







一、视觉原理
人和动物如何把看到的图像转化为大脑中的一个概念?
我们知道计算机是把图转换为一大堆数字,通过训练可以知道这堆数字代表什么含义。但通过前面学过神经网络模型和梯度下降法的方法训练费时费力,而且一旦图片进行改变如缩放、旋转或其他变换,那么计算机就识别不出来了。那么人如何记住的呢?例如一本书,看了一次,后面哪怕是破损了,形状变了也能认出来?
二、视觉神经实验及神经认知模型
1981年休伯尔和威泽尔做过实验,给动物看不同图片,观察跟视觉相关的大脑中的细胞变化,主要分为两种
- 简单视觉神经细胞:对线条敏感,某个方向线条出现变化就会感应
- 复杂视觉神经细胞:对线条反应,且对线条的运动产生反应
根据这个实验,提出人是如何检测物体的?日本科学家福岛提出神经认知模型,即人是如何检测物体的是猫还是狗。
人的大脑中有很多皮层,一层一层对视觉信号进行传输处理。光从眼睛进入后,先计入第一皮层,在进第二皮层,直到最后一个皮层,每个皮层对信号处理的方式是不一样的。
神经认知模型流程如下;
- 实际上最开始刚进入视网膜时候是一大堆像素点
在第一皮层中,从这些像素点抽出一些特征,如边缘,而边缘是具有方向性的,
在第二皮层中,会将提取的边缘特征进行组合,形成物体的轮廓及物体更多细节
在第三皮层中,把轮廓和细节组合成一个整体
最终做出一个判断。
杨立昆根据这个神经认知模型流程原理(先输入,提取边缘特征,组合组轮廓和细节,在组合轮廓与细节成整体,最后进行判断)发明一种实用的图像识别方法,就是卷积神经网络。
三、卷积的定义和理解
卷积就是一种数学的方法,这个方法是通过两个函数f 和g 生成第三个函数的一种数学算子。
比如我们有1图片,我们想判断一下这幅图片是不是x,但是实际生活中每个人写字不同,X有很多种写法如下图,但是不管是哪一种写法,他们都有一个共同的特征,比如说都有有一个叉,都有1个往左下的线,有1个往右下的线。越符合这些特征,那么这个图就越有可能是X。因此判断这些图像X就需要提取出这些特征。所以卷积的作用就是用一种数学的方法,能提取出这个图像中我们刚刚说的这些特征。

四、卷积的计算
我们看 7x7 的图片,想让计算机判断这个黑白图片是不是X。计算机首先要把图像转换为一堆数字,因为是黑白图片,所以黑色0,白色是1,转为数字如下图:

计算机如何做呢?
首先是提取特征,那么提取特征的方法就是使用卷积核(也是1个矩阵,通常是3*3或5*5)来进行做卷积运算。
就是把卷积核(矩阵)放到图片对应的位置进行对应位置数据相乘再求和,然后放到被卷积核覆盖区域的中间的位置。卷积核向右平移1个单元,再次执行相同操作,依次类推,于是就形成1张新的图,这张图就叫做特征图。

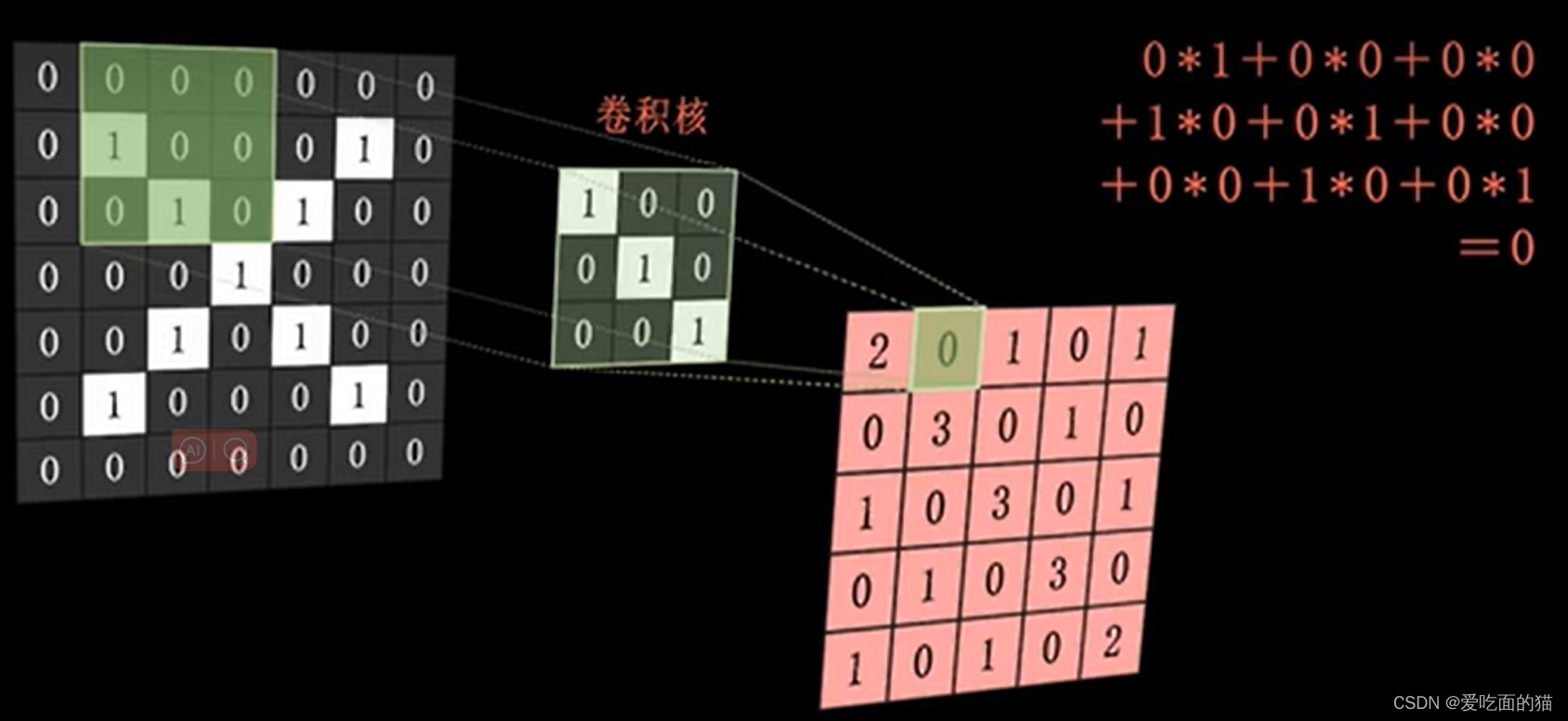

通过卷积核进行卷积运算得到的特征图结果如下,我们进行分析,在原图中,如果右下斜线都是1,而卷积核也是右下斜线是1,那么他们经过卷积运算得到的结果就会比较大,也就是说我们提取到了这些特征。(例如在特征图中的右下斜线中的3表明特征明显,而2则表示特征弱一点,而实际上我们他原图中顶脚是左上和右下都是0,也比较符合。而特征图中0和1表示原图中对应位置没有右下斜线的特征)。

五、池化和激活
池化:
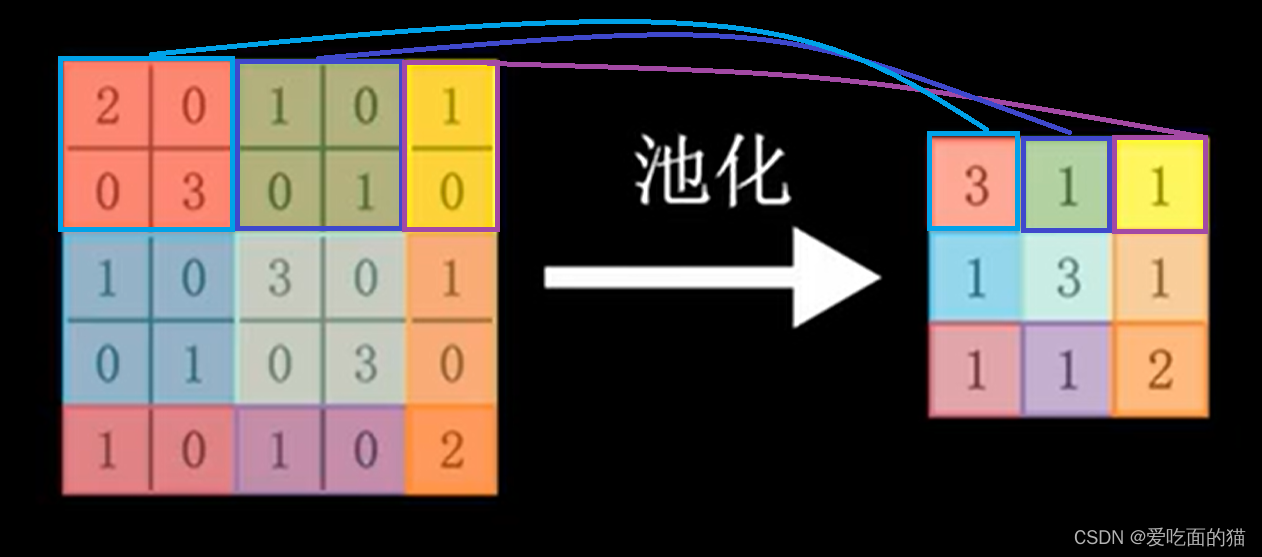
可以看出,当图像尺寸增大时,其内部的加法、乘法和除法操作的次数会增加得很快,每一个filter的大小和filter的数目呈线性增长。由于有这么多因素的影响,很容易使得计算量变得相当庞大。 为了有效地减少计算量,CNN使用的另一个有效的工具被称为“池化(Pooling)”。池化就是将输入图像进行缩小,减少像素信息,只保留重要信息。
并且经过卷积后的特征图可能还是比较大,不方便计算,则可以按区域对特征图进行提取,选取区区域中最大值,这个值一般也代表原图中的特征,如下图所示,对第一个区域取最大值为3(代表原图中的特征),第二个区域最大值为1,第三区域最大值为1,以此类推。得到池化后特征图结果。
我们看到最后池化的结果仍然是1个特征图,仍然是存在原图中的主要特征(右下斜线的特征,这些特征都比较大)。通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。
激活:
在前面所讲的神经网络,我们使用的是Sigmod函数作为激活函数。自变量越小,函数值越接近于0,自变量越大,函数值越接近于1。函数值为1,则说明激活了,会向下游传递信号。
此时需要对池化后的特征图结果使用的是Sigmod函数进行激活,于是就将池化后的特征图转换为0-1之间的数据。
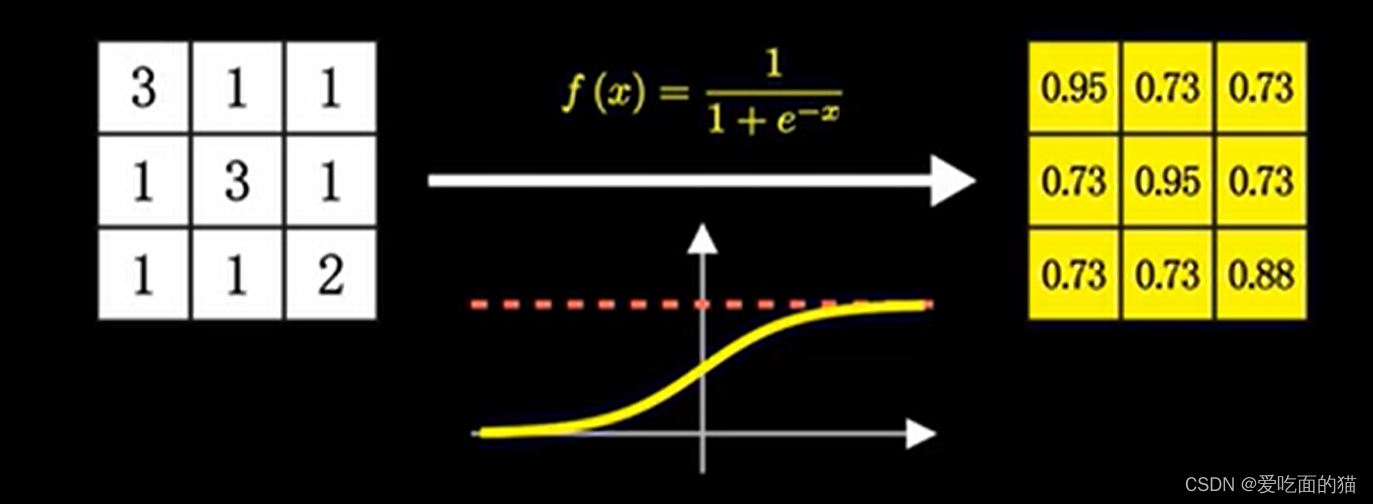
通过激活后的结果看到,数字越接近于1,这个地方越满足卷积核的特性。
问题:卷积核是如何设定的?
最开始是人为设定的,但随着机器学习,会根据数据进行反向调节这个卷积核(和前面讲的用参数训练的方式一样),通过不断学习,不断调节,找到最能满足特征的卷积核,这个卷积核就是最终模型要保存的参数数据。

全连接计算:
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。如下图:
1、结果串连
首先将经过卷积、激活函数、池化的深度网络后的结果串起来,如下图所示:
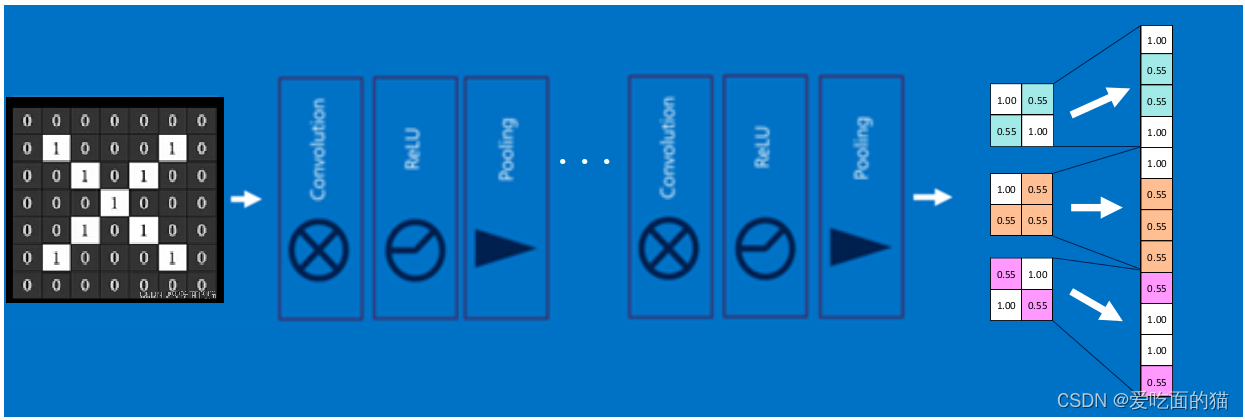
2、获取全连接权重
由于神经网络是属于监督学习,在模型训练时,根据训练样本对模型进行训练,从而得到全连接层的权重(例如获取预测字母X的所有连接的权重)

3、 预测值的计算
在利用该模型进行结果识别时,根据刚才提到的模型训练得出来的权重,以及经过前面的卷积、激活函数、池化等深度网络计算出来的结果,进行加权求和,得到各个结果的预测值,然后取值最大的作为识别的结果(如下图,最后计算出来字母X的识别值为0.92,字母O的识别值为0.51,则结果判定为X)
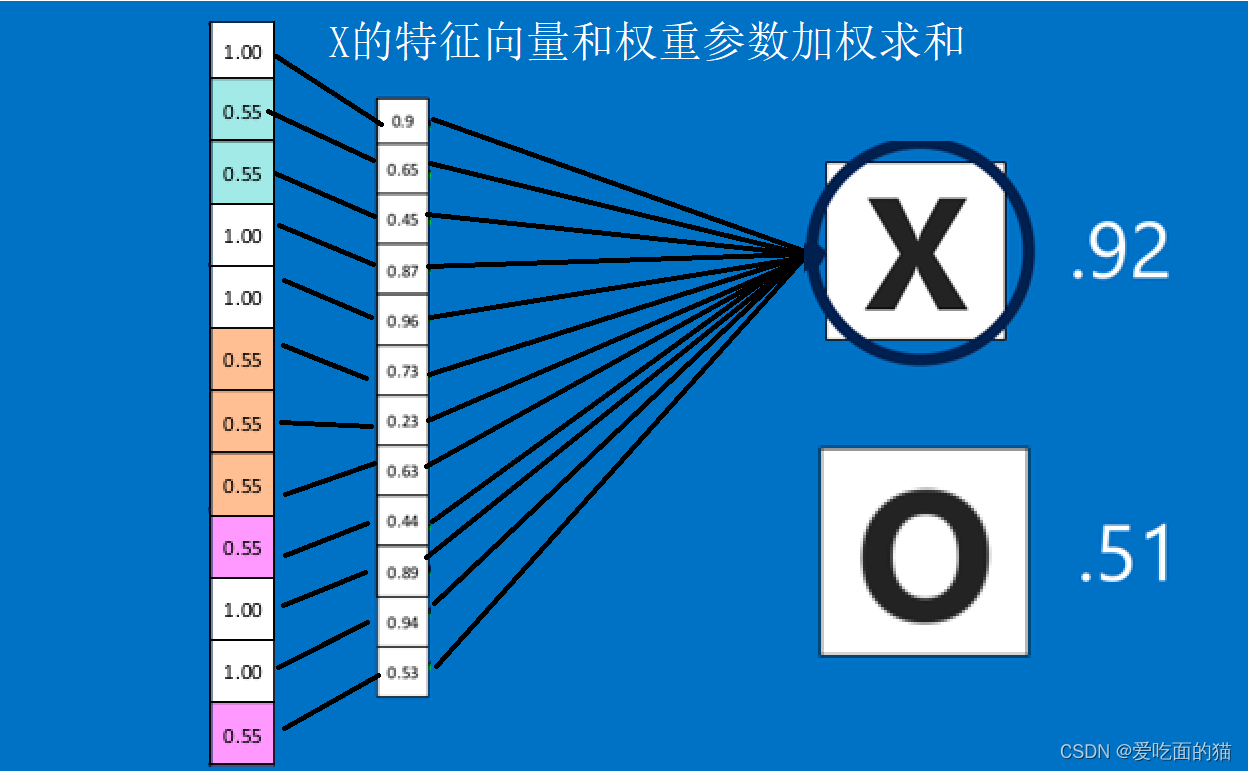
上述这个过程定义的操作为”全连接层“(Fully connected layers),全连接层也可以有多个,如下图:

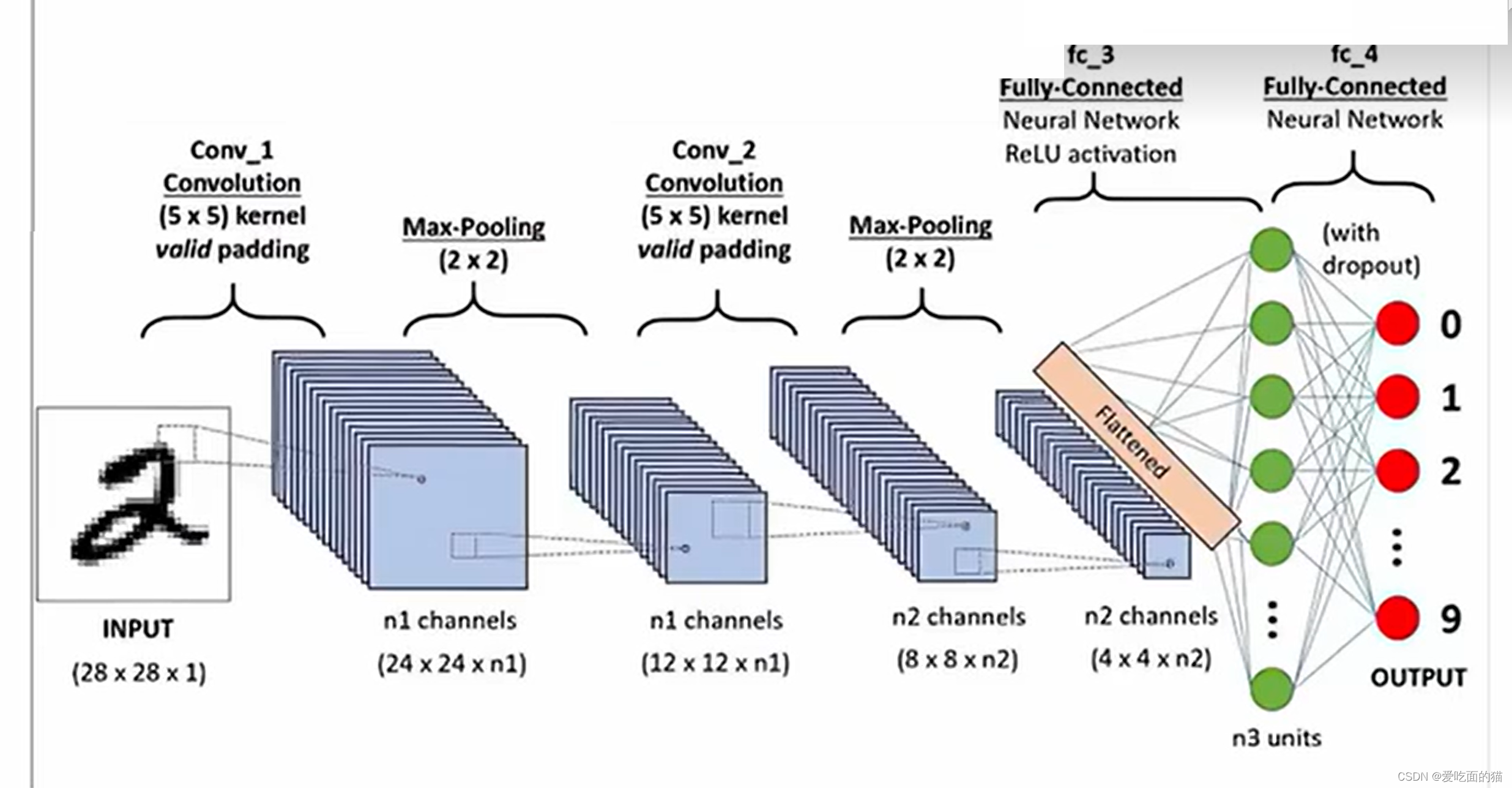
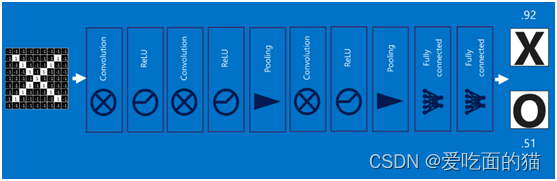
六、卷积神经网络(Convolutional Neural Networks)
将以上所有结果串起来后,就形成了一个“卷积神经网络”(CNN)结构,如下图所示:
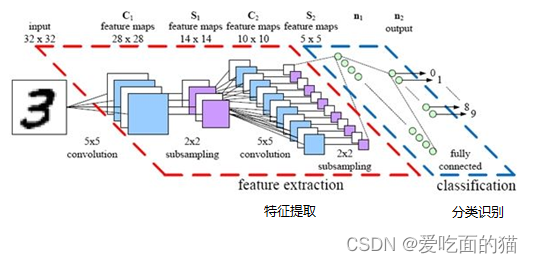
总结:卷积神经网络主要由两部分组成,下图便是著名的手写文字识别卷积神经网络结构图
- 一部分是特征提取(卷积、激活函数、池化)
- 另一部分是分类识别(全连接层)
七、算法、数据、算力
算法无非就是 + - *,只是计算量比较大而已。例如3通道800x600的图片,像素点= 800x600x3 = 1440000个。如果用3x3x3(3个通道则3个3x3卷积核)的卷积核,则运算的次数需要 130000次乘法和120000次加法。
此时只是1张800x600的图片就需要这么多次计算 ,而实际上有些时候需要训练的图片是成千上万张,图片可能是更大的(如:5742x3822),则计算的次数需要更多。此时算力显得尤为重要。
能体现算力的有以下几种方式:
- cpu:中央处理器,通用性强(什么都可以算),但串行能力差。
- gpu:图形处理器(用于图像渲染),专用行强,但并行能力强。
- npu:神经网络处理器,专门计算人工智能的处理器(具有cpu和gup特点),如华为升腾910AI处理器,有32个核,每个核是16x16x16=4096的矩阵。















 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









