










今天介绍transformer模型的encoder编码器,padding填充,source mask填充掩码

背景
encoder编码器层是对之前文章中提到的子层的封装。它接收位置嵌入的序列,并将其通过多头注意力机制和位置感知前馈网络。在每个子层之后,它执行残差连接和层归一化。
因为要循环n次,所以封装到一起就比较方便。
为了充分利用多头注意力子层的优势,输入标记会先通过一堆编码器层,然后再传递给解码器。这在文章开头的图片中用Nx表示,而上面的图片展示了这些堆叠的编码器如何将其输出传递给解码器层,这将在下一篇文章中讨论。
通过前向传播后,可以通过encoder.attn_probs访问注意力概率。

为什么要进行填充和掩码操作?
填充Padding
在实际应用中,一个批次中更可能出现的是长度各异的序列。为了保证一个批次中的所有序列长度相同,会对序列进行填充。当这种情况发生时,模型不需要关注填充标记。为每个序列创建一个掩码向量,以反映应该关注的值。
这个掩码的形状为(batch_size, 1, 1, seq_length)。它会在每个头对序列的表示中进行广播。
例如,下面的三个序列长度不同:
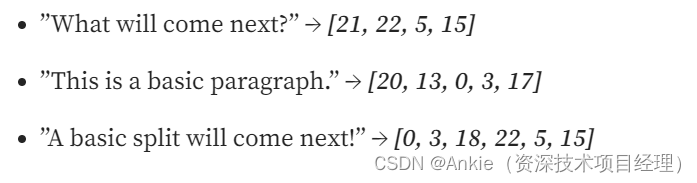
为了使不同长度的序列能在张量中使用,必须将它们填充到相同的长度。这可以通过使用torch.nn.functional中的pad函数来实现,它允许每个输入都被填充到相同的长度。pad函数需要以下参数:
seq: 一个序列(0, pad_to_add): 一个元组,指示要填充的维度以及填充的数量value=pad_idx: 用于填充的值,通常是一个整数
这个函数可以在一个for循环中使用,以便将一批序列填充到相同的长度,如下所示。这些填充后的序列可以用作编码器的输入。
填充标记被添加到每个序列中,次数根据需要达到最大长度。由于第一个序列的长度为4,因此需要添加四个填充标记。第二个序列需要三个填充标记,最后一个需要两个。
模型不应学习每个标记与填充标记之间的关系。它应该专注于原始序列中的标记以及它们彼此之间的关系,同时忽略填充标记。这些填充标记需要被屏蔽掉。这是通过创建一个源掩码来实现的,该掩码指示哪些标记需要被考虑。
源掩码The Source Mask
可以通过比较填充序列tensor_sequences中的标记和填充索引来创建源掩码。只有填充标记不应被考虑。当这个掩码传递给编码器时,每个填充标记的值需要被替换为一个非常大的负值,例如-∞或-1e10。由于当它被指数化时(e-∞ = 0),这是一个无关紧要的值,因此它不会对softmax输出产生显著影响。这意味着在概率分布中只会考虑适当的标记,而填充标记的值将为0。
假设填充标记是24,因此相应的值被设置为False,而所有其他标记保持为True。到目前为止,它的形状为(batch_size, seq_length)。为了将这个掩码广播到注意力概率上,这些注意力概率的形状为(batch_size, n_heads, Q_length, K_length),因此掩码的形状需要是(batch_size, 1, 1, seq_length)。请记住,在编码器中,seq_length、Q_length和K_length的长度是相同的,在这个上下文中是8。本质上,张量将包含3个序列的1个矩阵,该矩阵有1行,这是序列的源掩码。这个掩码被广播到键上,防止查询在句子中计算它们的上下文。


原文链接:https://medium.com/@hunter-j-phillips/the-encoder-f698b2c7afc0
















 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











