









大模型训练:有 16块 A100(2个算力节点)、4块H100(1个算力节点),来训练一个医学大模型。
超大模型训练:384 张 A100 (48 个算力节点) + 32 张备用 GPU、每个节点 8 张 GPU,4 条 NVLink 卡间互联,4 条 OmniPath 链路,来训练一个通用大模型。
前置知识:从【注意力机制】开始,到【Transformer】的零基础【大模型】系列
分布式训练
分布式训练的总体目标就是提升总的训练速度,减少模型训练的总体时间。
总训练速度,可以用如下公式简略估计:
- 总训练速度 ∝ 单设备计算速度 × 计算设备总量 × 多设备加速比
分布式训练就像是大合唱,目标是唱得快,节省排练时间。
唱歌速度,简单地说,就是单个人的唱功(单设备速度)乘以合唱团人数(设备总数),再乘以合唱团的默契程度(多设备加速比)。
提高个人唱功有几个巧办法,比如先练低音后练高音(混合精度训练),或者一边跳一边唱(算子融合)。
人越多,理论上咱们的合唱就能唱得越响亮,但如果大家配合不好,效果就会打折扣。
合唱的默契程度取决于咱们的练习和配合(计算和通讯效率),需要调整排练方法和位置分布(算法和网络结构)来提高。
- 算力:单个计算设备无法提供大模型的计算量
- 存储:单个计算设备无法完整存储一个大语言模型的参数
- 通信:分布式训练系统中各计算设备之间,需要频繁地进行参数传输和同步
计算和显存源于单计算设备的计算和存储能力有限,与模型对庞大计算和存储需求之间存在矛盾。
这个问题可以通过采用分布式训练方法来解决,但分布式训练又会面临通信的挑战。
就像工地上,每个工人(计算设备)都有自己的任务,但要完成整个建筑,大家必须互相协调,经常交流信息(参数传输和同步)。
如果工地上的对讲机(网络通信系统)不给力,工人们就没法及时沟通,工程就会延迟,效率也会大打折扣。
在分布式训练中,这个对讲机就是网络通信,它必须快速可靠。
但这里的难题就好比工地扩大了,工人多了,对讲机的信号就必须更强,否则信息传递就会慢,甚至出错。
传递的信息(数据)量越大,就越需要更好的对讲机和更精心的协调,以确保每个工人都能准确快速地接收到需要的信息,协同工作。
并行模型
-
数据并行:模型小、数据大,适合采用数据并行的训练方式,每个 GPU 都会复制一份模型的参数。
-
模型并行:由于模型太大(层数太深,参数太多),而无法将整个模型载入一个GPU,将模型划分为多个子模型。
如模型有 10000 层,10块GPU,GPU0 装载模型的前1000层,以此类推,GPU9 装载模型的最后 1000 层。
训练时,GPU0 先进行前向传播,其结果传给 GPU1,GPU1 接着进行前向传播,以此类推。
直到 GPU9 拿到 GPU8 给的结果进行反向传播。
反向传播过程与前向传播过程类似,就是每个GPU节点必须等待前一个节点的结果,才能进行运算。
-
张量并行:适合模型大,数据少,需要对模型做切分,将模型参数划分为多个部分,放到不同的GPU上进行独立计算,再做聚合。属于模型并行方法之一
-
零冗余数据并行:解决数据并行训练和模型并行训练之间权衡问题的算法
-
混合并行:结合了张量并行、数据并行和模型并行等多种并行技术
模型并行 MP 之 张量并行
适合模型大,数据少,需要对模型做切分,将模型参数划分为多个部分,放到不同的GPU上进行独立计算,再做聚合。
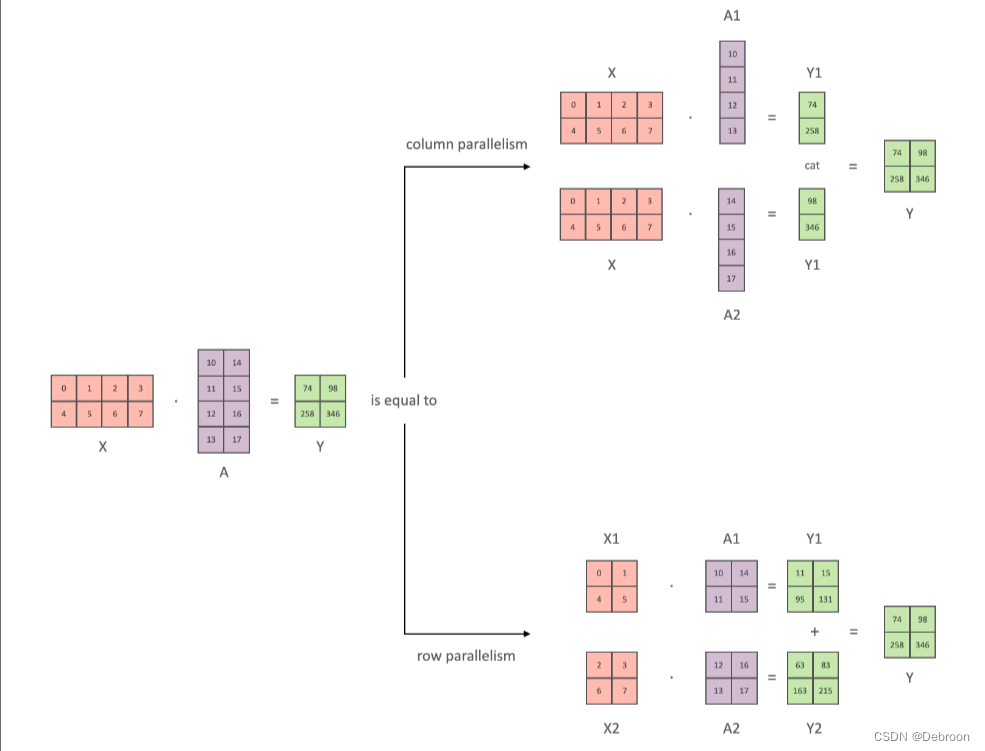
输入 X,模型参数 A。
如果是输入数据比较大,则优先选择做数据并行,即对输入X做切分。
如果是模型本身比较大,则优先选择做模型并行,即对矩阵A做拆分。
模型参数有 2 种划分方法:
- 按 y 轴方向切分(如上图 column parallelism 的 A1、A2) -》 数据 X 复制 2 份(如上图 column parallelism 的 X1、X2)
- 按 x 轴方向切分(如上图 row parallelism 的 A1、A2) -》 数据 X 要按 y 轴切分(如上图 row parallelism 的 X1、X2)
一般,是按 y 轴方向切分。
张量并行:
-
每个张量(模型参数)都被分成多个块,因此张量的每个分片都位于其指定的 GPU 上,而不是让整个张量驻留在单个 GPU 上。
-
在处理过程中,每个分片在不同的 GPU 上分别并行处理,结果在步骤结束时同步。
Transformer MLP 并行
以 2 个 GPU 为例子,MLP 全连接层的并行图:
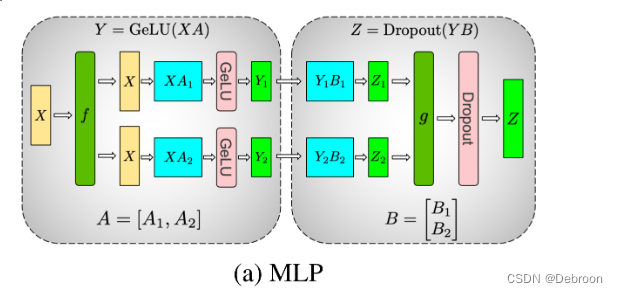
把模型参数 A 按 y 轴切,与输入 X 矩阵相乘,经过激活函数 GeLU,得到 Y1、Y2。
再把模型参数 B 按 x 轴切,与 Y1、Y2 矩阵相乘,Dropout 后聚合。
Transformer 多头注意力层 并行
以 2 个 GPU 为例子:
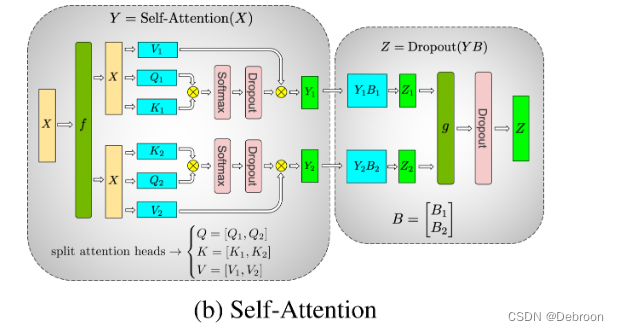
各个头各自计算,然后聚合。
数据并行 DP
数据并行:模型小、数据大,适合采用数据并行的训练方式,每个 GPU 都会复制一份模型的参数。
前向:
- 复制模型参数,数据分片
- 每个 GPU 处理一部分(n 分之一)
反向:
- 梯度是每个卡的平均
- 回传到 parameter server(内存超大的机器) 更新参数
这是普通数据并行。
All-Reduce 算子
如果是分布式,那梯度就不是求平均。
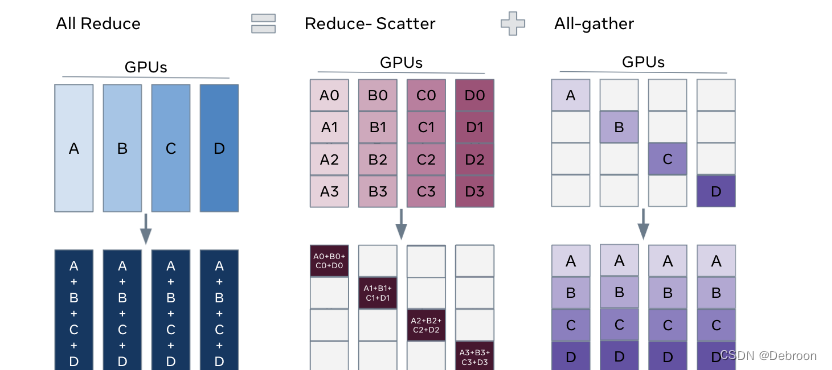
Reduce-Scatter:将所有这些向量的对应元素进行加法操作,然后将结果分散到所有参与的设备上,每个设备最终获得整个规约结果的不同部分:
- 把第一部分所有参数加起来放在卡1
- 把第二部分所有参数加起来放在卡2
- …
All-gather:每个设备提供一个数据片段,所有这些片段被聚集并复制到所有设备上。因此,操作结束时,每个设备都将有一个完整的数据集:
- 第一张卡只有一部分参数,拼接起来
- 第二张卡只有一部分参数,拼接起来
- …
All-Reduce:合并以上两个算子,保证每个卡最后参数一样。
分布式数据并行:
前向:
- 复制模型参数,数据分片
- 每个 GPU 处理一部分(n 分之一)
反向:
- 通过 all reduce 获得梯度平均
- 保证每个卡最后参数一样
切片数据并行
零冗余数据并行:ZeRO方法可以减少数据并行训练中的冗余通信和计算,提高训练速度和资源利用率。特别适用于大规模模型和大批量训练,可加快训练过程并提高训练效果。
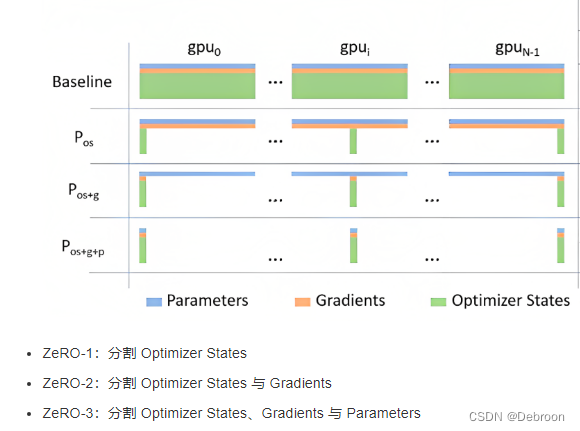
在零冗余数据并行(ZeRO)有 3 个版本:
-
ZeRO-1(上图的 P o s P_{os} Pos):对优化器状态做切分。
-
ZeRO-2(上图的 P o s + g P_{os+g} Pos+g):对优化器状态、梯度做切分。
-
ZeRO-3(上图的 P o s + g + p P_{os+g+p} Pos+g+p):对优化器状态(上图绿色)、梯度(橙色)、模式参数(蓝色)做切分。
ZeRO-3 是最高级别的优化,适用于处理更大规模的模型和更大批量的训练。
ZeRO-1
前向:
- 复制模型参数,数据分片
- 每个 GPU 处理一部分(n 分之一)
反向:
- 通过 Reduce Scatter 更新每个卡的梯度
- 每个卡获取一部分梯度
- 根据 all gather 更新最后参数
优化器更新参数的过程可以分两步:
- 1、计算梯度
- 2、基于状态更新
Adam优化器中的“momentum”就是一种状态。
原来的做法是:
-
整个模型和所有momentum状态都保存在每张卡上
-
每张卡前向+反向传播计算部分梯度
-
每张卡用所有momentum和全部参数更新模型
每张卡有完整参数和状态的内存。
如 8块 GPU,ZeRO-1的改进是:
-
模型参数区分8份,momentum也分8份,每份放一张卡
-
每张卡只计算自己这 1/8 参数的梯度
-
每张卡只用自己的 1/8 momentum更新自己的 1/8 参数
-
最后通过 All-gather技术 收集归并结果
这样每张卡只需要保存 1/8 参数和 1/8 状态的内存,但最后实际上执行了等效的“全部参数”的更新。
让每个进程(卡)只保存和计算部分状态,减轻了内存和计算压力,最后合并结果,整体任务也完成了。
对 优化器状态 分片存储,这就是ZeRO-1的核心思路。
8个工人合力修一条路,原来每个工人都要记住整条路的维修方案。
现在每人只需要记住自己负责的部分路段的维修计划。
最后汇总每个人提交的计划,整条路的维修还是完成了。
ZeRO-2
前向:
- 复制模型参数,数据分片
- 每个 GPU 处理一部分(n 分之一)
反向:
- 分层计算,得到梯度
- 通过 Reduce Scatter 更新 gradient*
- 每个卡更新其中一部分
- 根据 all gather 更新
ZeRO-1做了什么:
- 把模型参数和更新参数的状态(optimizer states)分给了8个进程,每进程一小份。
- 这样减少了每个进程的内存占用。
ZeRO-2在此基础上优化了梯度(gradient)的处理:
- 原来这8个进程计算 Parameter 的梯度时,每个进程都要把整个完整的梯度保存起来。
- ZeRO-1将 Optimizer States 分小段储存在了多个进程中,所以在计算时,这一小段的Optimizer States也只需要得到进程所需的对应一小段Gradient就可以。
- 遵循这种原理,和Optimizer States一样,ZeRO-2也将Gradient进行了切片。
举个例子,在ZeRO-1的基础上,优化了“工人实施维修”这个过程:
原来每个工人执行自己路段的维修时,还是要把整条路的维修进度和结果都记在自己本子上。
现在,每人只记录自己负责部分的实施维修情况,不需要记下整条路的实施细节。
最后汇总大家的实施结果,就能检查出整条路的修复情况。
总结一下区别:
-
ZeRO-1: 优化了“计划制定”的内存,每人只制定自己路段的方案
-
ZeRO-2: 在此基础上,优化了“实施过程”的内存,每人只记录自己路段的实施细节
通过逐步优化不同阶段的内存占用,进一步降低了每个进程的总体内存消耗。
ZeRO-3
前向:
- 数据分片,每个卡是模型参数的一部分
- 通过 all gather 获取模型全部参数(多了一次计算)
- 算完后,只保留一部分参数
反向:
- 分层计算,得到梯度
- 通过 Reduce Scatter 更新 gradient*
- 每个卡更新其中一部分
- 根据 all gather 更新
更精细的通信优化。
3 在 2 基础上,原来计划制定和执行记录都需要工人们全体讨论。
现在改为只跟相邻的2名工人沟通,再传给下一个人,最后传遍所有工人,减少了沟通量。
总结三者区别:
- 1、优化了计划制定的内存
- 2、优化了执行过程的内存
- 3、优化了集体协作时的通信量
逐步进行了阶段性的优化,逐步减少内存和通信消耗。
3 具体怎么实现呢?
初始化:
- 模型由多个 submodule (子模块)组成,每个子模块都有对应的参数 parameter tensors(模型参数)
- ZeRO-3会按照GPU的数量(例如8块GPU),把每个submodule的parameter tensors分割成8份小数据块,存储在8个不同的GPU进程中
- 这8个小数据块中的数据可以重组合并成为完整的原始 parameter tensors
- 因此这个 submodule 在每个GPU进程里都完整保存了一遍 parameter tensors 现在就成了冗余/重复的数据
- 所以ZeRO-3会释放每个GPU进程内 submodule 里的本地完整 parameter tensors,只保留那一小块划分的数据
总结一下:
- 原来每个submodule的参数完整保存8遍(每个GPU进程一遍),现在只保存参数的一小部分,其它进程中是同样数据的冗余拷贝就可以删除了,这样减少了每个进程的内存占用。
举个例子,假设模型有一个子模块,有一个参数tensor,长度是100(即有100个参数元素),全部参数元素的值是1-100。
原来这个tensor是完整保存的:
- GPU 1进程: 1 2 3 … 100
GPU 2进程: 1 2 3 … 100
GPU 3进程: 1 2 3 … 100
…
GPU 8进程: 1 2 3 … 100
现在ZeRO-3改进后,分割和只保存一部分:
- GPU 1进程: 1 2 3 … 12
GPU 2进程: 13 14 15 … 25
GPU 3进程: 26 27 28 … 38
…
GPU 8进程: 88 89 90 … 100
原来每个GPU进程都完整保存了一遍全部100个参数。
现在只保存一部分,比如GPU1只保存 1-12 这12个参数的值。
这样就大大减少了每个GPU进程的内存 usages。
训练过程:
在训练过程中,ZeRO-3 会按照Submodule的计算需求进行参数的收集和释放:
- 在当前Submodule正向/反向传播计算前,ZeRO-3会先通过 all-gather 操作。
- All-gather就是从其他进程收集该子模块需要用的参数数据块(ds_tensor)。
- 收集回来的数据块可以重新组合起来,恢复成该子模块完整的参数(param),用于训练计算前向、反向。
ZeRO-3在训练过程中采用的就是“用完即释放”的机制。
并行框架
-
Deepspeed: 是微软开发。提供了多种优化技术,包括模型并行、梯度积累、零冗余优化等,可以显著提高大规模模型的训练效率和性能。
-
Megatron-LM: 是 NVIDIA开发。一个用于训练大型语言模型的开源项目。结合了模型并行和数据并行的技术,通过分布式训练和优化策略来提高训练速度和扩展性。
-
Colossal-AI: 是新加坡国立大学开发。提供了对大规模模型进行并行训练的能力,支持模型并行和数据并行,并提供了一系列的优化策略和工具,以提高训练效率和性能。
对比框架的优势
| 框架 | 应用场景 | 好 | 坏 |
|---|---|---|---|
| Deepspeed | 预训练、微调、推理 | 简单可用 | 预训练需要定制 |
| Megatron-LM | 预训练 | 分布式训练最成熟、3D并行 | 定制 |
| Colossal-AI | 训练、微调 | 方法多 | 没实践案例 |
| Accelerate | 微调 | API便捷 | 没预训练案例 |
预训练基本就用 Deepspeed、Megatron-LM。
微调基本就用 Accelerate、Deepspeed。
数据并行策略方面:
- Deepspeed 的 ZeRO-1/2/3 原创、最强
模型并行策略:
- Deepspeed 的 Ulysses 最新、好用
Offload 技术:
- Deepspeed 的 ZeRO-Offload 原创、配套
- Colossal-AI 的 PatrickStar 进一步精细的优化
Other features:
- Deepspeed 特性最多
集成环境:
- Megatron-LM 最多,直接把同行 Deepspeed、Fairscale 集成了
- 同行收集库,我收集同行
Deepspeed 实战 切片数据并行
Deepspeed 地址:https://github.com/microsoft/DeepSpeed.git
Deepspeed 项目:https://github.com/tatsu-lab/stanford_alpaca
加载了TransNormer-LLM的预训练模型权重,演示了基于 Deepspeed 的 ZeRO1/2/3 使用方式。
Accelerate 实战 超大模型推理
详情,请猛击:https://blog.csdn.net/qq_56591814/article/details/134373026

















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









