







文章目录
搞这个的初衷一是想对时间序列预测结果进行交叉验证;二是想和prophet自带的交叉验证方法进行比较。
然而sklearn自带的时序交叉验证包并不是那么好用,不太灵活,就决定自己写一个。
1. 时间序列特定的交叉验证方法简介
时间序列不能采用一般的K-FOLD校验,具体的原理可以看机器之心翻译的这篇文章:
时间序列一般采用递增时间窗交叉验证法,如下图所示:
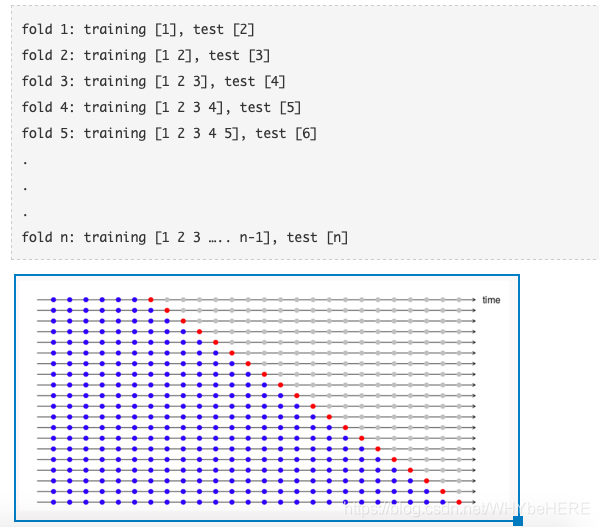
2. sklearn时间序列交叉验证包TimeSeriesSplit
sklearn.model_selection.TimeSeriesSplit的包默认为递增窗口交叉验证。
官方doc及sample如下:
class sklearn.model_selection.TimeSeriesSplit(n_splits=5, ***, max_train_size=None)
Parameters
-
n_splitsint, default=5
--把时间序列数据拆成几份Number of splits. Must be at least 2.Changed in version 0.22:
n_splitsdefault value changed from 3 to 5. -
max_train_sizeint, default=None
--限制每次training的大小。如果不设置,则默认从头开始训练(如上图所示);如果设置,就可以控制成固定的moving window。见下文的example。Maximum size for a single training set.
递增窗口交叉验证Example
>>> import numpy as np
>>> from sklearn.model_selection import TimeSeriesSplit
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([1, 2, 3, 4, 5, 6])
>>> tscv = TimeSeriesSplit()
>>> print(tscv)
TimeSeriesSplit(max_train_size=None, n_splits=5)
>>> for train_index, test_index in tscv.split(X):
... print("TRAIN:", train_index,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









