







 YOLO(You Only Look Once)是一种实时目标检测系统,它将目标检测视为回归问题,通过单一神经网络同时预测边界框坐标、置信度和类别概率。YOLOv1速度快且简洁,但在定位精度和处理小物体上存在挑战。相比于其他检测系统,如R-CNN系列,YOLOv1能以更高的速度运行,但mAP(平均精度)略低。YOLOv1通过网络设计、训练策略和损失函数优化来提高检测性能,但仍然存在定位错误和小物体检测问题。
YOLO(You Only Look Once)是一种实时目标检测系统,它将目标检测视为回归问题,通过单一神经网络同时预测边界框坐标、置信度和类别概率。YOLOv1速度快且简洁,但在定位精度和处理小物体上存在挑战。相比于其他检测系统,如R-CNN系列,YOLOv1能以更高的速度运行,但mAP(平均精度)略低。YOLOv1通过网络设计、训练策略和损失函数优化来提高检测性能,但仍然存在定位错误和小物体检测问题。
最近新出了YOLOV4,我系统的从V1开始整理出稿,传送门:
【YOLOv1原文+翻译】You Only Look Once Unified, Real-Time Object Detection
【YOLOv2原文+翻译】YOLO9000: Better, Faster, Stronger
【YOLOv3原文+翻译】YOLOv3:An Incremental Improvement
【YOLOv4原文+翻译】YOLOv4:Optimal Speed and Accuracy of Object Detection
You Only Look Once Unified, Real-Time Object Detection是CVPR2016的论文
首先上传原文:百度云盘
提取码:
bvsq
因为大多数博主所给的都是外链,对于没有梯子的同学来说打开非常痛苦,我直接上传PDF啦
正文开始
Abstract摘要
我们提出YOLO9000,一个最先进的,实时目标检测系统,可以检测超过9000个目标类别。首先,我们提出对YOLO检测方法的各种改进方法,包括新颖的和从以前的工作中得出的。改进的模型YOLOv2在如PASCAL VOC和COCO标准检测任务是最先进的。使用一种新颖的多尺度训练方法,相同的YOLOv2模型可以运行在不同的大小的图片上,提供速度和精度之间的轻松权衡。在67 FPS时,YOLOv2在VOC 2007上获得76.8 mAP。在40 FPS时,YOLOv2获得78.6 mAP,性能优于最先进的方法,例如使用ResNet的faster R-CNN和SSD,同时运行速度明显更快。最后,我们提出了一种联合训练目标检测和分类的方法。使用这种方法,我们在COCO检测数据集和ImageNet分类数据集上同时训练YOLO9000。我们的联合训练方法允许YOLO9000预测没有标记检测数据的目标类的检测。我们在ImageNet检测数据集上验证我们的方法。YOLO9000在ImageNet检测验证集上获得19.7 mAP,尽管只有200个类中的44类检测数据。在不在COCO的156类中,YOLO9000获得16.0 mAP。但是YOLO可以检测超过200个类;它预测超过9000个不同目标类别的检测。它仍然实时运行。
我提出了YOLO:一种新的物体检测方法。YOLO之前的物体检测方法主要是通过region proposal产生大量的可能包含待检测物体的 potential bounding box,再用分类器去判断每个 bounding box里是否包含有物体,以及物体所属类别的 probability或者 confidence,如R-CNN,Fast-R-CNN,Faster-R-CNN等。YOLO不同于这些物体检测方法,它将物体检测任务当做一个regression(回归)问题来处理。YOLO从输入的图像,仅使用一个神经网络,直接从一整张图像来预测出bounding box 的坐标、box中包含物体的置信度和物体的probabilities(概率)。因为YOLO的物体检测流程是在一个神经网络里完成的,所以可以end to end(端对端:指的是输入原始数据,输出的是最后结果,应用在特征学习融入算法,无需单独处理)来优化物体检测性能。
YOLO检测物体的速度很快,标准版本的YOLO在Titan X 的 GPU 上能达到45 FPS。网络较小的版本Fast YOLO在保持mAP是之前的其他实时物体检测器的两倍的同时,检测速度可以达到155 FPS。相较于其他的state-of-the-art 物体检测系统,YOLO在物体定位时更容易出错,但是在背景上预测出不存在的物体(false positives)的情况会少一些。而且,YOLO比DPM、R-CNN等物体检测系统能够学到更加抽象的物体的特征,这使得YOLO可以从真实图像领域迁移到其他领域,如艺术。
1.Introduction(介绍)
人们瞥视图像,立即知道图像中的物体,它们在哪里以及它们如何相互作用。 人类的视觉系统是快速和准确的,使我们能够执行复杂的任务,例如驾驶时几乎没有意识的想法。 快速,准确的目标检测算法可以让计算机在没有专门传感器的情况下驾驶汽车,使辅助设备能够向人类用户传达实时的场景信息,并释放通用目标响应式机器人系统的潜力。
当前的物体检测系统使用分类器来完成物体检测任务。为了检测一个物体,这些物体检测系统要在一张测试图的不同位置和不同尺寸的bounding box上使用该物体的分类器去评估是否有该物体。如DPM系统,要使用一个滑窗(sliding window)在整张图像上均匀滑动,用分类器评估是否有物体。
在DPM之后提出的其他方法,如R-CNN方法使用region proposal来生成整张图像中可能包含待检测物体的potential bounding boxes,然后用分类器来评估这些boxes,接着通过post-processing来改善bounding boxes,消除重复的检测目标,并基于整个场景中的其他物体重新对boxes进行打分。整个流程执行下来很慢,而且因为这些环节都是分开训练的,检测性能很难进行优化。
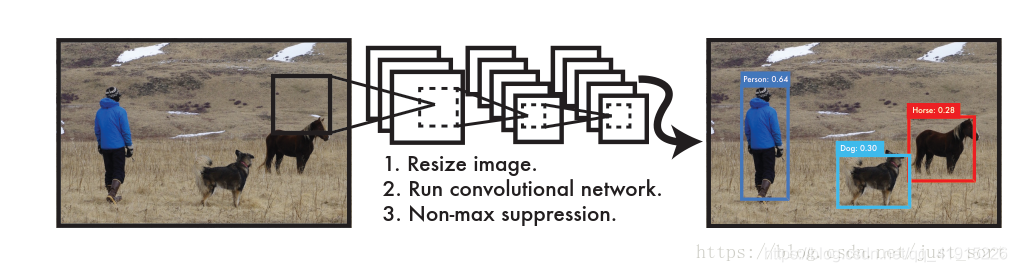
图1:YOLO检测系统。 用YOLO处理图像简单而直接。
我们的系统(1)将输入图像的大小调整为448×448,(2)在图像上运行单个卷积网络,(3)通过模型的置信度对结果检测进行阈值。
本文提出的YOLO(you only look once),将物体检测任务当做回归问题(regression problem)来处理,直接通过整张图片的所有像素得到bounding box的坐标、box中包含物体的置信度和class probabilities。通过YOLO,每张图像只需要输入到神经网络就能得出图像中都有哪些物体和这些物体的位置。
YOLO非常简单:参见图1.单个卷积网络可同时预测多个边界框和这些框的类概率,YOLO训练全图像并直接优化检测性能。 这种统一的模型与传统的物体检测方法相比有许多优点。
YOLO模型相对于之前的物体检测方法有多个优点:
1、YOLO检测物体非常快。
因为没有复杂的检测流程,只需要将图像输入到神经网络就可以得到检测结果,YOLO可以非常快的完成物体检测任务。标准版本的YOLO在Titan X 的 GPU 上能达到45 FPS。更快的Fast YOLO检测速度可以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









