







提出背景
论文:https://arxiv.org/pdf/2401.05695.pdf
起始问题: 如何提高大型语言模型(LLMs)在医疗对话生成中的逻辑一致性和诊断准确性?
5why分析:
- Why 1: 为什么现有的医疗对话模型存在逻辑一致性和诊断准确性问题?原因是训练数据的质量和模型对话逻辑的不足。
- Why 2: 这个原因为什么会导致逻辑一致性和诊断准确性问题?因为数据和对话逻辑不足不能准确模拟医生的诊断过程。
- Why 3: 为什么会有这样的原因?现有研究主要关注单轮对话的优化,忽视了多轮对话中的逻辑一致性。
- Why 4: 这个原因背后的更深层次原因是什么?医疗领域的复杂性要求高度的专业性和准确性,这在传统的模型训练方法中难以实现。
- Why 5: 最根本的原因是什么?缺乏有效的训练方法和算法来集成和优化医疗专业知识和对话逻辑。
5so分析:
- So 1: 因此,我们可以通过大模型集成医生的诊断逻辑和偏好学习方法来解决或改进。
- So 2: 这个解决方案或改进会带来更高的逻辑一致性和诊断准确性。
这个解法是 PLPF — 偏好学习自过程反馈(PLPF)方法。
它将医生的诊断逻辑集成到LLM中。
PLPF涉及规则建模、偏好数据生成和偏好对齐,以训练模型遵循诊断过程。
为什么PLPF需要拆解为这三个步骤?
原因是这三个步骤反映了医疗诊断过程中的关键阶段:
- 理解规则(规则建模)
- 评估情况(偏好数据构建)
- 做出决策(人类偏好对齐)
规则建模
制定一套详细的医疗对话流程规则,包括如何询问病史、判断何时进行诊断以及如何推荐治疗。
首先,我们需要了解医生如何与患者进行对话,包括询问病史、判断症状、建议检查、下诊断和提供治疗建议的流程。
然后,基于这个流程,制定一套规则,这些规则会指导模型在对话中的每一步应该如何进行,确保每一步都符合医学逻辑和实际操作。
- 特征1(规则定义):通过流程图定义六条规则,包括任务导向和约束导向规则,以评估对话是否遵循特定的诊断流程。
通过实际的医疗对话数据训练一个规则评估模型(REM),用于自动评估生成的对话是否符合预先定义的医疗对话流程。
- 特征2(规则评估模型REM的开发):利用Q&A任务格式开发REM,通过手工注释的数据集进行训练,以自动评估对话是否符合定义的规则。
医疗对话流程图:
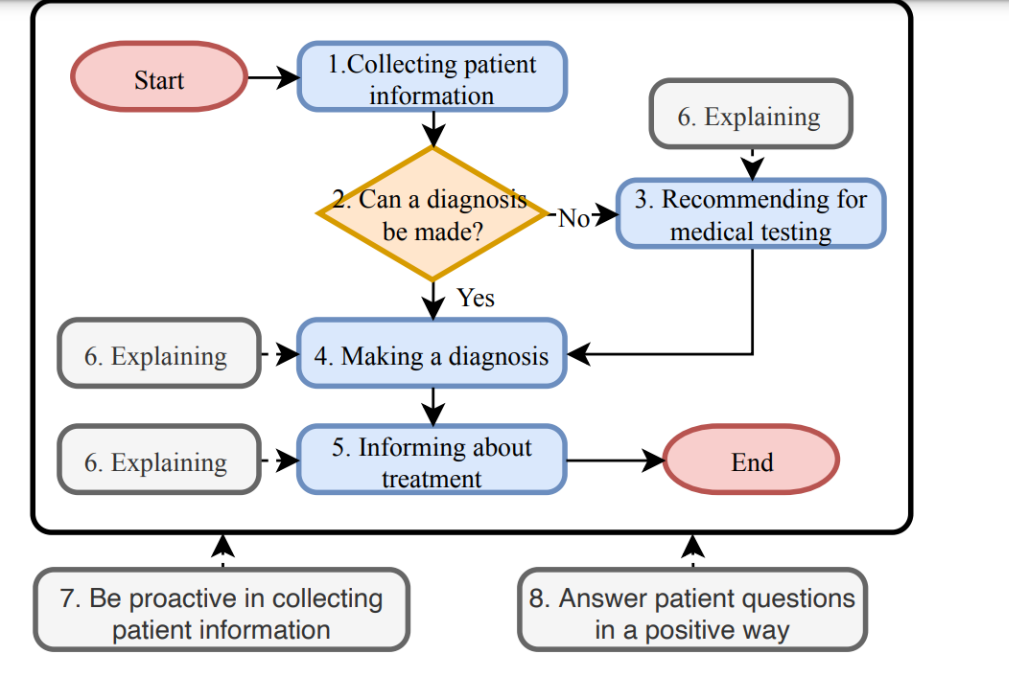
- 使用蓝色框表示活动、橙色菱形表示判断条件,以及灰色框表示额外的约束。
- 流程图包含了三个本地约束,鼓励医生向患者解释活动内容,以及两个全局约束,鼓励积极收集患者信息以及在医疗对话中积极回答患者问题。
这幅图直接关联到规则建模阶段。
它定义了医疗对话中的关键活动和决策节点,这些是之后需要在语言模型中实现和遵循的规则。
这些规则会在后续阶段用于生成和评估偏好数据。
偏好数据构建
接着,使用已经制定的规则去评估现有的医疗对话数据。
这个过程可能需要医学专家去手动标注数据,评价对话中的每一句话是否遵守了我们的规则。
同时,开发一个自动的规则评估模型(REM),这个模型能够自动判断一个对话是否符合我们的规则。
- 特征3(候选回复生成):通过数据采样和轨迹预测生成候选回复,旨在学习如何完成多阶段任务。
- 特征4(回复排名):利用REM对候选回复进行评分和排名,选择高分回复并排除低分回复,以此构建偏好数据。
从规则建模到偏好数据构建的整个过程:
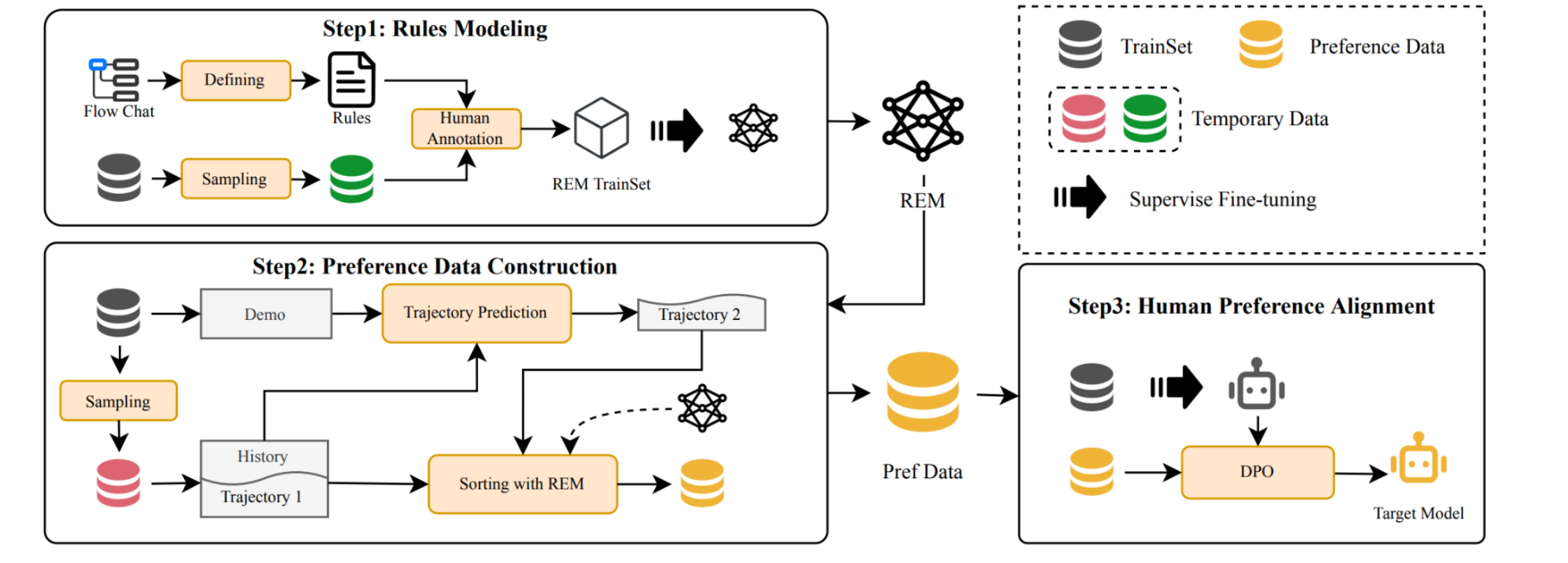
- 训练过程被划分为三个步骤,分别用不同颜色的圆角方框标出了关键活动。
- 每个步骤分别为:规则建模、偏好数据构建和人类偏好对齐,通过不同的数据处理和优化技术来训练最终的目标模型。
CSPT数据集的实验结果:
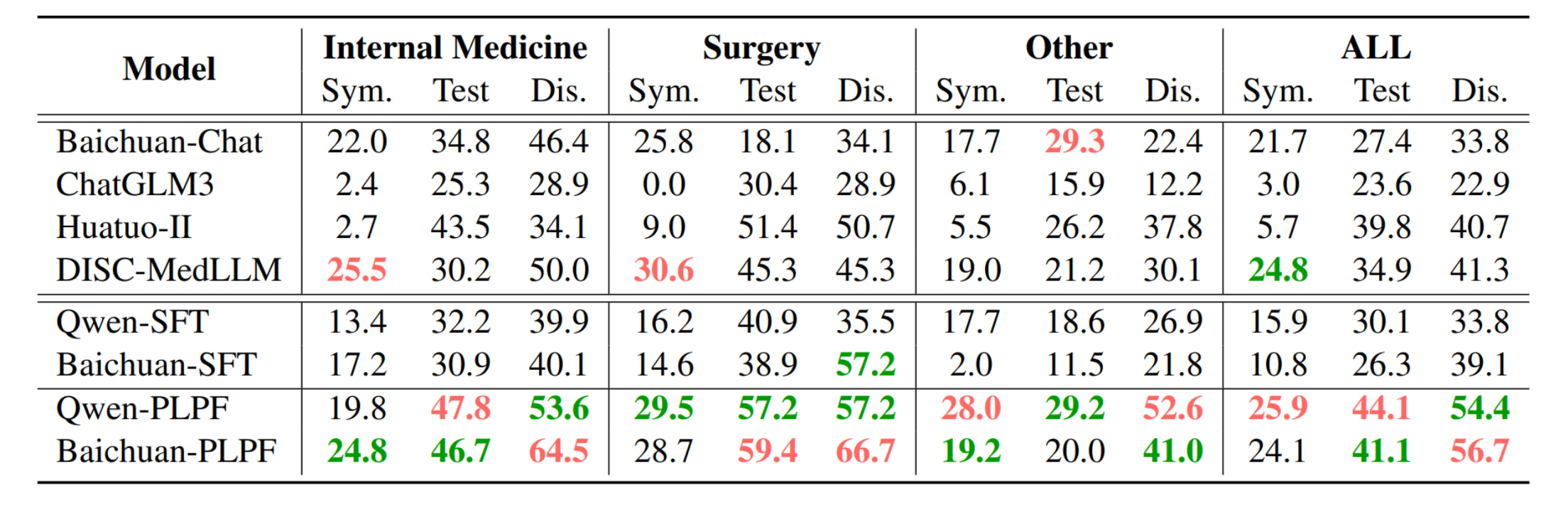
- 表格展示了不同模型在CSPT数据集上的表现,包括识别关键症状、医学测试和疾病诊断的概率。
- 红色和绿色标签分别表示最佳和次佳结果,我们的PLPF优化模型在多个方面都取得了显著的提升。
人类偏好对齐
- 特征5(模型训练):使用标注好的数据对基础模型进行微调,然后应用直接偏好优化(DPO)算法训练模型,以学习偏好数据,优化模型以偏好选择的回复而非拒绝的回复。
以偏向于产生更符合医生诊断逻辑的对话。
反映了人类偏好对齐阶段的成果:
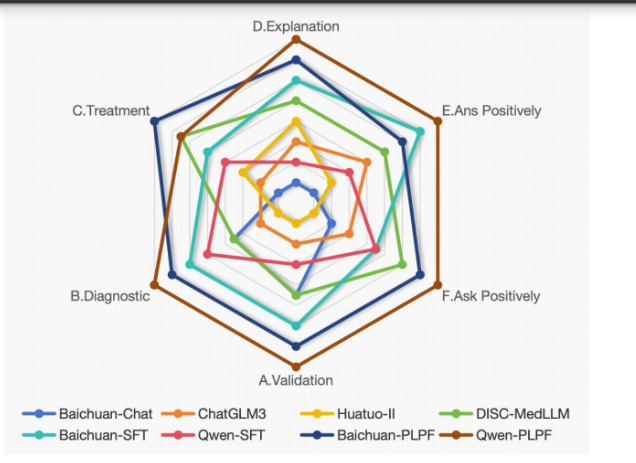
雷达图展示了各个模型遵循六个规则的程度,每个规则对应雷达图的一个轴。
模型的排名以每个雷达轴上的分数表示,分数越高,排名越靠前。
实验结果
作者在实验中,使用不同模型处理相同患者案例(急性阑尾炎)时的对话历史。
- Baichuan-Chat 有效地生成了潜在的病人诊断列表,并与特定的解释相关联。
- Huatuo-II 使用单轮对话完成多轮对话任务,但未能协助病人使用对话历史中的症状信息来解释医学检查结果。
- DISC-MedLLM 有效地从病人那里获取了他们的症状信息,但回答模板化,大部分回答用于提供建议。
- PLPF (Baichuan-base) 严格遵循询问症状、提出诊断、验证诊断和建议治疗的过程。
不同模型对比
Baichuan-Chat: 在处理标准化病人案例时,Baichuan-Chat能够有效列出潜在诊断并与具体解释相关联,但在指导病人验证诊断方面表现不足,有时会避免回答病人的某些询问。
Huatuo-II: Huatuo-II的独特之处在于尝试使用单轮对话完成多轮对话任务。然而,它在使用对话历史中的症状信息帮助病人解读医疗测试结果方面存在不足。
DISC-MedLLM: 虽然DISC-MedLLM有效地从病人那里获取症状信息,但它采用固定的回复模板,回复往往过长且缺乏针对性。
论文复现
PLPF(偏好学习自过程反馈)方法是一种结合了医生诊断逻辑的大型语言模型训练方法。
PLPF主要包含以下步骤:
-
规则建模:
- 根据医生的诊断流程创建一个详细的流程图。
- 为每个步骤定义明确的规则,包括何时收集信息、何时进行诊断、何时建议治疗等。
-
偏好数据生成:
- 使用规则评估模型(REM)来自动评估生成的对话是否符合预先定义的规则。
- 生成候选对话,然后使用REM为这些对话打分,以建立一个偏好数据集。
-
偏好对齐:
- 利用偏好数据对模型进行训练,使用如直接偏好优化(DPO)算法等技术来调整模型的参数,使其更倾向于生成符合医生诊断逻辑的对话。
要实现这个方法,你需要:
- 一组定义良好的医疗对话规则。
- 大量的医疗对话数据进行训练和测试。
- 一个能够处理自然语言并生成对话的预训练语言模型。
- 一个规则评估模型来自动评分对话的质量。
- 一个算法来进行偏好对齐,例如DPO。
以下是基于这些步骤的一个高层次的概念实现:
# 定义医疗对话的规则
rules = define_medical_dialogue_rules()
# 加载和预处理医疗对话数据
dialogues = load_and_preprocess_medical_dialogues()
# 使用预训练的语言模型生成候选对话
candidate_responses = generate_candidate_responses(pretrained_model, dialogues)
# 使用规则评估模型为候选对话打分
rem_scores = score_with_rem(candidate_responses, rules)
# 生成偏好数据集
preference_data = construct_preference_data(rem_scores)
# 使用偏好数据对模型进行训练
trained_model = train_with_preference_data(pretrained_model, preference_data, DPO_algorithm)
# 使用训练好的模型生成符合医生诊断逻辑的对话
final_dialogues = generate_dialogues(trained_model)
需要一个预训练的语言模型作为起点,可能是GPT-3或类似的模型。
还需要一个REM,能够根据规则来评分对话。
最后,需要实现一个训练算法,比如DPO,来根据偏好数据调整模型的行为。

















 1326
1326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









