







 本文详细介绍了MMoE(Mixture of Experts)和PLE(Progressive Layered Extraction)两种多任务学习模型。MMoE通过多个专家网络和门控机制实现任务间的资源共享与任务特定的贡献分配。然而,MMoE可能存在任务间效果不平衡的问题。为解决这一问题,PLE模型引入了任务专属的特定专家网络,并通过多层CGC(Coarse-to-Fine Gating Control)网络逐步提取任务特征,实现了更精细的任务分离和特征提取。PLE模型在保持任务间相关性的同时,提升了模型的性能和稳定性。
本文详细介绍了MMoE(Mixture of Experts)和PLE(Progressive Layered Extraction)两种多任务学习模型。MMoE通过多个专家网络和门控机制实现任务间的资源共享与任务特定的贡献分配。然而,MMoE可能存在任务间效果不平衡的问题。为解决这一问题,PLE模型引入了任务专属的特定专家网络,并通过多层CGC(Coarse-to-Fine Gating Control)网络逐步提取任务特征,实现了更精细的任务分离和特征提取。PLE模型在保持任务间相关性的同时,提升了模型的性能和稳定性。
1. MMoE
1.1 MMoE模型框架
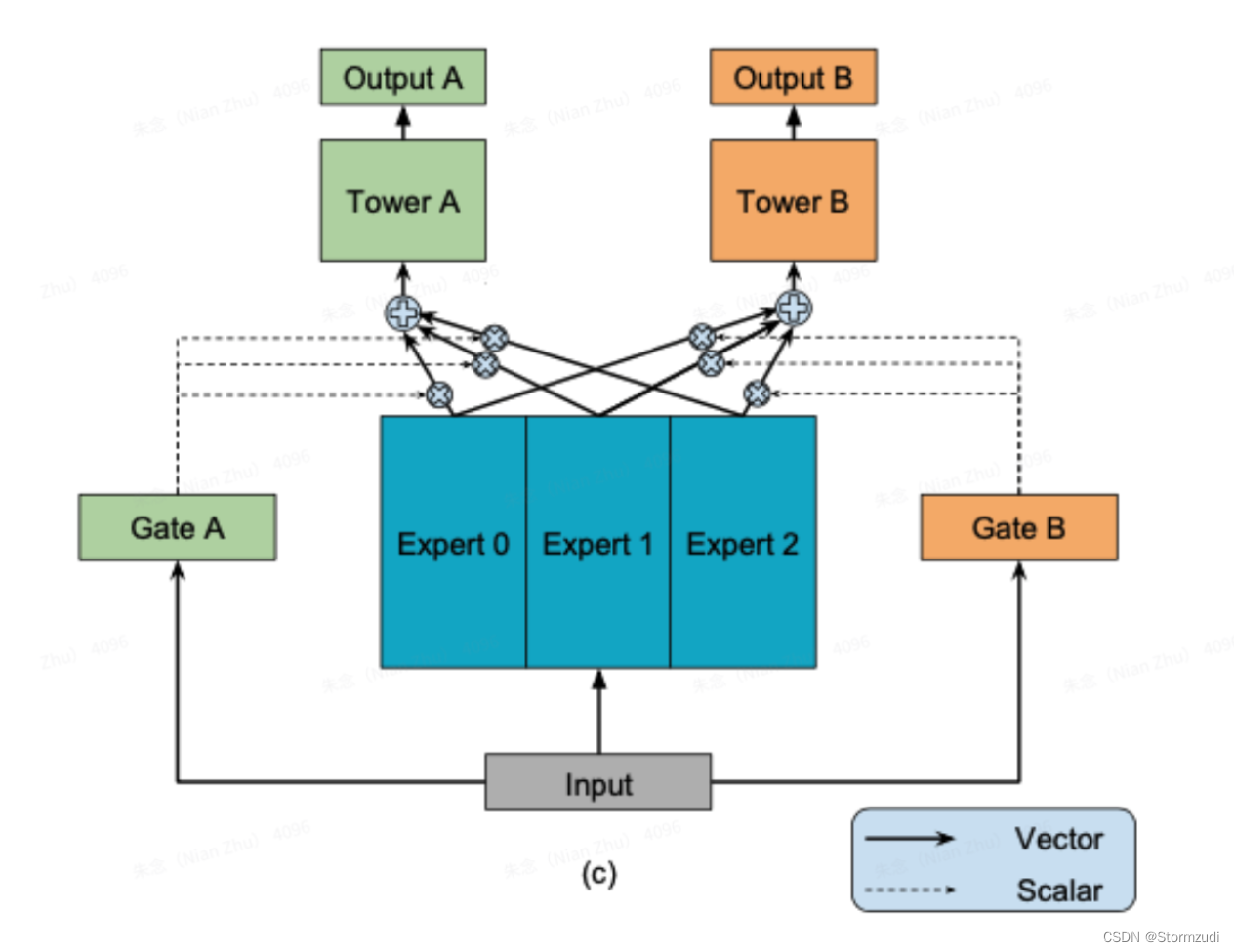
- 模型输入会通过映射到,所有task共享的多个Expert, 一个Expert就是RELU激活函数的全连接层,称为Mixture-of-Experts
n_expert = 20 # 定义Expert个数
expert_dim = 32 # 每个Expert隐藏结点个数(全连接层)
self.expert_layer = [Dense(expert_dim,activation='relu')for i in range(n_expert)]
#多个专家网络
E_net = [expert(x) for expert in self.expert_layer] #n_expert个(bs,expert_dim)
E_net = Concatenate(axis=1)([e[:,tf.newaxis,:] for e in E_net]) #(bs,n_expert,expert_dim)
- 模型输入还会映射到多个Gate,一个task独立拥有一个Gate,论文中Gate就是一个没有bias和激活函数的全连接层,然后接softmax,称为Multi-gate。
n_expert = 20
n_task = 4 # 表示四个任务类似["read_comment","like","click_avatar","forward"]
self.gate_layers = [Dense(n_expert,activation='softmax') for i in range(n_task)]
#多个⻔网络
gate_net = [gate(x) for gate in self.gate_layers] # n_task个(bs,n_expert)
- 每个Gate与共享的多个Expert相乘,Gate是一个概率分布,控制每个Expert对task的贡献程度,比如taskA的gate为(0.1,0.2,0.7),则代表Expert0、Expert1、Expert2对taskA的贡献程度分别为0.1、0.2和0.7.
# 每个towers等于,对应的⻔网络乘上所有的专家网络。
towers=[]
for i in range(self.n_task):
g=tf.expand_dims(gate_net[i],axis=-1) #(bs,n_expert,1)
_tower=tf.matmul(E_net,g,transpose_a=True) #(bs,expert_dim,1)
towers.append(Flatten()(_tower)) #(bs,expert_dim)
return towers #(n_task,bs,expert_dim)
- 通过task对应的Gate来得到多个Expert的加权平均,然后输入到task对应的Tower层(MLP网络层);
towers = MmoeLayer(expert_dim,n_expert,n_task)(input_embed)
outputs = [Dense(1,activation='sigmoid',
kernel_regularizer = regularizers.l2(dnn_reg_l2),
name=f,use_bias=True)(_t) for _t,f in zip(towers,target)]
这里MLP就直接了一层dense(),由于有多个任务,最后outputs=[task1,task2,task3,task4]。每个task==Dense()。
- 最后,通过对应task的Tower层输出,计算得到task的预测值。
target = ["read_comment","like","click_avatar","forward"]
train_labels = [train[y].values for y in target]
history = model.fit(train_model_input,train_labels,validation_data=
(val_model_input,val_labels),
batch_size=10240,epochs=4,verbose=1)
Tf, Dense: Dense 详解
tf.keras.layers.Dense(
units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)

2. PLE
论文:
《Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》
在Mmoe中会出现的问题,:
Mmoe在弱相关性task中表现地相对比较稳定,但由于底层的Expert仍然是共享的,虽然引入了Gate 来让task 选择 Expert, 所以还是会存在 “不均衡”的现状,一个task的效果提升,会伴随着另一个task的效果降低。
2.1 CGC
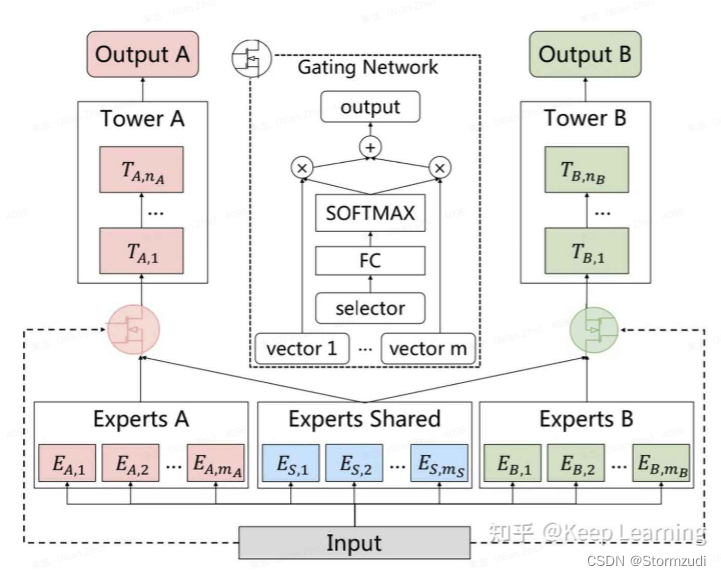
CGC网络中相比MMoE的一个差别就在于:除了共享的Expert之外,还加入了每个task自己的Specific Expert。
- 所有task共享的expert(如上图Experts Shared)、每个task自己的expert(如上图task A的Experts A),跟MMoE一样,Expert也是模型输入Input映射而来:ReLU激活函数的全连接层;
参数定义:
'''
n_experts: list, 每个任务使用几个expert。[2,3]第一个任务使用2个expert,第二个任务使用3个expert。
n_expert_share: int, 共享的部分设置的expert个数。
expert_dim: int, 每个专家网络输出的向量维度。
n_task: int, 任务个数。
'''
ExpertsShared的结构
self.share_layer = [Dense(expert_dim,activation='relu')for j in range(n_expert_share)]
每个task自己的expert个数不一样:n_experts : list
# 生成多个任务task网络
self.E_layer = []
for i in range(n_task):
sub_exp = [Dense(expert_dim,activation='relu') for j in range(n_experts[i])]
self.E_layer.append(sub_exp)
- 每个task通过Input映射为自己的Gate:一个没有bias和激活函数的全连接层,然后接softmax,即图中的Gating Network;
# 定义⻔控网络
self.gate_layers = [Dense(n_expert_share + n_experts[i], kernel_regularizer = regularizers.l2(dnn_reg_l2), activation='softmax')for i in range(n_task)]
- 每个task选择共享的Experts和task自己的Experts,通过task自己的Gate来得到多个Expert的加权平均。
# tasks网络和共享网络
x = inputs
E_net = [[expert(x) for expert in sub_expert] for sub_expert in self.E_layer]
share_net = [expert(x) for expert in self.share_layer]
# ⻔的权重乘上,指定任务和共享任务的输出。
towers=[]
for i in range(self.n_task):
g = self.gate_layers[i](x)
g = tf.expand_dims(g,axis=-1) # (bs,n_expert_share+n_experts[i],1)
_e = share_net + E_net[i]
_e = Concatenate(axis=1)([expert[:,tf.newaxis,:] for expert in _e]) #(bs,n_expert_share+n_experts[i],expert_dim)
_tower = tf.matmul(_e,g,transpose_a=True)
towers.append(Flatten()(_tower)) #(bs,expert_dim)
return towers
- 然后输入到task对应的Tower层(MLP网络层)
这里只进行了 一层 dense层
# Ple网络层
towers = PleLayer(n_task,n_experts,expert_dim,n_expert_share)(input_embed)
outputs = [Dense(1,activation='sigmoid',kernel_regularizer=regularizers.l2(dnn_reg_l2),name=f,use_bias=True)(_t) for f,_t in zip(targets,towers)]
2.2 PLE
PLE由多个Extraction Network组成,每个Extraction Network就是CGC网络层,做法与CGC一致;第一层Extraction Network的输入是原生模型输入Input;但后面的Extraction Network,输入就不再是
Input,而是所有Gate与Experts的加权平均的融合,这里的融合一般做法包括:拼接、加法融合、乘法融合,或者这三种的组合;最后一层Extraction Network中gate的数量等于task的数量,对应每个task的gate;而前面层的Extraction Network中gate的数量是task的数量+1,这里其实就是对应每个task的gate,加上共享expert的gate。
参考:
在定义了一层 CGC 时,PLE 会遍历多层num_levels CGC 网络结构。
ple_outputs=[] # PLE结构由多层CGC组成
for i in range(num_levels):
if i == num_levels-1: # the last level
ple_outputs = cgc_net(inputs=ple_inputs,level_name='level_'+str(i)+'_',is_last=True)
else:
ple_outputs = cgc_net(inputs=ple_inputs,level_name='level_'+str(i)+'_',is_last=False)
ple_inputs = ple_outputs
参考文章:
【1】https://zhuanlan.zhihu.com/p/425209494
【2】https://github.com/ShowMeAI-Hub/multi-task-learning
【3】https://github.com/shenweichen/DeepCTR/tree/master/deepctr/models/multitask

















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









