







本文对应课程中的Lecture11和12, 第一部分是如何对环境模型进行学习,第二部分是在model learning的基础上进行Policy learning。
1. Model Learning
model learning部分的内容逻辑顺序依然是从易到难,从基础版的naive approach出发,每发现其中的一些问题,就将该问题可行的解决方法加入到原先的算法中。
1.1 Naive Approach及其存在的问题
lecture 10是在假设model已知的情况下进行的Planning相关算法,一般情况下model是未知的,该部分就是叙述如何通过learning的方式得到Model。Model一般有两种形式,一种是deterministic情况下的 s t + 1 = f ( s t , a t ) \textbf s_{t+1}=f(\textbf s_t, \textbf a_t) st+1=f(st,at),另一种是stochastic情况下的 p ( s t + 1 ∣ s t , a t ) p(\textbf s_{t+1}|\textbf s_t, \textbf a_t) p(st+1∣st,at)。
参考之前的强化学习一般范式中的三步骤,第一步是智能体与环境交互得到初始数据,第二步如果是Model-based的方法的话,利用初始获取的数据学得环境模型,最直观的方式是在deterministic的情况下将数据中的
s
t
+
1
\text s_{t+1}
st+1作为标签,用一个神经网络模型代替
f
(
s
t
,
a
t
)
f(\textbf s_t, \textbf a_t)
f(st,at),用最小均方差训练该网络。学到该env model之后,就可以上篇文章中的plan的方法产生动作序列(可采用closed-loop, 或open-loop都可以),这种初始版的算法总结如下(版本0.5):

Version 0.5 存在的问题
当算法简单的时候,肯定存在一定的问题。从以上算法流程可以看出,这里收集到的数据只来自于初始策略
π
0
\pi_0
π0,那么当该策略并不是最优策略的时候,那么最后通过model learning并用规划算法输出的动作就有可能不是最优的,另一个问题是通过神经网络学得的model再进行plan所得到的策略
π
f
{\pi_f}
πf与初始用于收集数据的策略
π
0
\pi_0
π0并不一样。以上问题可以用以下公式描述:
p
π
f
(
s
t
)
≠
p
π
0
(
s
t
)
p_{\pi_f}(\textbf s_t)\neq p_{\pi_0}(\textbf s_t)
pπf(st)=pπ0(st)
如果算法中使用的是更为复杂的神经网络模型,那么该问题会被进一步放大。下图是Lecture中举的一个例子:

其实在模仿学习中也会遇到distribution mismatch的问题,它的解决方法就是Dagger,重新向Buffer中加入用
f
(
s
t
,
a
t
)
f(\textbf s_t, \textbf a_t)
f(st,at)规划产生的数据,即该动作或策略与环境交互后产生的
(
s
t
+
1
,
a
t
,
s
t
)
(\textbf s_{t+1}, \textbf a_t, \textbf s_{t})
(st+1,at,st)的数据。

1.2 Naive Approach下的Replan
Version 1.0 存在的问题
该算法中的第三步,即plan through
f
(
s
t
,
a
t
)
f(\textbf s_t, \textbf a_t)
f(st,at)产生的输出也可能出错,导致后续重新加入到buffer中的数据并不好。这时另一个解决办法就是每一次迭代中只执行第三步规划出的动作序列的第一个,之后进行重新规划(Replan),重新规划其实也算是MPC的核心思想之一。

replan的引入其实更利于使用较为简单的controller进行规划。这涉及到了controller复杂度——replan次数的权衡。如果内循环进行的replan次数越多,那么设计controller的时候就可以降低其复杂度。如果controller的复杂度很高,内循环中的replan次数可能并不需要那么多。(这里用horizon表示内循环的次数)
1.3 在Model Learning中考虑Uncertainty
为什么要考虑Uncertainty?(Motivation是什么)
基本上发现问题的过程都源于实验结果,这里也不例外。UCB团队将model-based与model-free的方法做了结合并与纯model-free算法进行了对比,结果如下:棕色线段部分是纯model-based算法进行初始化,后续是model-free阶段的训练。可以看出,纯model-based的方法中,cumulative reward的值已经陷入了局部最优(不再变化,或变化不明显),由于这时候所用到的数据量并不算大,而且本身Model-based的模型表达能力也较强,所以可以推断出是出现了过拟合的现象。

该过拟合现象可以用下图一维的奖赏值曲线来解释,这里的点为真实的奖赏值曲线,蓝色线为在使用Model的情况下得到的Reward值(例如优化目标是
min
r
(
s
0
,
a
0
)
+
∑
t
=
1
T
r
(
f
(
s
t
−
1
,
a
t
−
1
)
,
a
t
)
\min r(\textbf s_{0}, \textbf a_{0})+\sum_{t=1}^Tr(f(\textbf s_{t-1}, \textbf a_{t-1}),\textbf a_t)
minr(s0,a0)+∑t=1Tr(f(st−1,at−1),at)),那么在每次使用模型进行规划的时候,Plan后输出的动作就更倾向于选择图中箭头所指的错误的最优点(真正正确的是选择靠近直线最右端的点)。

其实上述问题本质上还是属于distribution mismatch的问题。正是因为通过model规划出的策略会随着model参数的更新而不断变化,其与初始策略一定存在不一致的问题(至于该差距是否bound这是之后RL theory中会探讨的问题)。正是由于该原因,在算法version 1.5第三步的planning中,可以将max reward换成mean reward,如果考虑了model uncertainty之后得到的mean reward较大,则证明在该模型的预测结果的方差较小。(这是因为一旦考虑了expectation之后,那么肯定是要获取多条数据。如果模型的方差较大,尽管该步后reward可能没有相比于方差小的模型没有太大变化,但Reward累计之后就会变小,所以描述Model Uncertainty是有意义的)
A. 最简单的方法——output entropy
上文是关于为什么要描述Model uncertainty,至于如何对Uncertainty建模,有以下两种比较可行的方法(采用贝叶斯网络或bootstrap ensembles)加上lecture中最先介绍的一种最直观的方法,那就是对模型的输出求熵的操作,因为在信息论中熵是用来不确定性的大小的。
如果状态的取值是离散的,即 s t + 1 = { s 1 , s 2 , … , s K } \textbf s_{t+1}=\{\textbf s_{1},\textbf s_{2},\dots, \textbf s_{K}\} st+1={s1,s2,…,sK},其概率分布为 p ( s t + 1 ) = { p 1 , p 2 , … , p k } p(\textbf s_{t+1})=\{p_1,p_2,\dots, p_{k}\} p(st+1)={p1,p2,…,pk}那么其熵的表达式就是 H ( s ) = E s t + 1 ∼ p ( s t + 1 ) [ log p ( s t + 1 ) ] = ∑ k = 1 K p ( s k ) log p ( s k ) H(\textbf s)=E_{\textbf s_{t+1} \sim p(\textbf s_{t+1})}[\log p(\textbf s_{t+1})]=\sum_{k=1}^Kp(\textbf s_{k})\log p(\textbf s_{k}) H(s)=Est+1∼p(st+1)[logp(st+1)]=∑k=1Kp(sk)logp(sk),连续的情况也类似,把求和变成积分。熵的本质含义就是其值越大,不确定性越大。但只对输出求熵并不能完全反映出整个模型的不确定性,可以用一个直观的例子理解,比如Model的输出是服从均匀分布,真实数据也是均匀分布,由于均匀分布的熵会非常大,按照output entropy的方法我们就认为该模型的不确定性很大,但是该模型很好地模拟了真实数据,是一个好的模型;从另一个角度看,假设真实输出还是均匀分布,但是模型已经过拟合,例如拟合曲线是一个非常高阶的多项式曲线,这时候模型才是高度不确定的。综上,Output的熵并不能完全反映出模型的不确定性。
B. 估计Model Uncertainty的方法
B.1. Uncertainty的分类
其实在机器学习算法过程中,不止有模型的不确定性,还有数据的不确定性。当模型不能准确拟合真实数据的时候,这种不确定性叫做model uncertainty(更正式的术语是epistemic uncertainty);另一种不确定性源于数据,由真实数据和一些噪声组成,这种不确定性叫做statistical uncertainty(更正式的术语是aleatoric uncertainty)。Model Uncertainty用另一种说法可以解释:
The model is certain about the data, but we are not certain about the model.
一般地,在训练神经网络的时候使用的是最大似然的方法, 即 arg max θ log p ( D ∣ θ ) \argmax_{\theta} \log p(D|\theta) θargmaxlogp(D∣θ),而要描述的模型不确定性要用到模型中的参数 θ \theta θ,表达式是 arg max θ log p ( θ ∣ D ) \argmax_{\theta} \log p(\theta|D) θargmaxlogp(θ∣D),一般情况下这两个优化目标可以互换,这可以用Bayes公式解释, p ( D ∣ θ ) = p ( D ) p ( θ ∣ D ) p ( θ ) p(D|\theta)=\frac{p(D)p(\theta|D)}{p(\theta)} p(D∣θ)=p(θ)p(D)p(θ∣D),两边取对数之后就是: log p ( D ∣ θ ) = log p ( D ) p ( θ ∣ D ) p ( θ ) = log p ( D ) + log p ( θ ∣ D ) − log p ( θ ) \log p(D|\theta)=\log \frac{p(D)p(\theta|D)}{p(\theta)}=\log p(D)+\log p(\theta|D)-\log p(\theta) logp(D∣θ)=logp(θ)p(D)p(θ∣D)=logp(D)+logp(θ∣D)−logp(θ),这里 log p ( D ) \log p(D) logp(D)与 θ \theta θ无关,而 p ( θ ) p(\theta) p(θ)是先验,所以带入到优化目标就能得到 arg max θ log p ( D ∣ θ ) = arg max θ log p ( θ ∣ D ) \argmax_{\theta} \log p(D|\theta)=\argmax_{\theta} \log p(\theta|D) θargmaxlogp(D∣θ)=θargmaxlogp(θ∣D),这里与模型不确定性有关的量是 p ( θ ∣ D ) p(\theta|D) p(θ∣D),该量的熵准确描述了模型的不确定性。
B.2. Bayesian Neural Network
贝叶斯网络的原理就是学习神经网络的每个神经元的概率分布,其中对参数的概率分布做了相互独立的假设,所以用公式表示就是
p
(
θ
∣
D
)
=
∏
i
p
(
θ
i
∣
D
)
where
p
(
θ
i
∣
D
)
=
N
(
μ
i
,
σ
i
)
p(\theta|D)=\prod_{i}p(\theta_i|D)\quad \text{where}\ p(\theta_i|D)=N(\mu_i,\sigma_i)
p(θ∣D)=i∏p(θi∣D)where p(θi∣D)=N(μi,σi)

可以看出,如果神经网络中的隐藏层参数非常多,那么贝叶斯网络的计算复杂度非常高。
训练过程及其他详细内容以后用到再来补
B.3.Bootstrap Ensembles

集成学习的方法相较贝叶斯网络来说更好理解。其方法的核心思想就是通过同时训练多个神经网络,并将这些网络的输出进行某种运算得到最终ensemble的输出(例如对每个神经网络的输出求平均),以上思想用数学公式表达就是:(课件中的定义感觉不是很严谨,这里重新改写下)
p
(
θ
∣
D
)
=
1
N
∑
i
δ
(
θ
−
θ
i
)
p(\theta|D)=\frac{1}{N}\sum_{i}\delta({\theta}-\theta_i)
p(θ∣D)=N1i∑δ(θ−θi)
Output:
E
θ
∼
p
(
θ
∣
D
)
[
p
(
s
t
+
1
∣
s
t
,
a
t
)
]
=
∫
θ
p
(
s
t
+
1
∣
s
t
,
a
t
)
p
(
θ
∣
D
)
=
1
N
∫
θ
p
(
s
t
+
1
∣
s
t
,
a
t
,
θ
)
∑
i
δ
(
θ
−
θ
i
)
=
1
N
∑
i
p
(
s
t
+
1
∣
s
t
,
a
t
,
θ
i
)
\text{Output: }E_{\theta \sim p(\theta|D)}[p(\textbf s_{t+1}|\textbf s_{t},\textbf a_{t})]=\int_{\theta}p(\textbf s_{t+1}|\textbf s_{t},\textbf a_{t})p(\theta|D)\\=\frac{1}{N}\int_{\theta}p(\textbf s_{t+1}|\textbf s_{t},\textbf a_{t},\theta)\sum_{i}\delta({\theta}-\theta_i)=\frac{1}{N}\sum_{i}p(\textbf s_{t+1}|\textbf s_{t},\textbf a_{t},\theta_i)
Output: Eθ∼p(θ∣D)[p(st+1∣st,at)]=∫θp(st+1∣st,at)p(θ∣D)=N1∫θp(st+1∣st,at,θ)i∑δ(θ−θi)=N1i∑p(st+1∣st,at,θi)
上述第一个公式是bootstrap ensemble中的参数概率分布表达式,这里的
δ
(
⋅
)
\delta(\cdot)
δ(⋅)代表Dirac Delta Function,只有在
θ
=
θ
i
\theta=\theta_i
θ=θi时,
δ
(
θ
)
=
∞
\delta(\theta)=\infty
δ(θ)=∞,这时候可以得到以下式子:
∫
θ
f
(
θ
)
δ
(
θ
−
θ
i
)
=
f
(
θ
i
)
\int_{\theta}f(\theta)\delta(\theta-\theta_i)=f(\theta_i)
∫θf(θ)δ(θ−θi)=f(θi)。这里的
θ
i
\theta_i
θi代表第
i
i
i个神经网络的参数。上述第二个公式是求模型的输出,即对每个神经网络的输出求平均值即可。
以上是关于ensemble如何构造网络的介绍,接下来是如何进行网络的训练。一般来说,在ensemble下,每个神经网络都需要用独立的数据集来训练,这样才能保证每个网络的输出是独立的。独立数据集的获取可以通过从原始数据集 D D D中有放回地采样得到。但在实际中,不用独立的数据集训练也能得到还不错的结果,因为在网络训练的过程中SGD, 或者是随机初始化这种操作在一定程度上保证了神经网络之间充分独立性。
在Ensemble下进行规划
对于仅使用单个神经网络对env建模的过程中,其目标函数是: J ( a 1 , … , a H ) = ∑ i H r ( s t , a t ) , where s t + 1 = f ( s t , a t ) J(\textbf a_1,\dots,\textbf a_H)=\sum_i^Hr(\textbf s_t, \textbf a_t),\ \text{where }\textbf s_{t+1}=f(\textbf s_t, \textbf a_t) J(a1,…,aH)=∑iHr(st,at), where st+1=f(st,at),在有了ensemble networks之后,该目标函数就会多了一个外圈的求和,即 J ( a 1 , … , a H ) = 1 N ∑ i N ∑ i H r ( s i , t , a t ) , where s t + 1 , i = f i ( s t , i , a t ) J(\textbf a_1,\dots,\textbf a_H)=\frac{1}{N}\sum_i^N\sum_i^Hr(\textbf s_{i,t}, \textbf a_t),\ \text{where }\textbf s_{t+1,i}=f_i(\textbf s_{t,i}, \textbf a_t) J(a1,…,aH)=N1∑iN∑iHr(si,t,at), where st+1,i=fi(st,i,at)
以下是在ensemble下进行规划的算法大致步骤:(流程比较直观,不再解释)

1.4 Latent Model
使用Latent Model的Motivation
其实从上文中可以看出,Model-based的方法都是用于比较简单的场景,例如场景中的状态向量的维度比较小,比如有的比较简单的gym场景中的observation dimensionality也就在10左右。那么假如观测量较为复杂,能否继续使用model-based的方法呢?答案是会遇到以下几个问题。由于观测量这时候(在简单的fully observable场景中, s t = o t \textbf s_t=\textbf o_t st=ot)非常复杂,其维度会陡然增长(例如在训练Atari游戏agent的时候观测量是一张张图片,或者通过相机拍摄的图片控制机械手臂的运动,这类观测量的维度动辄上千);第二个问题是观测量中存在大量冗余(redundancy),比如一张图片中的几个像素点可能同时描述一个事物,有强相关性;第三个问题是任务可能是partially observable的,这时候 s t ≠ o t \textbf s_t\neq\textbf o_t st=ot,所以不能直接使用之前Model-based的方法学到的 f ( s t , a t ) = s t + 1 f(\textbf s_t,\textbf a_t)=\textbf s_{t+1} f(st,at)=st+1。(个人认为基于latent model的方法更适合实际情况)
如何训练Latent Model?
直接的解决办法就是在
s
t
≠
o
t
\textbf s_t\neq\textbf o_t
st=ot的情况下估计以下三种模型:

训练Model的方式与之前的方法略有不同,前文不考虑Latent model的情况且model是随机的情况下基本上是通过最大似然法,即完成以下的优化目标:
max
ϕ
1
N
∑
i
=
1
N
∑
t
=
1
T
log
p
ϕ
(
s
t
+
1
,
i
∣
s
t
,
i
,
a
t
,
i
)
\max_{\phi}\frac{1}{N}\sum_{i=1}^N\sum_{t=1}^T\log p_{\phi}(\textbf s_{t+1,i}|\textbf s_{t,i},\textbf a_{t,i})
ϕmaxN1i=1∑Nt=1∑Tlogpϕ(st+1,i∣st,i,at,i)
这里的下标
i
i
i代表model ensemble中模型的数量(最多使用
N
N
N个模型)。
如果考虑latent space model的话(这里先只考虑observation model),优化目标就变成了:
max
ϕ
1
N
∑
i
=
1
N
∑
t
=
1
T
E
(
s
t
,
s
t
+
1
)
∼
p
(
s
t
,
s
t
+
1
∣
o
1
:
T
,
a
1
:
T
)
[
log
p
ϕ
(
s
t
+
1
,
i
∣
s
t
,
i
,
a
t
,
i
)
+
log
p
ϕ
(
o
t
,
i
∣
s
t
,
i
)
]
\max_{\phi}\frac{1}{N}\sum_{i=1}^N\sum_{t=1}^TE_{(\textbf s_{t},\textbf s_{t+1})\sim p(\textbf s_{t},\textbf s_{t+1}|\textbf o_{1:T},\textbf a_{1:T})}[\log p_{\phi}(\textbf s_{t+1,i}|\textbf s_{t,i},\textbf a_{t,i})+\log p_{\phi}(\textbf o_{t,i}|\textbf s_{t,i})]
ϕmaxN1i=1∑Nt=1∑TE(st,st+1)∼p(st,st+1∣o1:T,a1:T)[logpϕ(st+1,i∣st,i,at,i)+logpϕ(ot,i∣st,i)]
上式多了一个对数项和期望运算,之所以要加上对状态的后验概率求期望的运算是因为这里的状态
(
s
t
,
s
t
+
1
)
(\textbf s_{t},\textbf s_{t+1})
(st,st+1)是未知的,只能通过通过后验概率,通过期望运算中的积分将其积掉。但是准确的后验概率
p
(
s
t
,
s
t
+
1
∣
o
1
:
T
,
a
1
:
T
)
p(\textbf s_{t},\textbf s_{t+1}|\textbf o_{1:T},\textbf a_{1:T})
p(st,st+1∣o1:T,a1:T)是很难精确计算得到的,所以一般情况下要使用变分推断对其估算。一般的方法有两种:full smoothing posterior和single-step encoder,其中的优缺点如下:

课程中主要介绍了第二种方法,并且假设其是确定性的函数(随机情况需要变分推断技巧),即
s
t
=
g
ψ
(
o
t
)
\textbf s_t=g_{\psi}(\textbf o_t)
st=gψ(ot),这里只需要将上文有
s
t
\textbf s_t
st的地方换成
g
ψ
(
o
t
)
g_{\psi}(\textbf o_t)
gψ(ot),并去掉期望符号即可,如下:
max ϕ 1 N ∑ i = 1 N ∑ t = 1 T log p ϕ ( g ψ ( o t + 1 , i ) ∣ g ψ ( o t , i ) , a t , i ) + log p ϕ ( o t , i ∣ g ψ ( o t , i ) ) \max_{\phi}\frac{1}{N}\sum_{i=1}^N\sum_{t=1}^T\log p_{\phi}(g_{\psi}(\textbf o_{t+1,i})|g_{\psi}(\textbf o_{t,i}),\textbf a_{t,i})+\log p_{\phi}(\textbf o_{t,i}|g_{\psi}(\textbf o_{t,i})) ϕmaxN1i=1∑Nt=1∑Tlogpϕ(gψ(ot+1,i)∣gψ(ot,i),at,i)+logpϕ(ot,i∣gψ(ot,i))
如果考虑以上所有三种latent model,优化目标如下:

基于latent model的算法伪代码如下:

整个流程也遵循一开始的RL方法范式,先用基础版策略与环境交互得到数据,将得到的数据存储到buffer中,之后比Model-based的方法多了一步,即学习这些Latent models,之后根据以上所有的Models进行规划操作,再将通过这些动作获取的新的交互数据存到buffer中。
2. Policy Learning
内容逻辑
本文第一部分(课程中的Lecture11)只是对model learning做了阐述,算法中的策略也只是通过plan的方法(Plan的方式基本是open-loop的)得到,而这一部分是进一步复杂化Policy,尝试通过learning的方法或者通过plan+learning的方式计算Policy。所以Lecture 12更关心closed-loop planning(即Policy learning的方法),并且先提出一个有较为直观思路的policy learning的方法和其存在的问题。为了更有效地解决Policy Learning地问题,这里先通过结合Model-free和model-based的方法对策略进行学习(通常用神经网络的方式),之后考虑能否在尽量使用较少数量的神经网络的情况下,转而用一些简单的模型,例如高斯过程来作为策略,或者是用神经网络作为全局策略,与局部策略结合的方式以达到Policy learning的目的。
2.1 Recap: closed-loop与open-loop的区别
lecture 10,11两节课都是关于Planning in open-loop的一些方法,其缺点也是显而易见的。lectrue 12关注closed-loop的方法,思路就是只获取环境的初始状态,利用策略与学到的环境模型不断交互得到每一时刻的动作,这与Open-loop中直接给出所有时刻的动作在思路上有着本质上的区别。

2.2 一种简单的Policy Learning方式
使用Backpropagation
在lectrue 10中Plan的方法基本上都是基于控制器的思想,通过计算直接得到策略,即不涉及策略的学习过程。那么如何用一个简单的方法对策略进行学习呢?由于环境模型给出的下一个状态
s
t
+
1
\textbf s_{t+1}
st+1,策略函数
a
t
=
π
θ
(
s
t
)
\textbf a_t=\pi_{\theta}(\textbf s_t)
at=πθ(st),环境给出的奖赏值
r
(
s
t
,
a
t
)
r(\textbf s_{t}, \textbf a_{t})
r(st,at)构成了一张计算图,所以可以考虑用自动求导包进行反向传播的方法。反向传播的过程和加上backprop的算法如下图:

算法中只有第三步发生了变化,换成了通过学习的方式更新策略网络(或者是策略函数的参数),之前version 1.5是通过Plan的方式(巧妙利用MPC的核心思想)获取actions。
存在的问题
由于强化学习中整个状态转移链是非常长的,所以这里反向传播之后的梯度会逐渐变小。该问题与RNN中的梯度消失和梯度爆炸是类似的,RNN解决该问题的方法是更改网络结构,例如使用LSTM,但强化学习中的状态转移是由环境决定的,整条链的结构是不能被认为改变的(dynamics are chosen by nature)。

以上问题也可以通过把反向传播过程中的梯度表达出来,这里可以看出策略梯度方法与反向传播的区别,策略梯度没有反向传播中的连乘项,连乘项就是造成梯度消失或爆炸的原因,所以策略梯度的方法尽管方差会比较大,但是与backprop相比其稳定性要更好。将backprop梯度项展开可以写成:
∇
J
(
θ
)
=
d
r
1
d
s
1
+
d
r
2
d
s
2
d
s
2
d
a
1
d
a
1
d
s
1
+
…
\nabla J(\theta)=\frac{dr_1}{d \textbf s_1}+\frac{dr_2}{d \textbf s_2}\frac{d \textbf s_2}{d \textbf a_1}\frac{d \textbf a_1}{d \textbf s_1}+\dots
∇J(θ)=ds1dr1+ds2dr2da1ds2ds1da1+…

第二个存在的问题是parameter sensitivity的问题,与planning中的shooting method类似,尽管策略的参数空间上发生的变化比较微小,但由于生成的轨迹很长的情况下,策略空间上的变化会变得非常大。这时候不能使用Planning中的LQR来解决,因为这里的Policy learing的函数表达式是非常复杂非线性的神经网络,用一阶近似的方法会相当不准确(这里更准确地说是用一阶近似只能在局部对该dynamics model做出比较准确的近似,这也是为什么这节课第二部分要介绍Local policy的方法,这里的Local我认为就是说明LQR中对系统函数的一阶近似只适用于局部求解)。
2.3 Dyna & ‘Dyna-Style’ method(Model-free+Model-based方法)
这一部分的方法旨在解决backprop的第一个问题,即引入model-free的相关方法解决梯度爆炸或消失的问题。
Dyna算法
最早的Hybrid方法,即Dyna算法是由sutton在《Integrated architectures for learning, planning, and reacting based on approximating dynamic programming.》这篇文章中提出的。其算法思路结合了Model-free中的Q Learning和model-based中的model learning部分。

算法中的第三步是用一次采样后得到的数据对环境模型
p
(
s
′
∣
s
,
a
)
p(\textbf s'|\textbf s,\textbf a)
p(s′∣s,a)和奖赏模型
r
^
(
s
,
a
)
\hat{r}(\textbf s,\textbf a)
r^(s,a)同时进行更新,第四步,第七步是用期望对Q值进行更新(注意与Q learning中区别,Q learning中的TD difference是没有这个期望运算的),这里就涉及到了环境模型。如果将一个期望展开写,如下:
E
s
′
∼
p
(
s
′
∣
s
,
a
)
,
r
∼
r
^
(
s
,
a
)
[
r
+
max
a
′
Q
(
s
′
,
a
′
)
]
=
∑
r
r
^
(
s
,
a
)
∑
s
′
p
(
s
′
∣
s
,
a
)
(
r
+
max
a
′
Q
(
s
′
,
a
′
)
)
E_{\textbf s' \sim p(\textbf s'|\textbf s,\textbf a),r\sim \hat{r}(\textbf s,\textbf a)}[r+\max_{a'}Q(\textbf s',\textbf a')]=\sum_r \hat{r}(\textbf s,\textbf a)\sum_{s'} p(\textbf s'|\textbf s,\textbf a)(r+\max_{a'}Q(\textbf s',\textbf a'))
Es′∼p(s′∣s,a),r∼r^(s,a)[r+a′maxQ(s′,a′)]=r∑r^(s,a)s′∑p(s′∣s,a)(r+a′maxQ(s′,a′))
General ‘Dyna-Style’ 算法
通用的dyna算法与原版的区别在于原版的dyna算法中Model-free部分用的是Q-learning算法,而通用的算法中model-free方法可以是任意的某一种,策略梯度,基于值的方法均可以。核心思想就是要用学到的环境模型或奖赏值模型去生成一些可以替代原来由环境产生的数据,从而提高算法的采样效率(sample efficiency)。这里重新梳理一下该算法的思路:首先,先用某个初始策略(可以是Model-free方法使用的策略或策略网络)与环境交互得到一批交互数据;之后用这些数据训练环境模型(或者奖赏值模型),得到一个初步的环境模型。再之后进入主循环,从buffer中采样某个状态
s
\textbf s
s,选择某个动作(来自随机策略、策略网络)构成状态-动作对,将其输入到初始学到的env model或reward model得到next state和reward,这里只获取一次rollout,用该数据对model-free方法进行训练。如果可以的话,用更新后的model-free的方法继续收集数据,并对env model进一步训练。

该算法的优势就在于它只要求从Model中获取很少的数据,这里只有较少的 rollout numbers(上图右侧中红橙色圈代表当前状态,红色线段代表rollout)。尽管使用的rollout数量很少,该算法还是能够让智能体经历不一样的状态(即环境模型的输出)。
以下算法(MBA, MVE, MBPO)都是dyna-style的,其过程与general dyna-style的流程略有不同,这里是获取了较多的Model-based Rollouts,如下:

这些算法的优点依然是所使用的rollout数量依然很少,缺点就是所学到的env model不一定是对真实环境精确的描述,所以算法的效能也就取决于模型的准确度了(该问题可以从上图右侧直观看出,本来由model产生的数据应该不断贴近黑线,而这里由于rollout的数量越来越多,导致model偏移量较大)。
(这里的MBPO与我的研究相关,后续继续学习该论文后加上笔记)
2.4 Local Policy + Global Policy方法
这一部分的方法旨在解决backprop的第二个问题,即parameter sensitivity的问题。该部分的思路是先不直接把策略用神经网络参数化,而是巧妙借用planning中的LQR方法获取一个或多个Local policies,之后再用这些Local policies引导global policy的更新,形成一个闭环(当然,这里的env model还是需要通过数据拟合得到)。
Local Policy构建的整体框架及具体方法
这里重新回顾一下Planning中的方法。在Planning中,例如LQR方法中,我们假设系统是线性的,损失函数是二次型。而在针对非线性系统问题的iLQR中,其对系统进行了一阶近似,不断迭代求得最优的动作序列。在求解得到最优动作序列的过程中,只需要对一阶系统或近似出的一阶系统求导即可,该梯度的获取非常容易。而当env model并非已知的时候其梯度是很难获取的,这里需要获取的梯度表达式有: d f d x t , d f d u t \frac{df}{d\textbf x_t},\frac{df}{d\textbf u_t} dxtdf,dutdf。
Local Policy如何构建?
一个非常直接的想法就是用机器学习或深度学习的方法拟合不能直接获取的梯度,从而获取env model,如果上述梯度已知,则env model(这里假设其为deterministic)可以被写成:
f
(
x
t
,
u
t
)
=
d
f
d
x
t
x
t
+
d
f
d
u
t
u
t
+
const
f(\textbf x_t,\textbf u_t) = \frac{df}{d\textbf x_t}\textbf x_t +\frac{df}{d\textbf u_t}\textbf u_t+\text{const}
f(xt,ut)=dxtdfxt+dutdfut+const
这里可以进一步将上述公式写成:
f
(
x
t
,
u
t
)
=
A
t
x
t
+
B
t
u
t
+
const
,
where
A
t
=
d
f
d
x
t
,
B
t
=
d
f
d
u
t
f(\textbf x_t,\textbf u_t) =\textbf A_t \textbf x_t +\textbf B_t \textbf u_t+\text{const}, \ \text{where } \textbf A_t =\frac{df}{d\textbf x_t},\ \textbf B_t=\frac{df}{d\textbf u_t}
f(xt,ut)=Atxt+Btut+const, where At=dxtdf, Bt=dutdf
以上的拟合其实是一种一阶近似的操作,其有效性只在函数的局部区域有保证(直观解释可以参考指数函数在
x
=
0
x=0
x=0处的一次函数近似0),而且这种拟合在每个timestep都需要被执行。这也是为什么说通过该近似产生的env model生成的是Local policy。
用于拟合env model的方法可以是基本的线性回归方法,如果Model被假设成随机的,即其公式为:
p
(
x
t
+
1
∣
x
t
,
u
t
)
=
N
(
A
t
x
t
+
B
t
u
t
+
const
,
Σ
t
)
,
where
A
t
=
d
f
d
x
t
,
B
t
=
d
f
d
u
t
p(\textbf x_{t+1}|\textbf x_t,\textbf u_t) =N(\textbf A_t \textbf x_t +\textbf B_t \textbf u_t+\text{const},\Sigma_t), \ \text{where } \textbf A_t =\frac{df}{d\textbf x_t},\ \textbf B_t=\frac{df}{d\textbf u_t}
p(xt+1∣xt,ut)=N(Atxt+Btut+const,Σt), where At=dxtdf, Bt=dutdf
那么就在用高斯过程,高斯混合模型等先验模型的基础上利用Bayesian linear regression的方法即可。
通过上述拟合出的env model,就可以利用iLQR中的方法输出动作序列了,以下为完整的Local policy的求解流程(这里假设是stochastic model):

上文解决了该流程中的对dynamics的fitting部分,这一步要回答的问题是execute what controller?这里直接借用Lecture10中的ilQR方法中生成的动作序列,即
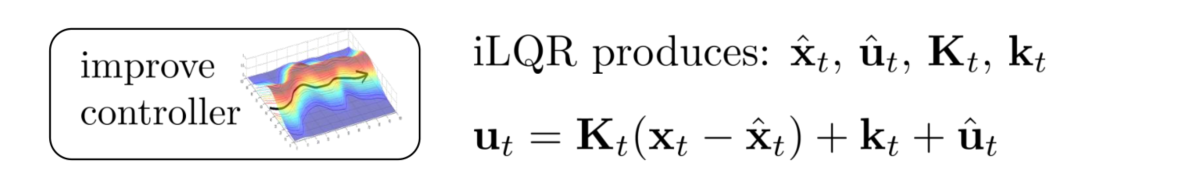
这里
x
^
t
,
u
^
t
\hat{\textbf x}_t,\hat{\textbf u}_t
x^t,u^t是将非线性系统进行一阶近似展开的点,所以这里使用的动作输出有以下三种可能形式(思路是通过不断改进得到最后一个较好的形式)。

version 0.5的缺点是该输出并没有考虑由线性近似而产生的Model inaccuracy的问题,version 1.0的缺点是输出的动作序列是deterministic的,缺少了一些exploration,所以在其之上可以进一步修改,加入一些噪声,将输出的策略改为stochastic的,这里以高斯分布为例,高斯分布的方差的一般经验表达式是
Q
u
t
,
u
t
−
1
\textbf Q^{-1}_{\textbf u_t, \textbf u_t}
Qut,ut−1。
以上方法可以通过下图来直观理解,这里的绿线是真实的env dynmaics model,蓝色线代表对该Model的局部线性近似,蓝色虚线代表基于真实模型得到的策略输出,而红色虚线代表基于该近似模型运行多步之后得到的trajectory,很明显,尽管一开始两者差距不大,但随着时间的推移这两次的轨迹采样差距很大,其原因就在于由local linearization引起的Model inaccuracy。

那么如何修正这个问题呢,也就是通过什么样的方式来更新输出的策略?首先先看在上述得到的policy输出之后整条轨迹的概率表达式:
p
(
τ
)
=
p
(
x
1
)
∏
t
=
1
T
p
(
u
t
∣
x
t
)
p
(
x
t
+
1
∣
x
t
,
u
t
)
where
p
(
u
t
∣
x
t
)
=
N
(
K
t
(
x
t
−
x
^
t
)
+
k
t
+
u
^
t
,
Σ
t
)
p
(
x
t
+
1
∣
x
t
,
u
t
)
=
A
t
x
t
+
B
t
x
t
+
c
t
p(\tau) = p(\textbf x_1)\prod_{t=1}^Tp(\textbf u_t|\textbf x_t)p(\textbf x_{t+1}|\textbf x_t, \textbf u_t)\\ \text{where } p(\textbf u_t|\textbf x_t)=\mathcal{N}(\textbf K_t(\textbf x_t-\hat{\textbf x}_t)+\textbf k_t+\hat{\textbf u}_t,\Sigma_t)\\ p(\textbf x_{t+1}|\textbf x_t, \textbf u_t)=\textbf A_t\textbf x_t+\textbf B_t\textbf x_t+\textbf c_t
p(τ)=p(x1)t=1∏Tp(ut∣xt)p(xt+1∣xt,ut)where p(ut∣xt)=N(Kt(xt−x^t)+kt+u^t,Σt)p(xt+1∣xt,ut)=Atxt+Btxt+ct
为了让新旧Trajectory的分布足够接近,足够接近在数学上的表达就是
D
K
L
(
p
(
τ
)
∣
p
ˉ
(
τ
)
)
≤
ϵ
\text{D}_{KL}(p(\tau)|\bar{p}(\tau))\leq \epsilon
DKL(p(τ)∣pˉ(τ))≤ϵ,所以其中一个方法就是在LQR中的cost function中加上old controller概率分布的对数项,从而让更新后的new controller与之前的controller接近,即避免parameter sensitivity的问题。回忆前面的model-free方法中的Policy gradient存在参数空间和策略空间并不完全等同的情况。
Global+Local Policy的方法
以上只通过local policy输出策略的方法由其应用的局限性,例如目标问题必须是连续可微的状态和动作,而且所使用的控制器只是线性的,表达能力有限,并且其所能够利用的初始状态数量也有限。所以本节Lecture最后一部分就是向local policy中加入global policy,这一大类方法叫做Guided Policy Search(GPS),下图是其算法思路:

这里结合课程详细记录一下对这GPS算法的理解。从上图可以看出该算法由两个阶段组成,第一个阶段是先用不同的初始状态,例如
x
0
,
1
,
x
0
,
2
,
…
,
x
0
,
N
\textbf x_{0,1},\textbf x_{0,2},\dots, \textbf x_{0,N}
x0,1,x0,2,…,x0,N,出发得到的不同轨迹(multiple rollouts),并利用iLQR方法(步骤与上文构建Local policies一致)学得多个local policies,并将该过程中的交互数据进行存储,之后利用这些数据对global policy (使用neural network参数化)进行监督学习的训练(上述为伪代码中的前两步)。由于一个神经网络并不能很好地表达出多个trajectory-centric local policies的输出,例如每个local policy都只是完成从某个具体初始状态点开始的特定任务,可以将local policies看成得到了多个局部最优解,神经网络无法对其进行选择,所以需要将local policy与global policy的交互变成一个闭环。第二个阶段是利用global policy的输出对local policies的训练过程做修改,以便让其接近global policy,具体做法就是在local policy的iLQR阶段中修改其损失函数,加上与global policy的输出相关的一个对数项,其中的拉格朗日乘子可以根据dual gradient descent动态调整(上述为伪代码中的第三步),不断迭代上述两个阶段直到算法收敛。
GPS的思想与 Distillation
可以看出GPS算法的本质思想就是将多个local policies所包含的信息进行某种“压缩”或“提取”,从而得到一个比较好的global policy。该思想与深度学习中的distillation是一致的。一般来说,为了使算法更加鲁棒所使用的一种方法就是同时训练多个神经网络,即network ensemble的方式,但因为ensemble引入了多个神经网络,即参数空间的翻倍导致该方法在测试阶段会非常耗时,所以能否通过某种办法用一个神经网络得到等同于通过network ensemble方式得到的输出呢?该方法就是distillation。其核心思想在于网络训练时采用soft targets,例如在分类问题中使用以下的概率分布作为输出:
p
i
=
exp
(
z
i
/
T
)
∑
j
exp
(
z
j
/
T
)
p_i=\frac{\exp(z_i/T)}{\sum_j\exp(z_j/T)}
pi=∑jexp(zj/T)exp(zi/T)
举一个具体例子,在手写字体识别问题中(假设使用的数据集是MNIST),则一般情况下神经网络的输出是One-hot编码的,例如
[
0
,
1
,
0
,
…
,
0
]
[0,1,0,\dots,0]
[0,1,0,…,0],这里向量中第二项为1就代表将某个数字识别成2。而distillation方法产生的输出向量中每个元素对应
[
0
,
1
]
[0,1]
[0,1]中的某个数,即概率,例如
[
0
,
0.8
,
0
,
…
,
0.2
]
[0,0.8,0,\dots,0.2]
[0,0.8,0,…,0.2],那么该情况下对其输出的解释就是有0.8的概率该数字为2,0.2的概率该数字为9. 这类输出与network ensemble的输出情况是类似的。
这里的distillation的思想也可以用于RL中的multi-task learning问题,如下图:

这里也是先用"local policies"在不同子任务上进行训练,之后通过将加权最大似然函数作为目标函数对global policy network进行训练,这里的权重就是每个任务下所得到的local policy。
有了以上的motivation,可以进一步将GPS算法扩展,其中一个思路是加强其local policies的表达能力,该方法为Divide-and-Conquer Reinforcement learning,目的是让GPS能够用于更加复杂的任务中。这里将原先的LQR方法替换为local neural networks,在不同的初始状态下训练从而得到不同种local policies(这里的本意是将某个要求解的复杂问题分解成多个子问题,每个子问题都对应一个局部最优解),再通过原先GPS框架中的方法训练global policy,之后重新调整Local policies的cost function即可。

参考
- https://zhuanlan.zhihu.com/p/105133985,这篇笔记对于帮助我理解课程中的内容起到了很大作用,感谢!














 1798
1798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









