







论文基本信息
期刊: 厦门大学学报(自然科学版) 、北大核心
IF = 0.77
出版时间:2022年3月
摘要
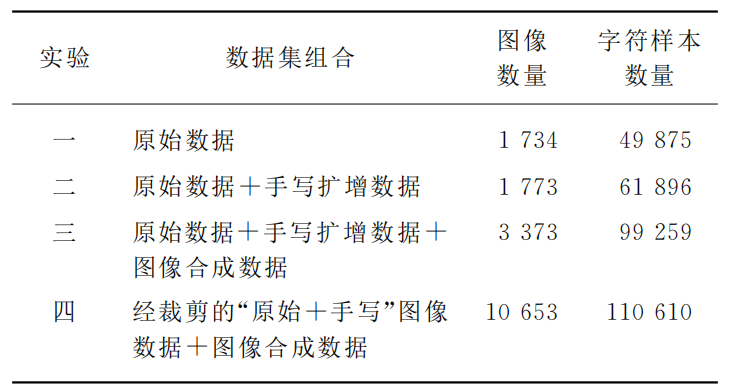
Step1: 通过多种数据扩增方式(如:人工书写、图像合成、图像裁剪)获得了80个文字别类,共110610个带标签的字符样本;
Step2: 将Faster-RCNN算法应用到水书古籍文字识别中,以上面的样本以不同组合的数据集作为输入进行实验,在全部80个目标类别上获得了91.95%的平均识别率。
引言
介绍了很多目前的水书识别方法,本文主要记录了以下几个自己可能会用到的文献:
| 方法 |
|---|
| 1. 杨秀璋等提出了一种改进的图像增强及图 像 识 别 方 法,并将其应用于水书文字图像中,经过灰度转换、中值滤波去噪、直方图均衡化等处理,之后再通过Sobel算子锐化文字边缘,最终提取了水族刺绣图像及建筑图像中的水书文字 |
| 2. 翁彧设计了一个轻量级网络结构, 在5万个水书字符型样本上进行了分类实验,得到了93.3%的识别准确率,该研究没有涉及页面的水书文字识别,主要是单个水书文字的分类研究. |
| 3. 赵洪帅等将拉普拉斯金字塔与对抗性神经网络相结合,对水书古籍图像进行数据清晰度处理;再使用基于信息熵的无监督密度聚类算法,研究水书古籍图像文字的自动标注;在6230个水书字符样本上进行实验.其结果表明:拉普拉斯金字塔结构的生成对抗网络对水书文字的图像样本具有更高的分辨 率,且能增加少量的样本,但自动标注方法存在一些问题,即自动标注的准确率不高,影响了水书文字的识别准确率 |
| 4. 丁琼提 出 采用YOLO模型对水书文字进行识别检测,经 测 试识别率稳定在98%以上,但其采用的数据样本来源于水书文字和汉字混编的书籍中,并非水书卷本原件图像或影印件图像资料,且未具体介绍所使用的数据集及规模. |
1. 数据集
其原始数据集来源于《九星集》等古籍影印卷本。
重要的是数据扩增:
该文对一些样本比较少的生僻字,为提高模型的鲁棒性和扩展能力,通过人工手写、图像合成、图像裁剪 等方式进行数据扩增。
(1)人工方式
对于样本数量低于300个的水书文字类别及逆行人工手写,经过8个笔记不同的志愿者进行手写扩增,得到37个类别的水书文字共12021个字符样本。
(2)图像合成
对样本数量低于500的水书文字类别通过图像合成方式进行扩增。具体做法如下:
Step1: 首先确定该文字通过方向变换不会发生歧义,如:中文中的一、十。
Step2: 对字符切片进行二值化、旋转、翻转、添加噪声等方式;
Step3: 最后,对处理过的图像随机组合,进而合成一张完整的图片。
通过以上方式共获得图片1600张,共计37363个字符样本。
目的: 增加数据量,且包含各种场景、使数据呈现多样性,从而增强模型的泛化能力,防止过拟合。
(3)图像裁剪
对39张人工书写扩增的图像和1734张原始数据图像进行上、下、左、右及中心裁剪,最终获得水书文字图像9053张,共计73247个字符样本
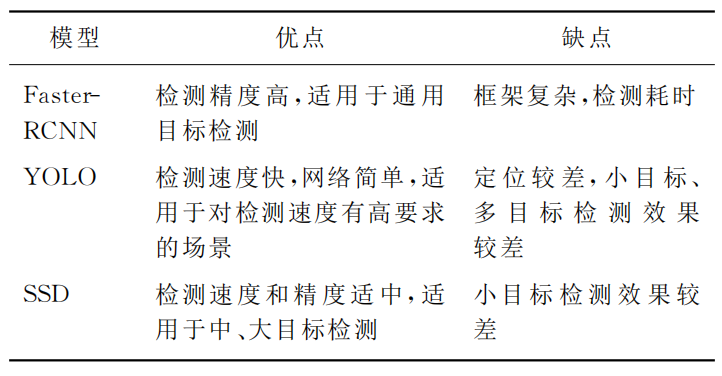
2. 目标检测算法的选取
(1)目标检测算法简介
主要分为"一步检测算法"、“两步检测算法”
| 一步检测法 | 两步检测法 |
|---|---|
| 在多层特征图上直接抽样并回归,一 步产生物体的类别概率和位置坐标值并输出,检测速度快,典型的有:SSD、YOLO | Step1: 首先在特征图上抽样产生密集的候选区域; Step2: 再对候选区域进行分类和回归。 常见的有: RCNN、Fast-RCNN、Faster-RCNN |
(2)两步检测算法详细介绍
a. RCNN
Step1: 先用选择性搜索算法在每个网格上依次提取1000-2000个候选区域;
Step2: 再使用卷积神经网络在其中依次提取每一个候选区域的特征;
Step3: 最后用支持向量机来对这些候选区域的数据特征进行综合分类.
优点: 在准确率上有不错的表现;
缺点: 该方法计算量过大,是以大量的资源和运行时长为代价换取准确率的提升
b. Fast-RCNN
Fast-RCNN是RCNN的升级版本。Fast_RCNN在卷积神经网络的最后一层卷积层后增加了ROI池化层,使得网络输入的尺寸可以是任意的(因为池化层课程改变图片的尺寸),并且对每一个图像只进行一次特征提取,大大提高效率。
此外,Fast-RCNN采用Softmax代替支持向量机进行多任务的分类,使得检测效率得到答复提升
但是,该算法依然存在选取候选区域耗时大的问题。
c. Faster-RCNN
Faster-RCNN的的主要特点是改变了候选区域的提取方法,即使用了候选区域网络RPN,使得卷积神经网络直接产生候选区域,而放弃了之前使用的选择性搜索方法。
Faster-RCNN交替训练的方式,可以在大大缩短目标检测耗时的同时,有效提高目标检测的准确率.
(3)一步检测算法详细介绍
a. YOLO
YOLO的训练和检测均在一个单独网络中进行,待检测图像仅需经过一次图像预测,便能得到该预测图像中所有置信目标的类别、位置、相应置信概率,计算速度快且有较高的准确率.
但是,YOLO算法直接将图像分割成若干区域,需要提前设定候选区域。且当多个目标同时落在一个区域时,只会取置信度最高的一类。
因此,YOLO算法对小目标或目标密集的检测精度较差。
b. SSD
该算法结合了Faster-RCNN和YOLO的部分思想,对图像不同位置的多种尺度的区域的不同特征进行回归,对这些特征进行分层提取和分析,并依次进行边框的尺度回归和特征分类等计算操作。最终完成多种不同尺度区域目标的训练、检测任务。
SSD算法在不影响素的同时,提高了目标检测准确率。
但该算法的默认框形状、网格尺寸都是预设的。
因此对小目标的检测效果仍然不够理想。
3. 实验
(1)实验设计
因为采用了3种不同数据扩增方式,故采用了不同组合的数据集进行了消融实验。具体如下:
(2)评价指标
实验结果的评价采用各自收敛轮数的mAP进行比较.mAP用于评价模型的好坏,是目标检测中的重要评估指标,其公式如下:
P
m
A
=
∑
i
=
1
N
P
i
A
N
∗
100
%
P_{mA} = { \sum_{i=1}^N P_i^A \over N } * 100\%
PmA=N∑i=1NPiA∗100%
其中,
N
N
N为类别数目,
P
i
A
P_i^A
PiA 为第i类的精确度,其计算如下:
P
i
A
=
P
(
i
)
Δ
r
(
i
)
P_i^A = P(i) \Delta r(i)
PiA=P(i)Δr(i)
其中,
P
(
i
)
P(i)
P(i) 表示第i类的准确率,
Δ
r
(
i
)
\Delta r(i)
Δr(i)表示第i类的召回率。
(3)实验设计
- 实验采用Faster-RCNN模型进行训练和测试;
- 使用VGG16作为其框架中提取图像特征的基础网络;
- 训练集: 测试集 = 8: 2
- 初始学习率 lr = 0.001
(4)实验结果


















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









