









 通过对电影数据集的深入分析,本博客揭示了豆瓣排名、评分、评论人数及电影时长之间的相关性,并通过折线图、条形图和直方图直观展示各项指标的分布与关系。
通过对电影数据集的深入分析,本博客揭示了豆瓣排名、评分、评论人数及电影时长之间的相关性,并通过折线图、条形图和直方图直观展示各项指标的分布与关系。
1、数据集预览
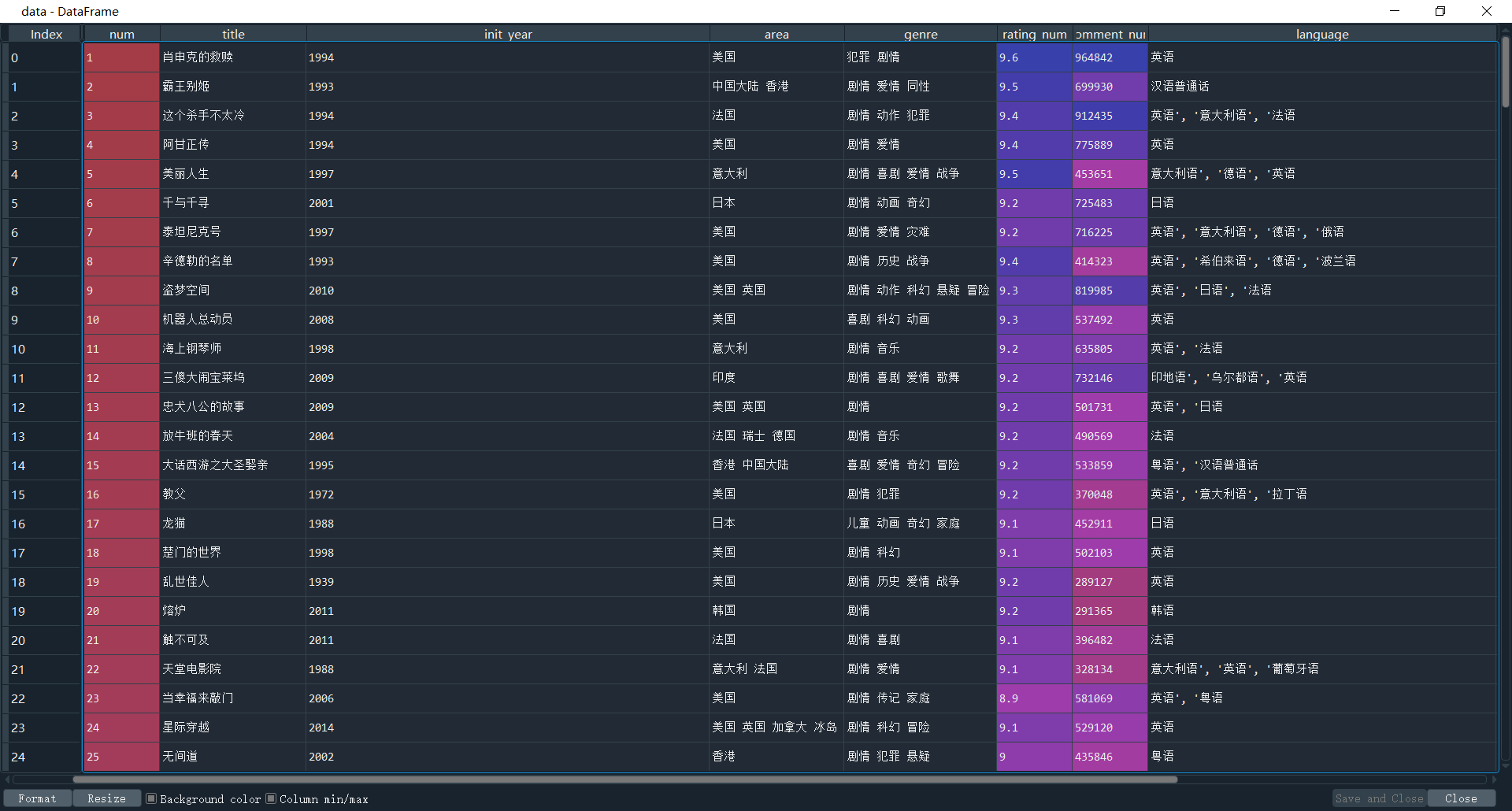
部分数据说明:
豆瓣排名num
评分rating_num
评分人数comment_num
电影时长movie_duration
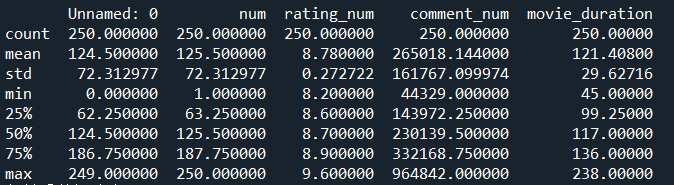
2、查看电影数据集基本数据信息
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('电影排名.csv') #读取数据
#1.查看电影数据集基本数据信息
print(data.describe())
3、Pearson相关系数分析数据之间的关系
#2.分析数据集中的数据项和电影排名的关系。
#输出Pearson相关系数,并保留两位小数
print('相关系数矩阵为:','\n',np.round(data.iloc[1:,1:].corr(method = 'pearson'), 2))
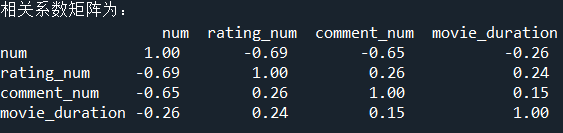
分析:
相关系数的绝对值越大,相关性越强:相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
(1)豆瓣排名num和评分rating_num之间的相关系数为:-0.69,可见其存在强相关关系。即评分越高,排名数越小(排名越靠前)
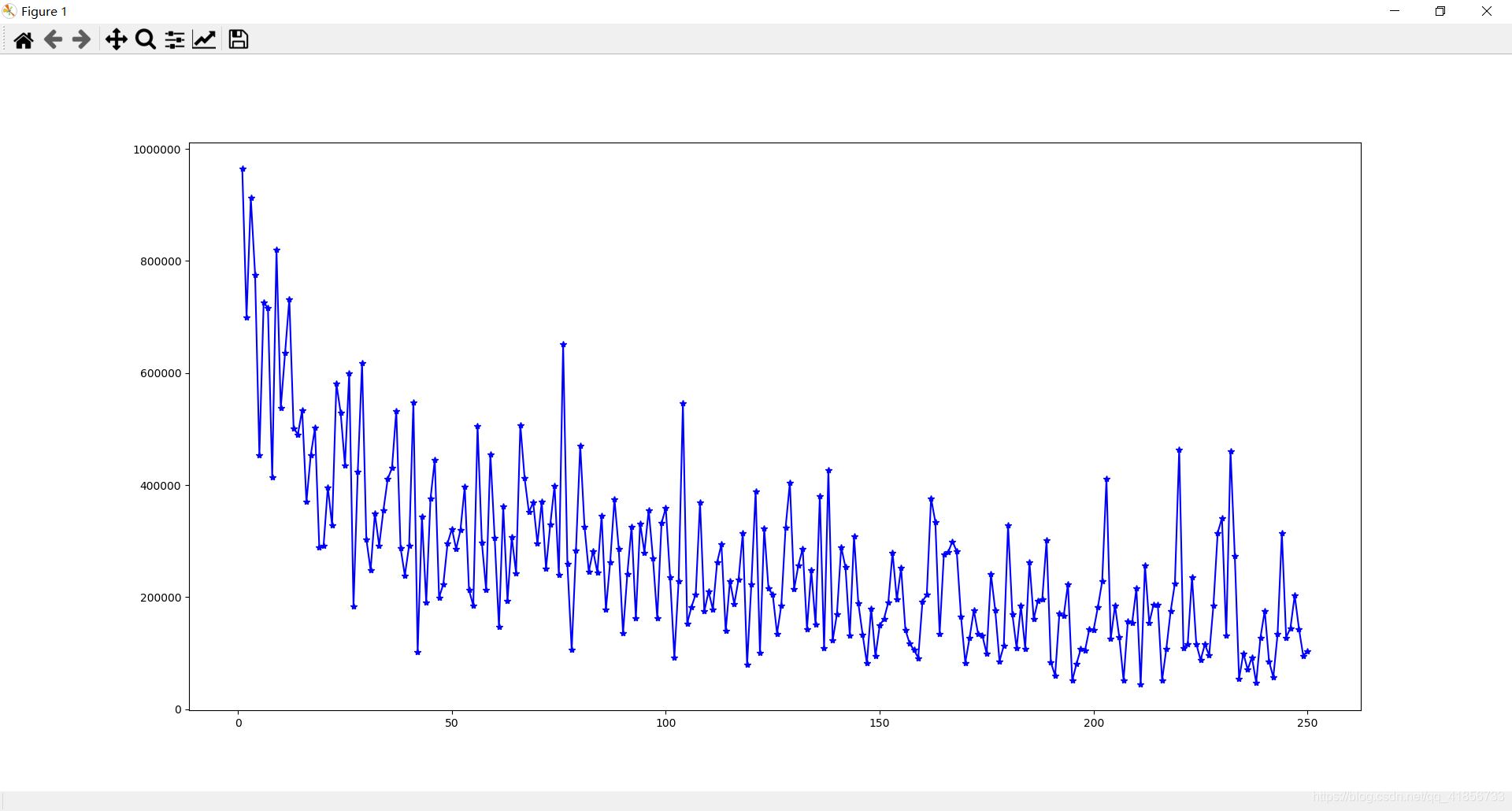
(2)豆瓣排名num和评分人数comment_num之间的相关系数为:-0.65,强相关,即评分人数越多,排名越靠前!
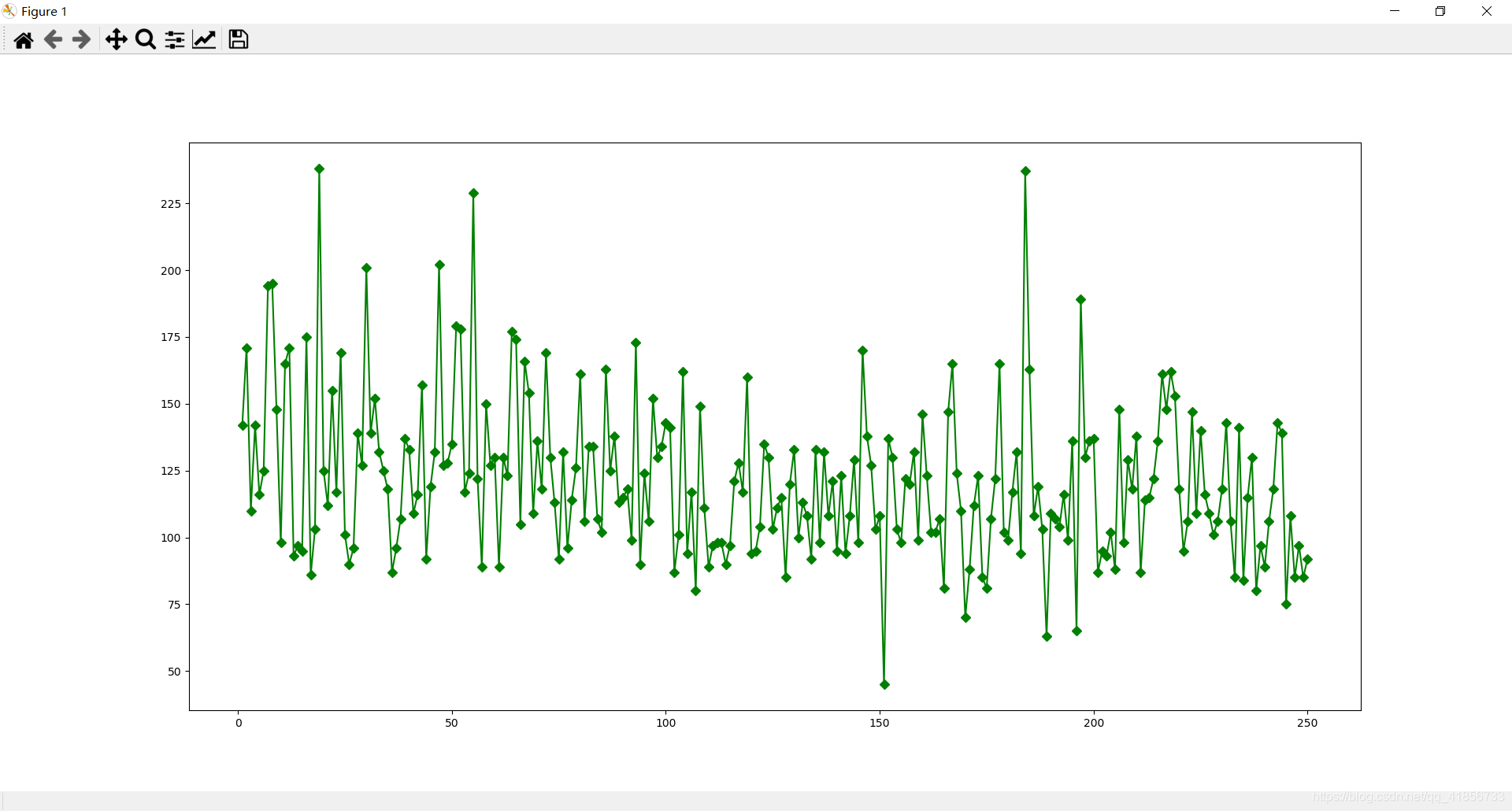
(3)豆瓣排名num和电影时长movie_duration的相关系数为:-0.26,关系为弱相关,可以认为这两者并没什么关系。(常识亦可知,一个电影的好坏,排名是否靠前,与其时长确实关系不大)
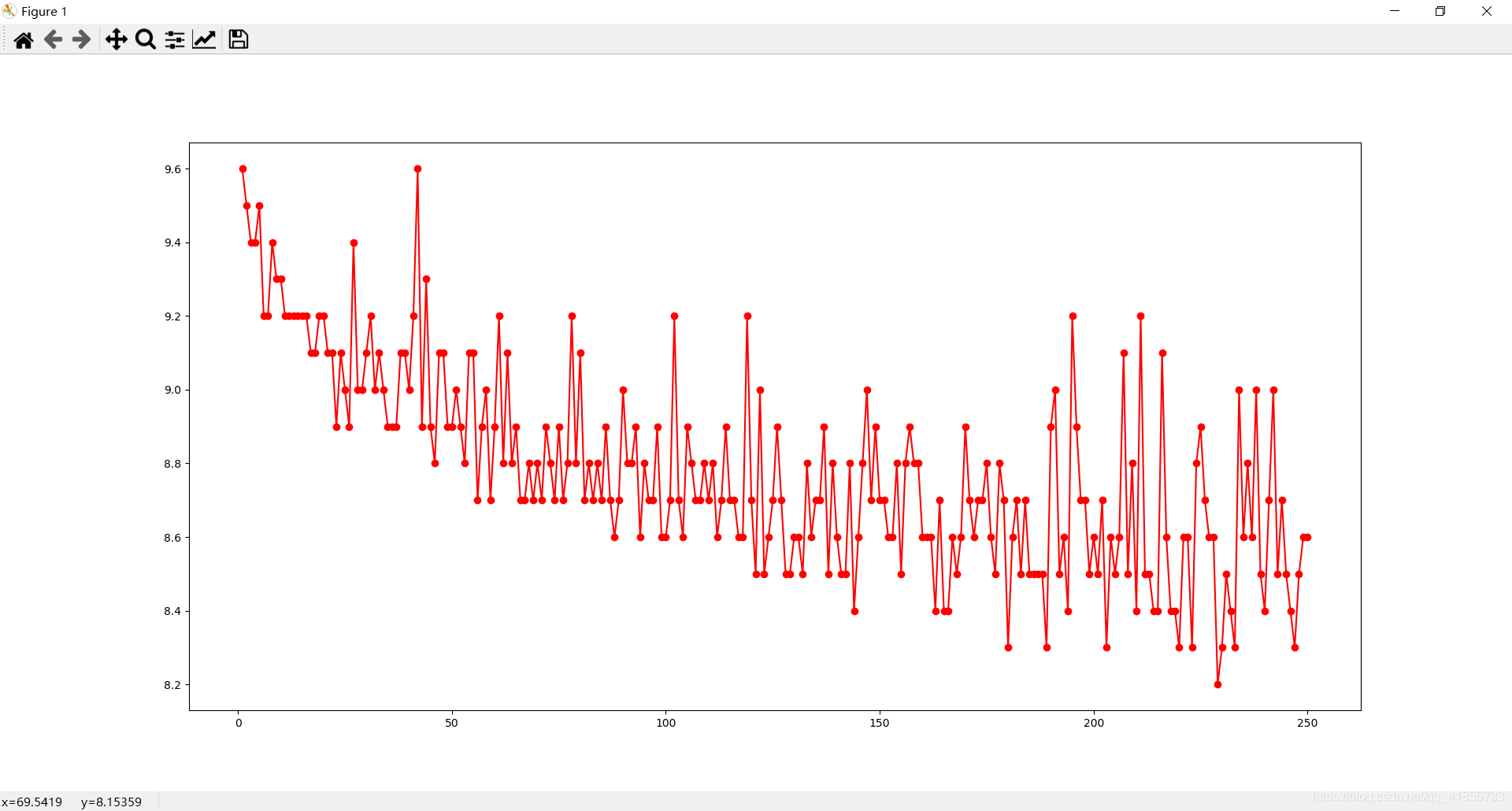
4、分析结果并使用图形说明
折线图
import matplotlib.pyplot as plt
#(1)豆瓣排名num和评分rating_num之间的关系折线分布图
plt.plot(data['num'],data['rating_num'],'ro-')
plt.show()
#(2)豆瓣排名num和评分人数comment_num之间的关系折线分布图
plt.plot(data['num'],data['comment_num'],'b*-')
plt.bar(data['num'],data['comment_num'])
plt.show()
#(3)豆瓣排名num和电影时长movie_duration的关系折线分布图
plt.plot(data['num'],data['movie_duration'],'gD-')
plt.show()
(1)豆瓣排名num和评分rating_num之间的关系折线图分布图
(2)豆瓣排名num和评分人数comment_num之间的关系折线分布图
(3)豆瓣排名num和电影时长movie_duration的关系分布折线图
条形图
#条形图
#plt.bar(data['num'],data['rating_num']-8) #通过减8的方法来控制范围
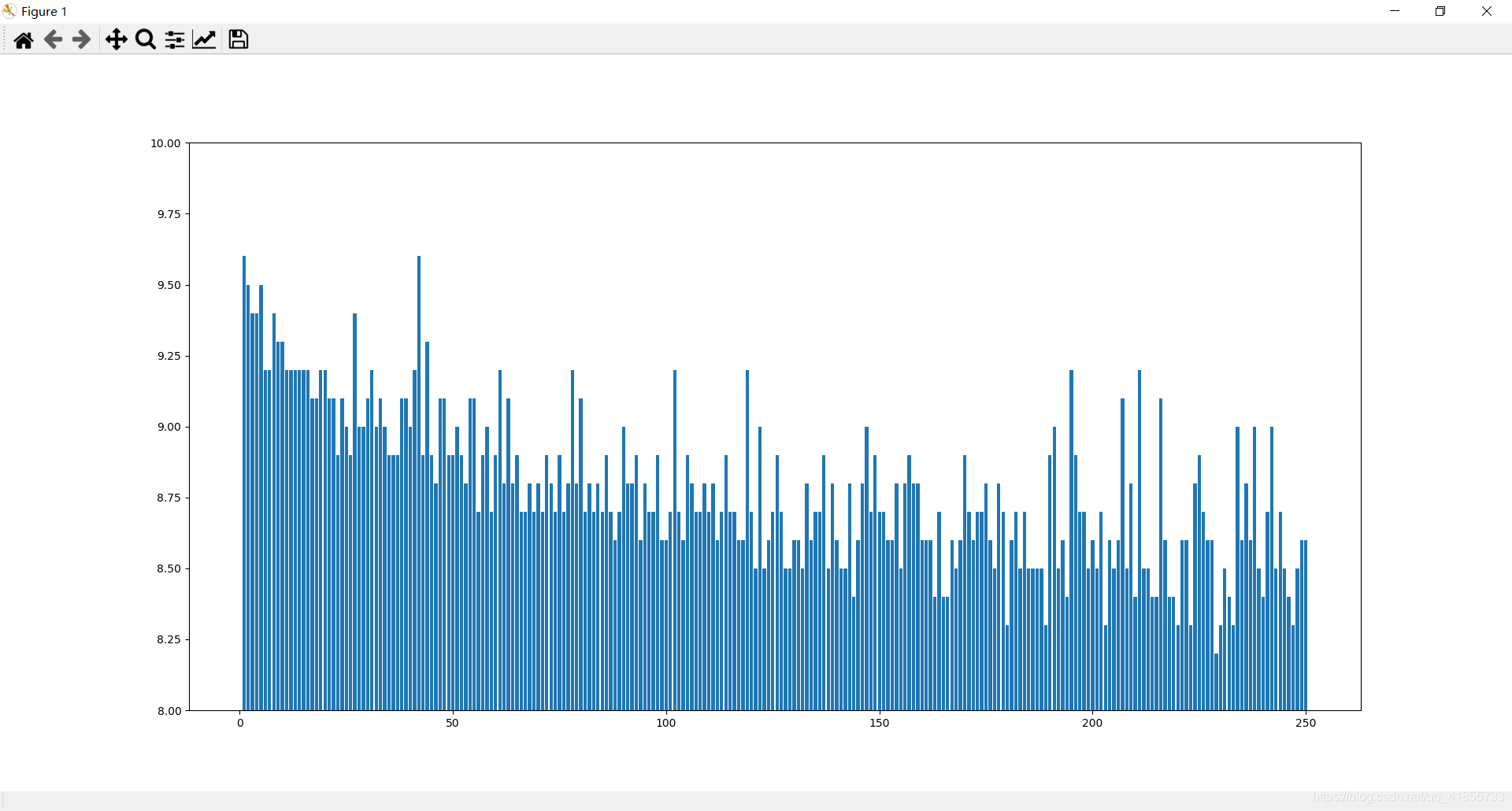
plt.ylim(8,10)
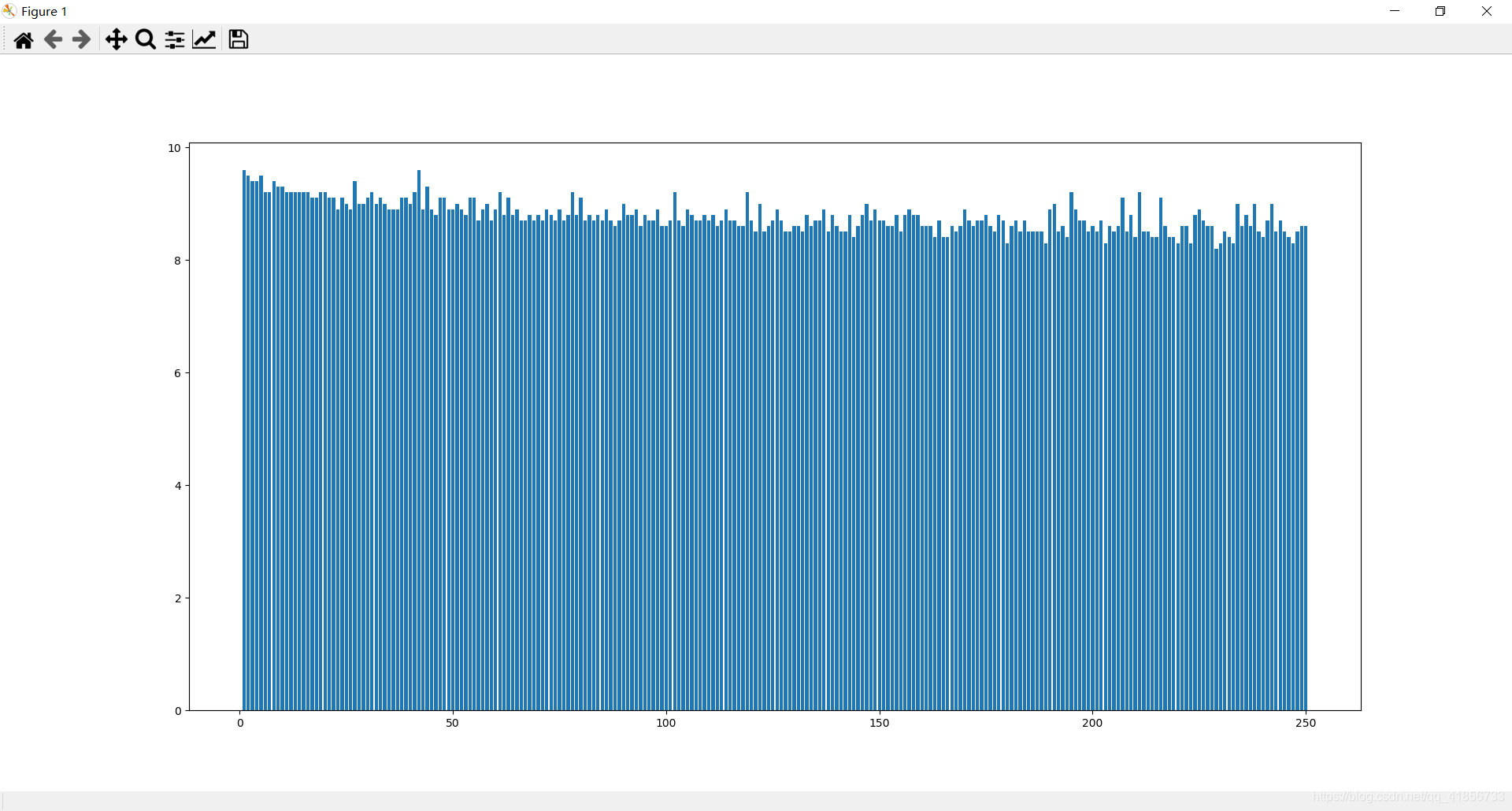
plt.bar(data['num'],data['rating_num'])
plt.bar(data['num'],data['comment_num'],color='pink')
plt.bar(data['num'],data['movie_duration'],color='green')
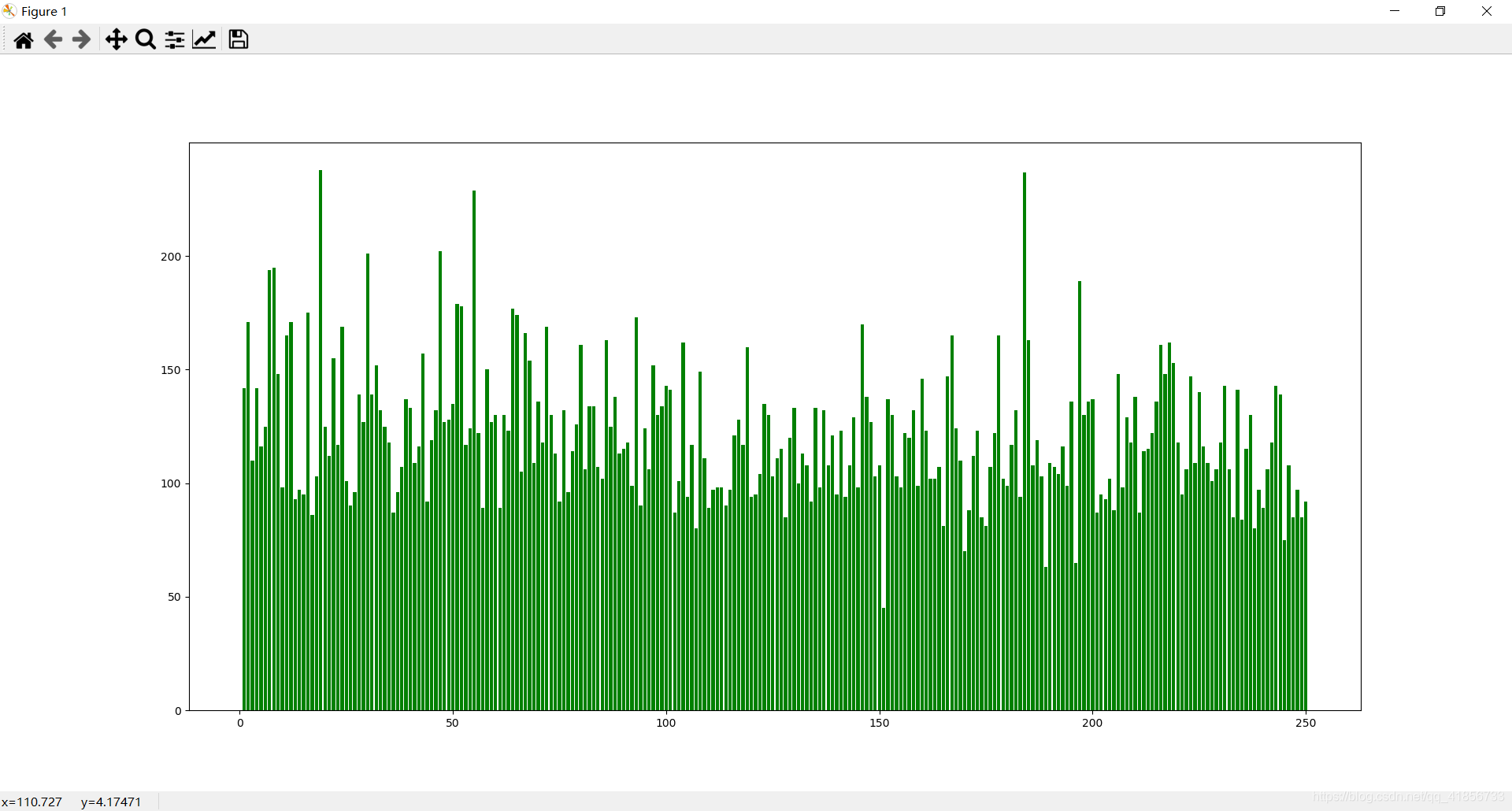
(1)豆瓣排名num和评分rating_num之间条形分布图
直接绘制效果不明显
设置y轴范围后效果不错:
(2)豆瓣排名num和评分人数comment_num之间关系条形图
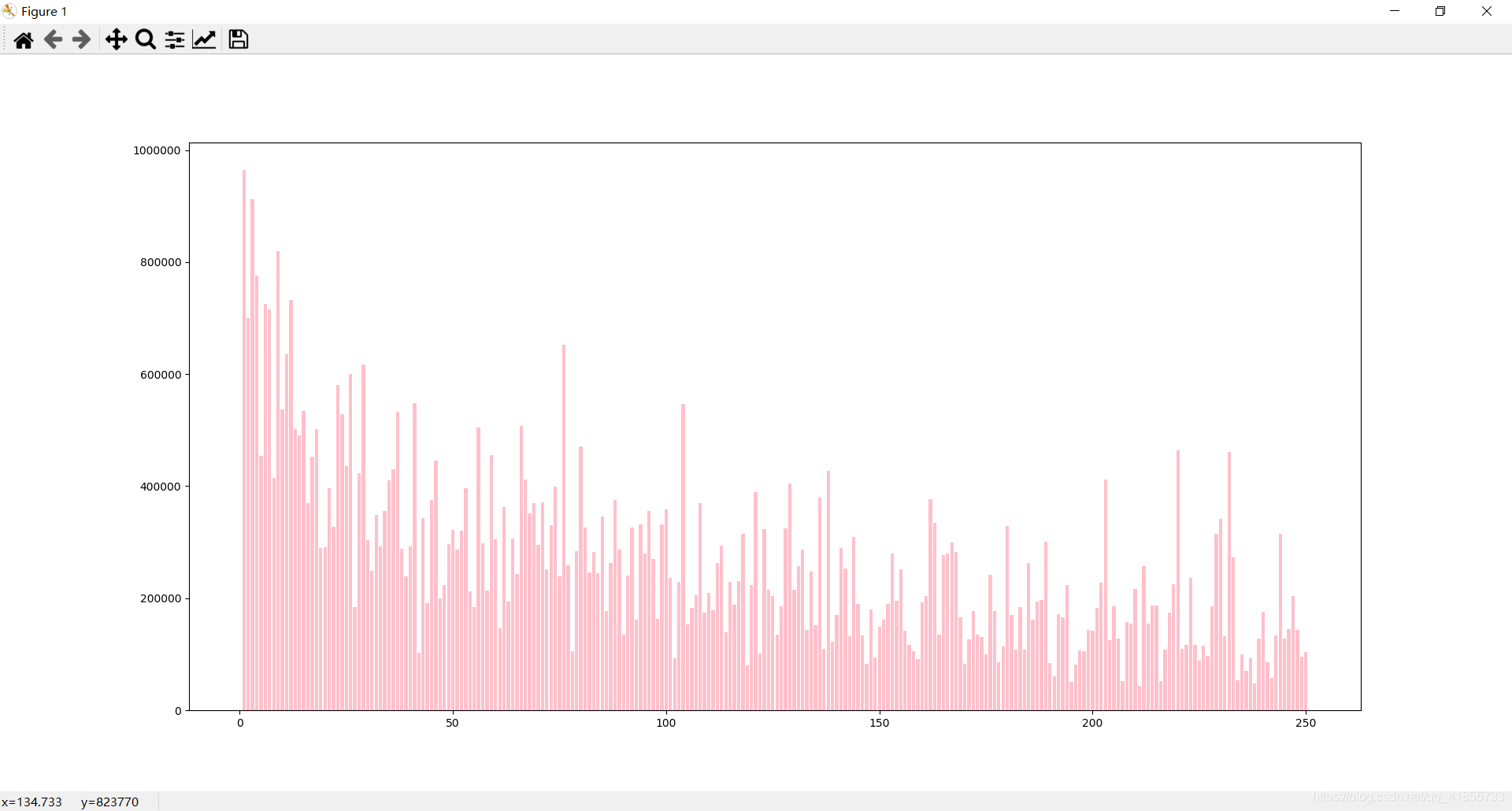
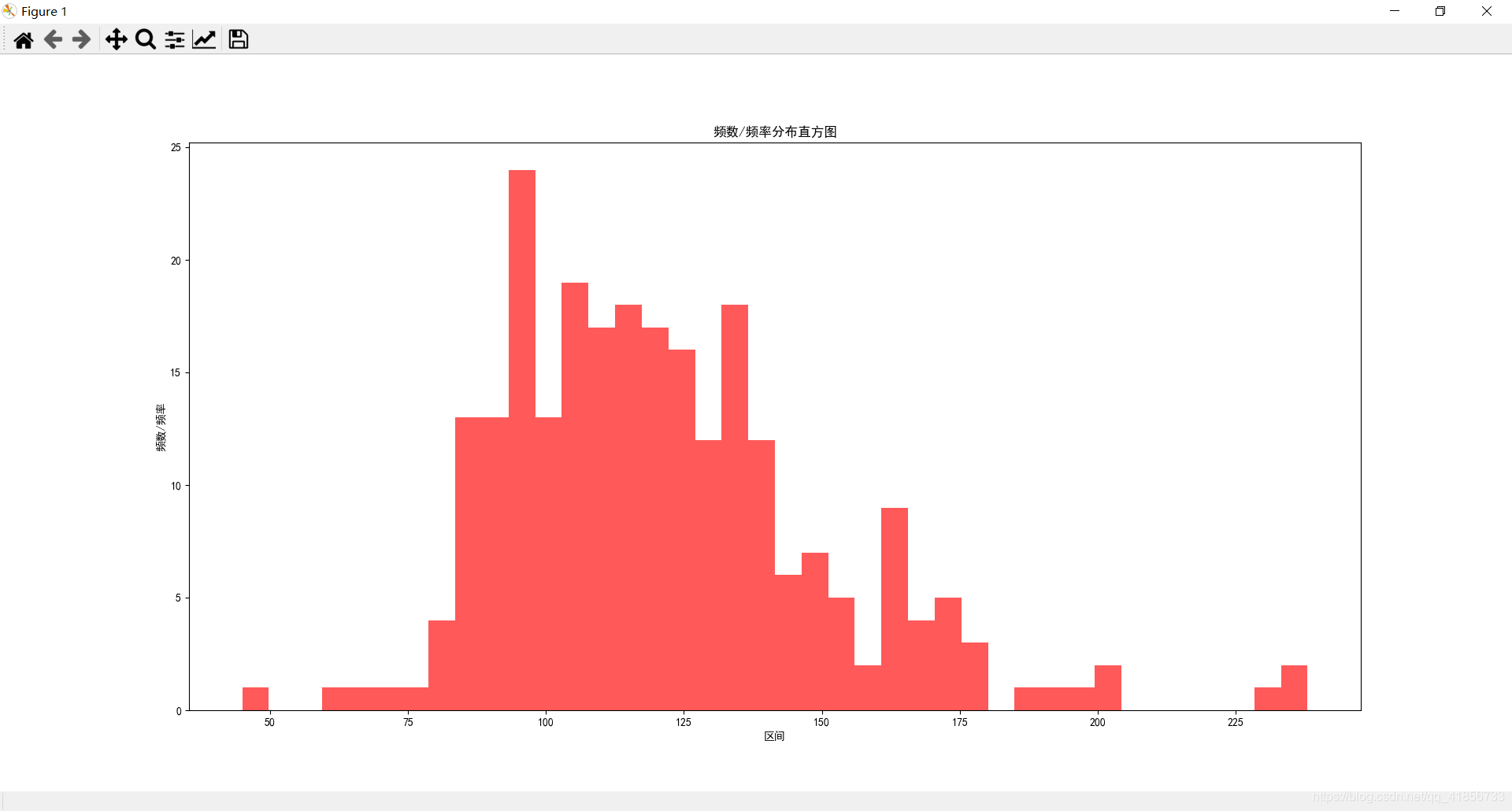
(3)豆瓣排名num和电影时长movie_duration的关系分布直方图
直方图
#直方图(反映数据分布规律,不反映数据之间的关系)
plt.hist(data['rating_num'])
plt.hist(data['comment_num'], bins=100, normed=0, facecolor="blue", edgecolor="black", alpha=0.7)
plt.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文
plt.rcParams['axes.unicode_minus']=False # 正常显示负号
plt.xlabel("区间")
plt.ylabel("频数/频率")
plt.title("频数/频率分布直方图")
plt.hist(data['movie_duration'], 40, histtype='stepfilled', facecolor='r', alpha=0.65)
(1)评分分布规律
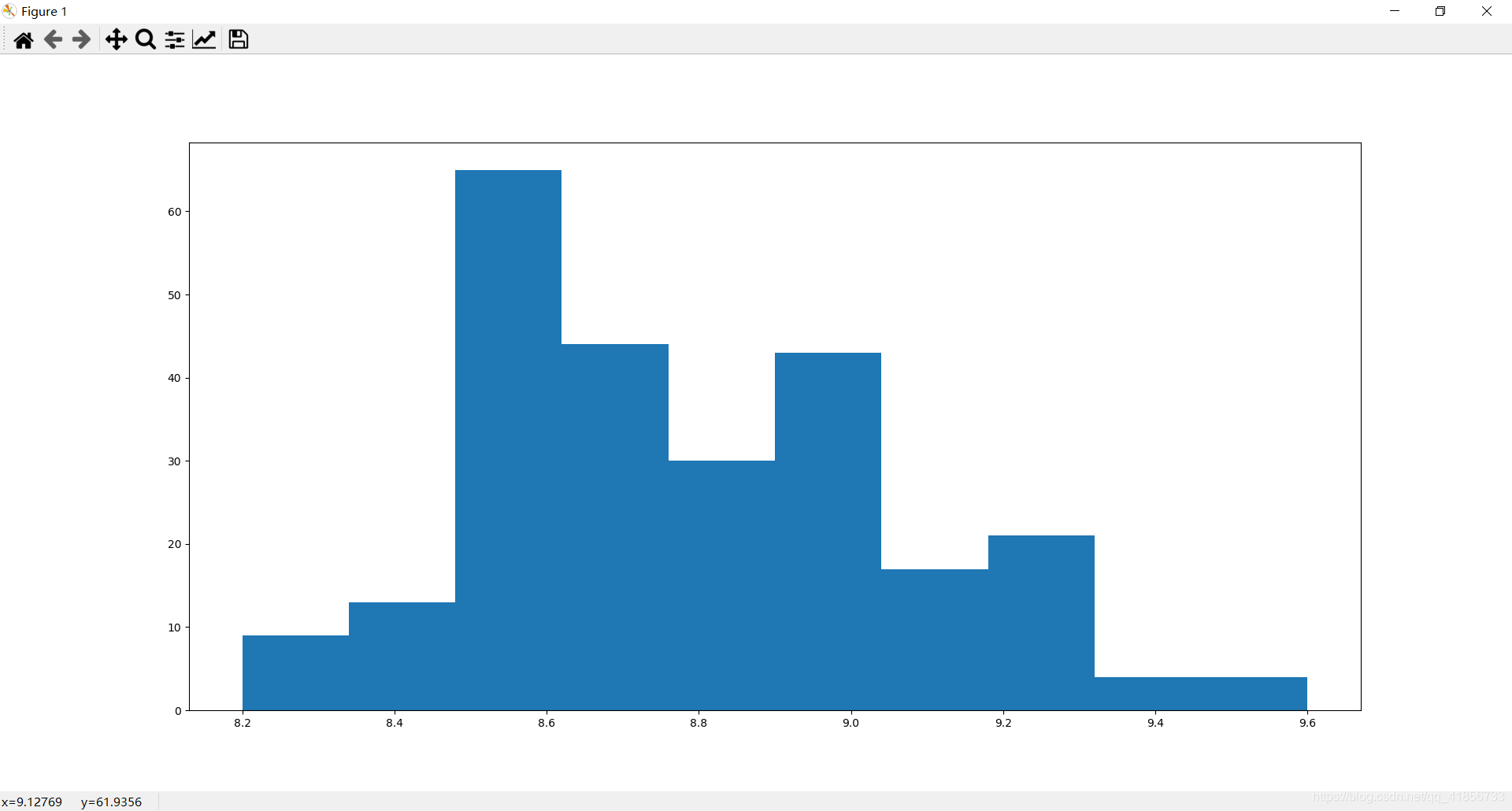
(2)评分数目分布规律直方图
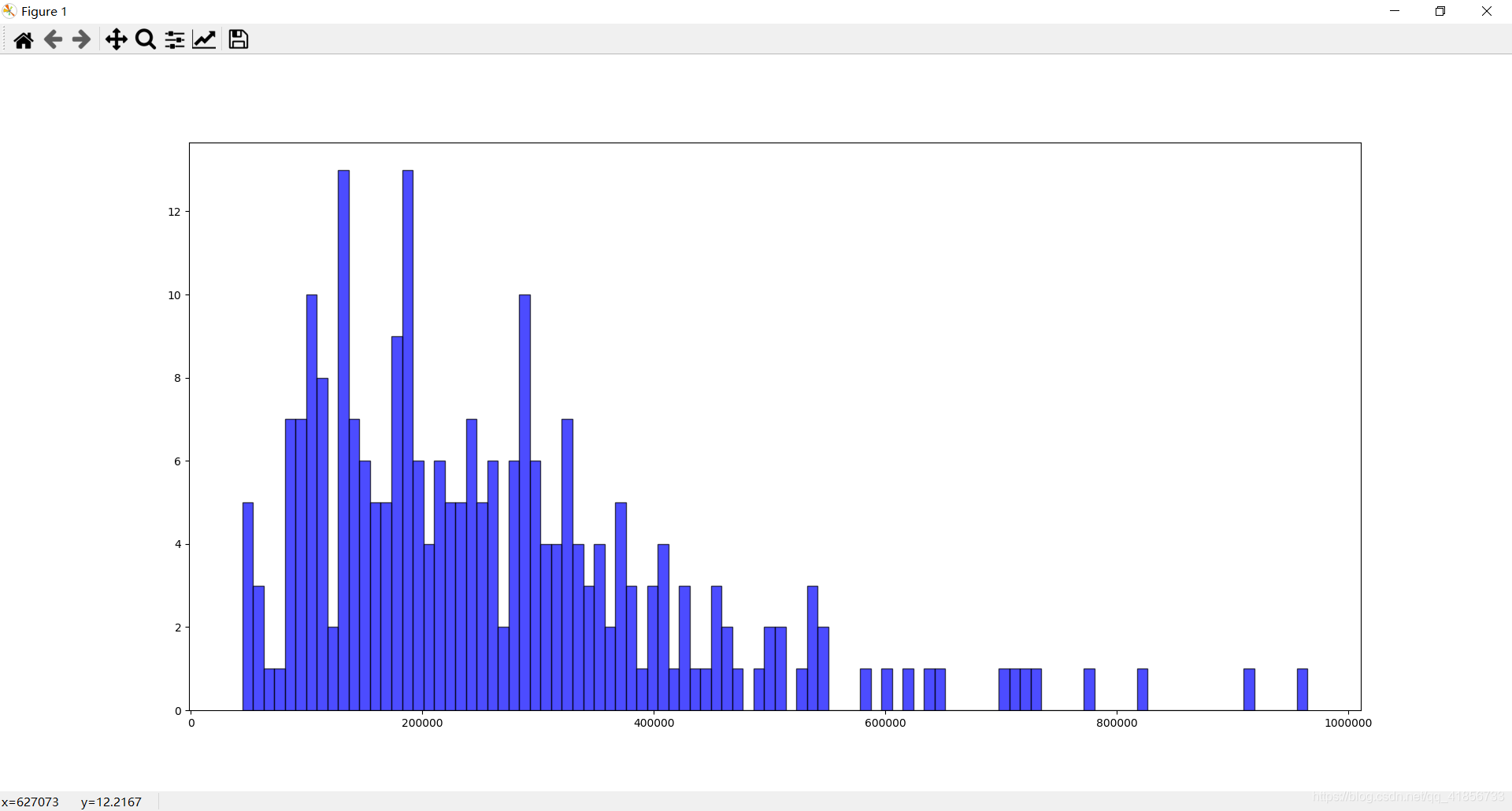
(3)电影时长分布直方图
标准化后对比分析
#4.附加实验:标准化后,对比分析评分、评论人数、时长数据的差异
def MaxMinNormalization(x): #0/1标准化
x = (x - np.min(x)) / (np.max(x) - np.min(x))
return x
d1 = MaxMinNormalization(data['rating_num'])
d2 = MaxMinNormalization(data['comment_num'])
d3 = MaxMinNormalization(data['movie_duration'])
plt.plot(data['num'],d1,'r-',d2,'b-',d3,'g-')
plt.legend(['评分rating_num','评分人数comment_num','电影时长movie_duration'])
、

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









