







文章目录
1 离散有限时间系统
1.1 LQR问题描述
离散系统方程:
x
t
+
1
=
A
n
×
n
x
t
+
B
n
×
m
u
t
,
x
0
=
x
i
n
i
t
x_{t+1}=A_{n\times n}x_{t}+B_{n\times m}u_{t}, x_0=x^{init}
xt+1=An×nxt+Bn×mut,x0=xinit
问题: 选取
u
0
,
u
1
,
…
u_0,u_1,\ldots
u0,u1,…使得:
- x 0 , x 1 , … x_0,x_1,\ldots x0,x1,…较小,获得较好的状态控制;
- u 0 , u 1 , … u_0,u_1,\ldots u0,u1,…较小,使用较少的输入控制;
较大的 u u u可以使 x x x快速趋于0。
定义二次代价函数:
J
(
U
)
=
∑
τ
=
0
N
−
1
(
x
τ
T
Q
x
τ
+
u
τ
T
R
u
τ
)
+
x
N
T
Q
f
x
N
J(U)=\sum_{\tau=0}^{N-1}(x^T_{\tau}Qx_{\tau}+u^T_{\tau}Ru_{\tau})+x^T_NQ_fx_N
J(U)=τ=0∑N−1(xτTQxτ+uτTRuτ)+xNTQfxN
其中,
U
=
(
u
0
,
u
1
,
…
,
u
N
−
1
)
U=(u_0,u_1,\ldots,u_{N-1})
U=(u0,u1,…,uN−1)
Q
=
Q
T
≥
0
,
Q
f
=
Q
f
T
≥
0
,
R
=
R
T
>
0
Q=Q^T\ge0,Q_f=Q^T_f\ge0,R=R^T>0
Q=QT≥0,Qf=QfT≥0,R=RT>0
分别为状态代价权重矩阵,终态代价权重矩阵和输入权重矩阵。
N N N为时间范围,可有限也可无限,后续分开讨论。
- R > 0 R>0 R>0 表示任何非零输入都会影响代价 J J J
LQR问题:找到 u 0 l q r , u 1 l q r , … , u N − 1 l q r u_0^{lqr},u_1^{lqr},\ldots,u_{N-1}^{lqr} u0lqr,u1lqr,…,uN−1lqr使 J J J最小。
1.2 最小二乘法求解
令
X
=
[
x
0
T
,
x
1
T
,
…
,
x
N
T
]
T
,
U
=
[
u
0
T
,
u
1
T
,
…
,
u
N
−
1
T
]
T
X=[x_0^T,x_1^T,\ldots,x_N^T]^T,U=[u_0^T,u_1^T,\ldots,u_{N-1}^T]^T
X=[x0T,x1T,…,xNT]T,U=[u0T,u1T,…,uN−1T]T,则有:
X
N
n
×
1
=
[
B
0
⋯
0
A
B
B
⋯
0
⋮
⋮
⋮
⋮
A
N
−
1
B
A
N
−
2
B
⋯
B
]
N
n
×
N
m
U
N
m
×
1
+
[
A
⋮
A
N
]
N
n
×
n
x
0
X_{Nn\times 1}= \begin{bmatrix} B&&0&&\cdots&&0\\ AB && B && \cdots &&0\\ \vdots && \vdots && \vdots && \vdots \\ A^{N-1}B && A^{N-2}B && \cdots &&B \end{bmatrix}_{Nn\times Nm}U_{Nm\times 1}+ \begin{bmatrix} A\\ \vdots\\ A^{N} \end{bmatrix}_{Nn\times n}x_0
XNn×1=⎣⎢⎢⎢⎡BAB⋮AN−1B0B⋮AN−2B⋯⋯⋮⋯00⋮B⎦⎥⎥⎥⎤Nn×NmUNm×1+⎣⎢⎡A⋮AN⎦⎥⎤Nn×nx0
写做:
X
=
G
U
+
H
x
0
X=GU+Hx_0
X=GU+Hx0
则有:
J
=
U
T
R
~
U
+
X
T
Q
~
X
=
U
T
R
~
U
+
(
G
U
+
H
x
0
)
T
Q
~
(
G
U
+
H
x
0
)
J=U^T\widetilde RU+X^T\widetilde QX=U^T\widetilde RU+(GU+Hx_0)^T\widetilde Q(GU+Hx_0)
J=UTR
U+XTQ
X=UTR
U+(GU+Hx0)TQ
(GU+Hx0)
其中
R
~
=
d
i
a
g
(
R
,
R
,
⋯
,
R
⏟
N
个
)
\widetilde R=diag(\underbrace{R,R,\cdots,R}_{N\text{个}})
R
=diag(N个
R,R,⋯,R),
Q
~
=
d
i
a
g
(
Q
,
Q
,
⋯
,
Q
⏟
N
个
)
\widetilde Q=diag(\underbrace{Q,Q,\cdots,Q}_{N\text{个}})
Q
=diag(N个
Q,Q,⋯,Q)
J
J
J可以表示为关于
U
U
U的二次型形式:
J
(
U
)
=
U
T
(
R
~
+
G
T
Q
~
G
)
U
+
2
x
0
T
H
T
Q
~
G
U
+
x
0
T
H
T
Q
~
H
x
0
J(U)=U^T(\widetilde R +G^T\widetilde QG)U+2x_0^TH^T\widetilde QGU+x_0^TH^T\widetilde QHx_0
J(U)=UT(R
+GTQ
G)U+2x0THTQ
GU+x0THTQ
Hx0
可以证明求
J
J
J的最小值是一个凸优化问题,可直接求导得到
J
J
J取最小值时的
U
U
U。
d
J
d
U
=
2
(
R
~
+
G
T
Q
~
G
)
U
+
2
G
T
Q
~
H
x
0
\frac{dJ}{dU}=2(\widetilde R +G^T\widetilde QG)U+2G^T\widetilde QHx_0
dUdJ=2(R
+GTQ
G)U+2GTQ
Hx0
令
d
J
d
U
=
0
\frac{dJ}{dU}=0
dUdJ=0,则有
U
∗
=
−
(
R
~
+
G
T
Q
~
G
)
−
1
G
T
Q
~
H
x
0
U^*=-(\widetilde R +G^T\widetilde QG)^{-1}G^T\widetilde QHx_0
U∗=−(R
+GTQ
G)−1GTQ
Hx0
1.3 最小二乘法编程实现
以下为一个简单的例子:
%% Problem description:
% Suppose there is a car moving along the trajectory, and the current speed
% is 0.1m/s. The current state of the car is that the lateral error is 0.5m,
% and the lateral error angle is 5 degrees. Now that the car wants to eliminate
% the lateral error by entering the angular velocity, we need to design the LQR
% target and solve it.
% state function:
% [dx1, dx2]' = [0, v; 0, 0] * [x1, x2]' + [0, 1]' * u
% where x1 is the the lateral error, x2 is the the lateral error
% angle, and u is the angular velocity
% Initial state: x1 = 0.5, x2 = 0.0872;
% End state: x1 = 0
%%
clear;clc;
close all;
A = [0, 0.1; 0, 0];
B = [0, 1]';
x0 = [0.5, 0.0872]';
[state_num, input_num] = size(B);
dt = 0.05;
N = 80/dt;
Ak = eye(2) + dt*A;
Bk = dt*B;
Q = eye(2);
R = 1;
% X = G * U + H * x0
G = zeros(N*state_num, N*input_num);
H = zeros(N*state_num, state_num);
tic;
for i = 1:N
for j = 1:i
G((state_num*(i-1)+1):(state_num*(i)), (input_num*(j-1)+1):(input_num*(j))) = Ak^(i-j)*Bk;
H((state_num*(i-1)+1):(state_num*(i)), 1:state_num) = Ak^(i);
end
end
H_q = diag(repmat(diag(R), N, 1)) + G'*diag(repmat(diag(Q), N, 1))*G;
f_q = x0'*H' * diag(repmat(diag(Q), N, 1)) *G;
U = - H_q \ f_q';
X = G*U+H*x0;
X1 = [x0(1); X(1:2:end-2)];
X2 = [x0(2); X(2:2:end-2)];
toc;
figure;
subplot(2, 1, 1);
hold on;
plot(X1, 'b');
subplot(2, 1, 2);
plot(X2, 'b');
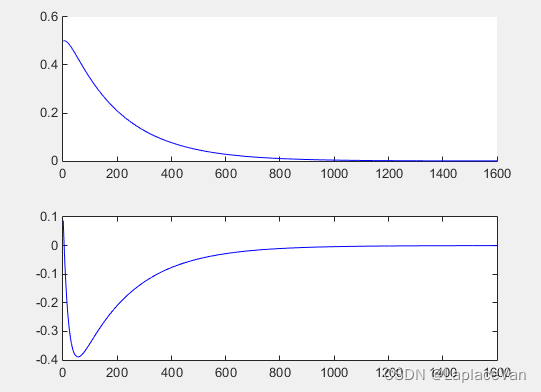
运行时间为71s,讲义里说明这种解法时间复杂度为
O
(
N
3
n
m
2
)
O(N^3nm^2)
O(N3nm2),确实效率不高。
1.4 动态规划算法
定义函数
V
t
:
R
n
→
R
V_t:\mathbf{R}^n\rightarrow\mathbf{R}
Vt:Rn→R
V
t
(
z
)
=
m
i
n
u
t
,
⋯
,
u
N
−
1
∑
τ
=
t
N
−
1
(
x
τ
T
Q
x
τ
+
u
τ
T
R
u
τ
)
+
x
N
T
Q
f
x
N
V_t(z)=\mathop{min}\limits_{u_t, \cdots, u_{N-1}}\sum\limits_{\tau=t}^{N-1}(x_{\tau}^TQx_{\tau}+u_{\tau}^TRu_{\tau})+x_N^TQ_fx_N
Vt(z)=ut,⋯,uN−1minτ=t∑N−1(xτTQxτ+uτTRuτ)+xNTQfxN
满足
x
t
=
z
,
x
τ
+
1
=
A
x
τ
+
B
u
τ
x_t=z, x_{\tau+1}=Ax_{\tau}+Bu_{\tau}
xt=z,xτ+1=Axτ+Buτ。则有一下几个性质:
- V t ( z ) V_t(z) Vt(z)即为从 t t t时刻,初始状态为 z z z开始的LQR代价函数;
- V 0 ( x 0 ) V_0(x_0) V0(x0)为系统LQR代价函数;
- 可以证明 V t V_t Vt可以写成二次型形式,即 V t ( z ) = z T P t z V_t(z)=z^TP_tz Vt(z)=zTPtz,并且有 P t = P t ≥ 0 P_t=P_t\geq0 Pt=Pt≥0;
- P t P_t Pt可以从 t = N t=N t=N开始反向递归求解;
- 最优控制 u u u可以用 P t P_t Pt表示。
假设我们知道
V
t
+
1
(
z
)
V_{t+1}(z)
Vt+1(z),需要选取
u
t
u_t
ut使得系统代价函数最小,
u
t
u_t
ut的选取会影响
u
t
T
R
u
t
u_t^TRu_t
utTRut,以及从下一个时刻开始的代价函数
V
t
+
1
(
A
z
+
B
u
t
)
V_{t+1}(Az+Bu_t)
Vt+1(Az+But)。
动态规划基本公式:
V
t
(
z
)
=
m
i
n
w
(
z
T
Q
z
+
w
T
R
w
+
V
t
+
1
(
A
z
+
B
w
)
)
V_t(z)=\mathop{min}\limits_{w}(z^TQz+w^TRw+V_{t+1}(Az+Bw))
Vt(z)=wmin(zTQz+wTRw+Vt+1(Az+Bw))
w
w
w即为使得
V
t
(
z
)
V_t(z)
Vt(z)取最小值的
u
t
u_t
ut。
根据上面的第三条性质,有:
V
t
+
1
(
A
z
+
B
w
)
=
(
A
z
+
B
w
)
T
P
t
+
1
(
A
z
+
B
w
)
V_{t+1}(Az+Bw)=(Az+Bw)^TP_{t+1}(Az+Bw)
Vt+1(Az+Bw)=(Az+Bw)TPt+1(Az+Bw)
代入上式可得:
V
t
(
z
)
=
m
i
n
w
(
z
T
Q
z
+
w
T
R
w
+
(
A
z
+
B
w
)
T
P
t
+
1
(
A
z
+
B
w
)
)
V_t(z)=\mathop{min}\limits_{w}(z^TQz+w^TRw+(Az+Bw)^TP_{t+1}(Az+Bw))
Vt(z)=wmin(zTQz+wTRw+(Az+Bw)TPt+1(Az+Bw))
同时也可以证明该问题为凸优化,最小值取在导数为0处。
d
V
t
d
w
=
2
w
T
R
+
2
(
A
z
+
B
w
)
T
P
t
+
1
B
=
0
\frac{dV_t}{dw}=2w^TR+2(Az+Bw)^TP_{t+1}B=0
dwdVt=2wTR+2(Az+Bw)TPt+1B=0
可得:
w
∗
=
−
(
R
+
B
T
P
t
+
1
B
)
−
1
B
T
P
t
+
1
A
z
w^*=-(R+B^TP_{t+1}B)^{-1}B^TP_{t+1}Az
w∗=−(R+BTPt+1B)−1BTPt+1Az
则有:
V
t
(
z
)
=
z
T
Q
z
+
w
∗
T
R
w
∗
+
(
A
z
+
B
w
∗
)
T
P
t
+
1
(
A
z
+
B
w
∗
)
=
⋯
=
z
T
(
Q
+
A
T
P
t
+
1
A
−
A
T
P
t
+
1
B
(
R
+
B
T
P
t
+
1
B
)
−
1
B
T
P
t
+
1
A
)
z
=
z
T
P
t
z
\begin{aligned} V_t(z) &= z^TQz+w^{*T}Rw^*+(Az+Bw^*)^TP_{t+1}(Az+Bw^*) \\ &= \cdots \\ &= z^T(Q+A^TP_{t+1}A-A^TP_{t+1}B(R+B^TP_{t+1}B)^{-1}B^TP_{t+1}A)z \\ &= z^TP_tz \end{aligned}
Vt(z)=zTQz+w∗TRw∗+(Az+Bw∗)TPt+1(Az+Bw∗)=⋯=zT(Q+ATPt+1A−ATPt+1B(R+BTPt+1B)−1BTPt+1A)z=zTPtz
所以:
P
t
=
Q
+
A
T
P
t
+
1
A
−
A
T
P
t
+
1
B
(
R
+
B
T
P
t
+
1
B
)
−
1
B
T
P
t
+
1
A
P_t = Q+A^TP_{t+1}A-A^TP_{t+1}B(R+B^TP_{t+1}B)^{-1}B^TP_{t+1}A
Pt=Q+ATPt+1A−ATPt+1B(R+BTPt+1B)−1BTPt+1A
同时又有
P
N
=
Q
f
P_N=Q_f
PN=Qf,所以可以根据时间序列反向求解
P
N
−
1
,
P
N
−
2
,
⋯
,
P
0
P_{N-1},P_{N-2},\cdots,P_0
PN−1,PN−2,⋯,P0,根据
w
∗
w^*
w∗表达式可以顺序求解
u
t
l
q
r
u_t^{lqr}
utlqr。动态规划算法总结如下:
- 令 P N = Q f P_N=Q_f PN=Qf;
- 对于 t = N , ⋯ , 1 t=N,\cdots,1 t=N,⋯,1, P t − 1 = Q + A T P t A − A T P t B ( R + B T P t B ) − 1 B T P t A P_{t-1}=Q+A^TP_{t}A-A^TP_{t}B(R+B^TP_{t}B)^{-1}B^TP_{t}A Pt−1=Q+ATPtA−ATPtB(R+BTPtB)−1BTPtA
- 对于 t = 0 , ⋯ , N − 1 t=0,\cdots,N-1 t=0,⋯,N−1,定义 K t = ( R + B T P t + 1 B ) − 1 B T P t + 1 A K_t=(R+B^TP_{t+1}B)^{-1}B^TP_{t+1}A Kt=(R+BTPt+1B)−1BTPt+1A
- 对于 t = 0 , ⋯ , N − 1 t=0,\cdots,N-1 t=0,⋯,N−1,最优控制为: u t l q r = K t x t u_t^{lqr}=K_tx_t utlqr=Ktxt
1.5 动态规划算法实现
问题描述:
两自由度,单输入单输出系统:
x
t
+
1
=
[
1
1
0
1
]
x
t
+
[
0
1
]
u
t
,
y
t
=
[
1
0
]
x
t
x_{t+1}=\begin{bmatrix} 1 & 1\\ 0 &1 \end{bmatrix}x_t+\begin{bmatrix}0 \\1 \end{bmatrix}u_t,\ y_t=\begin{bmatrix} 1 & 0 \end{bmatrix}x_t
xt+1=[1011]xt+[01]ut, yt=[10]xt
初始状态
x
0
=
(
1
,
0
)
,
N
=
20
x_0=(1, 0), N=20
x0=(1,0),N=20,权重矩阵:
Q
=
Q
f
=
C
T
C
,
R
=
ρ
I
Q=Q_f=C^TC, R=\rho I
Q=Qf=CTC,R=ρI,可取
ρ
1
=
0.3
,
ρ
2
=
10
\rho_1=0.3, \rho_2=10
ρ1=0.3,ρ2=10。
clear;clc;
close all;
A = [1,1;0,1];
B = [0;1];
C = [1,0];
x0 = [1;0];
N = 20;
Q = C'*C;
Q_f = Q;
rho = 0.3;
R = rho*eye(size(B, 2));
P = zeros(2, 2, N);
P(:,:,N) = Q_f;
for i = N-1:-1:1
P(:,:,i) = Q+A'*P(:,:,i+1)*A-A'*P(:,:,i+1)*B/(R+B'*P(:,:,i+1)*B)*B'*P(:,:,i+1)*A;
end
K = zeros(1, 2, N);
u = zeros(1,N);
x = zeros(2, N);
x(:, 1) = x0;
y = zeros(1, N);
for i = 1:1:N-1
K(:, :, i) = -(R+B'*P(:,:,i+1)*B)\B'*P(:,:,i+1)*A;
u(i) = K(:,:,i)*x(:,i);
x(:, i+1) = A*x(:, i)+B*u(i);
y(i) = C*x(:, i);
end
figure(1);
subplot(2,2,1);
plot(u, '-ob');
hold on;grid on;
subplot(2,2,3);
plot(y, '-ob');
hold on;grid on;
K1 = reshape(K(1,1,:), 1, N);
K2 = reshape(K(1,2,:), 1, N);
subplot(2,2,2);
hold on;grid on;
plot(K1, '-b');
ylabel('K1');
subplot(2,2,4);
hold on;grid on;
plot(K2, '-b');
ylabel('K2');
%%
rho = 10;
R = rho*eye(size(B, 2));
P = zeros(2, 2, N);
P(:,:,N) = Q_f;
for i = N-1:-1:1
P(:,:,i) = Q+A'*P(:,:,i+1)*A-A'*P(:,:,i+1)*B/(R+B'*P(:,:,i+1)*B)*B'*P(:,:,i+1)*A;
end
K = zeros(1, 2, N);
u = zeros(1,N);
x = zeros(2, N);
x(:, 1) = x0;
y = zeros(1, N);
for i = 1:1:N-1
K(:, :, i) = -(R+B'*P(:,:,i+1)*B)\B'*P(:,:,i+1)*A;
u(i) = K(:,:,i)*x(:,i);
x(:, i+1) = A*x(:, i)+B*u(i);
y(i) = C*x(:, i);
end
figure(1);
subplot(2,2,1);
plot(u, '-*r');
ylabel('u');
hold on;grid on;
legend('\rho = 0.3', '\rho = 10');
subplot(2,2,3);
plot(y, '-*r');
ylabel('y');
hold on;grid on;
legend('\rho = 0.3', '\rho = 10');
K1 = reshape(K(1,1,:), 1, N);
K2 = reshape(K(1,2,:), 1, N);
subplot(2,2,2);
hold on;grid on;
plot(K1, '-r');
ylabel('K1');
legend('\rho = 0.3', '\rho = 10');
subplot(2,2,4);
hold on;grid on;
plot(K2, '-r');
ylabel('K2');
legend('\rho = 0.3', '\rho = 10');
运行结果如下:
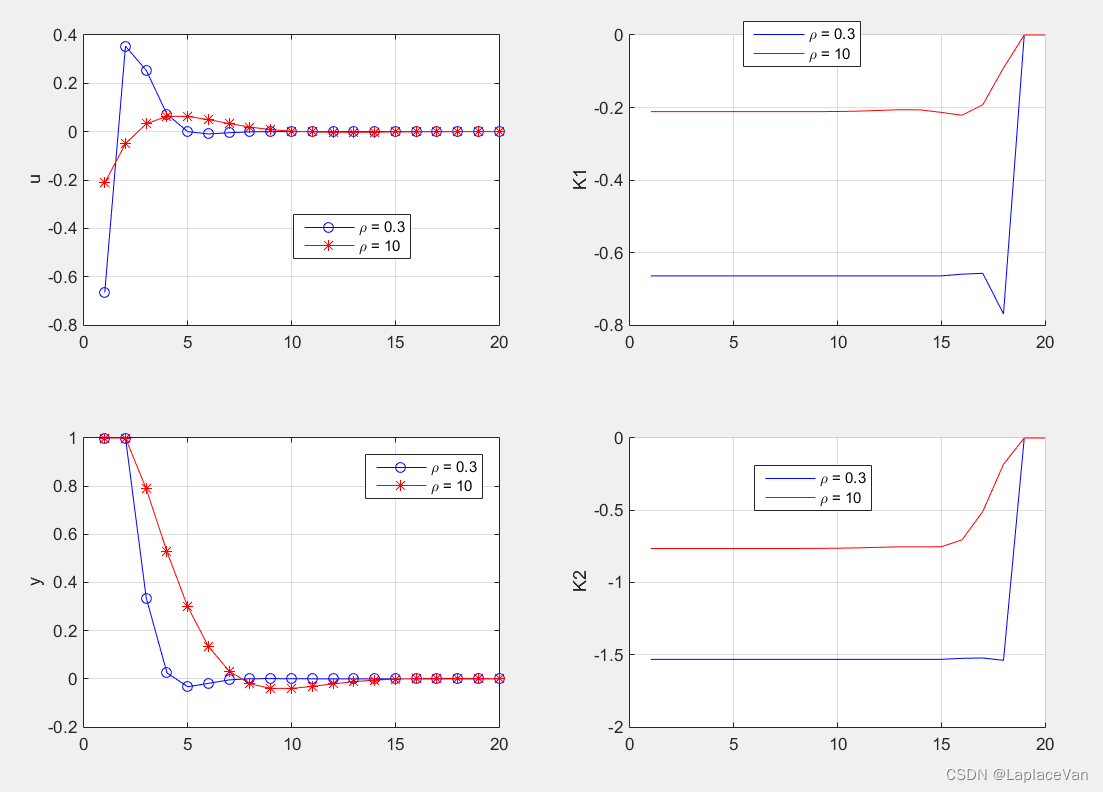
从上图结果可以发现,
K
t
K_t
Kt从
t
=
0
t=0
t=0开始一段时间内为恒定值,或者说
P
t
P_t
Pt从
N
N
N反向开始后很快就能收敛到恒定值。
即有:
P
s
s
=
Q
+
A
T
P
s
s
A
−
A
T
P
s
s
B
(
R
+
B
T
P
s
s
B
)
−
1
B
T
P
s
s
A
P_{ss} = Q+A^TP_{ss}A-A^TP_{ss}B(R+B^TP_{ss}B)^{-1}B^TP_{ss}A
Pss=Q+ATPssA−ATPssB(R+BTPssB)−1BTPssA
同时说明,对于不是很接近最终时刻的
t
t
t时刻,LQR控制可以看作是一个线性定常反馈系统:
u
t
=
K
s
s
x
t
,
K
s
s
=
−
(
R
+
B
T
P
s
s
B
)
−
1
B
T
P
s
s
u_t = K_{ss}x_t, K_{ss} = -(R+B^TP_{ss}B)^{-1}B^TP_{ss}
ut=Kssxt,Kss=−(R+BTPssB)−1BTPss
这在实际中经常用到。
另外讲义中也提到,最终态的权重矩阵对反馈增益没有影响,即
P
t
P_t
Pt的初始值对其收敛值没有影响:
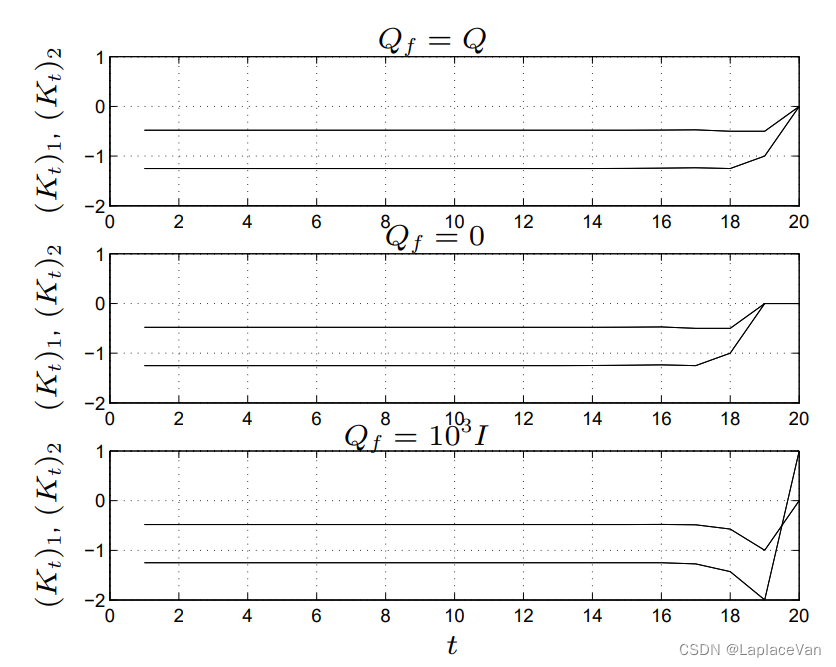
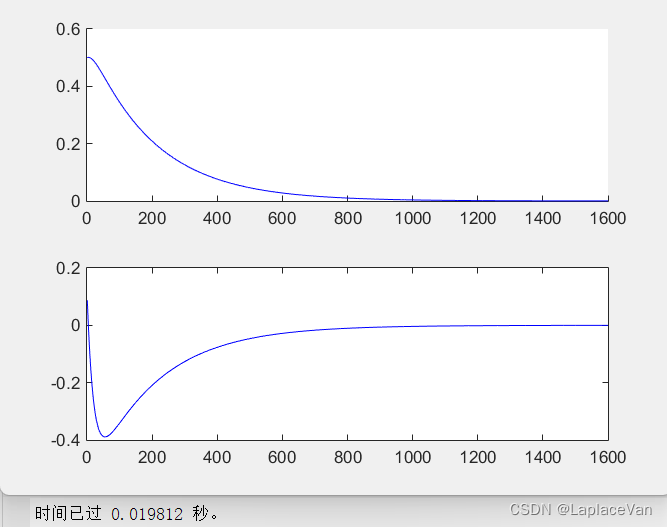
另外用DP方法求解第一个问题耗时不超过0.02s。
2 拉格朗日乘子法求解LQR
2.1 一些实用的矩阵特征
(1)
Z
(
I
+
Z
)
−
1
=
I
−
(
I
+
Z
)
−
1
Z(I+Z)^{-1}=I-(I+Z)^{-1}
Z(I+Z)−1=I−(I+Z)−1
其中
(
I
+
Z
)
(I+Z)
(I+Z)可逆。证明右边同乘
(
I
+
Z
)
(I+Z)
(I+Z)即可。
(2)
(
I
+
X
Y
)
−
1
=
I
−
X
(
I
+
Y
X
)
−
1
Y
(I+XY)^{-1}=I-X(I+YX)^{-1}Y
(I+XY)−1=I−X(I+YX)−1Y
证明:
(
I
−
X
(
I
+
Y
X
)
−
1
Y
)
(
I
+
X
Y
)
=
I
+
X
Y
−
X
(
I
+
Y
X
)
−
1
Y
(
I
+
X
Y
)
=
I
+
X
Y
−
X
(
I
+
Y
X
)
−
1
(
I
+
Y
X
)
Y
=
I
+
X
Y
−
X
Y
=
I
\begin{aligned}(I-X(I+YX)^{-1}Y)(I+XY) &= I+XY-X(I+YX)^{-1}Y(I+XY)\\ &= I+XY-X(I+YX)^{-1}(I+YX)Y\\ &= I+XY-XY=I \end{aligned}
(I−X(I+YX)−1Y)(I+XY)=I+XY−X(I+YX)−1Y(I+XY)=I+XY−X(I+YX)−1(I+YX)Y=I+XY−XY=I
(3)
Y
(
I
+
X
Y
)
−
1
=
(
I
+
Y
X
)
−
1
Y
Y(I+XY)^{-1}=(I+YX)^{-1}Y
Y(I+XY)−1=(I+YX)−1Y
证明左乘
(
I
+
Y
X
)
(I+YX)
(I+YX)右乘
(
I
+
X
Y
)
(I+XY)
(I+XY)即可。速记:左边
Y
Y
Y移进去,右边
Y
Y
Y移出来。
(4)
(
I
+
X
Z
−
1
Y
)
−
1
=
I
−
X
(
Z
+
Y
X
)
−
1
Y
(I+XZ^{-1}Y)^{-1}=I-X(Z+YX)^{-1}Y
(I+XZ−1Y)−1=I−X(Z+YX)−1Y
证明直接使用公式(2)即可。
(5)
(
A
+
B
C
)
−
1
=
A
−
1
−
A
−
1
B
(
I
+
C
A
−
1
B
)
−
1
C
A
−
1
(A+BC)^{-1}=A^{-1}-A^{-1}B(I+CA^{-1}B)^{-1}CA^{-1}
(A+BC)−1=A−1−A−1B(I+CA−1B)−1CA−1
证明:
(
A
+
B
C
)
−
1
=
(
A
(
I
+
A
−
1
B
C
)
)
−
1
=
(
I
+
A
−
1
B
C
)
−
1
A
−
1
=
(
I
−
A
−
1
B
(
I
+
C
A
−
1
B
)
−
1
C
)
A
−
1
(
使
用
公
式
(
2
)
)
=
A
−
1
−
A
−
1
B
(
I
+
C
A
−
1
B
)
−
1
C
A
−
1
\begin{aligned}(A+BC)^{-1}&=(A(I+A^{-1}BC))^{-1}\\ &=(I+A^{-1}BC)^{-1}A^{-1}\\ &=(I-A^{-1}B(I+CA^{-1}B)^{-1}C)A^{-1} (使用公式(2))\\ &=A^{-1}-A^{-1}B(I+CA^{-1}B)^{-1}CA^{-1} \end{aligned}
(A+BC)−1=(A(I+A−1BC))−1=(I+A−1BC)−1A−1=(I−A−1B(I+CA−1B)−1C)A−1(使用公式(2))=A−1−A−1B(I+CA−1B)−1CA−1
(6)根据之前关于
P
t
P_t
Pt的表达式可以进行化简:
P
t
=
Q
+
A
T
P
t
+
1
A
−
A
T
P
t
+
1
B
(
R
+
B
T
P
t
+
1
B
)
−
1
B
T
P
t
+
1
A
=
Q
+
A
T
P
t
+
1
(
I
−
B
(
R
+
B
T
P
t
+
1
B
)
−
1
B
T
P
t
+
1
)
A
=
Q
+
A
T
P
t
+
1
(
I
−
B
(
(
I
+
B
T
P
t
+
1
B
R
−
1
)
R
)
−
1
B
T
P
t
+
1
)
A
=
Q
+
A
T
P
t
+
1
(
I
−
B
R
−
1
(
I
+
B
T
P
t
+
1
B
R
−
1
)
−
1
B
T
P
t
+
1
)
A
=
Q
+
A
T
P
t
+
1
(
I
+
B
R
−
1
B
T
P
t
+
1
)
−
1
A
(
使
用
公
式
(
2
)
)
=
Q
+
A
T
(
I
+
P
t
+
1
B
R
−
1
B
T
)
−
1
P
t
+
1
A
\begin{aligned}P_t &= Q+A^TP_{t+1}A-A^TP_{t+1}B(R+B^TP_{t+1}B)^{-1}B^TP_{t+1}A\\ &=Q+A^TP_{t+1}(I-B(R+B^TP_{t+1}B)^{-1}B^TP_{t+1})A\\ &=Q+A^TP_{t+1}(I-B((I+B^TP_{t+1}BR^{-1})R)^{-1}B^TP_{t+1})A\\ &=Q+A^TP_{t+1}(I-BR^{-1}(I+B^TP_{t+1}BR^{-1})^{-1}B^TP_{t+1})A\\ &=Q+A^TP_{t+1}(I+BR^{-1}B^TP_{t+1})^{-1}A(使用公式(2))\\ &=Q+A^T(I+P_{t+1}BR^{-1}B^T)^{-1}P_{t+1}A \end{aligned}
Pt=Q+ATPt+1A−ATPt+1B(R+BTPt+1B)−1BTPt+1A=Q+ATPt+1(I−B(R+BTPt+1B)−1BTPt+1)A=Q+ATPt+1(I−B((I+BTPt+1BR−1)R)−1BTPt+1)A=Q+ATPt+1(I−BR−1(I+BTPt+1BR−1)−1BTPt+1)A=Q+ATPt+1(I+BR−1BTPt+1)−1A(使用公式(2))=Q+AT(I+Pt+1BR−1BT)−1Pt+1A
2.2 线性约束最优化问题
m i n f ( x ) s . t . : F x = g \begin{aligned}min\enspace &f(x)\\ s.t.:\enspace &Fx=g \end{aligned} mins.t.:f(x)Fx=g
- f : R n → R f:\mathbf R^n \rightarrow \mathbf {R} f:Rn→R
- F ∈ R m × n F\in \mathbf R^{m\times n} F∈Rm×n
拉格朗日表达式:
L
(
x
,
λ
)
=
f
(
x
)
+
λ
T
(
g
−
F
x
)
L(x,\lambda)=f(x)+\lambda ^T(g-Fx)
L(x,λ)=f(x)+λT(g−Fx)
其中,
λ
\lambda
λ为拉格朗日乘子。若
x
x
x是最优解,则有:
∇
x
L
=
∇
f
(
x
)
−
F
T
λ
=
0
,
∇
λ
L
=
g
−
F
x
=
0
\nabla _xL=\nabla f(x)-F^T\lambda = 0, \enspace \nabla _\lambda L=g-Fx=0
∇xL=∇f(x)−FTλ=0,∇λL=g−Fx=0
即
∇
f
(
x
)
=
F
T
λ
\nabla f(x)=F^T\lambda
∇f(x)=FTλ
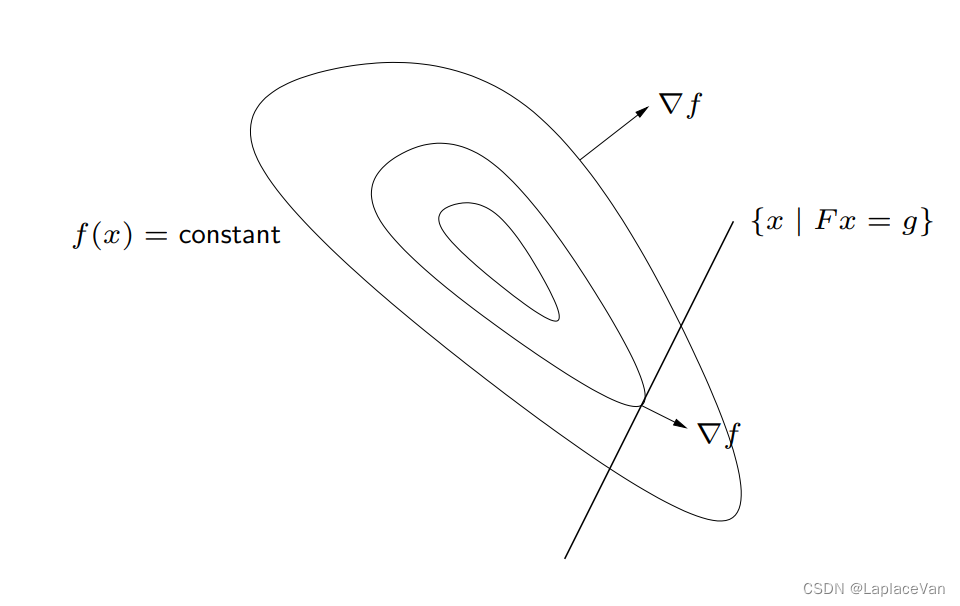
- 假设当前位置为 x x x,为可行点,即 F x = g Fx=g Fx=g;
- 考虑沿 v v v方向移动很小距离 h h h,到达 x + h v x+hv x+hv位置;
- 为了移动后仍为可行点,则需 F ( x + h v ) = g + h F v = g F(x+hv)=g+hFv=g F(x+hv)=g+hFv=g,即 F v = 0 Fv=0 Fv=0,所以 v ∈ N ( F ) v\in \Nu (F) v∈N(F),称为可行方向;
- 需要移动后得到更小目标函数: f ( x + h v ) ≈ f ( x ) + h ∇ f ( x ) T v < f ( x ) f(x+hv)\approx f(x)+h\nabla f(x)^Tv<f(x) f(x+hv)≈f(x)+h∇f(x)Tv<f(x)
当 ∇ f ( x ) T v < 0 \nabla f(x)^Tv<0 ∇f(x)Tv<0时,为目标函数下降方向。当存在下降方向时, x x x不为最优解,所以当 x x x为最优解时,应满足 ∇ f ( x ) T v = 0 \nabla f(x)^Tv=0 ∇f(x)Tv=0
2.3 LQR约束最优化求解
把LQR问题写成最优化问题:
m
i
n
J
=
1
2
∑
t
=
0
N
−
1
(
x
t
T
Q
x
t
+
u
t
T
R
u
t
)
+
1
2
x
N
T
Q
f
x
N
s
.
t
.
x
t
+
1
=
A
x
t
+
B
u
t
,
t
=
0
,
1
,
⋯
,
N
−
1
min \enspace J=\frac{1}{2}\sum_{t=0}^{N-1}(x_t^TQx_t+u_t^TRu_t)+\frac{1}{2}x_N^TQ_fx_N\\s.t. \enspace x_{t+1}=Ax_t+Bu_t, \enspace t=0,1,\cdots,N-1
minJ=21t=0∑N−1(xtTQxt+utTRut)+21xNTQfxNs.t.xt+1=Axt+But,t=0,1,⋯,N−1
则有拉格朗日表达式:
L
=
J
+
∑
t
=
0
N
−
1
λ
t
+
1
(
A
x
t
+
B
u
t
−
x
t
+
1
)
L=J+\sum_{t=0}^{N-1}\lambda _{t+1}(Ax_t+Bu_t-x_{t+1})
L=J+t=0∑N−1λt+1(Axt+But−xt+1)
则有:
∇
u
t
L
=
R
u
t
+
B
T
λ
t
+
1
=
0
,
u
t
=
−
R
−
1
B
T
λ
t
+
1
∇
x
t
L
=
Q
x
t
+
A
T
λ
t
+
1
−
λ
t
=
0
,
λ
t
=
A
T
λ
t
+
1
+
Q
x
t
∇
x
N
L
=
Q
f
x
N
−
λ
N
=
0
,
λ
N
=
Q
f
x
N
\nabla _{u_t}L=Ru_t+B^T\lambda_{t+1}=0,\enspace u_t=-R^{-1}B^T\lambda _{t+1}\\ \nabla _{x_t}L=Qx_t+A^T\lambda_{t+1}-\lambda_t=0, \enspace \lambda _t=A^T\lambda_{t+1}+Qx_t\\ \nabla _{x_N}L=Q_fx_N-\lambda_N=0, \enspace \lambda_N=Q_fx_N
∇utL=Rut+BTλt+1=0,ut=−R−1BTλt+1∇xtL=Qxt+ATλt+1−λt=0,λt=ATλt+1+Qxt∇xNL=QfxN−λN=0,λN=QfxN
对于原系统有:
x
t
+
1
=
A
x
t
+
B
u
t
,
x
0
=
x
i
n
i
t
x_{t+1}=Ax_t+Bu_t, \enspace x_0=x^{init}
xt+1=Axt+But,x0=xinit
迭代计算是从0时刻向后进行,初始条件为起始状态。
现在有:
λ
t
=
A
T
λ
t
+
1
+
Q
x
t
,
λ
N
=
Q
f
x
N
\lambda _t=A^T\lambda_{t+1}+Qx_t, \enspace \lambda _N=Q_fx_N
λt=ATλt+1+Qxt,λN=QfxN
迭代计算从
N
N
N时刻开始向前进行,初始条件为最终状态。
所以称
λ
\lambda
λ为伴随状态,上式也称为伴随系统的状态方程。
可以用归纳法证明
λ
t
=
P
t
x
t
\lambda_t=P_tx_t
λt=Ptxt:
对于
t
=
N
t=N
t=N,有
λ
N
=
Q
f
x
N
\lambda _N=Q_fx_N
λN=QfxN,现在假设
λ
t
+
1
=
P
t
+
1
x
t
+
1
\lambda_{t+1}=P_{t+1}x_{t+1}
λt+1=Pt+1xt+1成立,证明
λ
t
=
P
t
x
t
\lambda_t=P_tx_t
λt=Ptxt:
有:
λ
t
+
1
=
P
t
+
1
(
A
x
t
+
B
u
t
)
=
P
t
+
1
(
A
x
t
−
B
R
−
1
B
T
λ
t
+
1
)
\lambda_{t+1}=P_{t+1}(Ax_t+Bu_t)=P_{t+1}(Ax_t-BR^{-1}B^T\lambda _{t+1})
λt+1=Pt+1(Axt+But)=Pt+1(Axt−BR−1BTλt+1)
所以:
λ
t
+
1
=
(
I
+
P
t
+
1
B
R
−
1
B
T
)
−
1
P
t
+
1
A
x
t
\lambda _{t+1}=(I+P_{t+1}BR^{-1}B^T)^{-1}P_{t+1}Ax_t
λt+1=(I+Pt+1BR−1BT)−1Pt+1Axt
所以:
λ
t
=
A
T
λ
t
+
1
+
Q
x
t
=
A
T
(
I
+
P
t
+
1
B
R
−
1
B
T
)
−
1
P
t
+
1
A
x
t
+
Q
x
t
=
P
t
x
t
\lambda _t=A^T\lambda_{t+1}+Qx_t=A^T(I+P_{t+1}BR^{-1}B^T)^{-1}P_{t+1}Ax_t+Qx_t=P_tx_t
λt=ATλt+1+Qxt=AT(I+Pt+1BR−1BT)−1Pt+1Axt+Qxt=Ptxt
其中
P
t
=
Q
+
A
T
(
I
+
P
t
+
1
B
R
−
1
B
T
)
−
1
P
t
+
1
A
P_t=Q+A^T(I+P_{t+1}BR^{-1}B^T)^{-1}P_{t+1}A
Pt=Q+AT(I+Pt+1BR−1BT)−1Pt+1A与之前化简后结果一致。
持续更新中…














 2378
2378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









