









论文:KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques
代码:https://github.com/YangRui525/KG-Rank
如何个性化理解?
提出背景是什么?
- 这个研究的背景是为了解决大语言模型在医疗问答中存在的事实一致性问题。具体来说,是为了解决大语言模型在生成长篇医疗问答内容时可能出现的事实错误或不一致问题。
独特性质是什么?
- KG-Rank框架的主要性质是结合知识图谱和排序技术来增强大语言模型的医疗问答能力。这一性质源于将外部结构化医疗知识与先进的自然语言处理技术相结合的设计。
能不能举个例子?
- 一个例子是,对于询问"53岁急性肾衰和肝衰竭男性的理想饮食建议"的问题,KG-Rank能够生成更准确的答案,建议限制蛋白质摄入量为每公斤体重0.8-1.0克,而不是原始模型建议的1.6-2.2克。
能不能类比一下?
- KG-Rank就像是给大模型配备了一个医学专家顾问团。当模型需要回答医疗问题时,这个"顾问团"(知识图谱)会提供准确的医学知识,而"会议主席"(排序技术)则确保最相关的信息被优先考虑。
总结归纳
- KG-Rank是一个结合医学知识图谱和排序技术的大语言模型增强框架。它通过从知识图谱中检索相关信息,并使用多种排序技术优化这些信息,来提高模型生成长篇医疗问答的准确性。
概念定义是什么?
- KG-Rank是一个知识图谱增强排序框架,它通过图谱中的知识来增强语言模型的回答,同时用排序技术来筛选最相关的知识。
有什么关联?
- 这个KG-Rank框架与上文中提到的大模型在医疗问答中存在事实一致性问题有直接关联。它正是为了解决这个问题而提出的解决方案。
能否发现规律?
- 在这个研究中:
- 原则:结合外部知识和排序技术来增强大模型
- 立场:提高医疗问答的准确性和可靠性至关重要
- 方法:使用知识图谱检索+多种排序技术+再排序
- 主要矛盾:如何有效地将外部知识整合到大模型中以提高其事实一致性
- 次要矛盾:如何选择最相关的知识,如何在不同领域应用该框架等
如何分析?
升维
背景:大语言模型在医疗问答中存在事实一致性问题。
现状:生成长篇医疗问答内容时可能出现事实错误或不一致。
期望:提高大语言模型在医疗问答中的准确性和可靠性。
问题本质:如何有效地将外部医学知识整合到大语言模型中,以提高其事实一致性。
降维
-
公式法:KG-Rank = 知识图谱 + 排序技术 + 大语言模型
-
要素:
- 医学知识图谱(UMLS)
- 实体抽取和映射
- 关系检索
- 三元组排序
- 再排序
- 大语言模型
-
逻辑:
外部知识 → 相关性筛选 → 知识整合 → 准确回答 -
流程:
问题输入 → 实体抽取 → 知识检索 → 三元组排序 → 再排序 → LLM生成答案 -
模型:
KG-Rank框架 = 知识检索模块 + 排序模块 + 大语言模型 -
二分法:
- 内部知识 vs. 外部知识
- 相关信息 vs. 不相关信息
- 排序前 vs. 排序后
-
矩阵法:
检索 排序 生成
准确性 ↑ ↑ ↑
效率 ↓ - ↑
可解释性 ↑ ↑ - -
第一性原理:
- 准确的医学知识是回答医疗问题的基础
- 相关性决定了知识的有效利用
- 大语言模型具有强大的文本生成能力
梳理
-
目标、目的、本质的问题:
如何提高大模型在医疗问答中的事实一致性和准确性? -
实现目标、解决问题的步骤、条件、要素:
- 步骤:实体抽取 → 知识检索 → 排序 → 再排序 → LLM生成
- 条件:高质量的医学知识图谱、有效的排序算法、强大的大模型
- 要素:知识图谱、排序技术、大语言模型
-
每个步骤、条件、要素的提升/改良:
- 知识图谱:扩展和更新UMLS,提高覆盖率和时效性
- 实体抽取:优化NER模型,提高准确率
- 知识检索:改进检索算法,提高相关性
- 排序技术:开发更先进的排序算法,如考虑上下文的动态排序
- 再排序:优化MedCPT模型(医学交叉编码模型),提高其在医疗领域的表现
- 大模型:针对医疗领域进行微调,提高领域适应性
MedCPT模型(医学交叉编码模型):
-
目的:
确保选择最相关的三元组,进一步提高知识的相关性和准确性。 -
工作原理:
- 交叉编码:这种技术允许模型同时考虑问题和候选答案(在这里是三元组),而不是单独处理它们。
- 精确评估:通过同时处理问题和三元组,模型可以更准确地判断三元组与问题的相关性。
-
过程:
- 输入:已经经过初步排序的三元组和原始问题。
- 处理:MedCPT模型将问题和每个三元组作为一对输入,计算它们之间的相关性得分。
- 输出:根据新的相关性得分,对三元组进行重新排序。
-
优势:
- 上下文感知:考虑了问题和三元组之间的语义关系,而不仅仅是表面的相似度。
- 领域特化:MedCPT是专门为医学领域设计的,因此能更好地理解医学术语和概念。
-
结果:
- 最终选择出与问题最相关的三元组,为大语言模型提供更精准的知识支持。
这个步骤相当于在初步筛选后进行的"精细化筛选",确保提供给大语言模型的知识不仅相关,而且是最优质、最贴切的。
解法拆解
- 按照逻辑关系中文拆解【pdf】:
目的:提高大语言模型在医疗问答中的事实一致性和准确性。
问题:如何有效地将外部医学知识整合到大语言模型中?
解法:KG-Rank框架
子解法1(因为需要准确的医学知识):使用医学知识图谱(UMLS)
- 之所以用医学知识图谱,是因为它提供了结构化的、可靠的医学知识。
子解法2(因为需要识别问题中的医学实体):实体抽取和映射
- 之所以用实体抽取和映射,是因为需要将问题中的关键医学术语与知识图谱中的实体对应起来。
子解法3(因为需要获取相关的医学知识):关系检索
- 之所以用关系检索,是因为需要从知识图谱中获取与问题相关的医学知识。
子解法4(因为需要筛选最相关的信息):三元组排序
- 之所以用三元组排序,是因为需要从大量检索到的信息中筛选出最相关的知识。
子解法5(因为需要进一步优化相关性):再排序
- 之所以用再排序,是因为需要进一步提高筛选出的知识与问题的相关性。
子解法6(因为需要生成自然语言回答):大语言模型
- 之所以用大语言模型,是因为它能够基于提供的知识生成流畅、连贯的自然语言回答。
例子:
对于询问"53岁急性肾衰和肝衰竭男性的理想饮食建议"的问题,KG-Rank框架首先通过实体抽取识别出"急性肾衰"、"肝衰竭"等关键词,然后从UMLS中检索相关知识,通过排序和再排序筛选出最相关的信息(如蛋白质摄入量建议),最后由大语言模型生成准确的答案,建议限制蛋白质摄入量为每公斤体重0.8-1.0克。
- 这些子解法的逻辑链是一个决策树形式的链条:
KG-Rank框架
|
├── 使用医学知识图谱(UMLS)
|
├── 实体抽取和映射
|
├── 关系检索
|
├── 三元组排序
|
├── 再排序
|
└── 大语言模型
- 分析隐性特征:
在这个解法中,存在一个隐性特征:知识整合的动态性。
这个特征不直接出现在问题或条件中,而是体现在解法的中间步骤中。
隐性方法:动态知识整合
定义:动态知识整合是指根据具体问题,实时从知识图谱中提取相关信息,并通过多层次排序来优化知识的相关性和重要性,最终将筛选后的知识无缝整合到大模型的生成过程中。
这个隐性特征体现在以下几个步骤的组合中:
- 实体抽取和映射:根据问题动态识别关键实体
- 关系检索:基于识别的实体动态检索相关知识
- 三元组排序和再排序:动态调整和优化知识的相关性
- 大语言模型生成:将筛选后的知识动态整合到回答生成过程中
这种动态知识整合方法使得KG-Rank框架能够针对每个具体的医疗问题,灵活地调用和整合最相关的外部知识,从而提高回答的准确性和相关性。
全流程分析
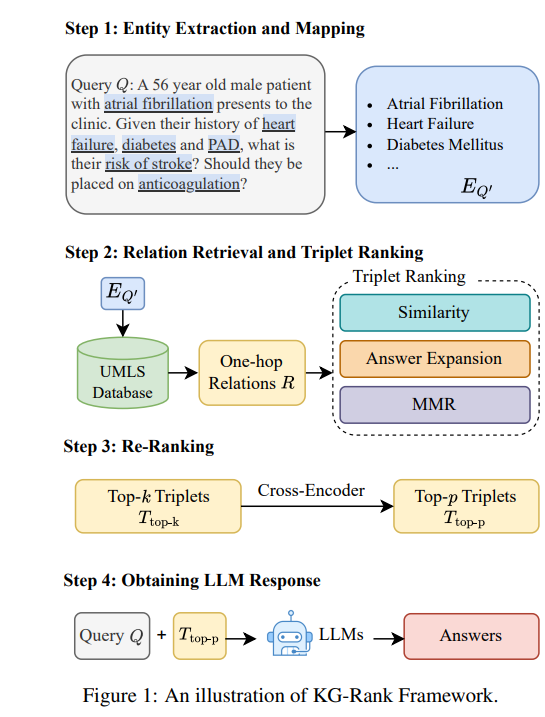
这张图描述了KG-Rank框架的工作流程,分为四个主要步骤:
-
实体提取和映射:
从查询中提取关键医学实体(如心房颤动、心力衰竭、糖尿病等)。 -
关系检索和三元组排序:
- 使用UMLS数据库检索与提取实体相关的一跳关系。
- 对检索到的三元组进行排序,使用三种方法:相似度、答案扩展和MMR(最大边际相关性)。
-
重新排序:
使用 MedGPT 医学交叉编码器模型对top-k个三元组进行重新排序,得到top-p个最相关的三元组。 -
获取LLM响应:
将原始查询和筛选出的top-p个三元组输入到大语言模型(LLMs)中,生成最终答案。
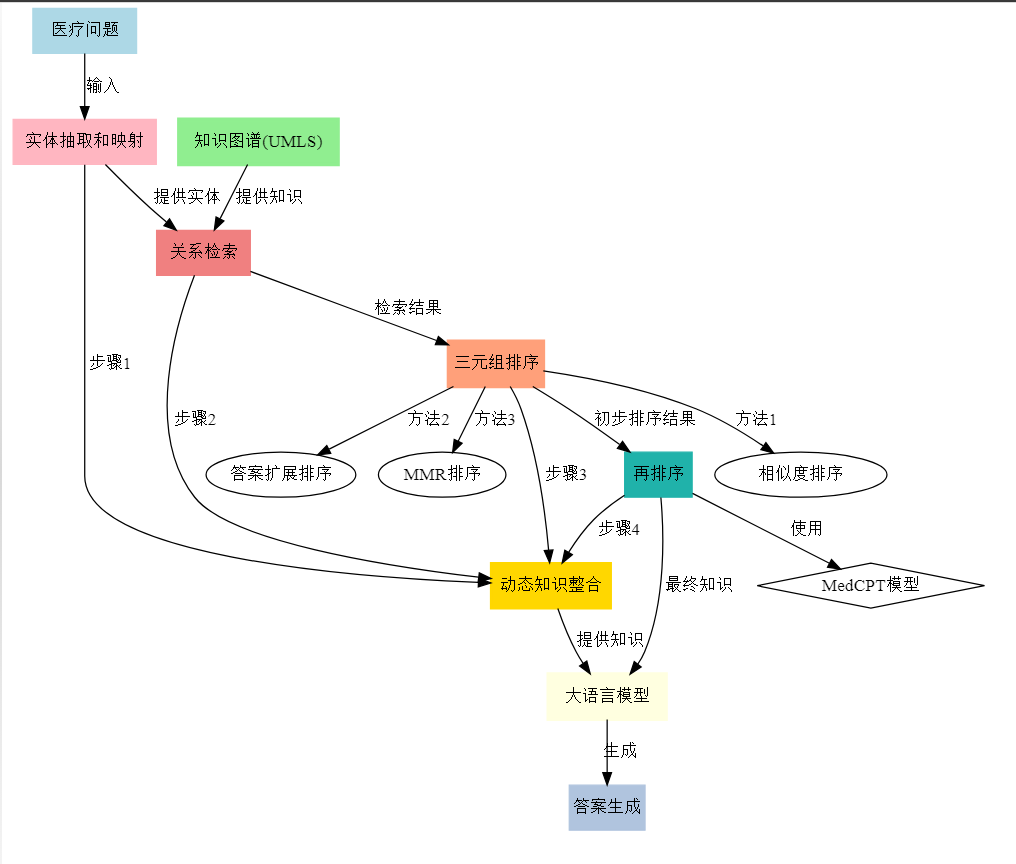
- 全流程优化
多题一解:
KG-Rank框架是一种"多题一解"的方法,它可以应用于各种医疗问答任务。
共用特征是"需要准确的外部医学知识",共用解法是"知识图谱增强排序框架"。
当遇到需要专业医学知识、长篇回答的问题时,都可以使用这种解法。
一题多解:
在三元组排序阶段,KG-Rank提供了多种解法:
- 相似度排序:对应特征 - 问题与三元组的语义相似性
- 答案扩展排序:对应特征 - 问题的潜在答案内容
- MMR排序:对应特征 - 信息的相关性和多样性
显性特征:
- 医疗问题的专业性
- 知识图谱的结构化特性
- 大语言模型的生成能力
隐性特征:
- 动态知识整合
- 多层次排序的必要性
- 领域特定的再排序需求
更直接的特征: 医疗知识的结构化表示与自然语言问题之间的语义映射
更优化的解法:
- 引入医学领域特定的预训练语言模型,提高实体抽取和映射的准确性
- 使用图神经网络增强知识图谱的表示能力
- 开发自适应的排序策略,根据问题类型动态选择最适合的排序方法
- 引入多任务学习,同时优化知识检索、排序和答案生成
- 利用强化学习优化整个框架的端到端性能
替换解法分析:
- 实体抽取和映射:使用医学领域特定的BERT模型替代通用NER模型,可以提高医学实体识别的准确率
- 关系检索:引入基于图嵌入的检索方法,可以捕捉更复杂的语义关系
- 排序方法:使用基于BERT的语义相似度计算替代传统的相似度计算,可以更好地理解问题和知识的语义关系
- 再排序:使用更先进的跨模态预训练模型(如CLIP)替代MedCPT,可能进一步提高再排序的效果
- 大语言模型:使用针对医疗领域微调的大语言模型,可以生成更专业、更准确的回答
通过这些优化,KG-Rank框架可以在实体识别、知识检索、信息排序和答案生成等各个环节得到提升,从而在整体上实现更高的准确性和效率。
特别是动态知识整合的引入,使得框架能够更灵活地适应不同类型的医疗问题,提供更精准的回答。
如何关联?
分析性关联图

所有知识点之间的关联,是什么样子?
KG-Rank框架【核心概念】
├── 医疗问答增强【主要目标】
│ ├── 提高事实一致性【具体目标】
│ └── 提高答案准确性【具体目标】
├── 知识图谱集成【核心技术】
│ ├── UMLS【具体知识源】
│ └── 三元组检索【知识获取方法】
│ ├── 实体抽取和映射【预处理步骤】
│ └── 关系检索【知识检索步骤】
├── 多重排序技术【关键功能】
│ ├── 相似度排序【排序方法1】
│ ├── 答案扩展排序【排序方法2】
│ │ ├── LLM生成幻觉答案【中间步骤】
│ │ └── 文本嵌入编码【中间步骤】
│ └── MMR排序【排序方法3】
├── 再排序优化【精细化处理】
│ ├── MedCPT模型【具体工具】
│ └── 选择最相关三元组【处理目标】
└── 大语言模型集成【最终处理】
├── 输入处理【数据准备】
│ ├── 再排序后的top-p三元组【知识输入】
│ └── 任务提示【任务指导】
└── 答案生成【最终输出】
方法部分:
KG-Rank框架【整体流程】
├── 输入【起始点】
│ ├── 医疗问题【用户查询】
│ └── UMLS知识图谱【外部知识源】
├── 处理过程【核心步骤】
│ ├── 知识图谱集成【知识获取】
│ │ ├── 实体抽取和映射【预处理】
│ │ │ └── NER技术【具体方法】用于识别医学实体
│ │ └── 三元组检索【知识检索】
│ │ └── 图遍历算法【具体方法】用于获取相关知识
│ ├── 多重排序技术【知识优化】
│ │ ├── 相似度排序【方法1】
│ │ │ └── 向量相似度计算【具体技术】用于评估相关性
│ │ ├── 答案扩展排序【方法2】
│ │ │ ├── LLM生成幻觉答案【中间步骤】利用大模型生成初步回答
│ │ │ └── 文本嵌入编码【中间步骤】将问题和答案转化为向量
│ │ └── MMR排序【方法3】
│ │ └── 多样性和相关性平衡【特点】避免信息冗余
│ ├── 再排序优化【精细化处理】
│ │ ├── MedCPT模型【核心工具】
│ │ │ └── 交叉编码技术【具体方法】进行更精确的相关性评估
│ │ └── 选择最相关三元组【处理目标】
│ │ └── Top-k选择算法【具体方法】筛选最相关知识
│ └── 大语言模型集成【知识应用】
│ ├── 输入处理【数据准备】
│ │ ├── 再排序后的top-p三元组【结构化知识】作为上下文信息
│ │ └── 任务提示【指令】引导模型生成答案
│ └── 答案生成【文本生成】
│ └── 条件文本生成【具体技术】基于输入生成连贯答案
└── 输出【最终结果】
└── 医疗问答答案【生成内容】具有高准确性和事实一致性
为什么排序算法会增加多样性?
起始问题: 用知识图谱和多级排序(相似度排名、答案扩展排名、MMR排名、重排)增强大模型,解决医疗问答准确性、多样性,为什么排序还能增加多样性?
5why分析:
Why 1: 为什么多级排序能增加多样性?
- 原因是多级排序中包含了MMR(最大边际相关性)排名。
Why 2: 为什么MMR排名能增加多样性?
- 因为MMR算法在选择相关信息时,同时考虑了与已选信息的差异性。
Why 3: 为什么考虑差异性能增加多样性?
- 因为这样可以避免选择重复或高度相似的信息,确保选择的信息涵盖不同角度。
Why 4: 为什么涵盖不同角度很重要?
- 因为医疗问题通常是复杂的,需要从多个方面进行考虑和分析。
Why 5: 为什么医疗问题需要多角度分析?
- 因为这符合医学实践中全面评估和诊断的原则,能提供更全面、准确的医疗建议。
问题:糖尿病患者应该注意哪些饮食事项?
-
知识图谱检索后的初始信息:
a) 限制碳水化合物摄入
b) 控制总热量
c) 增加纤维摄入
d) 选择低糖食物
e) 控制脂肪摄入
f) 均衡蛋白质摄入
g) 注意食物的血糖指数
h) 避免含糖饮料
i) 定时定量进食
j) 多吃全谷物 -
相似度排名可能会选择:
a, b, c, d (主要关注直接相关的饮食建议) -
答案扩展排名可能会加入:
e, f (考虑到更全面的营养需求) -
MMR排名会进一步考虑:
g, i (添加一些不同角度的建议,如血糖指数和进食时间) -
重排可能会最终选择:
a, c, e, g, i
糖尿病患者的饮食应注意以下几点:
-
- 限制碳水化合物摄入,控制血糖上升;
-
- 增加纤维摄入,有助于稳定血糖;
-
- 控制脂肪摄入,特别是饱和脂肪,以管理体重和心血管健康;
-
- 注意食物的血糖指数,选择低血糖指数的食物;
-
- 保持定时定量进食,有助于稳定血糖水平。"
这个例子展示了如何通过多级排序,特别是MMR排名,选择出既相关又多样的信息。
最终的答案不仅包含了基本的碳水化合物控制建议,还涵盖了纤维、脂肪、血糖指数和进食时间等多个角度,提供了一个更全面、多样的饮食指导。
这种多样性使得答案更加全面,能更好地帮助糖尿病患者管理他们的饮食。
能不能搞个创意?
-
组合:
将KG-Rank与虚拟现实(VR)技术结合,创造一个"知识图谱可视化诊断系统"。医生可以通过VR设备直观地"漫游"在患者的症状、诊断和治疗选项构成的3D知识网络中,实现更直观、更深入的医疗决策过程。 -
拆开:
将KG-Rank框架拆分为独立的微服务模块,如实体识别服务、知识检索服务、排序优化服务等。这样可以提高系统的灵活性和可扩展性,允许医疗机构根据自身需求选择性地部署和组合这些服务。 -
转换:
将KG-Rank从医疗问答系统转换为医学研究辅助工具。研究人员可以利用这个系统快速检索和关联跨学科的医学知识,发现潜在的研究方向或假说。 -
借用:
从社交网络推荐算法中借鉴个性化推荐技术,为KG-Rank添加个性化知识推荐功能。系统可以根据医生的专业背景、过往查询历史等,提供更有针对性的知识支持。 -
联想:
联想到蜜蜂的集群智能,可以设计一个"医疗集群智能系统"。多个KG-Rank实例可以像蜜蜂一样协同工作,共享和优化知识图谱,形成一个不断进化的医疗知识网络。 -
反向思考:
考虑KG-Rank的反面用途 - 创建一个"医疗谬误检测器"。利用系统的知识图谱和推理能力,识别和纠正医疗文献、社交媒体或公共健康信息中的错误或误导性信息。 -
问题:
深入探讨KG-Rank可能面临的核心问题,如知识更新的实时性。开发一个"实时医学知识更新系统",自动从最新发表的医学论文和临床试验结果中提取知识,实时更新知识图谱。 -
错误:
将KG-Rank的错误预测视为机会,开发一个"医疗诊断学习系统"。系统记录每次错误预测,并通过人工智能算法分析这些错误,不断改进其知识结构和推理能力。 -
感情:
在KG-Rank中引入情感分析功能,创建"情感感知型医疗问答系统"。系统能够识别患者问题中的情感倾向,提供不仅在医学上准确,而且在情感上恰当的回答。 -
模仿:
模仿人类医生的思维过程,为KG-Rank添加"医学直觉模拟器"。通过分析大量优秀医生的诊断过程,模拟人类医生的直觉判断,提供更接近人类专家的诊断建议。 -
联想法:
使用随机联想法,将"天气"这个概念与KG-Rank联系起来。创建一个"医疗-环境相关性分析系统",探索环境因素(如天气变化)对特定疾病发生率的影响,为公共卫生决策提供支持。 -
最渴望联结:
假设用户最渴望的是"永葆青春"。将KG-Rank与抗衰老研究结合,开发"个性化健康管理助手",根据个人基因、生活方式等数据,提供有针对性的抗衰老建议。 -
空隙填补:
识别当前医疗系统中的空隙 - 慢性病长期管理。开发基于KG-Rank的"智能慢性病管理平台",为患者提供持续的健康监测、用药提醒和生活方式建议。 -
再定义:
将KG-Rank重新定义为"医学知识探索引擎"。不仅回答问题,还主动发现知识间的新联系,启发医生和研究人员思考新的研究方向或治疗方法。 -
软化:
为KG-Rank添加幽默元素,创建"医学幽默问答助手"。在提供准确医学信息的同时,用轻松幽默的方式解释复杂的医学概念,提高患者的理解和接受度。 -
附身:
模拟名侦探的思维方式,开发"医学侦探模式"。系统像侦探一样收集"线索"(症状、检查结果等),推理可能的"犯罪者"(疾病),提供诊断过程的详细推理链。 -
配角:
关注医疗过程中被忽视的配角 - 护士。开发"智能护理助手",协助护士进行日常护理工作,如伤口评估、用药管理等,提高护理质量和效率。 -
刻意:
应用刻意夸张法,创建"极端情景模拟器"。系统能够模拟极端医疗情况(如大规模疫情爆发),帮助医疗机构进行应急预案制定和演练。 -
刻意省略:
故意省略某些医学术语,开发"通俗医学翻译器"。系统能将专业的医学语言转化为普通人易于理解的日常用语,促进医患沟通。
根据以上创新点,我们可以使用以下标准进行评估和选择:
- 实用性:创新点能否解决实际医疗问题
- 技术可行性:在当前技术条件下是否可实现
- 市场潜力:是否有广泛的应用前景
- 创新程度:相比现有解决方案的创新程度
- 社会影响:对医疗行业和社会的潜在正面影响
综合考虑这些因素,以下几个创新点可能最具价值:
- “医疗集群智能系统”:具有高度的实用性和创新性,可以大幅提升医疗知识的利用效率。
- “实时医学知识更新系统”:解决了医学知识快速更新的关键问题,具有很高的实用价值。
- “个性化健康管理助手”:结合了抗衰老这一广受关注的话题,市场潜力巨大。
- “医学知识探索引擎”:重新定义了系统的功能,可能带来医学研究方法的革新。
- “智能慢性病管理平台”:针对当前医疗体系的痛点,具有很高的社会价值和市场需求。
这些创新点既保留了KG-Rank的核心优势,又拓展了其应用范围和功能,有望带来显著的技术突破和社会效益。

















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









