







1 研究目的
现有的模型方法中存在以下问题:
• 堆叠生成器引入的纠缠问题• 限制额外网络在语义一致性方面的监督能力• 计算成本导致跨模态注意力文本 - 图像融合受限的问题
为了解决这些局限性,作者提出了一种更简单但更有效的深度融合生成对抗网络(DF-GAN)
• 单级的文本到图像生成骨干网络• 目标感知鉴别器和深度文本 - 图像融合块
该研究旨在简化模型结构并提高图像合成的效果和性能
2 模型结构
2.1 整体模型结构
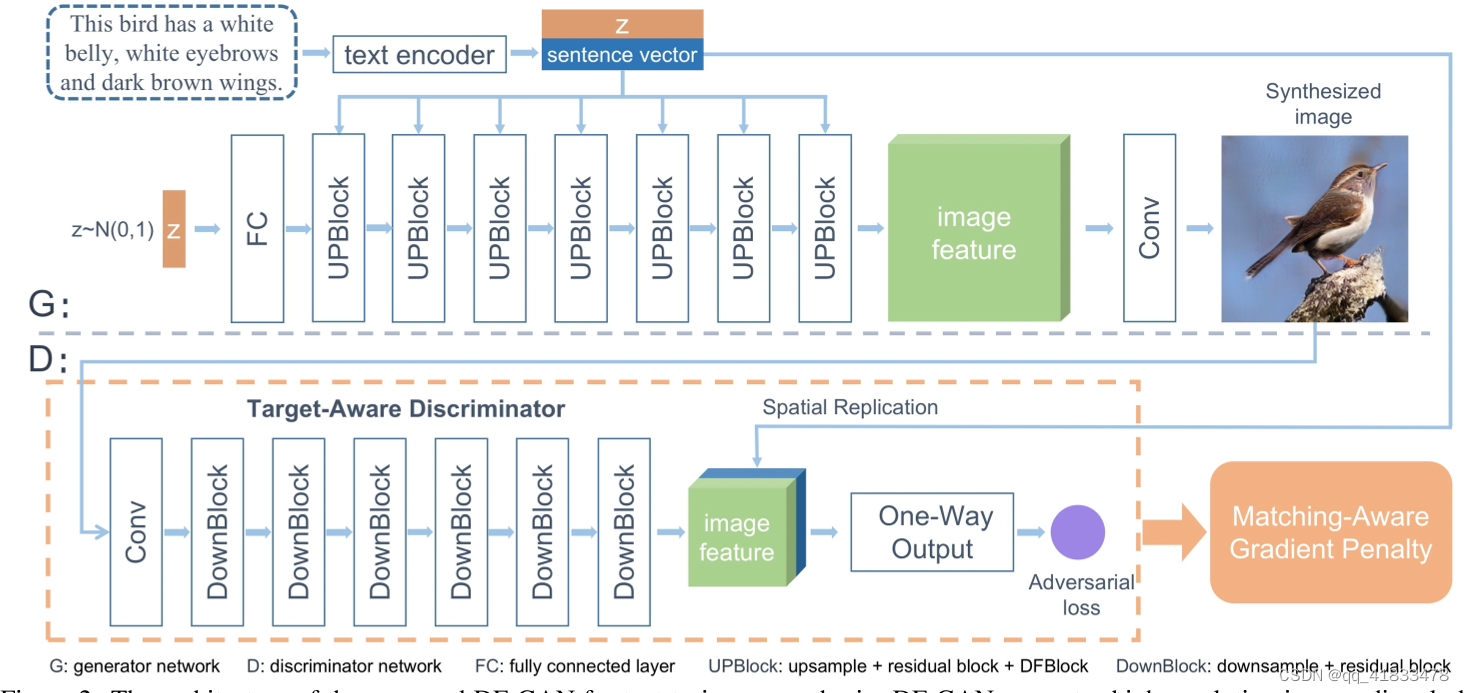
DF-GAN主要是由一个预训练的文本编码器,一个生成器,一个鉴别器组成
文本编码器(text encoder)是一个LSTM(长短期记忆网络),它从文本描述中提取语义向量。
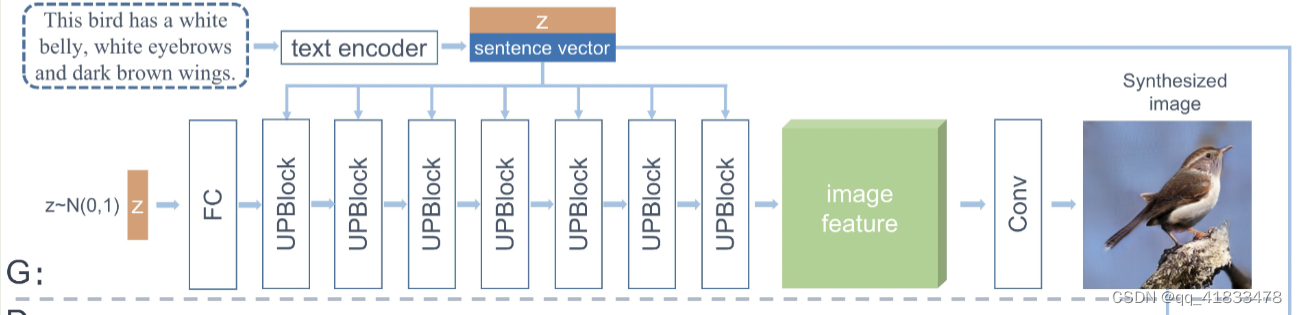
生成器有两个输入:一个是经过文本编码器处理后的句子向量,另一个是从正态分布上采用的随机噪声Z
- 将句子向量和噪声进行连接送入到生成器中的7个UPBlock(上采样块)
- 噪声向量通过全连接层(FC)进行重塑输入到UPBlock
- 经过一系列的UPBlock块生成图像特征,其中UPBlock块包括:一个上采样层,两个深度文本图像融合块(DFBlock,用于融合文本和图像特征),一个残差块(来稳定更深层次的网络训练)
- 最后卷积层将图像特征转换为图像
鉴别器使用一系列的DownBlock将图像转换为图像特征,然后将图像特征和复制的句子向量进行连接,一起送入到单向输出块,计算对抗性损失(包括视觉真实性和语义一致性)
其中计算损失时,使用的是铰链损失:

2.2 生成器

上面我们介绍生成器中的UPBlock中有一个上采样层,两个深度文本图像融合块(DFBlock,用于融合文本和图像特征),一个残差块,接下来详细介绍一下具体结构:
- UPBlock(a)有一个上采样层,两个DFBlock,一个残差块;其中DFBlock(b)由仿射层,ReLU,卷积组成;
- Affine(仿射层c)通过两个MLP(多层感知器)来调制从句子向量e预测的语言条件通道缩放参数
和移位参数
- 仿射层扩展了生成器的条件表示空间,但是,由于仿射变换是每个通道的线性变换,限制了文本图像融合过程的有效性
- 所以在Affine之间添加了两个ReLU层,该层将非线性带入融合过程,促进了视觉特征的多样性,扩大了表示空间,根据不同的文本描述来表示不同的视觉特征
(d1)生成器与跨模态注意
(d2)我们的生成器与 DFBlock 两者进行比较
2.3 鉴别器
作者在DF-GAN中设计的鉴别器为目标感知鉴别器(Target-Aware Discriminator),由匹配感知梯度惩罚和单向输出组成(红框)
由于鉴别器在我们的网络中联合训练,它可以防止生成器合成固定额外网络的对抗特征,这就意味着鉴别器的存在和训练可以防止生成器过度依赖这些额外网络来欺骗鉴别器。

2.3.1 匹配感知梯度惩罚

匹配感知梯度惩罚 (MA-GP) 是我们新设计的增强文本图像语义一致性的策略。
- 首先从新颖的角度展示无条件梯度惩罚 (橙色的虚线),然后将其扩展到我们的 MA-GP 用于文本到图像生成任务。
- 在无条件图像生成中,目标数据(真实图像)对应于低鉴别器损失。相应地,合成图像对应于高鉴别器损失。
- 铰链损失限制了 -1 和 1 之间的鉴别器损失范围。对真实数据的梯度惩罚将减少真实数据点及其附近的梯度。
- 然后对真实数据点周围损失函数的表面进行平滑处理,有助于合成数据点收敛到真实数据点。
2.3.2 单向输出
作者将双向输出和单向输出进行比较

该图展示的是双向输出
- 条件损失给出梯度
,指向反向传播后的图像真实和文本匹配方向
- 无条件损失给出梯度
,仅指向真实图像和文本不匹配方向
- 双向输出仅是将
由于生成器的目标是合成真实和文本匹配图像,因此偏差的最终梯度不能很好的实现文本图像语义一致性,减慢生成器的收敛过程。
所以作者提出单向输出

该图是双向输出和单向输出的结构
- (a)双向输出预测条件损失和无条件损失,并将它们相加作为最终的对抗性损失
- (b)单向输出直接预测整个对抗性损失,鉴别器连接图像特征和句子向量,然后通过两个卷积层只输出一个对抗性损失。通过单向输出,可以直接使单个梯度
目标感知鉴别器可以引导生成器合成更加真实和文本匹配的图像
3 实验评估

该表是DF-GAN和其他主流模型进行对比,从表中可以看到,DF-GAN在参数量很小的情况下仍然保持一定的竞争力,整体上优于其他模型

该表是进行的消融实验,来验证作者提出的MA-GP(匹配感知梯度惩)、OW-O(单向输出)和OS-B(单级文本到图像骨干)是有效的
对标的基线是采用堆叠框架和双向输出,与 StackGAN 具有相同的对抗性损失。在基线中,句子向量被简单的连接到输入噪声和中间特征图。

该表是将DFBlock与CBN、AdaIN和AFFBlock进行比较

定性分析,图像生成优于其他模型
4 优点
- 简单而有效:DF-GAN采用了单级的文本到图像生成网络,直接合成高分辨率的图像,避免了不同生成器之间的纠缠。
- 提高语义一致性:模型引入了目标感知鉴别器,通过匹配感知的梯度惩罚和单向输出来增强文本与图像之间的语义一致性,而无需引入额外的网络。
- 深度文本-图像融合:通过深度文本-图像融合块(DFBlock),将文本信息更有效地融入图像特征中。在所有图像尺度上堆叠多个DFBlock,深化了文本-图像融合过程,实现了文本和视觉特征的全面融合。
- 性能优越:与当前最先进的方法相比,DF-GAN在合成逼真且与文本匹配的图像方面取得了更好的性能。
5 缺点
- 模型只引入了句子级文本信息,这限制了细粒度视觉特征合成的能力
- 引入预训练的大型语言模型来提供额外的知识可能会进一步提高性能














 1563
1563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









