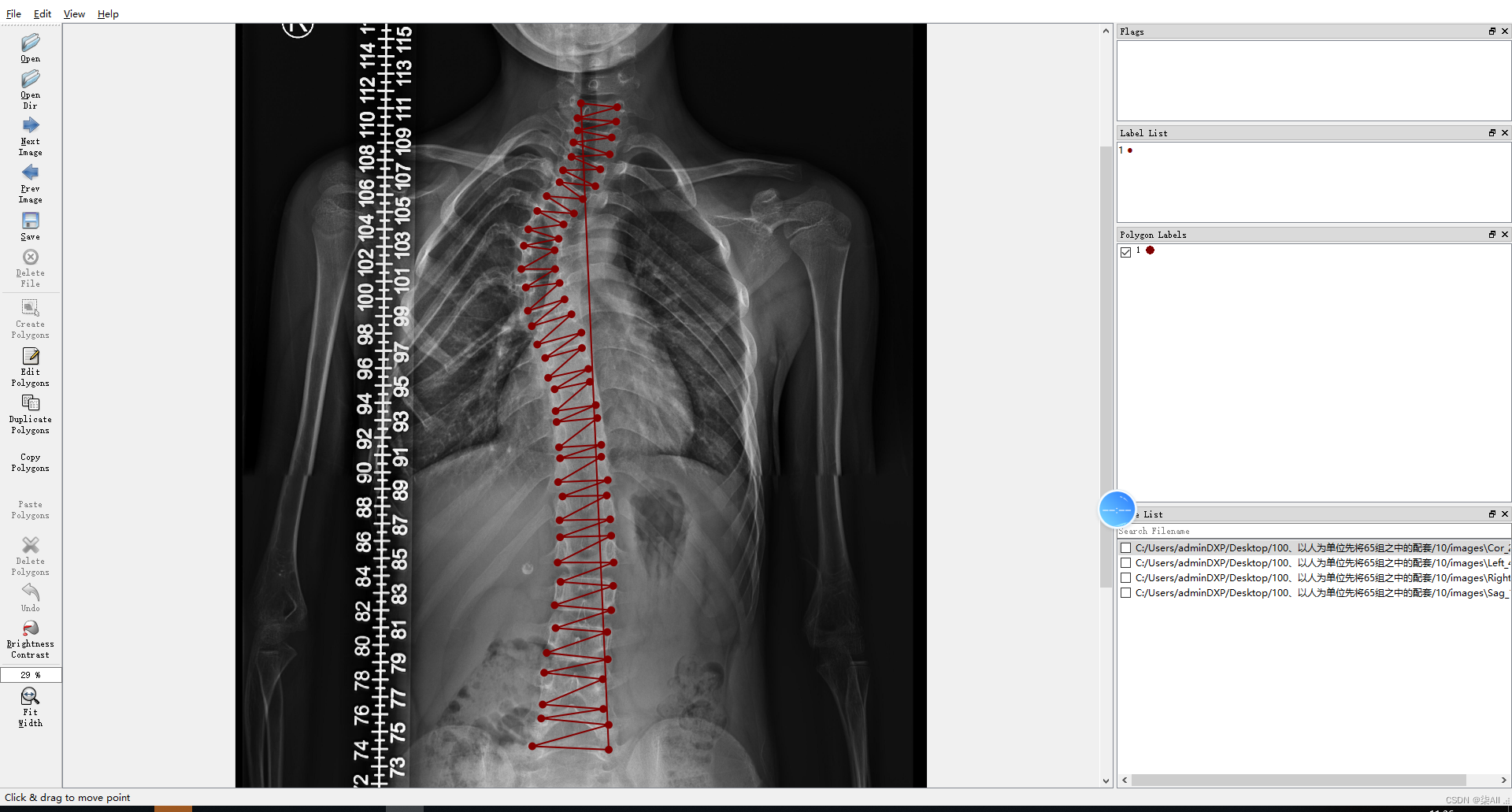
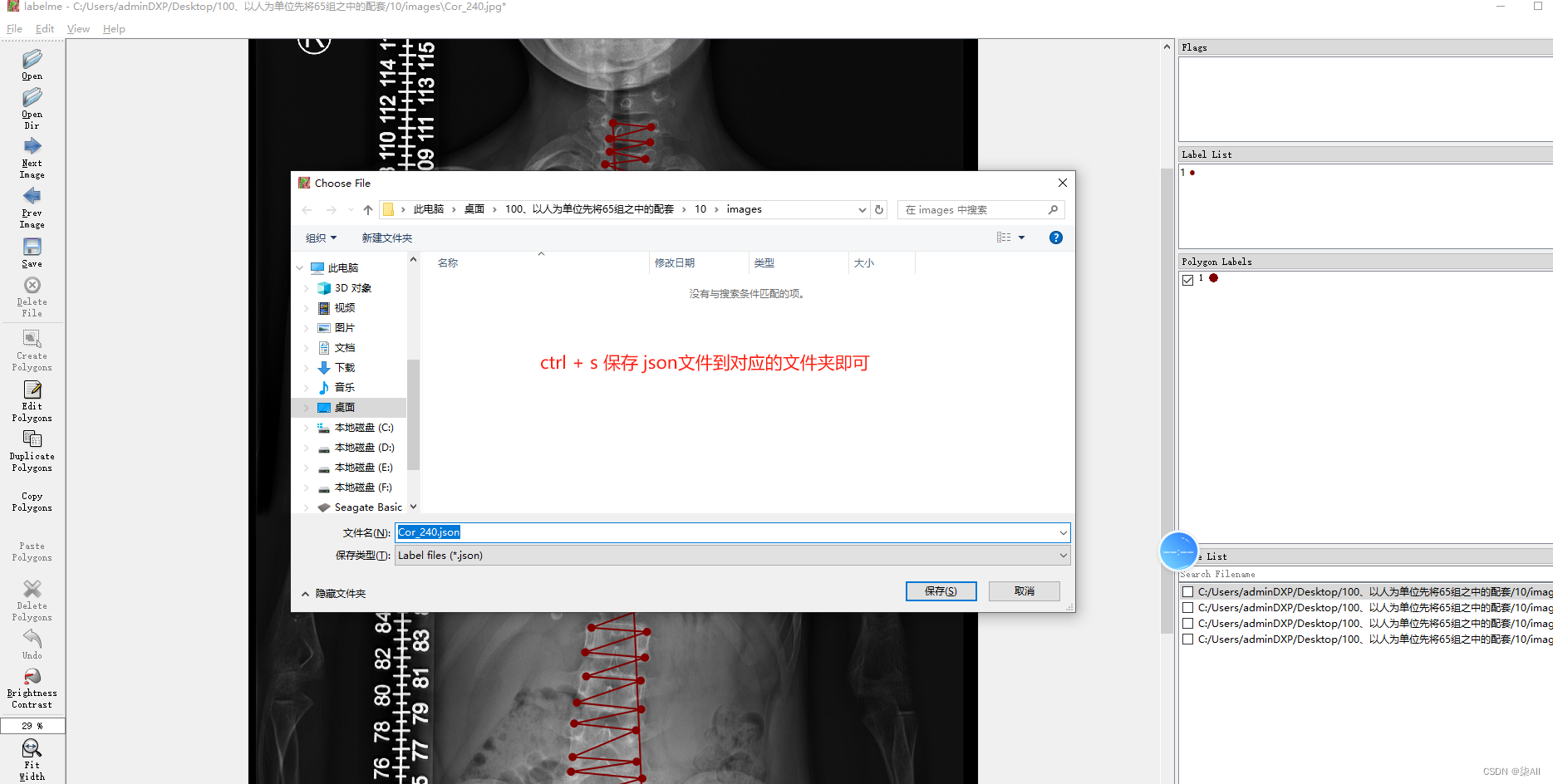
3、冠状位标注结果
4、标注过程注意事项
4.1、关键点不小心标注的位置不对


4.2 少标记或者多标记点。进行补点或者进行删除
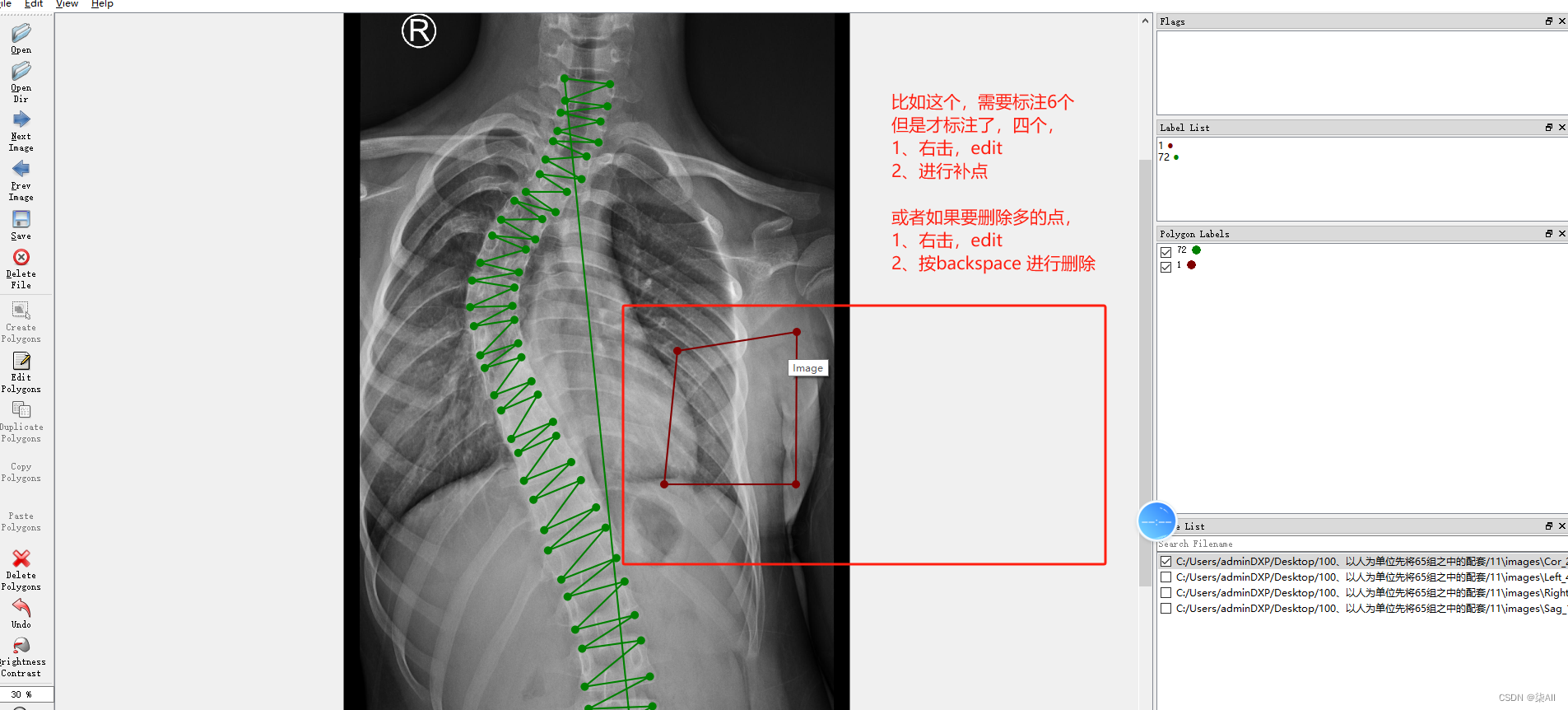
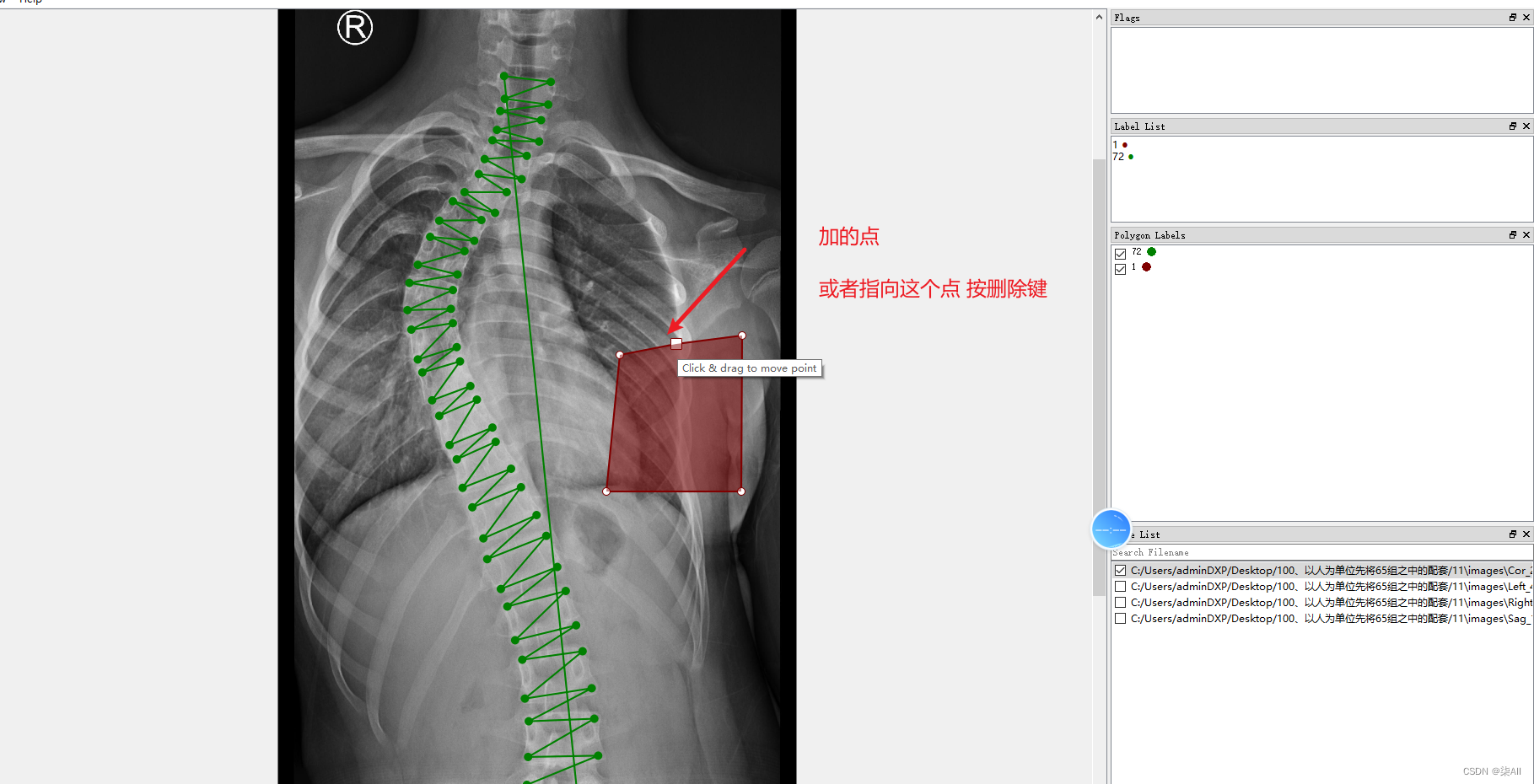
5、标注结果注意
(0) 最后一个椎体看不清的话,最后一个肋骨连接的就是胸12 也就是T 12 ,下面那个就是L1(腰椎1),往下数五个就是 最后一个腰椎
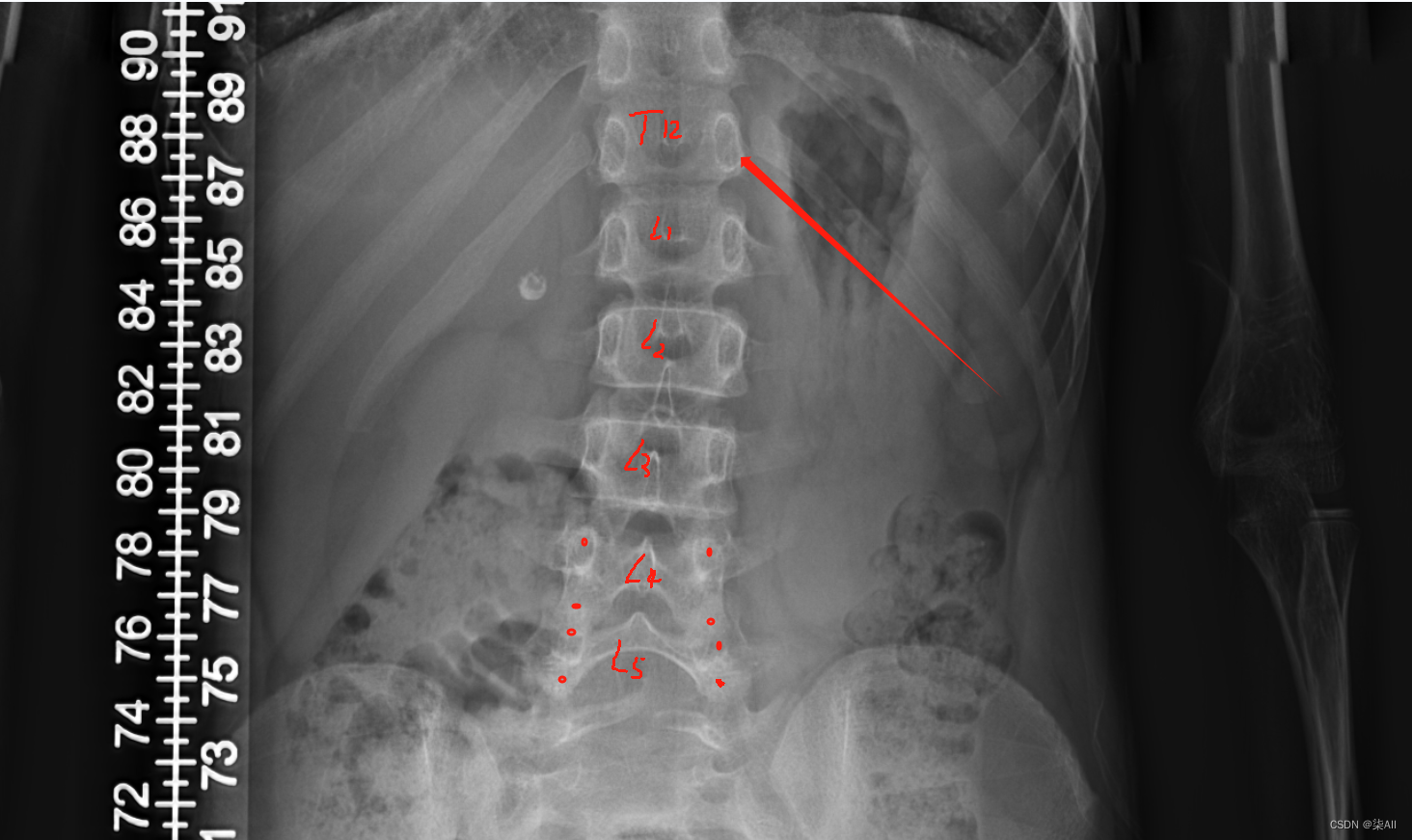
(1)标注的椎体应该近似是一个矩形,而不是梯形 如下图
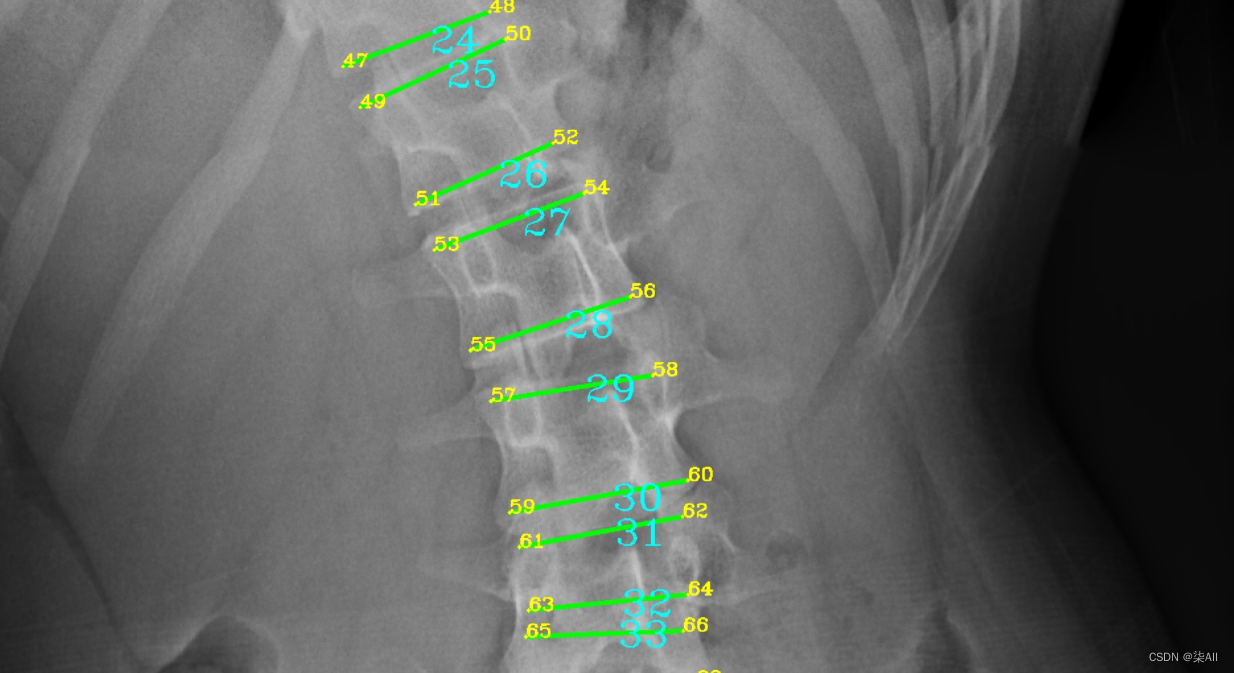
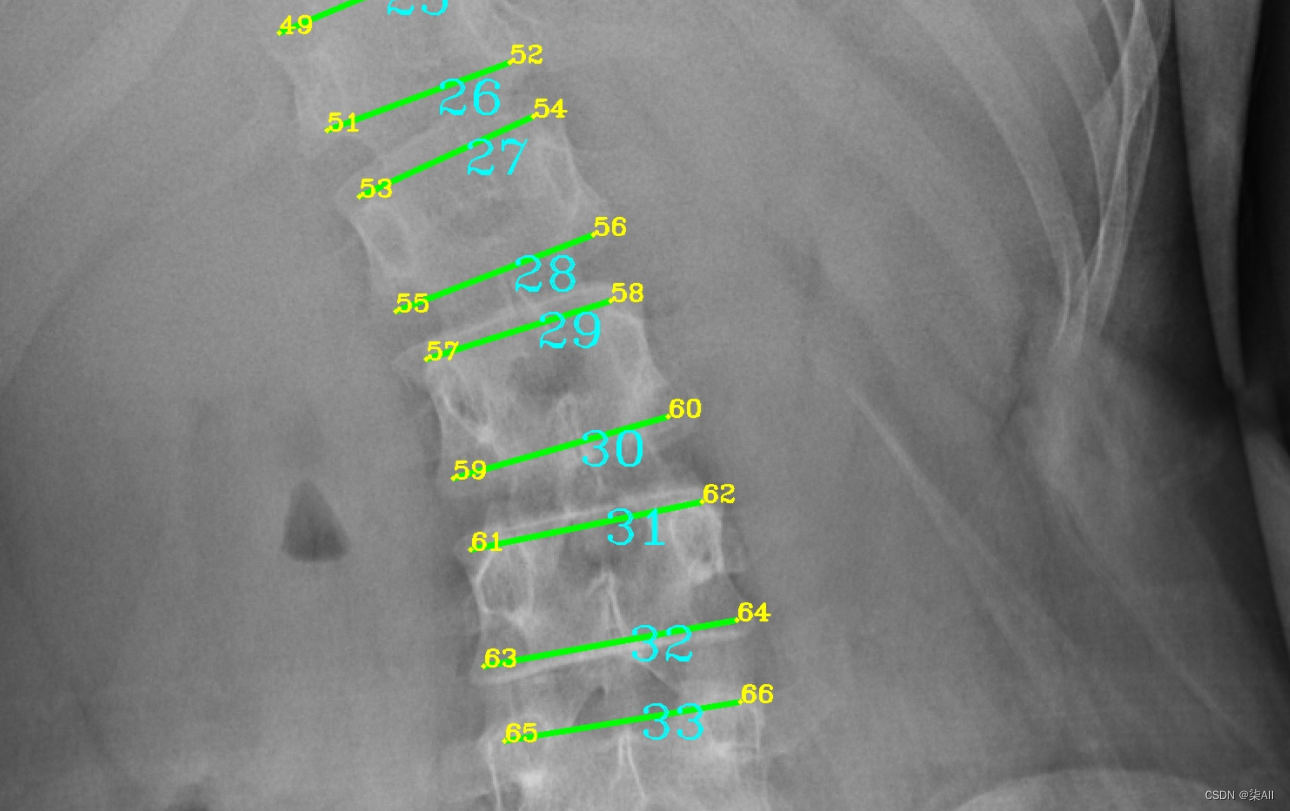
(2)标注的时候关键点 不要(X)标记的太靠 边 ,但是 也不要往内收的太厉害
下图这个就不太行

(3)像这种椎骨不要变化太大,一般都是底下的椎骨大一些,往上逐渐减少,就因为看不清,所以得这样表
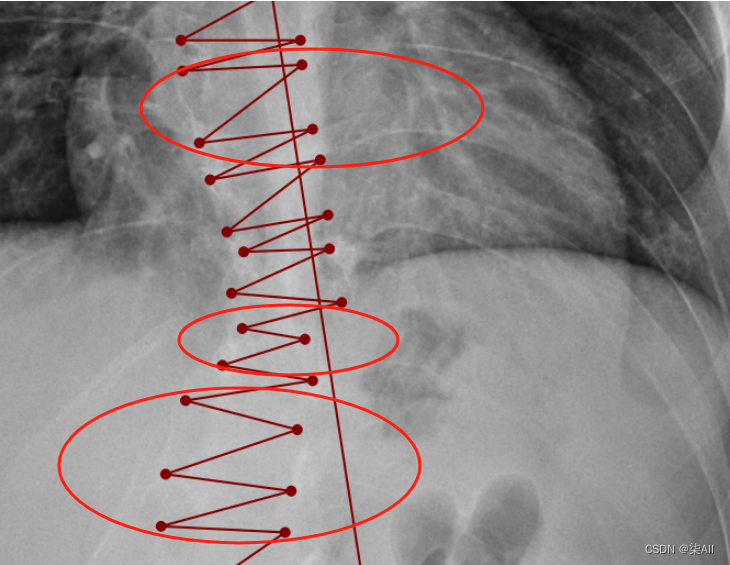
还是有很多问题的,这种计算cobb角肯定有问题,最后一个椎骨看不清,那画的线就与上一个椎骨平行,尽量平行标,要不然后面自动生成cobb角,误差很大,这样肯定不行,注意一下,认真一些,要不然得返修几次,不如好好弄,还节省时间
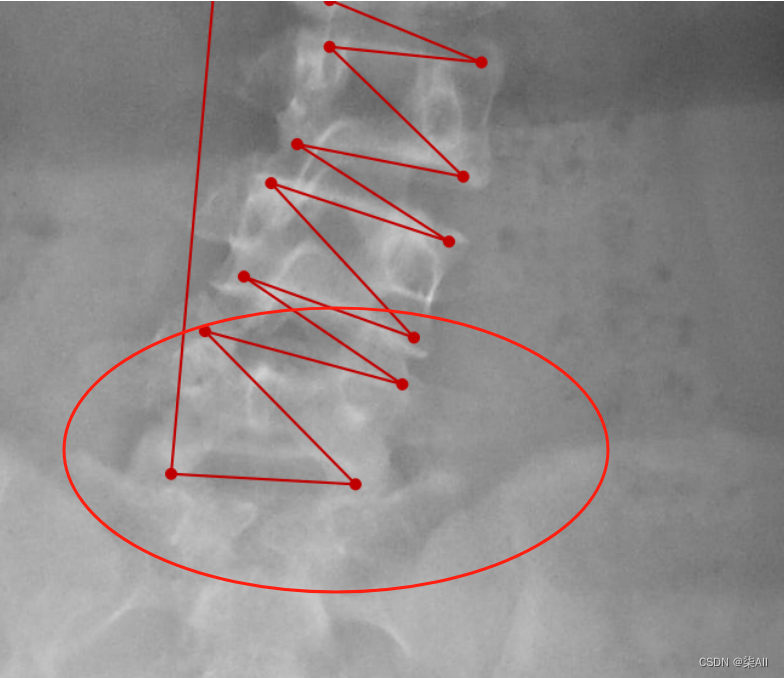
###(5) 参考AASCE2019 GT图
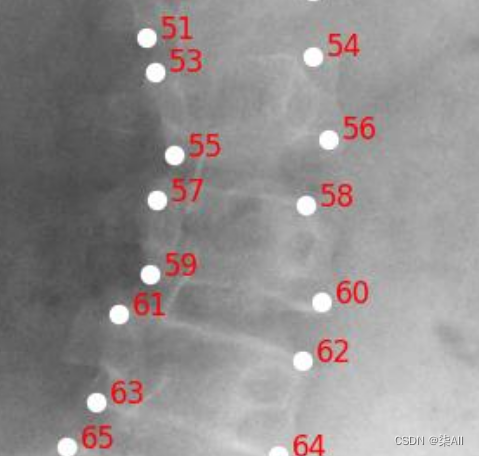
(6)你看这种58这种点,咱们可以往外标一点,或者把60缩一些
四、数据筛查代码
import json
import argparse
import glob
import numpy as np
import os
import cv2
import scipy.io as io
import shutil
def remove_file(p):
print(f"{p} --path already exists, remove all files!!!!!")
shutil.rmtree(p, ignore_errors=True)
print("success")
os.makedirs(p, exist_ok=True)
# json ----->npy
class labelmeJson2npy():
# 可以运行
def __init__(self, json_paths, image_paths, save_images_path, save_npy_path):
"""
:param json_paths: 所有json文件的上级目录
:param image_paths: 所有images的上级目录
:param save_images_path: 保存图片的路径
:param save_npy_path: 保存mat(npy)文件的路径
"""
self.json_paths = json_paths
self.image_paths = image_paths
self.save_images_path = save_images_path
self.save_npy_path = save_npy_path
self.image_types = ['*.jpg', '*.jpeg', '*.png'] #可以接受的格式
if not os.path.exists(save_images_path):
os.makedirs(save_images_path)
if not os.path.exists(save_npy_path):
os.makedirs(save_npy_path)
assert os.path.exists(json_paths), f"{json_paths} 路径有问题"
assert os.path.exists(image_paths), f"{image_paths} 路径有问题"
[remove_file(p) if os.path.exists(p) else print(f"{p} --path not found!")
for p in [self.save_images_path, self.save_npy_path]]
# 可以运行
def readPointsInJson(self, mode=True):
"""
:param mode: 模式 false为检查阶段,可点标注是否有错误, true为绘图阶段
:return:
"""
json_files = glob.glob(os.path.join(self.json_paths, "*.json"))
print(len(json_files))
for file_path in json_files:
all_pointsInfile = [] # 存储所有的点
file_name = os.path.basename(file_path)
with open(file_path, 'r') as f:
jn = json.load(f)
flag = False #如果图片像素较低为true
print(file_path)
imgHeight = jn['imageHeight']
imgWidth = jn['imageWidth']
if imgHeight < 1000:
flag = True
all_pointsInfile = jn['shapes'][0]['points'] #shape (68, 2) 68个点 / 存储(72,2) 72个 点到 all_pointInfile列表
if not mode:
# assert len(all_pointsInfile)==68, f"{file_path}该路径下的json文件标注错误,只有{len(all_pointsInfile)}个点"
assert len(all_pointsInfile)==72, f"{file_path}该路径下的json文件标注错误,只有{len(all_pointsInfile)}个点"
all_pointsInfile = np.asarray(all_pointsInfile, dtype=float) # 这行代码将all_pointsInfile中的坐标点数据转换为NumPy数组
all_pointsInfile = all_pointsInfile[::-1] ############## 需要逆序排列,因为标记点的顺序是从下往上标的 最后一个脊椎的标点顺序为 [] 3 2 1 0 shape (72,2)
mid_points = (all_pointsInfile[::2] + all_pointsInfile[1::2]) / 2
# 这行代码计算了中间点坐标,它将每两个连续的点的坐标相加并除以2,以获取中间点的坐标。这可能与标注点之间的线相关,以确定线的中点坐标。
# shape(36,2)
all_pointsInfile = np.reshape(all_pointsInfile, (-1, 2, 2)) #1、34条线 2、 36条线
# 这一行代码将all_pointsInfile重新塑造为一个三维数组。(-1, 2, 2)的形状意味着最外层的维度 shape = (36,2,2)
mid_points = np.asarray(mid_points, dtype=int)
# 这行代码将中间点坐标数组mid_points转换为整数数据类型,以确保它们以整数形式存储。
all_pointsInfile = np.asarray(all_pointsInfile, dtype=int) #shape (36,2,2)
# 最后一行将all_pointsInfile重新转换为整数数据类型,以确保最终的标注数据都以整数形式存储。这可能是为了与后续的图像处理或绘图操作相匹配。
file_pre_name = os.path.splitext(file_name)[0]
# 获得文件前缀
save_file_path = os.path.join(self.save_images_path, file_pre_name + ".jpg") # 保存绘制的图象划线
# 这行代码使用os.path.join函数构建一个文件路径,将file_pre_name与".jpg"扩展名结合起来,然后与self.save_images_path连接,得到要保存图像的完整文件路径。这个路径可能用于将绘制好的图像保存到指定的目录中。
aimg_path = os.path.join(self.image_paths, file_pre_name + ".jpg") # 原图 路径
# 这行代码使用os.path.join函数构建另一个文件路径,将file_pre_name与".jpg"扩展名连接,然后与self.image_paths连接,得到原始图像文件的完整路径。这个路径可能用于读取原始图像数据。
print(f"绘制图像name:{file_pre_name} , 原图path:{aimg_path}")
# 进入 cv2plot() 这个函数
self.cv2plot(aimg_path, all_pointsInfile, mid_points, save_file_path, flag=flag, mode=mode)
# 保存npy文件
if mode:
# 进入saveMat 这个函数
self.saveMat(all_pointsInfile, filename=file_pre_name)
def saveMat(self, points, filename):
'''
:param points: 关键点 shape(68,2) 或者(34,2,2)
:param filename: 没有后缀的名字
:return:
'''
points = np.array(points)
if len(points.shape) == 3:
points = np.reshape(points, (-1, 2))
data = {'p2': points}
path = os.path.join(self.save_npy_path, filename+'.jpg.mat')
io.savemat(path, data, long_field_names=True)
print(f'保存{filename}.jpg.mat数据成功')
# 这个函数里面有错误()
def cv2plot(self, img_path, lines, midpoints, save_file_path, flag=False, mode=True):
"""
:param img_path: 单个图片的路径
:param lines: 线条信息shape (36, 2, 2)
:param midpoints: 中点坐标 (36, 2)
:param save_file_path: 保存单个图片的路径
:param flag: 当前图片是否为低分辨率
:param mode: false检查阶段, True绘图阶段
:return:
"""
img = cv2.imread(img_path) # 这里是bgr
count = 1
font_text = np.array([3, 1.5, 1.5])
thickness = 2
if flag: # 如果像素分辨率太低
font_text = font_text * 0.5
thickness = 1
if mode: #把点输出到图片上
for i, line in enumerate(lines): #这个lines 就是 (362,2,2)
# 这行代码出错
pt1 = tuple(line[0])
pt2 = tuple(line[1])
# cv2.line(img, line[0], line[1], (0, 255, 0), 5)
cv2.line(img, tuple(line[0]), tuple(line[1]), (0, 255, 0), 5)
# cv2.putText(img, str(i + 1), midpoints[i] + 20, cv2.FONT_HERSHEY_COMPLEX_SMALL , font_text[0], (255, 255, 0), thickness)
cv2.putText(img, str(i + 1), tuple(np.array(midpoints[i]) + 20) , cv2.FONT_HERSHEY_COMPLEX_SMALL , font_text[0], (255, 255, 0), thickness)
# cv2.circle(img, line[0], 1, (0, 255, 255), 4)
cv2.circle(img, tuple(line[0]), 1, (0, 255, 255), 4)
# cv2.putText(img, str(count), line[0], cv2.FONT_HERSHEY_COMPLEX_SMALL , font_text[1], (0, 255, 255), thickness)
cv2.putText(img, str(count), tuple(line[0]), cv2.FONT_HERSHEY_COMPLEX_SMALL , font_text[1], (0, 255, 255), thickness)
count += 1
# cv2.circle(img, line[1], 1, (0, 255, 255), 4)
cv2.circle(img, tuple(line[1]), 1, (0, 255, 255), 4)
# cv2.putText(img, str(count), line[1], cv2.FONT_HERSHEY_COMPLEX_SMALL , font_text[2], (0, 255, 255), thickness)
cv2.putText(img, str(count), tuple(line[1]), cv2.FONT_HERSHEY_COMPLEX_SMALL , font_text[2], (0, 255, 255), thickness)
count += 1
cv2.imwrite(save_file_path, img)
else: #验证模式
for i, line in enumerate(lines):
if flag:
cv2.line(img, line[0], line[1], (0, 255, 0), 1)
else:
cv2.line(img, line[0], line[1], (0, 255, 0), 5)
count += 1
cv2.putText(img, str(count%10), (line[1][0], line[1][1]), cv2.FONT_HERSHEY_COMPLEX_SMALL, font_text[1], (0, 255, 255),
thickness)
count += 1
cv2.imwrite(save_file_path, img)
if not mode:
assert count == 72, f"{img_path} 当前关键点数量不符合规范,只有{count}个!!!"
if __name__ == '__main__':
root_path = r"./cor"
json_paths = os.path.join(root_path, "json")
image_paths = os.path.join(root_path, "images")
save_images_path = os.path.join(root_path, "out")
save_npy_path = os.path.join(root_path, "json_mat")
# 函数1
trans = labelmeJson2npy(json_paths, image_paths, save_images_path, save_npy_path)
# 函数2
trans.readPointsInJson(True)
五、参考链接
labelme的安装以及使用:https://blog.csdn.net/qq_41931453/article/details/125757449

















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









