







转载于:https://zhuanlan.zhihu.com/p/32216294
在大多数普通用户眼里,CPU也许就是一块顶着铁盖子的电路板而已。但是如果我们揭开顶盖,深入正中那片小小的集成电路,我们会发现这里有着人类科技史上,最伟大的奇迹。几十亿个晶体管层层叠叠,密密麻麻挤在一起,占据着这个仅有一点几个平方厘米的狭小世界。晶体管们在“上帝之手”的安排下,组成了各个功能模块。而这些功能模块之间,则是宽阔无比的超高速公路。这条超高速公路如此重要,以至于它的距离、速度和塞车与否,会大大影响这个小小世界的效率。这些模块就是CPU内部的功能模块,例如内存控制器、L3/L2 Cache、PCU、PCIe root complex等等,而这条高速公路,就是我们今天的主角,片内总线了。
为什么需要片内总线?
片内总线连接Die内部的各个模块,是它们之间信息交流的必须途径。它的设计高效与否,会大大影响CPU的性能。如果我们把各个模块看做一个个节点,那么它们之间相互连接关系一般可以有以下几种:
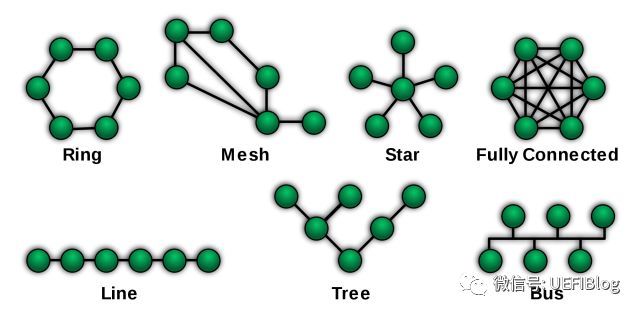
而我们CPU片内总线连接就经历了从星型(Star)连接–>环形总线(Ring Bus)–>Mesh网络的过程。
星型连接
早期CPU内部模块数目较少,结构单一,星型连结不失是一个简单高效的办法。
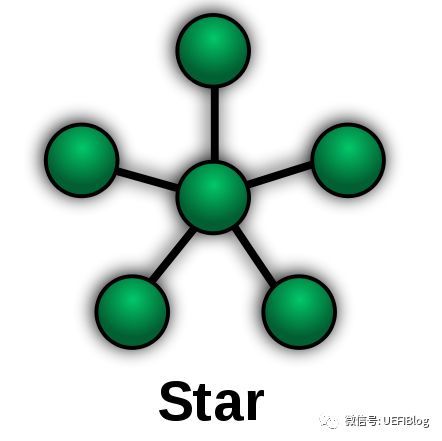
我们尊贵的Core无可争议的被放在中心的位置,各个模块都和它连接,而彼此并不直接交互,必须要Core中转。这种设计简单高效,被使用了相当长的时间。
问题随着多core的出现而显现出来,这个多出来的core放在哪里合适呢?一种星型连接的变种被利用起来。它类似一种双星结构,中间的节点似乎进行了有丝分裂,一分为二,各自掌管着自己的势力范围。同时为了高效,每个Core又伸出了些触手,和别的Core的小弟发生了些不清不楚的关系。问题被暂时解决了,这种混乱的关系被固定下来,世界又恢复了些许和平,直到Core数目的进一步增加。
环形总线(Ring Bus)
Intel的服务器产品线是第一个受不了这种临时安排的。至强CPU必须提供更多的CPU,而低效的变种星形连结限制了内核数目的增加,加上各个模块之间通讯的需求越来越多,一种新的总线便孕育而出。
在Nehalem EP/EX这个划时代的产品中,很多新技术被引入进来,Intel也由此确定了领先的地位。而Ring Bus就是其中重要的一个。

我们可以看到,Ring Bus实际上是两个环,一个顺时针环和一个逆时针环。各个模块一视同仁的通过Ring Stop挂接在Ring Bus上。如此设计带来很多好处:
- 双环设计可以保证任何两个ring stop之间距离不超过Ring Stop总数的一半,延迟较低。
- 各个模块之间交互方便,不需要Core中转。这样一些高级加速技术,如DCA(Direct Cache Access), Crystal Beach等等应运而生。
- 高速的ring bus保证了性能的极大提高。Core to Core latency 只有60ns左右,而带宽则高达数百G(记得Nehalem是192GB/s).
- 方便灵活。增加一个Core,只要在Ring上面加个新的ring stop就好,不用像以前一样考虑复杂的互联问题。
真是个绝妙的设计!然而,摩尔定律是无情的,计划能使用好久的设计往往很快就过时了,这点在计算机界几乎变成了普遍规律。Ring Bus的缺点也很快随着内核的快速增加而暴露出来。由于每加一个Core,ring bus就长大一些,延迟就变大一点,很快ring bus性能就随着core的增多而严重下降,多于12个core后会严重拖累系统的整体延迟。和星型连接一样,一种变种产生了:

在至强HCC(High Core Count, 核很多版)版本中,又加入了一个ring bus。两个ring bus各接12个Core,将延迟控制在可控的范围内。俩个Ring Bus直接用两个双向Pipe Line连接,保证通讯顺畅。于此同时由于Ring 0中的模块访问Ring 1中的模块延迟明显高于本Ring,亲缘度不同,所以两个Ring分属于不同的NUMA(Non-Uniform Memory Access Architecture)node。这点在BIOS设计中要特别注意。
聪明的同学可能要问了,如果Core比12个多,比24个少些呢?是不是凑合塞到第一个ring里拉倒呢?其实还有个1.5 ring的奇葩设计:

右边的是至强的LCC(Low Core Count)SKU,只有单Ring,而左边的MCC (Middle Core Count)则是 一个半Ring的设计!
核大战的硝烟远远尚未平息,摩尔定律带来的晶体管更多的都用来增加内核而不是提高速度(为什么CPU的频率止步于4G?我们触到频率天花板了吗?)24个Core的至强也远远不是终点,那么更多的Core怎么办呢?三个Ring设计吗?多于3个Ring后,它们之间怎么互联呢?这些困难促使Intel寻找新的方向。
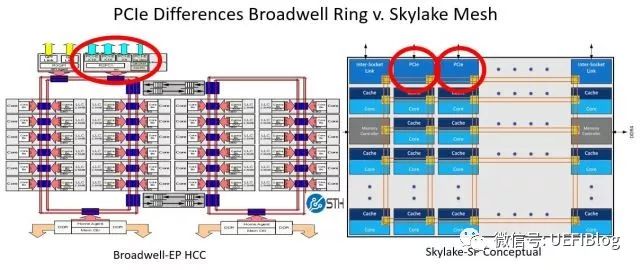
Mesh网络
Intel在Skylake和Knight Landing中引入了新的片内总线:Mesh。它是一种2D的Mesh网络:
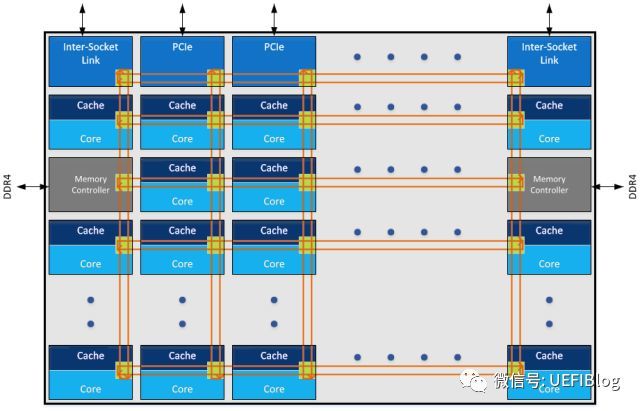
Mesh网络近几年越来越火热,它的灵活性吸引越来越多的产品加入对它的支持,包括我们的Wifi等等系统。Mesh网络引入片内总线是一个巨大的进步,它有很多优点:
- 首先当然是灵活性。新的模块或者节点在Mesh中增加十分方便,它带来的延迟不是像ring bus一样线性增加,而是非线性的。从而可以容纳更多的内核。
- 设计弹性很好,不需要1.5 ring和2ring的委曲求全。
- 双向mesh网络减小了两个node之间的延迟。过去两个node之间通讯,最坏要绕过半个ring。而mesh整体node之间距离大大缩减。
- 外部延迟大大缩短:
- RAM延迟大大缩短:
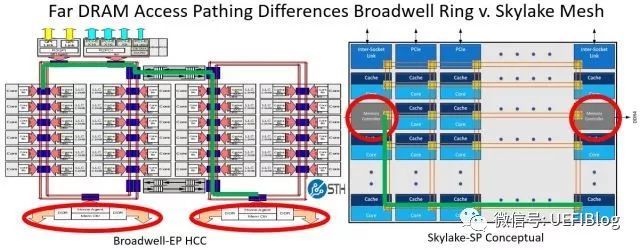
左边的是ring bus,从一个ring里面访问另一个ring里面的内存控制器。最坏情况下是那条绿线,拐了一个大圈才到达内存控制器,需要310个cycle。而在Mesh网络中则路径缩短很多。
- IO延迟缩短:
结论
Mesh网络带来了这么多好处,那么缺点有没有呢?它网格化设计带来复杂性的增加,从而对Die的大小带来了负面影响,这个我们会在下一篇文章中介绍,同时介绍相关性能详细数据,尽情期待。
最后请大家思考一下,为什么不干脆用全互联Full Connected网络来连接Die中的各个节点呢?

















 1303
1303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











