






 循环队列是一种解决数组队列假溢出现象的数据结构,通过首尾相连形成逻辑上的循环。它广泛应用于流水线缓冲区、提升IO性能和线程池。本文介绍了循环队列的概念,如假溢出的解决,以及其在重排缓冲区、IO性能提升和并发服务器中的应用,并提供了用数组实现循环队列的代码示例。
循环队列是一种解决数组队列假溢出现象的数据结构,通过首尾相连形成逻辑上的循环。它广泛应用于流水线缓冲区、提升IO性能和线程池。本文介绍了循环队列的概念,如假溢出的解决,以及其在重排缓冲区、IO性能提升和并发服务器中的应用,并提供了用数组实现循环队列的代码示例。
文章目录
前言
相比于链队列,循环队列有着内存固定,效率高等特点,因而广泛应用于计算机的各个层面。本文主要介绍循环队列的概念,列举一些循环队列的应用场景,以及给出用数组实现循环队列的代码。
一、循环队列是什么?
1.队列的两种表示方法
和线性表类似,队列有两种存储表示:分别为链式表示方式和顺序表示方式。
其中,链式表示方式的队列用链表实现。若用户无法预估队列的具体长度,那么用链队列是比较方便的,因为链表的好处就是可以很方便地添加和删除新的节点。但我们也知道链表在添加节点的时候需要动态分配内存,这个过程是比较耗费资源和时间的。
如果我们的队列长度固定,又想要有较高的性能,那么就可以用顺序表示方式的队列。
2.数组队列的“假溢出”现象
提起顺序的数据结构,大家可能首先想到了数组。那么我们能不能用正常意义上的数组实现顺序队列呢?答案是不好实现,原因就是所谓的“假溢出”现象。
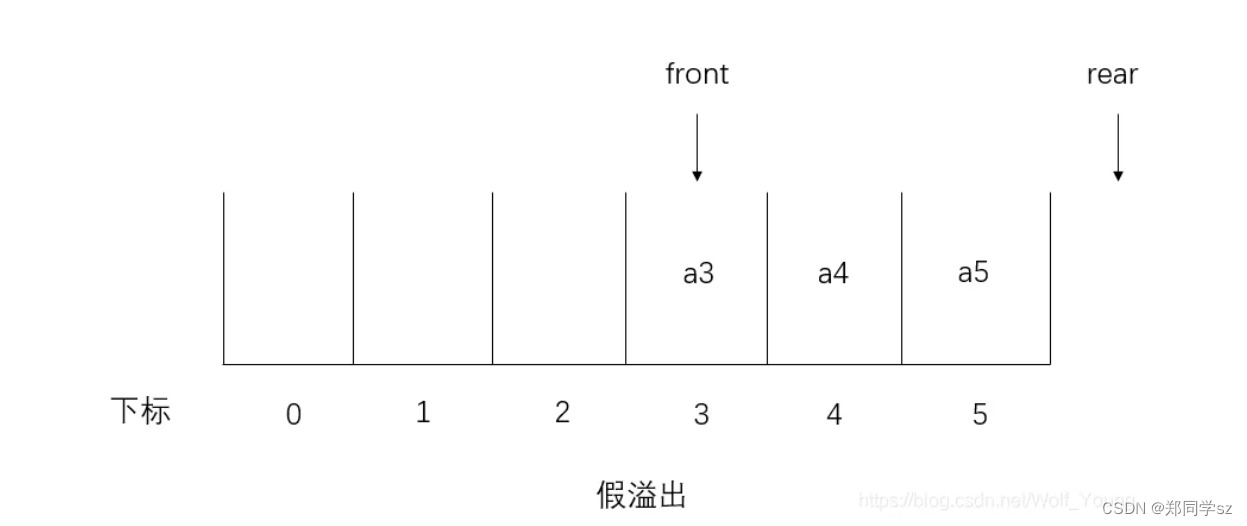
系统作为队列用的存储区还没有满,但队列却发生了溢出,我们把这种现象称为"假溢出"。我们可以假设分配了大小为6的数组,用作队列。那我们在添加完a5元素后,就无法再添加元素了,因为队列已经“满了”。但是这时0-2号数组的槽位是空的,理论上是可以添加新元素的,这时候的队列元素的溢出就是“假溢出”。
假溢出问题怎么解决呢?一种方法是每次队首的元素被取出时候,剩余所有的元素都往前平移一个单位。但是这种方式太过于耗费性能,数组最不擅长删除元素,与其用这种方式实现顺序队列,还不如直接用链式队列。
还有一种方法就比较巧妙了:将数组的首尾相连,组成一个逻辑上的“循环队列”。这就是我们今天主要讲的内容了。
3.循环队列应运而生
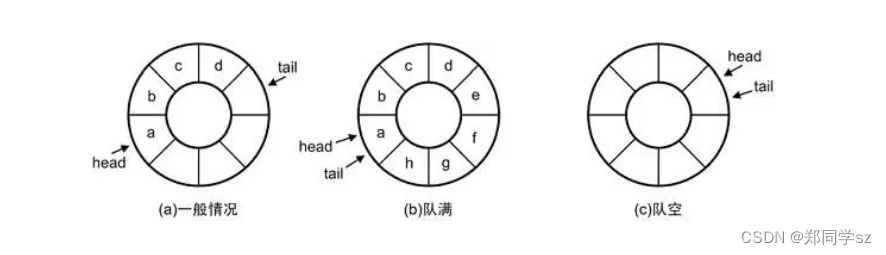
循环队列其实就是将数组的首尾相连,组成的一个特殊结构。我们用两个指针来表示队列的队首和队尾,head表示队首的元素,tail表示队尾的下一个元素。这里的数组“尾部”的下一个元素就是“首部”,这样就可以很好避免了假溢出的问题。
有人可能有疑问了:用数组存储数据是很自然的,因为计算机的寻址方式就是线性的;那么循环队列怎么寻址,计算机有对应的寻址方式,或者说内存结构吗?
其实答案很简单,计算机确实基本没有环形结构的内存结构,我们是用计算机的线性寻址方式,来模拟环形的结构。通俗来说,就是用数组来模拟循环队列。第三节会给出一种用数组实现循环队列的方式,在此就不再赘述了。
二、循环队列的一些应用场景
1.流水线缓冲区
现代计算机的CPU执行指令时,并不是每次一条指令,顺序执行的;而是多条指令组成流水线,并行执行的。并行执行就可能导致顺序问题。比如说正确的指令顺序是先执行A指令,再执行B指令,但是并行执行的情况下,指令顺序就可能被打乱,变成先执行B,再执行A。所以我们需要一种方法能保证指令是顺序执行的。
一种方法就是使用ROB,也就是重排缓冲区。ROB本质上就是一个循环队列,记录指令的执行顺序。每个系统时钟系统都会检测环形队列的首部指令是否执行完毕,如果执行完毕的话,首个元素就会退出。而尾部元素,就是最新的待执行的指令添加过来的。
2.使用环形队列提升IO性能
总所周知,计算机不同部件的运行速度是不同的,内存访问速度就远远大于硬盘IO速度。那么计算机在往硬盘写数据的时候,发生这种情况该怎么办:计算机短时间内由多个IO操作,第一个IO操作还没有执行完,第二个IO指令就已经发出来了,这个时候IO控制器还在处理第一个IO请求。
这种情况该怎么办?用一个循环队列可以轻松解决:计算机把所有要发送的IO命令写入一个循环队列,然后IO控制器定时去取IO命令,然后执行。这样降低了各个部件之间的耦合性,而且很好地解决了各个部件执行速率不一致的情况。
网卡是IO设备的一种,与磁盘IO用于计算机内部通信不同,网卡可以用于跨设备的通信。所以说网卡相比于别的IO设备,它的不稳定性是更强的。磁盘IO可能也就是速度慢了点,但是网络IO收到网络状况的影响很大。比如说有一段时间网络堵塞,可能等了好久都等不到下一个包。所以用循环队列来接收数据包是很必须的了。
3.线程池
上述两个例子都是比较底层的例子,那么我们在写代码的时候能否用到环形队列呢?
我们都知道,基本上所有的服务器都支持并发,也就是在一个时间间隔内能够处理多个用户的请求。但是不同的请求占用服务器的时间长短又不一样,如果使用单进程单线程的服务器,有可能一个用户请求就会阻塞服务器好久。所以我们可以使用多线程来构造服务器:将服务器进程分为生产者和消费者,生产者只是简单的接受请求,然后把连接放入循环队列,消费者从队列中取数据,做耗时较长的操作。
下边举一个简单的例子,来说明在构建web服务器的时候,如何用循环队列来实现并发服务器。
三、用数组实现循环队列
示例如下,代码取自《深入理解计算机系统》一书:
sbuf.h文件,定义了循环队列的结构体。具体解释见注释:
#ifndef __SBUF_H__
#define __SBUF_H__
#include "csapp.h"
/* $begin sbuft */
typedef struct {
int *buf; /* 数组结构,其长度由用户确定,在sbuf_init函数中进行内存分配 */
int n; /* 数组的最大长度,也就是循环队列的容量 */
int front; /* 队首指针,buf[(front+1)%n] 是循环队列的第一个元素 */
int rear; /* 队尾指针,buf[rear%n] 是循环队列的最后一个元素 */
sem_t mutex; /* Protects accesses to buf */
sem_t slots; /* Counts available slots */
sem_t items; /* Counts available items */
} sbuf_t;
/* $end sbuft */
void sbuf_init(sbuf_t *sp, int n);
void sbuf_deinit(sbuf_t *sp);
void sbuf_insert(sbuf_t *sp, int item);
int sbuf_remove(sbuf_t *sp);
#endif /* __SBUF_H__ */
sbuf.c文件,实现了循环队列的初始化,销毁,添加和删除元素:
/* $begin sbufc */
#include "csapp.h"
#include "sbuf.h"
/* Create an empty, bounded, shared FIFO buffer with n slots */
/* $begin sbuf_init */
void sbuf_init(sbuf_t *sp, int n)
{
sp->buf = Calloc(n, sizeof(int));
sp->n = n; /* Buffer holds max of n items */
sp->front = sp->rear = 0; /* Empty buffer iff front == rear */
Sem_init(&sp->mutex, 0, 1); /* Binary semaphore for locking */
Sem_init(&sp->slots, 0, n); /* Initially, buf has n empty slots */
Sem_init(&sp->items, 0, 0); /* Initially, buf has zero data items */
}
/* $end sbuf_init */
/* Clean up buffer sp */
/* $begin sbuf_deinit */
void sbuf_deinit(sbuf_t *sp)
{
Free(sp->buf);
}
/* $end sbuf_deinit */
/* Insert item onto the rear of shared buffer sp */
/* $begin sbuf_insert */
void sbuf_insert(sbuf_t *sp, int item)
{
P(&sp->slots); /* Wait for available slot */
P(&sp->mutex); /* Lock the buffer */
sp->buf[(++sp->rear)%(sp->n)] = item; /* 在队尾插入元素,并将队尾指针后移 */
V(&sp->mutex); /* Unlock the buffer */
V(&sp->items); /* Announce available item */
}
/* $end sbuf_insert */
/* Remove and return the first item from buffer sp */
/* $begin sbuf_remove */
int sbuf_remove(sbuf_t *sp)
{
int item;
P(&sp->items); /* Wait for available item */
P(&sp->mutex); /* Lock the buffer */
item = sp->buf[(++sp->front)%(sp->n)]; /* 从队首取出元素,并将队首指针后移 */
V(&sp->mutex); /* Unlock the buffer */
V(&sp->slots); /* Announce available slot */
return item;
}
/* $end sbuf_remove */
/* $end sbufc */
上述代码通过数组实现了循环队列,并通过信号量和锁避免读写冲突。通过slots信号量避免往满队列添加元素,用items避免从空队列中取元素。用上述代码,可以很简单地实现一个基于线程的并发服务器。生产者和消费者之间通过循环队列交换数据。
echoservert_pre.c文件,用循环队列实现一个基于线程的并发服务器:
/*
* echoservert_pre.c - A prethreaded concurrent echo server
*/
/* $begin echoservertpremain */
#include "csapp.h"
#include "sbuf.h"
#define NTHREADS 4
#define SBUFSIZE 16
void echo_cnt(int connfd);
void *thread(void *vargp);
sbuf_t sbuf; /* Shared buffer of connected descriptors */
int main(int argc, char **argv)
{
int i, listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
pthread_t tid;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]);
sbuf_init(&sbuf, SBUFSIZE); //line:conc:pre:initsbuf
for (i = 0; i < NTHREADS; i++) /* Create worker threads */ //line:conc:pre:begincreate
Pthread_create(&tid, NULL, thread, NULL); //line:conc:pre:endcreate
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen);
sbuf_insert(&sbuf, connfd); /* Insert connfd in buffer */
}
}
void *thread(void *vargp)
{
Pthread_detach(pthread_self());
while (1) {
int connfd = sbuf_remove(&sbuf); /* Remove connfd from buffer */ //line:conc:pre:removeconnfd
echo_cnt(connfd); /* Service client */
Close(connfd);
}
}
/* $end echoservertpremain */
总结
本文介绍了循环队列的定义、使用场景和实现方式。大家可能疑问,为什么上边举例的场景不用链队列实现?比如用链队列实现流水线缓存,IO缓存等。
我觉得是这样的:链队列一般是用于队列大小不固定的场景,而且依赖于操作系统给它分配资源。而流水线缓存,IO缓存等过于底层的东西,是比操作系统还底层的东西,我们难以给他们动态调度资源。而且这些缓存的大小一般也是固定的,不像操作系统虚拟出了一个地址空间,用户可以任意分配资源大小。
所以这也再次体现了循环队列的优点:资源固定,实现简单,性能高。

















 8310
8310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









