









引文 [7] [8] 都指出了GCN模型无法像视觉任务中的CNN模型一样堆叠很深,一旦使用多层GCN进行学习,相关的任务效果就会急剧下降。这使得在某些场景中,GCN的学习能力将非常有限 [0] 。
在引文 [1] 中,作者在Cora数据集上做了一个实验,直观地展示了多层GCN所遇到的这个问题,如图2-11所示。
 图2-11 GCN效果随层数增加而发生的变化
图2-11 GCN效果随层数增加而发生的变化
图2-11是Cora数据集分别经过一个1至5层的GCN节点的表示向量的散点图,数据的原始输入是16维,最后模型的输出层是2维。观察该图,我们可以发现,在一层GCN模型下,两类节点并不能很好地区分,在两层GCN模型下,两类节点已经能很好地区分,如果继续加深模型的层数,两类节点会逐渐混合在一起,区分度将大大降低。
通过上面这个例子,我们可以发现,在使用多层GCN之后,节点的区分性变得越来越差,节点的表示向量趋于一致,这使得相应的学习任务变得更加困难。我们将这个现象称为多层GCN的过平滑(Over-Smooth)问题。
在2.3节中我们论证过,GCN相当于对输入信号做了一个低通滤波的操作,这回使信号变得更加平滑,这也是GCN模型的一个内在优势。但是,过犹不及,多次执行这类对信号不断平滑的操作之后,信号会越来越趋同,也就丧失了节点特征的多样性。下面我们分别从评语和空域视角去理解过平滑问题。
1. 频域视角
事实上,我们可以从GCN的频率响应函数
p
(
λ
)
=
1
−
λ
~
i
p(λ)=1-\tilde{λ}_i
p(λ)=1−λ~i中更清楚地看到这一点。
lim
k
→
+
∞
L
~
sym
k
=
lim
k
→
+
∞
(
I
−
L
~
s
)
k
=
lim
k
→
+
∞
(
V
(
1
−
Λ
~
)
V
T
)
k
=
lim
k
→
+
∞
V
[
(
1
−
λ
~
1
)
k
(
1
−
λ
~
2
)
k
⋱
(
1
−
λ
~
N
)
k
]
V
T
\begin{aligned}\lim\limits_{k→+∞}\tilde{L}_{\text{sym}}^k &=\lim\limits_{k→+∞}(I-\tilde{L}_s)^k\\ &=\lim\limits_{k→+∞}(V(1-\tilde{Λ})V^\text{T})^k\\ &=\lim\limits_{k→+∞}V\begin{bmatrix}(1-\tilde{λ}_1)^k&&&\\&(1-\tilde{λ}_2)^k&&\\&&⋱&\\&&&(1-\tilde{λ}_N)^k\end{bmatrix}V^\text{T}\end{aligned}
k→+∞limL~symk=k→+∞lim(I−L~s)k=k→+∞lim(V(1−Λ~)VT)k=k→+∞limV⎣⎢⎢⎡(1−λ~1)k(1−λ~2)k⋱(1−λ~N)k⎦⎥⎥⎤VT
由于
(
1
−
λ
~
i
)
∈
(
−
1
,
1
)
(1-\tilde{λ}_i)∈(-1,1)
(1−λ~i)∈(−1,1),且当且仅当
i
=
1
i=1
i=1时,
1
−
λ
~
i
=
1
1-\tilde{λ}_i=1
1−λ~i=1,由于其他的特征值都大于
0
0
0(这里假设图是全连通图,仅存在一个特征值为
0
0
0),因此取极限之后的结果为:
lim
k
→
+
∞
L
~
sym
k
=
V
[
1
0
⋱
0
]
V
T
\lim\limits_{k→+∞}\tilde{L}_{\text{sym}}^k=V\begin{bmatrix}1&&&\\&0&&\\&&⋱&\\&&&0\end{bmatrix}V^\text{T}
k→+∞limL~symk=V⎣⎢⎢⎡10⋱0⎦⎥⎥⎤VT
如果设图信号为
x
\boldsymbol{x}
x,则有:
lim
k
→
+
∞
L
~
sym
k
x
=
V
[
1
0
⋱
0
]
V
T
x
=
⟨
x
⋅
v
1
⟩
v
1
=
x
~
1
v
1
\lim\limits_{k→+∞}\tilde{L}_{\text{sym}}^k\boldsymbol{x}=V\begin{bmatrix}1&&&\\&0&&\\&&⋱&\\&&&0\end{bmatrix}V^\text{T}\boldsymbol{x}=\langle\boldsymbol{x}⋅\boldsymbol{v}_1\rangle\boldsymbol{v}_1=\tilde{x}_1\boldsymbol{v}_1
k→+∞limL~symkx=V⎣⎢⎢⎡10⋱0⎦⎥⎥⎤VTx=⟨x⋅v1⟩v1=x~1v1
其中
v
1
v_1
v1 是
L
~
s
\tilde{L}_s
L~s 的最小频率
λ
~
1
=
0
\tilde{λ}_1=0
λ~1=0 对应的特征向量,
x
~
1
\tilde{x}_1
x~1 表示信号
x
x
x 在对应频率
λ
~
1
\tilde{λ}_1
λ~1 的傅里叶系数。
由于:
L
~
s
D
~
1
/
2
1
=
D
~
−
1
/
2
L
D
~
−
1
/
2
D
~
1
/
2
1
=
D
~
−
1
/
2
L
1
=
D
~
−
1
/
2
0
=
0
\tilde{L}_s \tilde{D}^{1/2} \textbf{1}=\tilde{D}^{-1/2} L\tilde{D}^{-1/2} \tilde{D}^{1/2} \textbf{1}=\tilde{D}^{-1/2} L\textbf{1}=\tilde{D}^{-1/2} \textbf{0}=\textbf{0}
L~sD~1/21=D~−1/2LD~−1/2D~1/21=D~−1/2L1=D~−1/20=0
即:
L
~
s
D
~
1
/
2
1
=
0
\tilde{L}_s \tilde{D}^{1/2} \textbf{1}=0
L~sD~1/21=0(这里使用导论一个性质——拉普拉斯矩阵
L
L
L 存在值全为
1
1
1 的特征向量,其对应特征值为
0
0
0 )。
因此,
v
1
=
D
~
−
1
/
2
1
\boldsymbol{v}_1=\tilde{D}^{-1/2} \textbf{1}
v1=D~−1/21 是
L
~
s
\tilde{L}_s
L~s 在
λ
~
1
\tilde{λ}_1
λ~1 处的特征向量,该向量是一个处处相等的向量。所以,如果对一个图信号不断地执行平滑操作,图信号最后就会变得处处相等,也就完全没有可区分性了。
2.空域视角
在引文 [2] 中,作者从空域角度解释了为什么多层GCN会出现效果不好的现象。从空域来看,GCN的本质是在聚合邻居信息,对于图中的任意节点而言,节点的特征每更新一次,就多聚合了更高一阶邻居节点的信息。如果我们把最高邻居节点的阶数称为该节点的聚合半径,我们可以发现,随着GCN层数的增加,节点的聚合半径也在增长,一旦到达某个阈值,该节点可覆盖的节点几乎与全图节点一致。同时没如果层数足够多,每个节点能覆盖到的节点都会收敛到全图节点,这与哪个节点是无关的。这种情况的出现,会大大降低每个节点的局部网络结构的多样性,对于节点自身特征的学习十分不利。
图2-12所示为对方块节点的邻居信息进行聚合的结果,不同的是a图中的方块节点处于图的中心,而b图中的方块节点处于图的边缘。在4层GCN之后,a、b两图的方块节点的聚合半径虽然一致,但是覆盖的节点却是非常不一样的,如图中的蓝色节点所示。如果继续增加一层GCN,b图中的节点可覆盖的节点会迅速扩大,从而覆盖图中中心区域的节点,如c图中的蓝色节点所示。这种突变现象导致两个方块节点聚合的节点网络趋于一致,模型对于a图、b图中两个节点的区分将会变得十分困难。
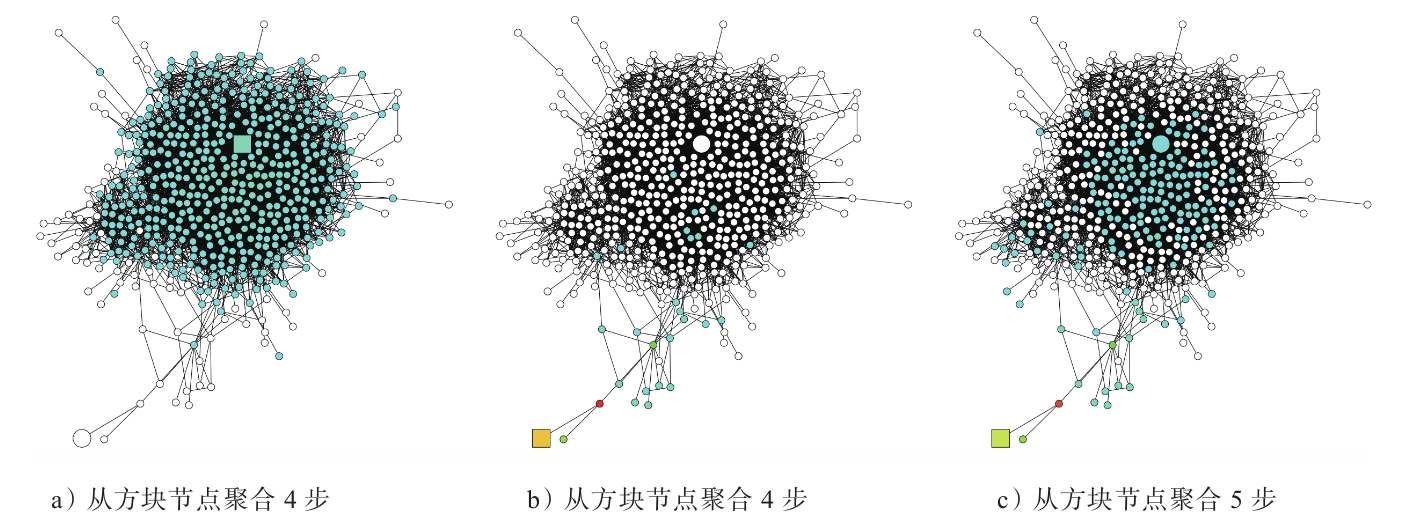
图2-12 对不同节点的聚合结果 [3]
关于如何应对过平滑,上文基于聚合半径与模型层数的关系,提出了自适应性聚合半径的学习机制,其实现的方式十分直观,就是通过增加跳跃连接来聚合模型的每层节点的输出,聚合后的节点特征拥有混合性的聚合半径,上层任务可对其进行选择性的监督学习,这样对于任意一个节点而言,既不会因为聚合半径过大而出现过平滑的问题,也不会因为聚合半径过小,使得节点的结构信息不能充分学习(见图2-13)。
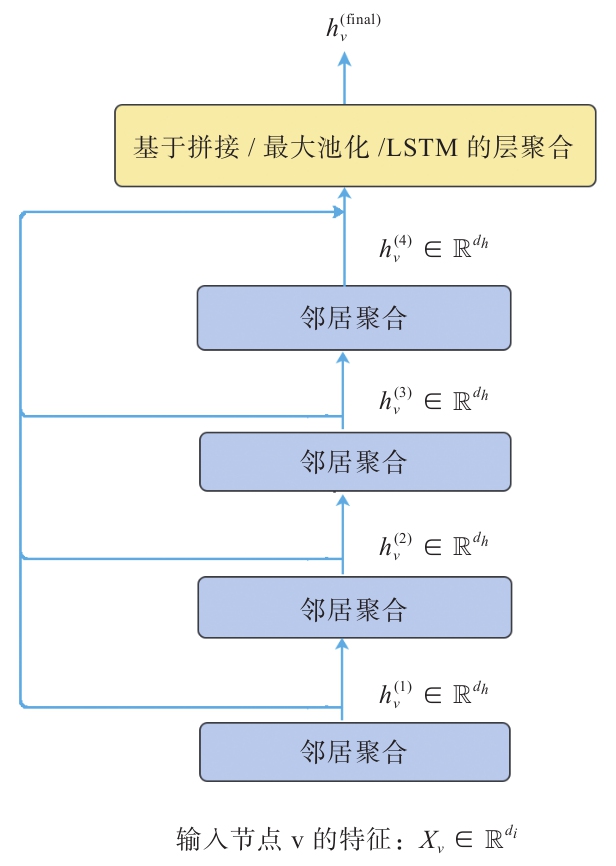
图2-13 聚合过程
图2-13说明了这种层级聚合的学习机制,在图2-13中,4层图模型的输出都会通过跳跃连接与最终的聚合层相连,聚合操作可以取如拼接、平均池化、最大池化等,聚合层的输出会作为整个模型的输出送到相应的监督任务中进行学习。
另一种方法是回到频率视角去调节图滤波器的值,在引文 [9] 中,使用了重新分配权重的方式来增加
A
~
\tilde{A}
A~ 中节点自连接的权重:
A
i
j
′
=
{
A
i
j
p
)
/
deg
(
v
i
)
,
if
i
≠
j
1
−
p
,
if
i
=
j
A_{ij}'=\begin{cases}A_{ij}p)/\text{deg}(v_i) , &\text{if}\ i≠j\\1-p, &\text{if}\ i=j\end{cases}
Aij′={Aijp)/deg(vi),1−p,if i=jif i=j
如上式所示,可以通过调节
p
p
p 的值对节点自身的权重进行重新分配。当
p
p
p 接近
1
1
1 时,模型趋向于不使用自身的信息,从频域来看,这加速了模型低通滤波的效应; 当
p
p
p 接近
0
0
0 时,模型趋向于布局和邻居的信息,从频域来看,这减缓了模型低通滤波的效应。
参考文献
[0] 刘忠雨, 李彦霖, 周洋.《深入浅出图神经网络: GNN原理解析》.机械工业出版社.
[1] Li Q , Han Z , Wu X M.Deeper insights into graph convolutional networks for semi-supervised learning[C]//Thirty-Second AAAI Conference on Artificial Intelligence.2018.
[2] Xu K , Li C , Tian Y , et al.Representation learning on graphs with jumping knowledge networks[J].arXiv preprint arXiv:1806.03536,2018.
[3] Xu K , Li C , Tian Y , et al.Representation learning on graphs with jumping knowledge networks[J].arXiv preprint arXiv:1806.03536,2018.
[4] Xu K , Li C , Tian Y , et al.Representation learning on graphs with jumping knowledge networks[J].arXiv preprint arXiv:1806.03536,2018.
[7] Li Q,Han Z,Wu X M.Deeper insights into graph convolutional networks for semi-supervised
learning[C]//Thirty-Second AAAI Conference on Artificial Intelligence.2018.[8] Xu K,Li C,Tian Y,et al.Representation learning on graphs with jumping knowledge networks[J].arXiv preprint arXiv:1806.03536,2018.
[9] Chen Z M,Wei X S,Wang P,et al.Multi-Label Image Recognition with Graph Convolutional Networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2019:5177-5186.


















 4298
4298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









