







Code:GitHub - wujcan/SGL-Torch: SGL PyTorch version(作者给出了Pytorch和Tensorflow两个版本)
本文提出了一种应用于用户-物品二分图推荐系统的图自监督学习框架。核心的思想是,对用户-物品二部图做数据增强(本文提出了三种方式:节点丢弃(nd))、边丢弃(ed),随机游走(rw),增强后的图可以看做原始图的子视图;在子视图上使用任意的图卷积操作,如LightGCN来提取结点的表征,对于同一个结点,多个视图就能形成多种表征;然后借鉴对比学习[5]的思路,构造自监督学习任务:最大化同一个结点不同视图表征之间的相似性,最小化不同结点表征之间的相似性;最后对比学习自监督任务和推荐系统的监督学习任务联合起来,构成多任务学习的范式,具体如下图所示。 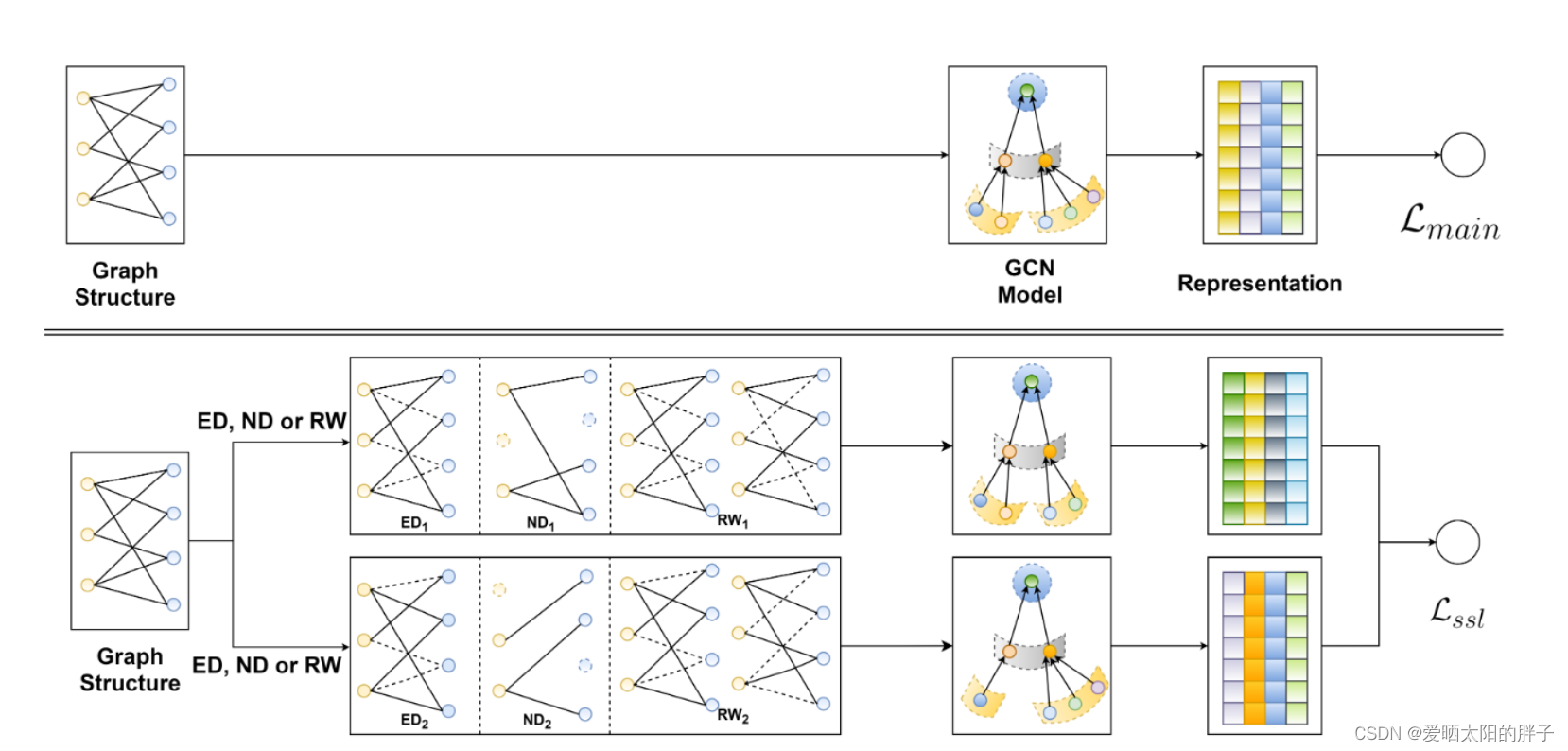
有上图可以看到,本文可大致分为两个部分:自监督学习部分、无监督学习部分(对比学习部分)
一、自监督学习
由于此部分不是本文重点,所以形式上很简单:lightgcn+bpr:
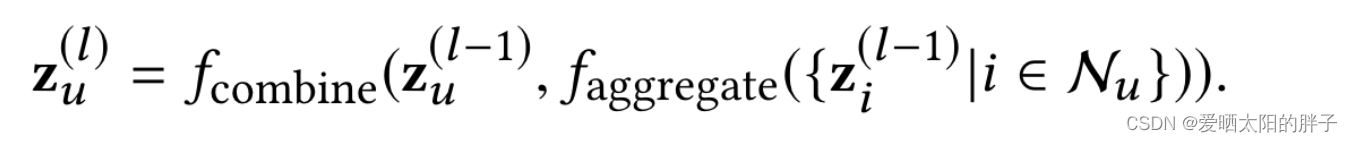
![]()
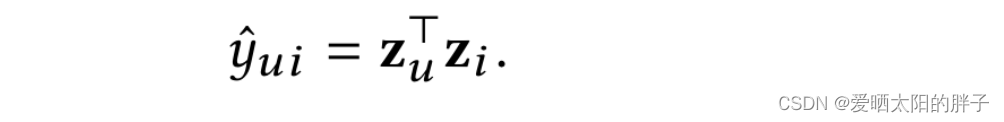
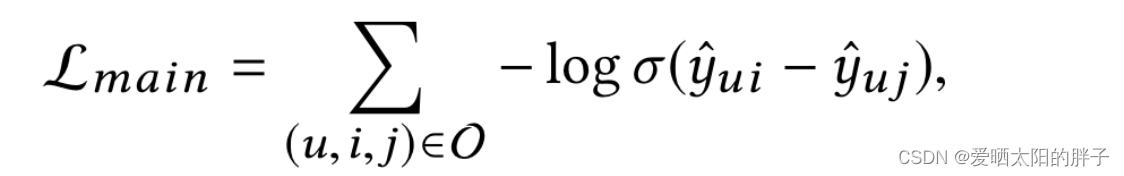
Lightgcn论文中给出的矩阵形式中的公式:
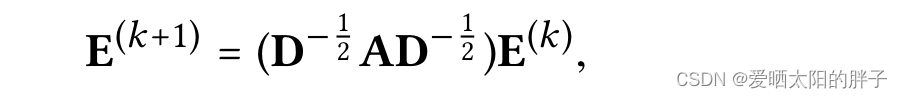
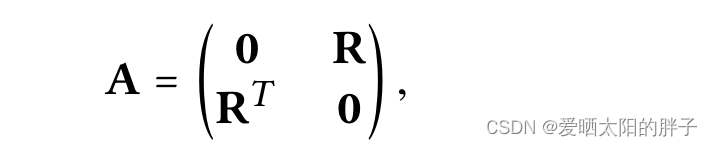
adj_mat = tmp_adj + tmp_adj.T
# normalize adjcency matrix
rowsum = np.array(adj_mat.sum(1))
d_inv = np.power(rowsum, -0.5).flatten()
d_inv[np.isinf(d_inv)] = 0.
d_mat_inv = sp.diags(d_inv)
norm_adj_tmp = d_mat_inv.dot(adj_mat)
adj_matrix = norm_adj_tmp.dot(d_mat_inv)
return adj_matrix二、无监督学习
1、节点/边丢弃
论文对这一部分描述的非常简洁,但也很抽象。下面公式中 masking vector(0/1组成的向量),
,
分别是点集和边集,字面意思就是:通过masking vector和点集/边集合坐元素积,0元素对应位置上的点/边被消掉。但代码是通过采样方式实现的,详情建议看原码:
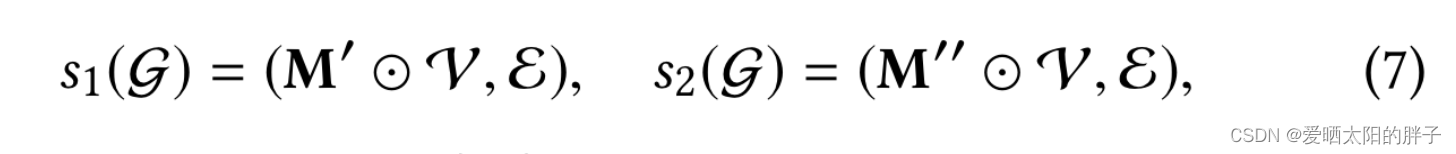
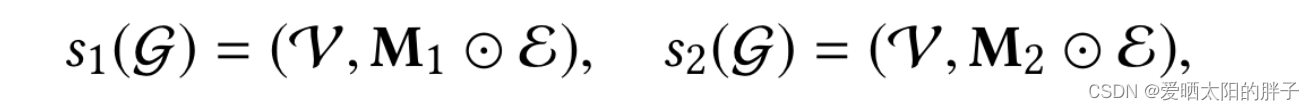
if is_subgraph and self.ssl_ratio > 0:
if aug_type == 'nd':
drop_user_idx = randint_choice(self.num_users, size=self.num_users * self.ssl_ratio, replace=False)
drop_item_idx = randint_choice(self.num_items, size=self.num_items * self.ssl_ratio, replace=False)
indicator_user = np.ones(self.num_users, dtype=np.float32)
indicator_item = np.ones(self.num_items, dtype=np.float32)
indicator_user[drop_user_idx] = 0.
indicator_item[drop_item_idx] = 0.
diag_indicator_user = sp.diags(indicator_user)
diag_indicator_item = sp.diags(indicator_item)
R = sp.csr_matrix(
(np.ones_like(users_np, dtype=np.float32), (users_np, items_np)),
shape=(self.num_users, self.num_items))
R_prime = diag_indicator_user.dot(R).dot(diag_indicator_item)
(user_np_keep, item_np_keep) = R_prime.nonzero()
ratings_keep = R_prime.data
tmp_adj = sp.csr_matrix((ratings_keep, (user_np_keep, item_np_keep+self.num_users)), shape=(n_nodes, n_nodes))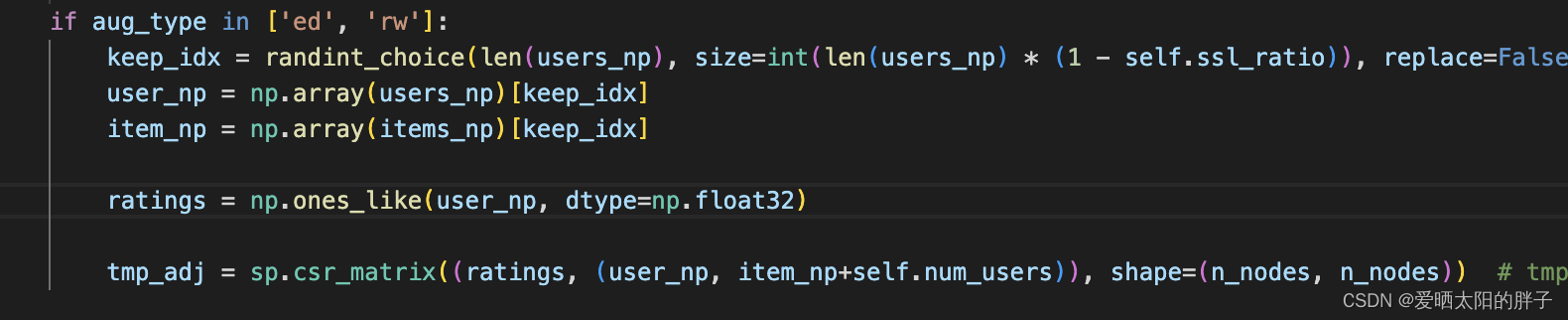
2、随机游走
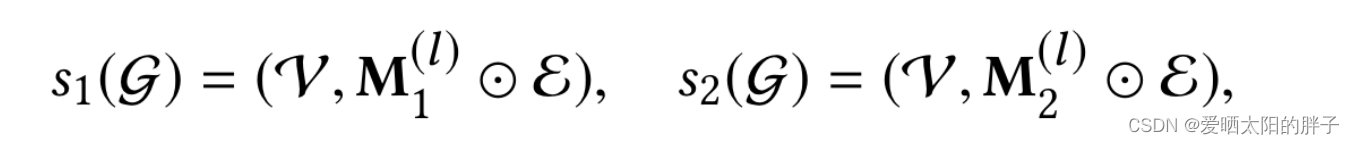
以上两个操作生成了一个在所有图卷积层上共享的子图。为了探索更强能力,我们考虑为不同的层分配不同的子图。这可以看作是为每个节点构建一个随机游走的单独子图。
The above two operators generate a subgraph shared across all the graph convolution layers. To explore higher capability, we consider assigning different layers with different subgraphs. This can be seen as constructing an individual subgraph for each node with random walk
这是论文中对着一部分的描述, 看完以后是不是很蒙?那我们只能看代码了。
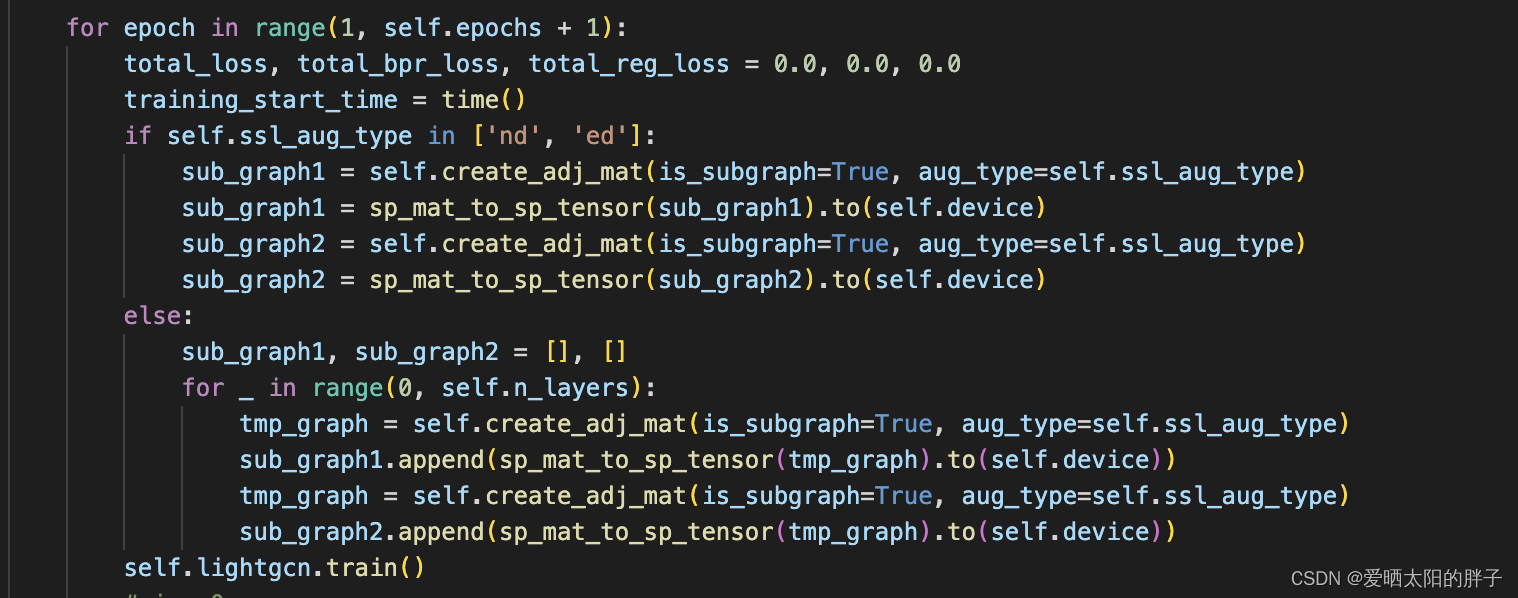
从下图代码中可以看到,'nd','ed'中生成了两张子图(sub_graph1,sub_graph2),而else也就是rw生成的是两个个子图列表,并且每个子图列表中子图的数量是等于n_layers(GCN中卷积蹭的数量)
下面是消息传递的代码。norm_adj是由上方子图得到的临接矩阵。if是rw对应的代码(由上图可知rw数据增强得到的是两个子图列表),else里是nd和ed对应的代码,可以看到rw方法,GCN做消息传递时候,每层都是在不同子图上进行的(norm_adj[k]),而ed方法做GCN时是在同一个子图上进行的(norm_adj)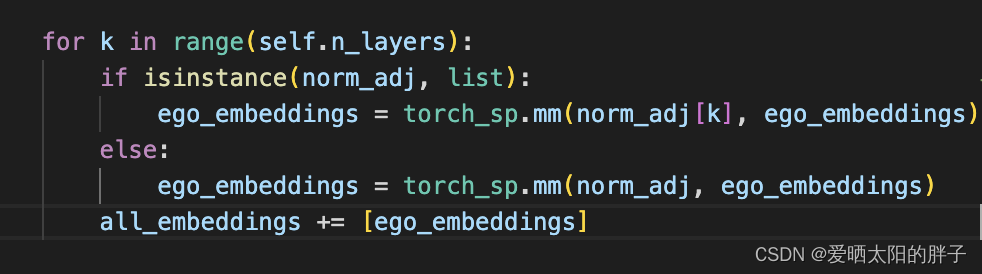















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









