







| 写在前面: |
这篇文章,值得看的地方有两块,一个是GAT(图注意力网络的应用),第二个是 (Cycle-GAN)的应用 。本文是全文翻译。关于Cycle-GAN的论文见解和阅读SINO的阅读笔记不错,文章3.6部分链接贴出来了。
文章目录
Social-BiGAT
摘要
对于从自动驾驶汽车和社交机器人的控制到安全和监视的许多不同应用,预测场景中多个交互代理的未来轨迹已变得越来越重要。人与人之间存在社会互动以及他们与场景的物理互动使问题更加复杂。现有文献已经探索了其中一些线索,但它们主要忽略了每个人未来轨迹的多峰性质。在本文中,我们介绍了Social-BiGAT,这是一种基于图的生成对抗网络,可以通过对场景中行人的社交互动进行更好的建模来生成逼真的多模态轨迹预测。我们的方法基于图注意力网络(GAT),该图学习网络中可靠的特征表示,这些特征表示对场景中人类之间的社交互动进行编码,而递归编码器-解码器体系结构经过对抗性训练,可以基于特征预测人类的路径。我们在Bicycle-GAN中通过在每个场景与其潜在噪声矢量之间形成可逆变换来明确说明预测问题的多峰性质。我们展示了我们的框架将其与现有轨迹预测基准上的多个基准进行比较,从而实现了最先进的性能。
1 引言
对于各种应用,准确的行人轨迹预测已成为至关重要的组成部分。无人驾驶汽车(例如自动驾驶汽车)和社交机器人技术(例如送货汽车)必须能够理解人的运动,避免发生碰撞[1-4]。用于城市规划的智能跟踪和监视系统必须能够了解人群将如何交互以更好地管理基础设施[5-8]。轨迹预测也变得至关重要,它可以实现下游任务,例如跟踪和重新识别[9]。但是,由于人类行为固有的几个属性,轨迹预测仍然是一项艰巨的任务:
- 社交互动当人们在公共场所活动时,他们经常与其他行人进行社交互动[10]。从采取避免冲突的行动到成群行走,人们在移动时有多种互动方式,需要使用预测方法来模拟社会行为[11,12]。这些社交互动不一定会受到人们的空间接近度的影响。
- 场景背景行人行为不仅取决于周围的人,而且高度取决于周围的人身场景[12-16]。这不仅包括无法避免的固定障碍物(例如建筑物),而且还包括视觉上呈现的不同物理提示,例如人行道或草地,这些可能会导致或限制人类活动。
- 多式联运行为人可能遵循几种合理的轨迹,因为潜在的人类行为分布广泛[10、11、17、18]。例如,当两个行人彼此靠近时,会出现几种行为模式,例如向左移动或向右移动。在每种模式下,变化也很大,允许行人改变其速度等特征。

轨迹预测的先前工作已经解决了之前列出的一些挑战,并为我们的模型设计提供了信息。Helbing等[19]和Pellegriniet等[20]成功地证明了对社交互动进行建模的好处,但需要手工制定的规则,这些规则难以推广到新的场景。Alahi等 [10]利用循环架构来考虑行人行为的多个时间步长,但不考虑场景的物理提示。其他先前的研究也集中于了解物理场景。Lee等。 [15]和Sadeghian等[16]使用原始场景图像和对场景的柔和关注来突出重要提示。他们的工作受到限制,因为他们没有与现场一起考虑社交线索。
相比之下,Gupta等 [11]和Sadeghian等 [12]利用具有社交机制的GAN来考虑现场所有人。但是,这两种模型都无法学习人类行为的真正多模式分布,而是学习具有高方差的单一行为模式。此外,这两种模型都受到他们学习社交行为的方式的限制:尽管前者通过对场景中的所有行人使用相同的社交矢量来丢失信息,但后者需要手动定义的排序操作,该操作在所有情况下均无法达到最佳效果。
为了解决这些工作的局限性,我们提出了Social-BiGAT,这是一种基于GAN [21]的方法,用于构建可以学习这些基本的多峰轨迹分布的生成模型。这项工作的主要贡献如下。首先,我们通过引入灵活的图注意力网络[22]来改善场景中行人之间的社交互动的建模,该网络允许场景中的所有行人进行交互。这比以前的工作有所改进,在以前的工作中,交互作用受到局部限制,或者使用手工定义的规则对交互作用进行建模。接下来,我们通过构建输出轨迹和表示场景中行人行为的潜势之间的可逆映射来鼓励多模分布的泛化,如之前Zhu等人对图像所做的那样 [23]。这使我们能够生成在社会上和身体上都可以接受的轨迹,同时还可以学习更大的多峰轨迹分布,尽管只能从跨场景的单一行为模式访问单个样本。最后,我们结合[12,16]中使用Soft-Attention具通用性。
2 相关工作
近年来,由于自动驾驶系统和社交机器人的发展越来越受到人们的欢迎,轨迹预测问题已受到社区许多研究人员的极大关注。现有的大多数作品都集中在将场景的物理特征整合到人类空间模型中[15,16],以及学习如何在人类模型中对行人之间的社会行为进行建模[10,24]。其他工作从生成的角度[11]解决了这个问题,并在一个框架中联合建模了这些特征[12]。尽管这些工作大大提高了领域,但它们有一些缺点,我们可以通过合并图注意力网络[22]和图像翻译网络[23]解决。
传统上轨迹预测,行人轨迹预测已通过定义捕获人的运动但无法正确概括的手工规则和能量参数来解决[19,20,24–26]。现代方法不是手工制作这些功能,而是依赖循环神经网络,这些神经网络直接从数据中学习这些参数[10、16],同时结合了一些捕获人类交互特征的方法[15、27、28]。这些现有方法中的几种已经受到范围的限制,因为它们通常将交互作用限制在附近的行人邻居[10、29、30],并且不对全局交互作用建模或无法概括为可变数量的人类。其他方法已经从生成的角度探讨了轨迹预测,包括Lee等[15],古普塔等 [11],和Sadeghian [12],有自己的局限性。前者仅考虑在有限的局部范围内的相互作用,而后两者导致具有高方差的模型。具体来说,尽管人类运动本质上是多峰的,但是这些方法不能表达性地学习这种多峰行为,而是学习具有高方差的一种模式。在我们的工作中,我们结合了从图像到图像转换的想法,以生成多峰行人轨迹。此外,我们的模型使用图注意力网络[22]来更有效,更健壮地模拟场景中智能体之间的交互,而先前的研究[12,31]取决于手工定义的规则。
Velickovi等人提出的图注意力网络[22],图注意力网络(GAT)允许在可以表示为图的任何类型的结构化数据上应用基于自我注意的架构。这些网络基于图卷积网络(GCN)[32]的先验而构建,它还允许模型隐式地为图中的节点分配不同的重要性。在我们的案例中,我们可以将行人互动表达为图形,其中节点是指人类,而边缘就是这些互动;较高的边缘权重对应于更重要的交互。通过使图完全连接,我们可以以高效的方式对人类之间的局部和全局交互进行建模,而无需执行可能丢失重要特征的系统,如合并[11]或排序[12]。
图像翻译在过去几年中,图像域翻译领域经历了几项重大的进步。pix2pix框架[33]是第一个进步,该框架支持翻译,但由于需要成对的训练示例而受到限制。朱等。通过CycleGAN [34]改进了该模型,该模型能够通过循环一致性损失从每个域中获取未配对示例的这些域映射。较新的研究集中在学习输出的多模态:InfoGAN [35]致力于最大化变分互信息,而BicycleGAN [23]引入了潜在的噪声编码器,并学习了噪声和输出之间的双射。在我们的模型中,我们借鉴了BicycleGAN提出的改进,提出了一种潜在的空间编码器,该编码器可以生成多模式行人轨迹。
3 Social-BiGAT
3.1 问题定义
正式定义的人类轨迹预测是预测行人未来的导航运动(即他们在2D地图表示中的x和y坐标)的问题,考虑到行人的先前运动和有关场景的其他上下文信息。 我们假设每个行人所走的路线都受到其他人的位置以及行进路线上的物理约束以及行进目标的影响,行进目标在某种程度上被其过去的运动轨迹所编码。 对于任何特定场景,我们模型的输入都是双重的:
1)场景信息,以场景的上下或侧面图像的形式 ,以及
2)每个场景中先前观察到的轨迹N个当前可见的行人, 代表 。
给定以上所有输入以及在obs和pred时间步之间每个行人的地面真实未来轨迹,即 的 ,我们的目标是学习潜在的(可能是多峰的)分布,这些分布可以为他们的未来轨迹生成可行的样本。
3.2 整体模型
我们的总体模型由四个主要网络组成,每个主要网络都由三个关键模块组成(图2)。具体来说,我们构造一个生成器,两种形式的鉴别器(一种以局部行人规模运行,另一种以全局场景级别规模运行)和一个潜在空间编码器。我们的生成器由功能编码器模块(第3.3节),关注网络模块(第3.4节)和解码器模块(第3.5节)组成。特征编码器模块从原始特征中提取编码,以用于注意力网络,从而反过来了解哪些特征在生成中最重要。然后将这些加权特征传递到解码器模块,该模块使用LSTM生成轨迹的多个时间步长。按照Isola等人的动机,对两种体系进行了对抗性训练[33]并鼓励现实的局部和全局轨迹,我们还训练了一个潜在的场景编码器,该编码器学会生成最能共同代表场景的噪声的均值和方差,如Zhu等人所述 [23]鼓励多式联运。

3.3 Feature Encoder
特征编码器具有两个主要组件:社交行人编码器(用于学习观察到的行人轨迹的表示),以及物理场景编码器(用于学习场景特征的表示)。对于社交编码器,对于每个行人,我们首先使用多层感知器(MLP)将行人的相对位移嵌入到一个更高的维度,然后使用LSTM将这些跨时间步长的行人运动编码为单个嵌入,从而为行人i编码 。对于物理特征编码器,我们只需通过卷积神经网络(CNN)传递场景的自上而下的图像视图,就得到了场景的特征图:
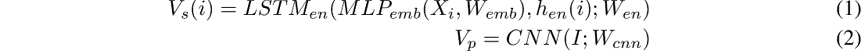
3.4 Attention Network
就像人类如何直观地知道要避免碰撞的其他行人一样,我们希望我们的模型更好地理解交互的相对权重:我们通过对提取的特征进行关注来实现此目标。
身体注意力为了关注与特定行人有关的身体特征,我们引入Vs(i)并施加软注意力,其中网络由Wp参数化并输出上下文向量C:
C
p
(
i
)
=
A
T
T
p
(
V
p
,
V
s
(
i
)
;
W
p
)
(
3
)
Cp(i) = ATTp(Vp, Vs(i); Wp) (3)
Cp(i)=ATTp(Vp,Vs(i);Wp)(3)
社会注意力与身体注意力类似,我们将行人嵌入Vs(i)用作社会注意力模型的输入。社会注意力模型将行人编码为与之交互的邻居行人的加权(趋于)总和。先前的研究要么使用置换不变对称函数,例如max或average (我们模型用到的池化层),要么使用排序函数,例如基于欧氏距离的排序 (我们模型用到的社会力建模) 。在前者中,不利之处在于,每个行人都将获得相同的联合特征表示,从而放弃了某些独特性。尽管后一种技术没有此缺点,但确实需要设置最大的行人数量,并且确实在模型上施加了人为偏差,不一定总是正确的。即,假定欧几里得距离排序是理解社交互动的关键组成部分。
为了避免这些缺陷,我们利用图注意力网络[22,36]。给定行人i的嵌入
V
s
(
i
)
Vs(i)
Vs(i),我们对场景中的所有行人都应用了几个堆叠的图形注意层。每层ℓ的应用方式如下,其中
W
g
a
t
Wgat
Wgat参数化共享的线性变换,而a是共享的关注机制:
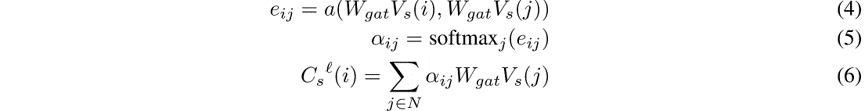
我们使用最后一个GAT层中的特征
C
s
(
i
)
Cs(i)
Cs(i),其中
L
L
L作为最终的社会特征。我们允许行人图形保持完全连接,并且不使用任何遮罩。这允许每个行人彼此交互,并且不对行人命令施加任何限制。
3.5 GAN Network
在本节中,我们将介绍我们的特征编码器和注意力网络如何在开发基于LSTM的生成对抗网络(GAN)时作为核心构建块。GAN通常由相互竞争的两个网络组成:一个生成器和一个鉴别器。在生成器学习从输入数据生成现实样本的同时,鉴别器学习识别哪些样本是真实的以及生成了哪些样本,从而参与了两个玩家的最小-最大游戏.
生成器
生成器使用解码器LSTM构建。类似于条件GAN [37],我们的生成器以从多元正态分布中采样的噪声矢量z作为输入,并以物理场景上下文Cp(i),行人场景上下文和先前的行人编码Vs(i)为条件。这些都串联在一起,这 。然后,通过解码器LSTM执行跨多个时间步长的轨迹的生成,从而:
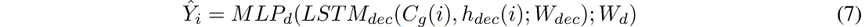
鉴别器
鉴别器体系结构反映了生成器的体系结构,其中编码器LSTM用于表示行人,而CNN用于表示场景特征。我们提出了此核心鉴别器体系结构的两种版本:一种在本地范围内运行,用于行人,另一种在全局范围内运行,用于整个场景。前者直接对串联的过去和将来轨迹的编码执行分类,例如:
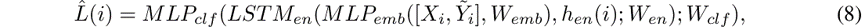
其中 是从地面真实情况或预测路径中随机选择的未来轨迹样本。 是分类分数,代表样本分别是带有真实标签1和0的地面真实(真实)或预测(伪造)。
全局判别器执行相同的分类操作,但基于行人轨迹的全局上下文向量。即,物理场景上下文 ,行人场景上下文 和行人编码 的串联。
3.6 Latent Encoder(该部分的描述,SINO的阅读笔记,讲的很清楚)
为了生成真正的多峰轨迹,我们鼓励我们的模型在输出的轨迹和输入到生成器的潜在空间之间建立双射。具体来说,我们既要将潜在噪声映射到输出轨迹,又要把该轨迹映射回到原始形势。虽然前者的任务是由发生器完成的,但我们使用潜场景编码器来完成后者,就像之前在Zhu等人中所做的那样[23]

潜在场景编码器的体系结构与本地鉴别器相对类似。首先,使用LSTM编码器在场景中对行人进行编码。该LSTM的嵌入在两个并行的MLP中传递,这些MLP被训练为每个行人输出均值 和对数方差 :
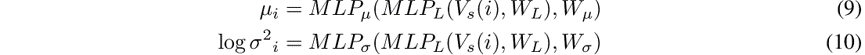
3.7 Losses
我们最终使用被选为超参数的λ权重组合所有这些损耗项:
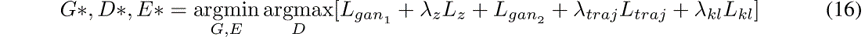
如图3所示,要训练这四个模型,我们有一个多步训练过程,我们不仅要从噪声 开始执行转换,还要从轨迹 开始执行转换。在前一种情况中,我们要考虑两个主要的损耗项:发电机使鉴别器欺骗的GAN损耗(Lgan1)和鉴别器正确分类了发电机,以及重建噪声的损耗项(Lgan2)。我们将这些计算如下,其中G表示生成器,D表示鉴别器,E表示潜在编码器:
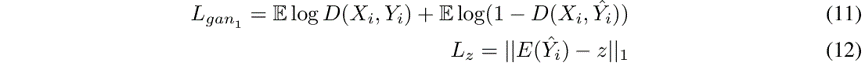
在后者中,我们有三个附加的损耗项:GAN损耗,轨迹的L2损耗,强制生成实际样本,以及生成的噪声的KL损耗,使其类似于绘制的噪声来自随机高斯分布:
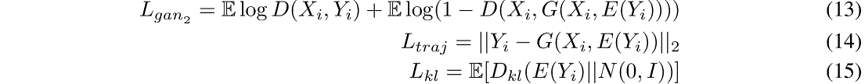
4 Experiments
5 Conclusion
我们介绍了Social-BiGAT,这是一种用于预测行人运动的新颖体系结构,其在多个广泛使用的轨迹基准中的性能优于先前的最新方法。与先前的研究不同,我们的模型不仅能够为给定的行人生成多个轨迹,而且还能够以多模式方式为多个人生成轨迹。通过我们的评估和可视化,我们证明,Social-BiGAT能够捕获行人运动的复杂社会本质,并且我们能够通过在测试时调整潜能来控制预测。我们进一步对轨迹生成过程进行了一些重要的体系结构改进:**1)我们利用社交注意图网络(GAT)通过数据更好地学习行人互动,以及2)我们使用在本地和全球范围内运行的两个鉴别器进行训练。**如实验所示,通过这些设计模式,我们的Social-BiGAT模型能够生成预测人类运动更真实的行人轨迹。















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









