







HyDE 假设性文档嵌入:大模型 + 对比学习,从关键词相似度搜索到语义搜索
提出背景
论文:Precise Zero-Shot Dense Retrieval without Relevance Labels
代码:https://github.com/texttron/hyde
HyDE 特别适合,当需要捕获广泛的语义内容并减少对关键词直接依赖时。
比如医学一个概念有很多术语,比如用户搜索感冒,数据库是风热流感,这俩的相似度很低,相似度匹配解决不了,只能语义匹配。
相似度搜索工作原理:
- 相似度搜索依赖于直接比较查询词与数据库中文档的关键词的匹配度。
- 使用如TF-IDF(词频-逆文档频率)或余弦相似度等算法来评估查询与每个文档的相似度。
- 最终的输出是根据相似度分数排序的文档列表,分数最高的文档最相关。
应用场景:
- 医生输入查询:“膝关节炎治疗方法”。
- 检索系统在医学文档数据库中查找包含“膝关节炎”和“治疗方法”这些关键词的文档。
- 返回的结果直接反映了关键词的出现频率和文档中的分布情况。
HyDE工作原理:
- HyDE首先通过一个生成性语言模型根据输入的查询“膝关节炎治疗方法”生成一个内容丰富的、假设性的答案或文档,这个文档详细描述了可能的治疗方法,如药物治疗、物理治疗、手术选项等,即使这样的文档在实际数据库中并不存在。
- 然后,这个生成的假设文档被转换成嵌入向量,使用对比编码器进行编码。
- 系统使用这个向量与数据库中文档的向量进行相似度比较,寻找与假设文档内容相似的实际文档。
应用场景:
- 通过假设性文档生成和后续的向量比较,HyDE能够捕捉查询的深层意图和复杂内容,不仅限于关键词匹配。
- 这使得即使医生的查询用词非常专业或非常通俗,系统也能理解并返回最相关的、专业的医疗建议和研究成果。
相似度搜索比作使用地图找到特定地址,而HyDE则像是先绘制一个详尽的旅行指南,然后再在地图上寻找与之最匹配的路径。
相似度搜索直接依赖于现有的、明确的标记和路径,而HyDE通过创造性地解释和拓展查询内容,提供更深层次的匹配和理解。
通过这种方式,HyDE不仅提高了检索的相关性和准确性,还能处理更复杂和多样化的查询,特别适用于需要高度解释性和语义理解的领域,如医疗、法律和科研文献检索。
流程图
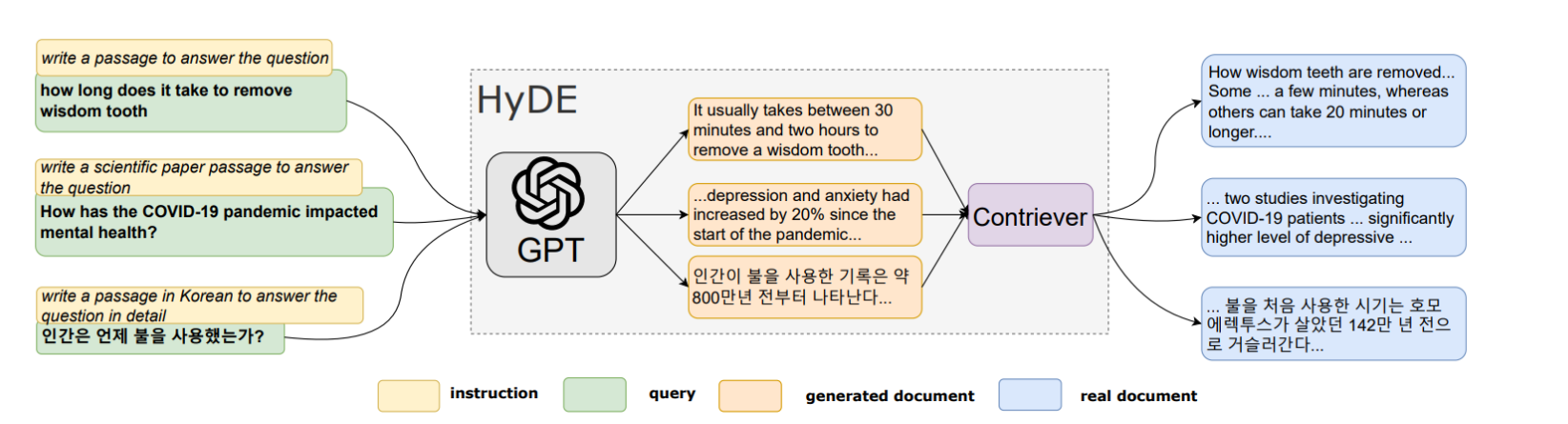
这张图是对Hypothetical Document Embeddings (HyDE) 模型的说明。
这个模型通过以下步骤来处理和检索信息:
-
输入指令和查询:HyDE接收一个查询指令,例如“写一个段落来回答这个问题”。
这个查询可以涵盖各种主题,如图中示例所示,包括“智齿拔除需要多长时间”,“COVID-19大流行如何影响心理健康?”,以及“인간은 언제 피를 사용했나요?”(人类何时开始使用血液?)。
-
生成文档:根据查询指令,一个基于GPT的语言模型生成一个假设的文档。
这个文档不是真实的,但它旨在模拟相关文档的内容。
例如,对于智齿拔除的查询,生成的文档可能会说“通常需要30分钟到两小时来拔除智齿”。
-
文档编码与检索:生成的文档被送入一个对比学习的编码器(如图中的Contriever),该编码器将文档转换成嵌入向量。
然后,这个向量被用来在语料库中查找最相似的真实文档。
-
返回结果:模型根据生成的文档与真实文档之间的语义相似性返回查询结果。
例如,关于智齿拔除的查询可能返回一些解释智齿拔除过程的真实文档。
这个模型的特点是它不直接计算查询与文档之间的相似度,而是通过生成文档和编码这两个步骤间接地处理查询,使得系统能够以零样本的方式工作,即不依赖于具体的相关性标签进行训练。
这使得HyDE模型能够适应多种语言和任务,即使在没有明确训练数据的情况下也能进行有效的文档检索。
解法拆解
目的:解决零样本密集检索的问题,这是因为在没有相关性判断或评分的情况下,传统的密集检索模型难以学习查询和文档的嵌入表示。
解法:HyDE模型设计
-
子解法1:单一文档嵌入空间的搜索
- 特征:只需学习文档之间的相似性,无需处理查询的嵌入。
- 原因:这通过使用无监督的对比学习来实现,可以简化学习过程,因为它不依赖于外部的相关性标签。
例如,通过Izacard等人的研究(2021),已经证明无监督对比学习在没有明确监督的情况下有效地学习文档特征。 -
子解法2:指令跟随型语言模型(InstructLM)的引入
-
特征:通过生成“假设文档”来间接捕获查询的相关性。
-
原因:InstructLM能根据给定的指令生成内容,这种方法将查询相关性的建模负担从传统的表示学习转移到了更容易泛化的自然语言生成模型上。
这使得模型即使在缺乏明确相关性数据的情况下也能有效工作。
例如,如果指令是“写一个回答问题的段落”,InstructLM生成的文档虽然不是真实的,但能够反映出与查询相关的内容模式。
-
-
子解法3:生成文档的嵌入编码
-
特征:通过文档编码器将生成的“假设文档”转化为嵌入向量,再进行相似性搜索。
-
原因:使用文档编码器f作为损失压缩器,可以过滤掉生成文档中的冗余细节,只保留与查询相关的核心内容,从而实现高效的文档检索。
这种方法利用了文档之间的相似性嵌入,进一步将假设向量与实际语料库中的真实文档对齐。
-
逻辑链:这些子解法形成一个线性逻辑链,每个步骤都是为了解决零样本密集检索中遇到的具体问题。
首先通过无监督学习建立文档嵌入,然后利用指令跟随模型生成与查询相关的假设文档,最后通过文档编码器压缩和过滤信息,执行有效的检索。
这个过程通过结合无监督学习和自然语言生成技术,创新性地解决了无法直接从标注数据学习的难题。
类比
想象一下你正在组装一套复杂的家具,但你没有明确的说明书,只有一些基本的工具和一些不标记的零件。
这就是传统密集检索系统在没有相关性标签时面临的挑战:它们需要准确地匹配查询和文档,但缺乏直接指导他们如何完成任务的明确指示。
HyDE模型的设计就像是给你一个能够生成使用说明的智能工具,同时也提供了检测哪些工具和零件最适合当前步骤的能力。
1. 单一文档嵌入空间的搜索
类比:这就像使用一个高级的金属探测器在沙滩上寻找金属物体。
探测器不需要知道每个物体具体是什么,只需要识别出哪些地方有金属物体。
在HyDE模型中,这个过程相当于用对比学习探测文档库中的文档,识别它们之间的相似性,而不是直接寻找与特定查询完全匹配的文档。
2. 指令跟随型语言模型(InstructLM)的引入
类比:想象你有一个能够根据你描述的需要自动生成建议方案的智能助手。
比如你说:“我需要一个可以放杂志的小桌子。”
即使你没有直接说明要用木头制作,智能助手也能生成一个包括材料和设计的建议方案。
在HyDE中,InstructLM正是这样一个智能助手,它能根据查询生成一个假设性的“方案”(即文档),捕捉查询的核心需求。
3. 生成文档的嵌入编码
类比:这就像把一份详细的设计图纸转换成一个更简洁的部件清单。
在建造时,你不需要再次查看复杂的图纸,只需根据这个清单挑选正确的材料和工具即可。
HyDE模型中的编码器就是这样一个工具,它将生成的文档转换为核心特征的集合(即向量),使得检索系统能够快速有效地找到与这些特征匹配的真实文档。
通过这种方式,HyDE模型有效地解决了传统密集检索在无标注数据情况下的局限,通过创新的方法优化了信息检索过程,使其更加智能和适应性强。
这种模型不仅适用于学术和科研领域,也可以广泛应用于医疗、法律、商业等信息密集型行业,提高检索的准确性和效率。

















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









