









抓取腾讯新闻思路:
- selenium模拟浏览器操作
- BeautlfulSoup解析
- 存储数据
1.导入相关模块
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
import time
2.打开chromedriver
url = 'https://news.qq.com/'
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get(url=url)
3.设置滚动条
js="window.scrollTo(0,document.body.scrollHeight)"
简单介绍下
-
window.scroll(x,y)是让window滚动条滚动到那个x,y坐标。//x是水平坐标,y是垂直坐标。
-
window.scrollBy(-x,-y)是让window滚动条相对滚动到某个坐标,- 10即相对向左/向上滚动10像素。
-
window.scrollTo(x,y)和window.scroll(x,y)一样。
4.滚动条下滑到定位的元素
当页面上的元素超过一屏后,想操作屏幕下方的元素,是不能直接定位到。这时候需要借助滚动条来拖动屏幕,使被操作的元素显示在当前的屏幕上。滚动条无法直接用定位工具来定位selenium里面也没有直接的方法去控制滚动条,但是提供了一个操作js的方法:
execute_script(),可以直接执行js的脚本。
for i in range(5):
if i == 0:
nexta = driver.find_element_by_xpath('//*[@id="load-more"]')
driver.execute_script("arguments[0].scrollIntoView();", nexta)
time.sleep(0.5)
5.解析页面
可以看到新闻包含在ul.list中
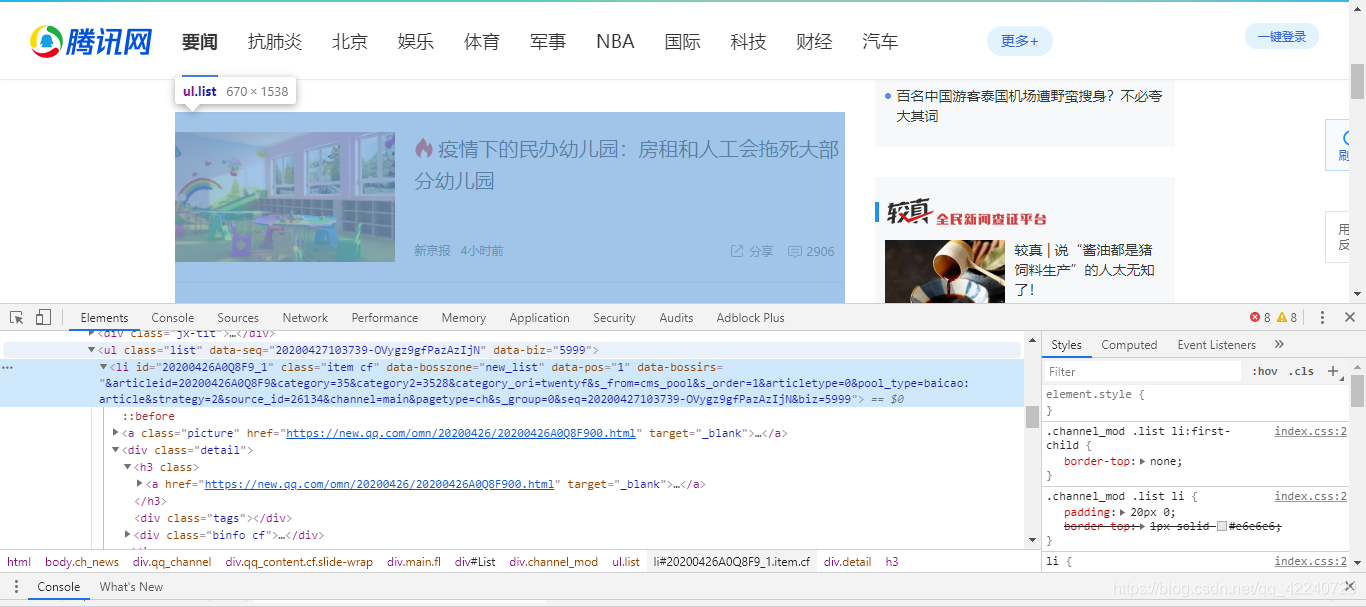
html=BeautifulSoup(driver.page_source,'lxml')
lis = html.select(r"ul.list")[1]
6.遍历标签输出结果
i = 1
for li in lis:
try:
name = li.select_one("div.detail a").text
website = li.select_one("div.detail a")['href']
if i == 1:
data_dict = {'标题':[name],'地址':[website]}
data = pd.DataFrame(data_dict,columns = ['标题', '地址'])
i+=1
else:
data_dict = {'标题':name,'地址':website}
data = data.append(data_dict, ignore_index=True)
except:
pass
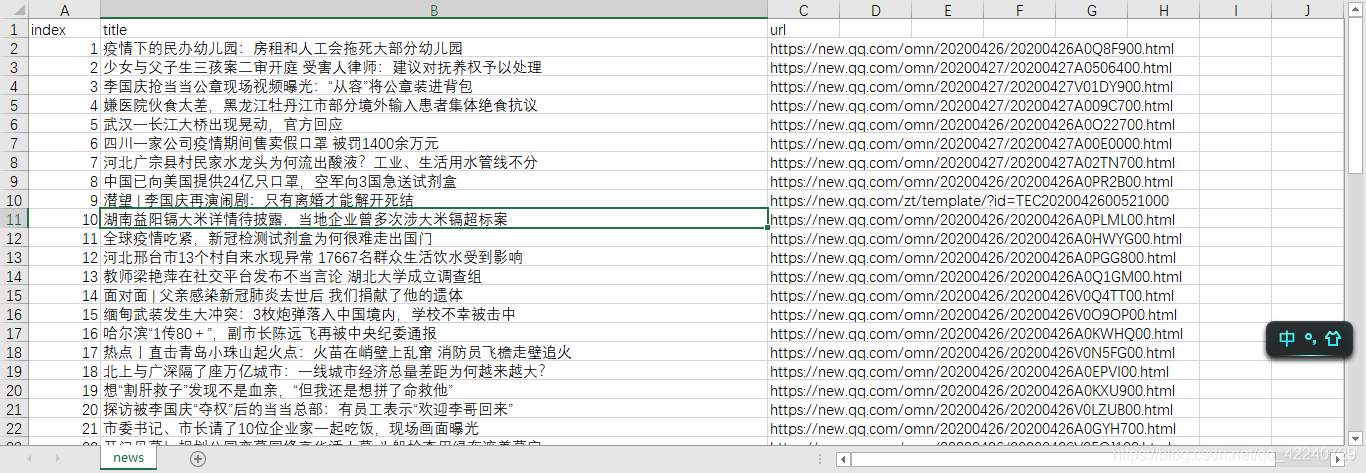
print(data)
print(‘Finish’)

7.输出结果
data.to_csv('test.csv')














 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









