







一、前言
在 AI 大模型与智能协同的浪潮中,“数据传输” 早已无法承载智能时代的协作需求:模型间的孤立、工具调用的低效、生态协同的割裂,正成为制约 AI 生产力爆发的 “隐形天花板”。
MCP 协议(Model Context Protocol)的诞生,本质是一场对 “智能协作底层逻辑” 的重构—— 它不仅定义了模型间的通信语法(如 SSE 流式交互的极致优化),更通过架构解构(从传输层到语义层的穿透式设计),为 LLM 工具链的智能调用、多模态生态的无缝协同,打造了一套 “可进化的协作神经系统”。
上文咱们从MCP协议的背景和核心定义进行了基础介绍,现在咱们将以技术解剖刀 + 实战显微镜双视角,逐步拆解 MCP 的核心:
- 架构层:如何通过 “上下文协议” 打破模型间的 “信息孤岛”,让协同从 “数据搬运” 升级为 “智能共生”?
- 通信层:SSE 流式交互如何为实时协同(如 AIGC 创作、智能决策流)提供 “神经脉冲级” 的响应?
- 实战层:从官方代码示例到 LLM 工具选型逻辑,揭秘 MCP 如何让 “模型协作” 像 “搭积木” 一样简单?
当数据传输的 “旧基建” 遇上智能协同的 “新文明”,MCP 正在书写的,是一场关于 AI 生产力的 “底层革命”—— 请随笔者的镜头,从技术解构到实战落地,见证这场范式革命的每一个 “神经突触”。
二、MCP 架构解构
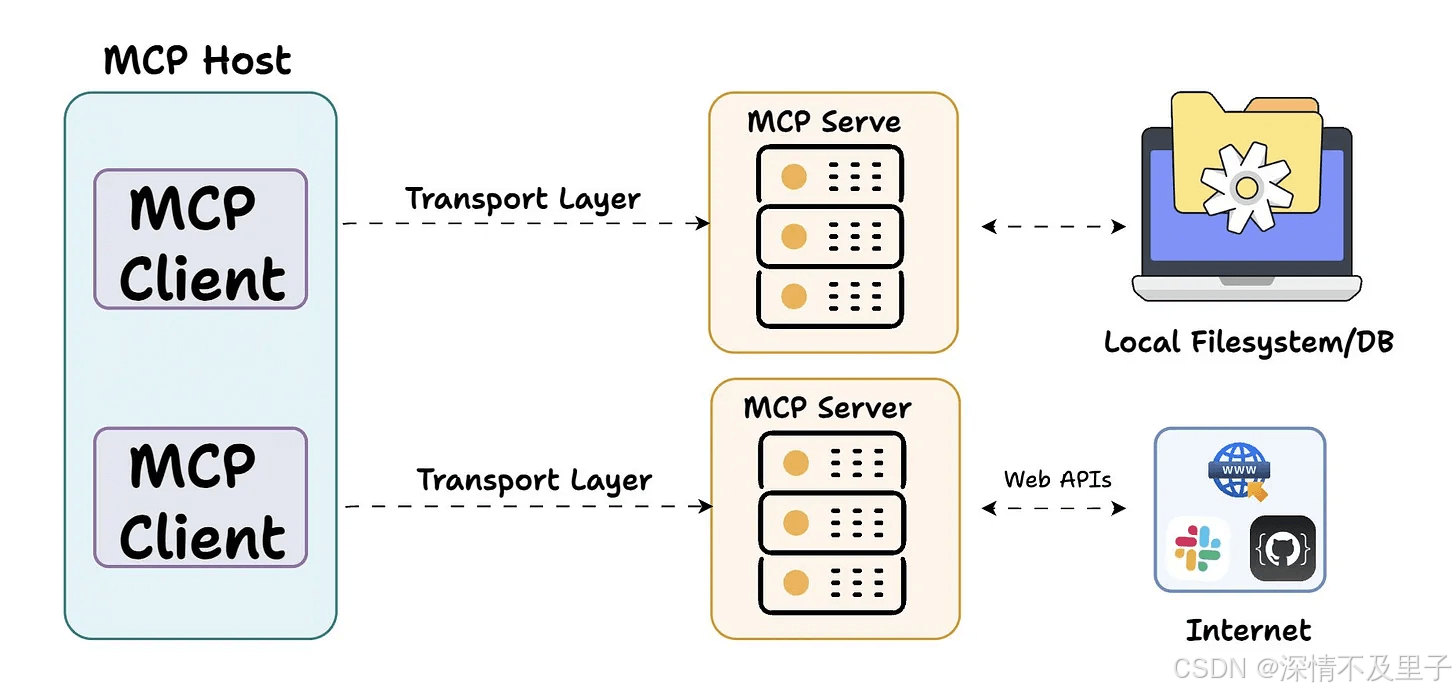
MCP的架构由三个核心功能组件构成:Host(主机)、Client(客户端)和 Server(服务器)。这三个组件通过标准化接口实现松耦合协作,形成高度模块化的技术架构。首先我们通过一个官方的介绍图来了解一下:
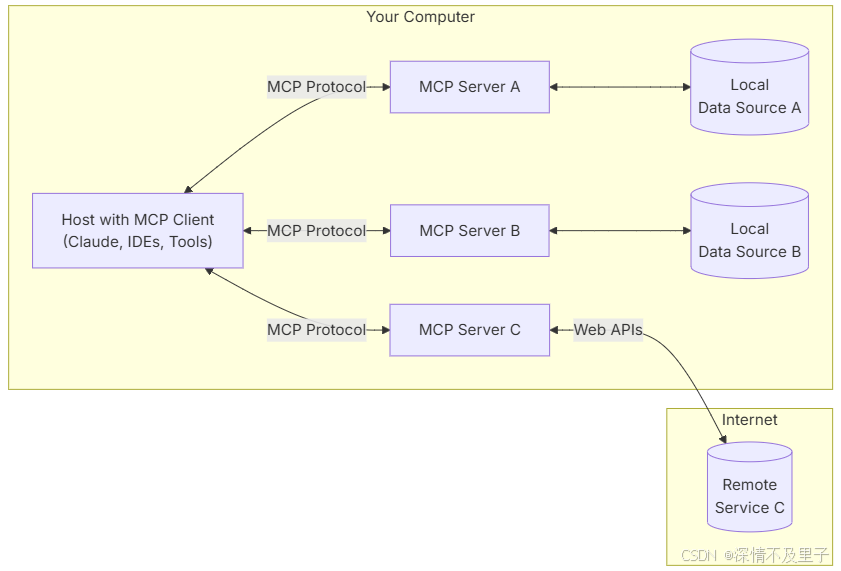
MCP Host作为运行 MCP 的核心应用程序,广泛应用于 Claude Desktop、Cursor、Cline 等 AI 工具中。它不仅为用户提供了与大型语言模型(LLM)交互的接口,还集成了 MCP Client 以实现与 MCP Server 的连接。
而MCP client 则是作为 LLM 与 MCP server 之间的通信桥梁,被嵌入在主机程序中,主要承担以下核心功能:
- 接收并处理来自 LLM 的请求
- 将请求精准路由至对应的 MCP server
- 将 MCP server 的处理结果及时反馈给 LLM
MCP Server作为MCP架构的核心组件,提供了一套专门设计的工具集,用于从本地数据源或远程服务中获取信息。
与传统的远程API服务器相比,MCP Server具备更灵活的部署方式:既可作为本地应用程序通过stdio模式在用户设备上运行,也能以SSE方式部署在远程服务器中,这点我们后面慢慢介绍。
我们用一个更详细的栗子来说明这些组件如何协同工作:假设我们正在使用 Claude Desktop (Host) 提出查询:"显示我桌面上所有.docx格式的文档"
具体流程如下:
-
用户交互阶段:
- 你在 Claude Desktop 界面输入查询
- Claude Desktop (Host) 接收并解析你的自然语言请求
-
模型处理阶段:
- Host 将请求发送给 Claude 语言模型
- Claude 分析后识别出需要访问本地文件系统
- 模型生成结构化指令:"获取桌面目录下所有扩展名为.docx的文件"
-
MCP 调用阶段:
- Host 内置的 MCP Client 被激活
- Client 通过标准协议连接文件系统 MCP Server
- 建立安全连接后,Client 发送具体请求参数:
{ "operation": "list_files", "path": "~/Desktop", "filter": { "extensions": [".docx"] } }
-
服务执行阶段:
- 文件系统 MCP Server 接收请求
- 执行实际的文件系统扫描操作
- 应用过滤条件,只获取.docx文件
- 准备响应数据,包括:
- 文件列表
- 每个文件的基本信息(大小、修改时间等)
- 操作状态码
-
结果返回阶段:
- Server 将结果返回给 Client
- Client 将数据转发给 Claude 模型
- 模型生成自然语言回复: "您桌面上有以下 Word 文档:
- 项目报告.docx (最后修改:2025-05-15)
- 会议纪要.docx (最后修改:2025-05-10)"
-
用户呈现阶段:
- Host 接收模型回复
- 在界面中美观地展示结果
- 可能附加操作按钮(如"打开文件")
架构优势体现:
- 安全隔离:文件访问通过专门的 Server 完成,Host 本身不直接接触文件系统
- 模块化设计:要支持新功能(如访问数据库),只需开发对应的 MCP Server
- 跨平台兼容:同一套 Host/Client 可连接不同操作系统的文件系统 Server
- 权限控制:Server 可实现精细的访问控制,比如只允许读取特定目录
这种设计模式类似于现代 IDE 的 Language Server Protocol,使得核心功能与扩展能力解耦,大大提高了系统的灵活性和可维护性。
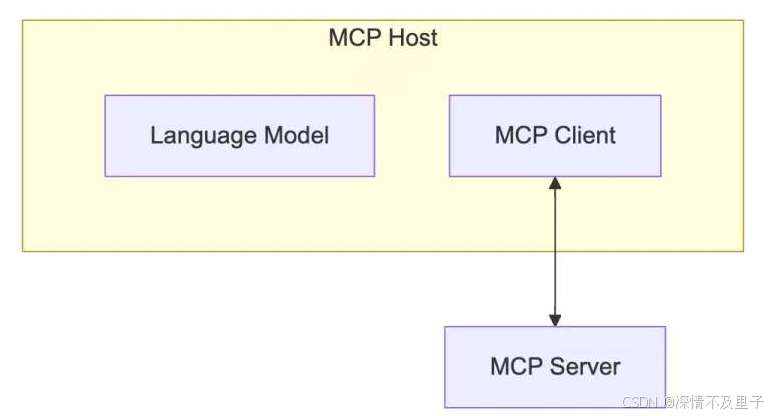
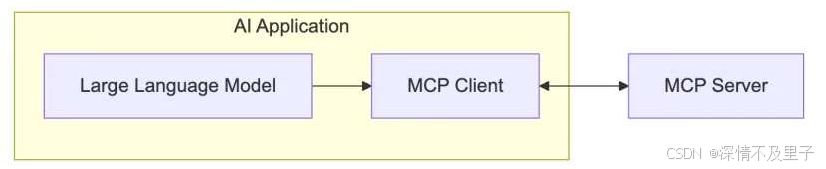
我们可以看一下更加细致的架构图示:
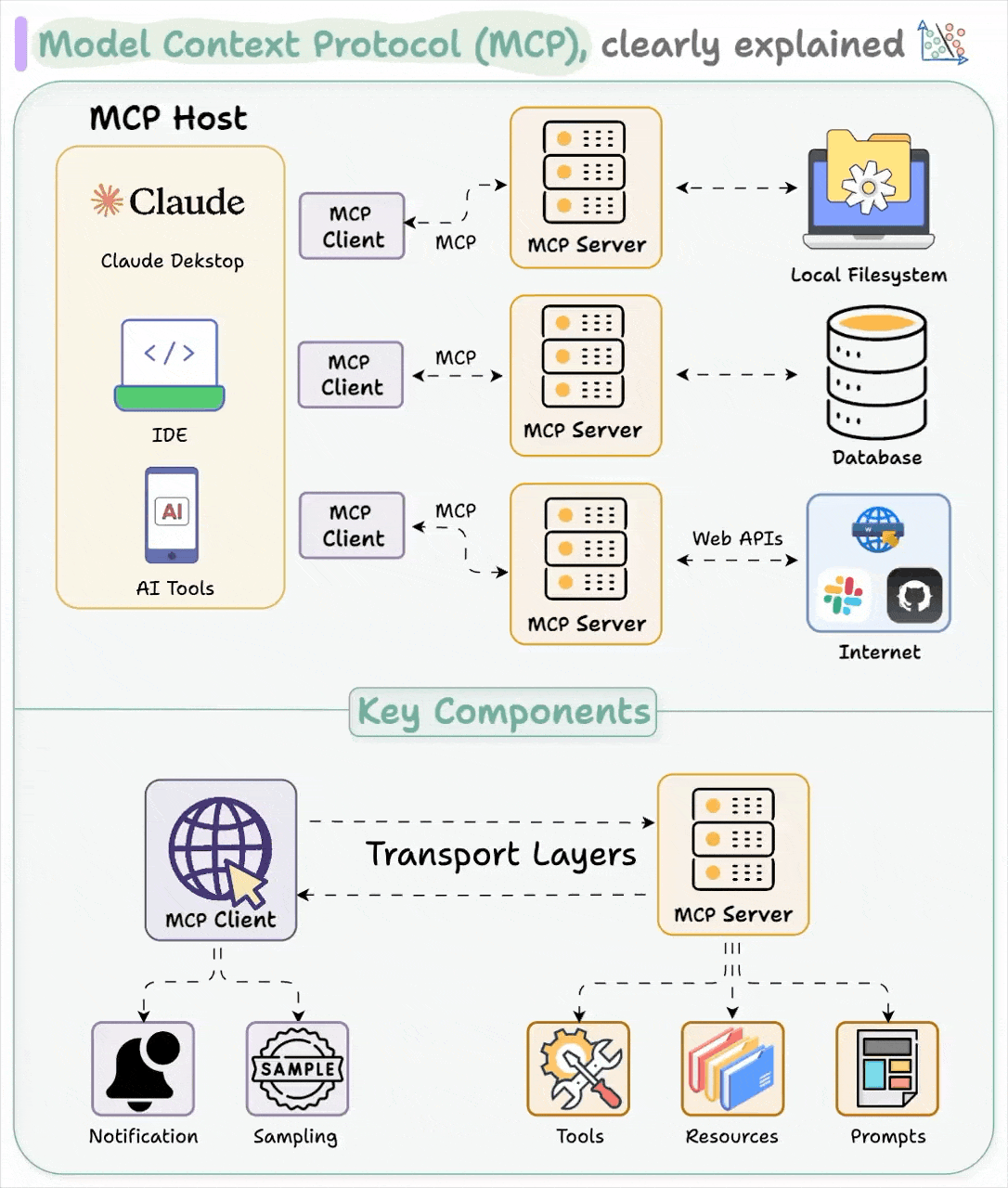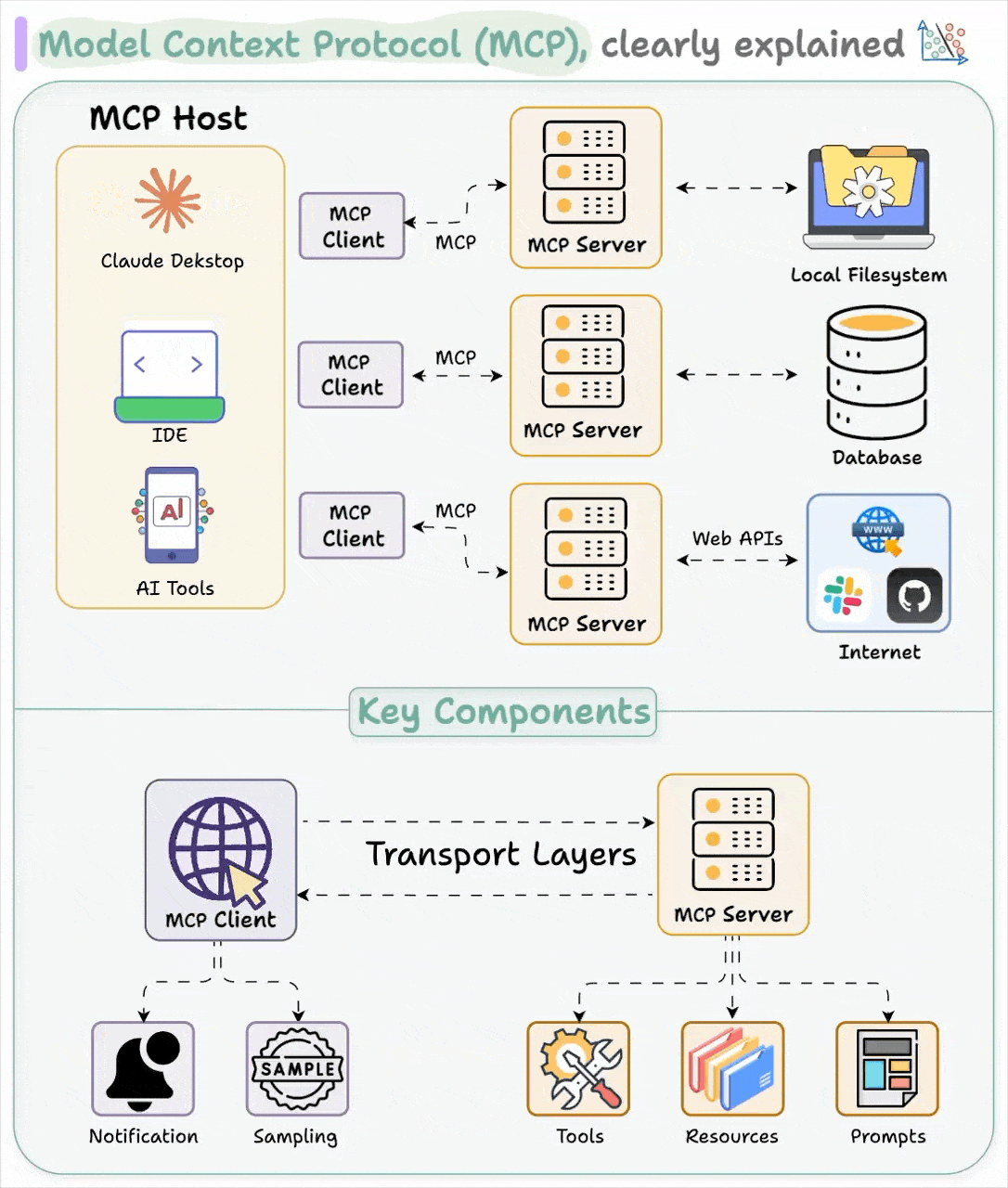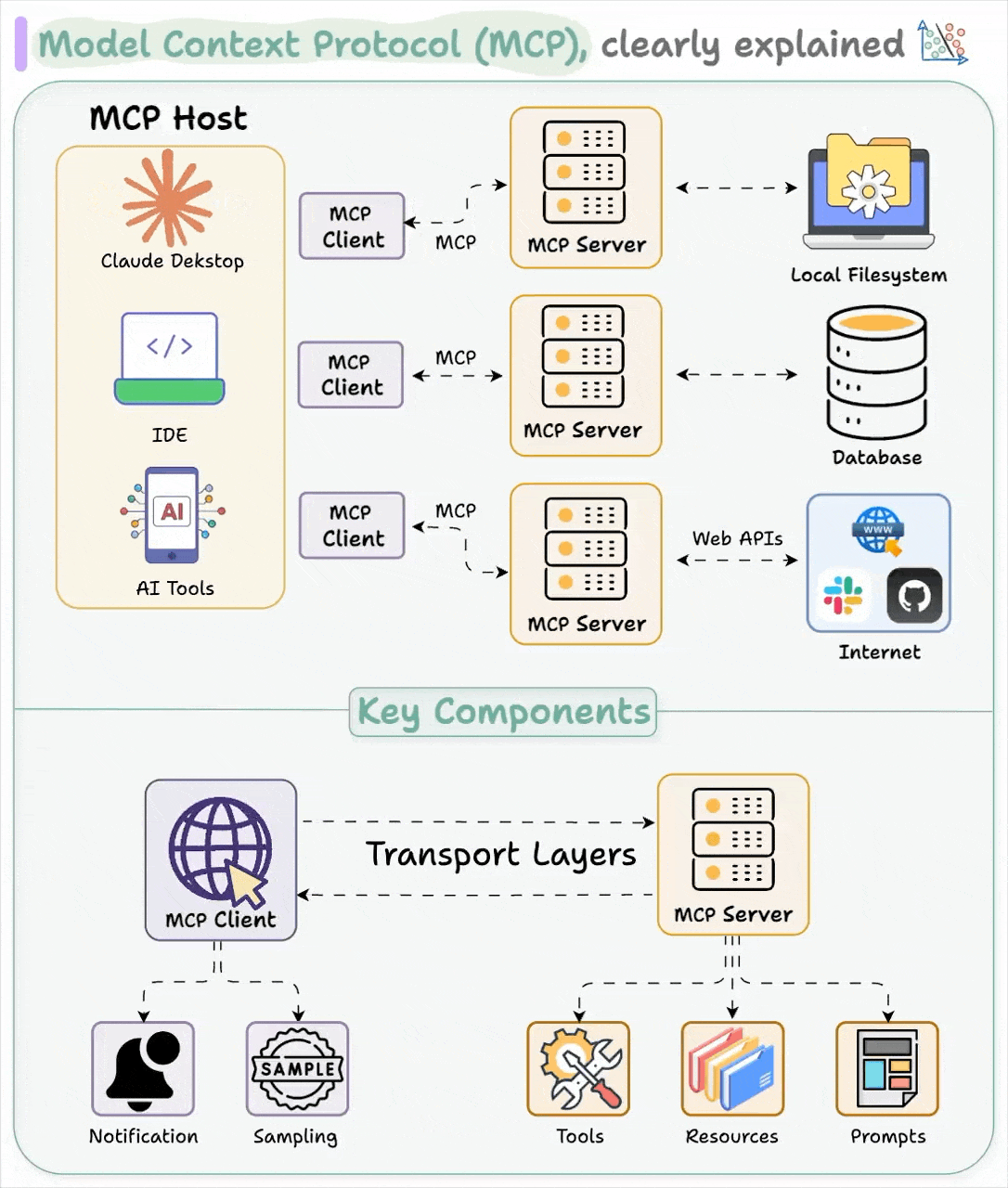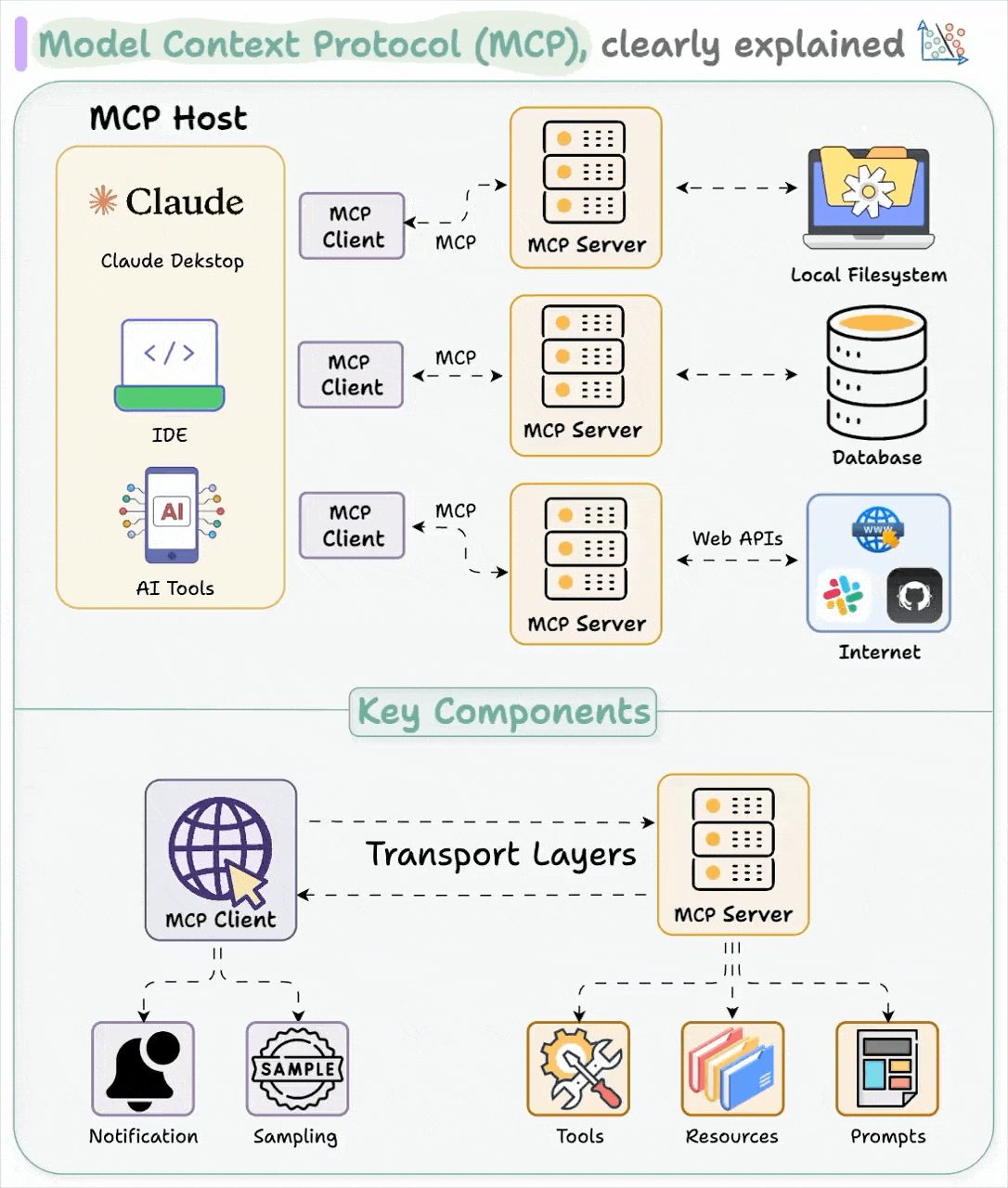
正如前文所述,MCP 堪称 AI 应用领域的 USB-C 接口。与 USB-C 为设备提供统一的外设连接方案类似,MCP 为 AI 应用实现了与各类数据源和工具的标准对接方式。
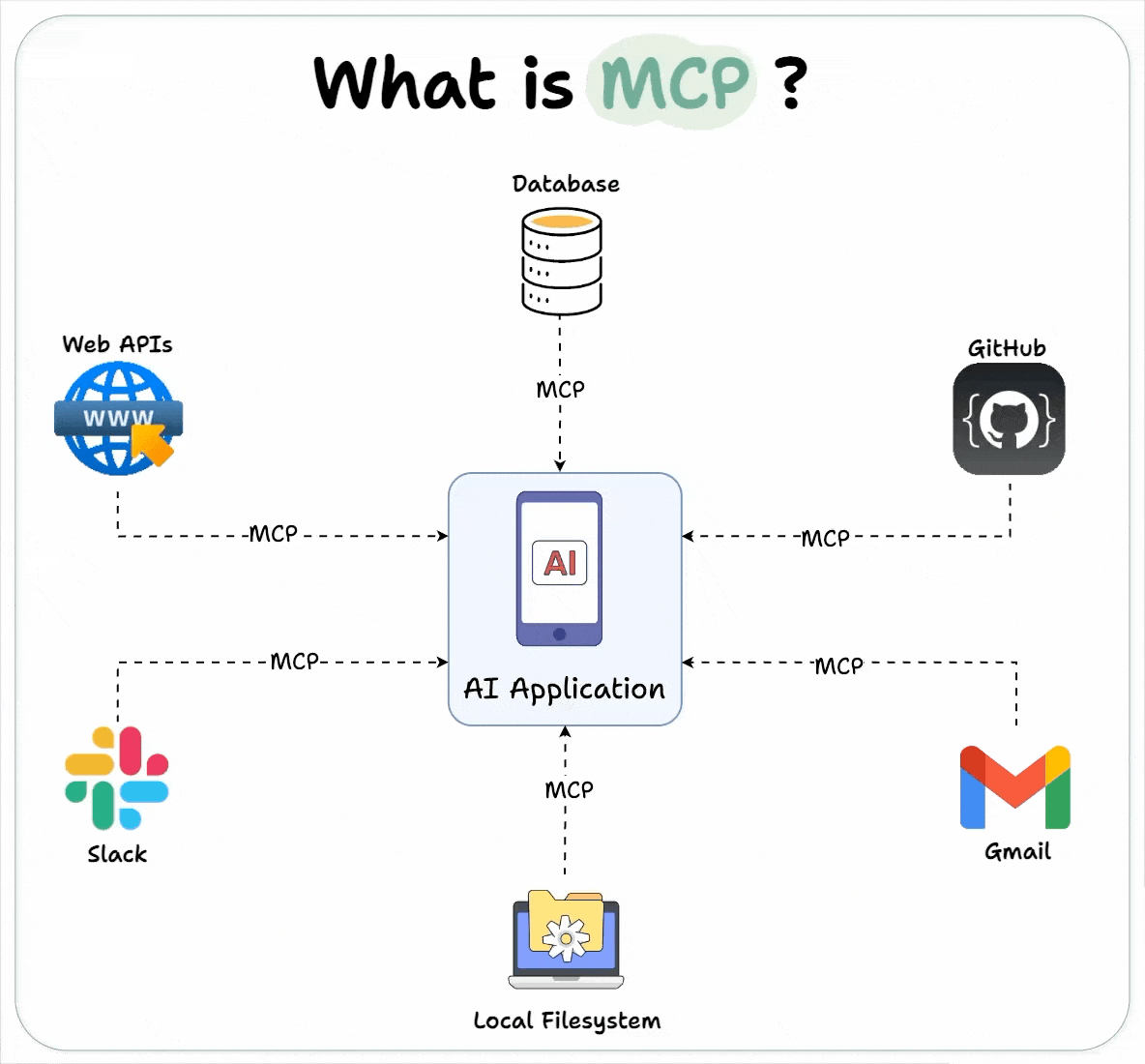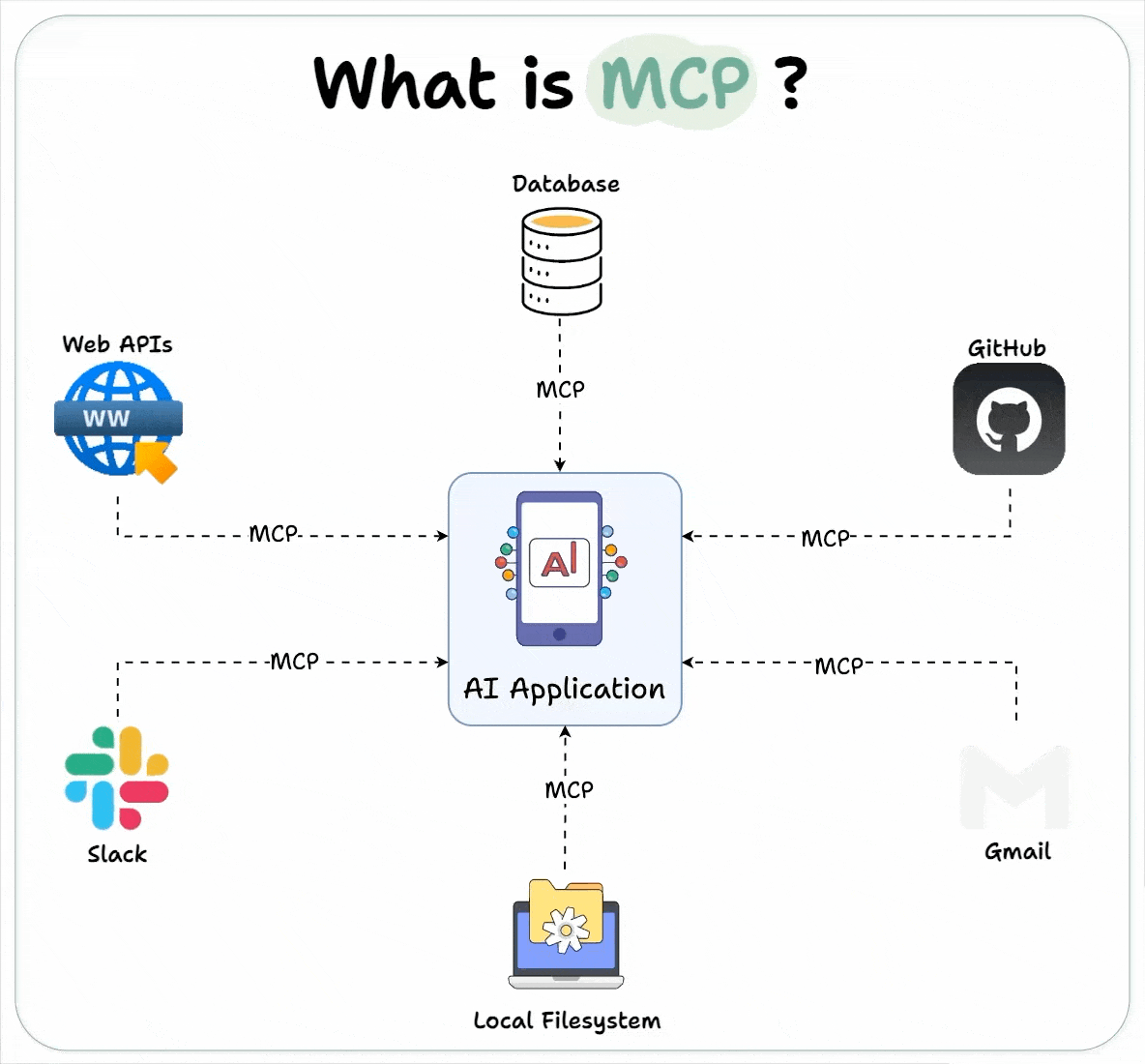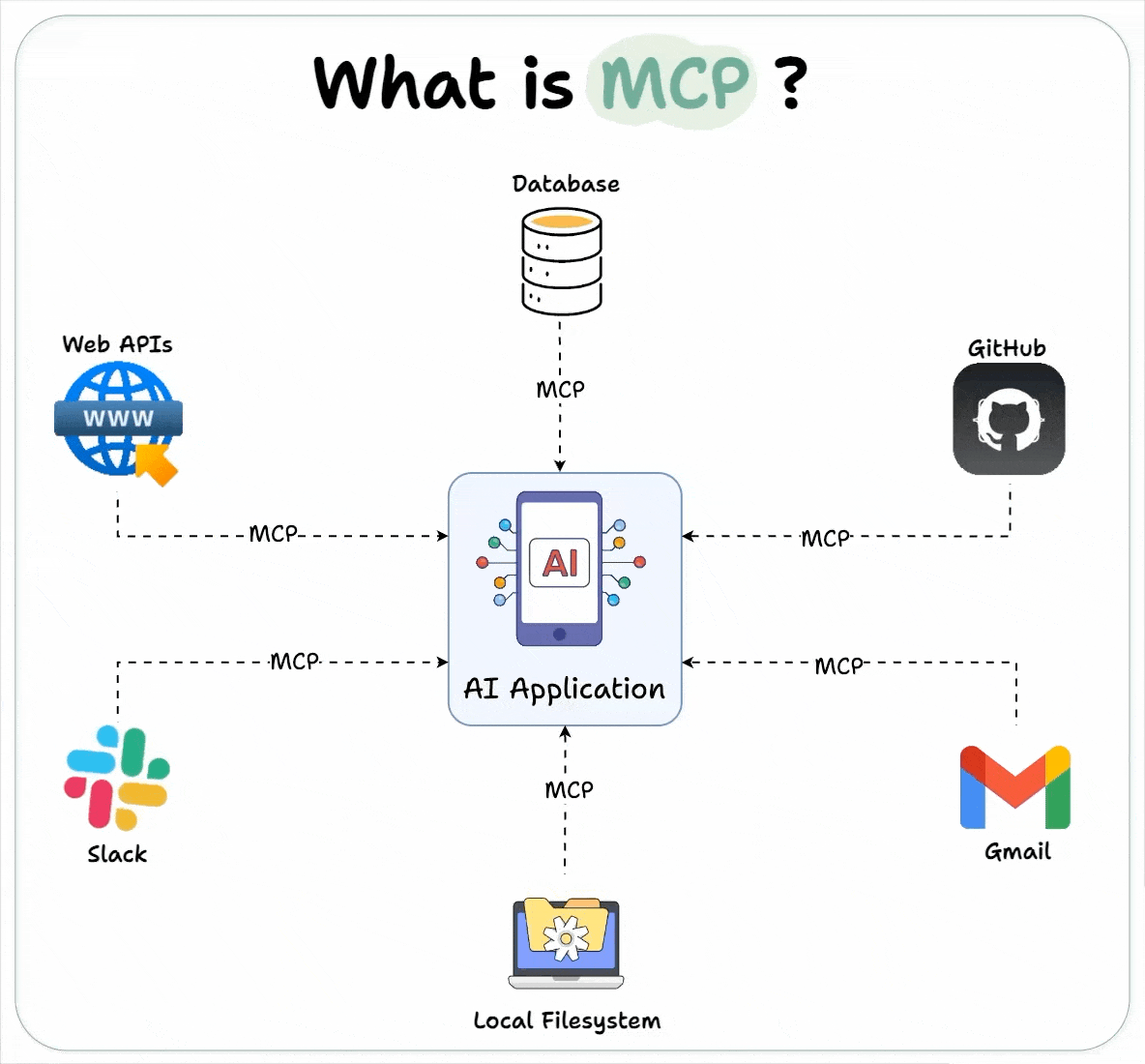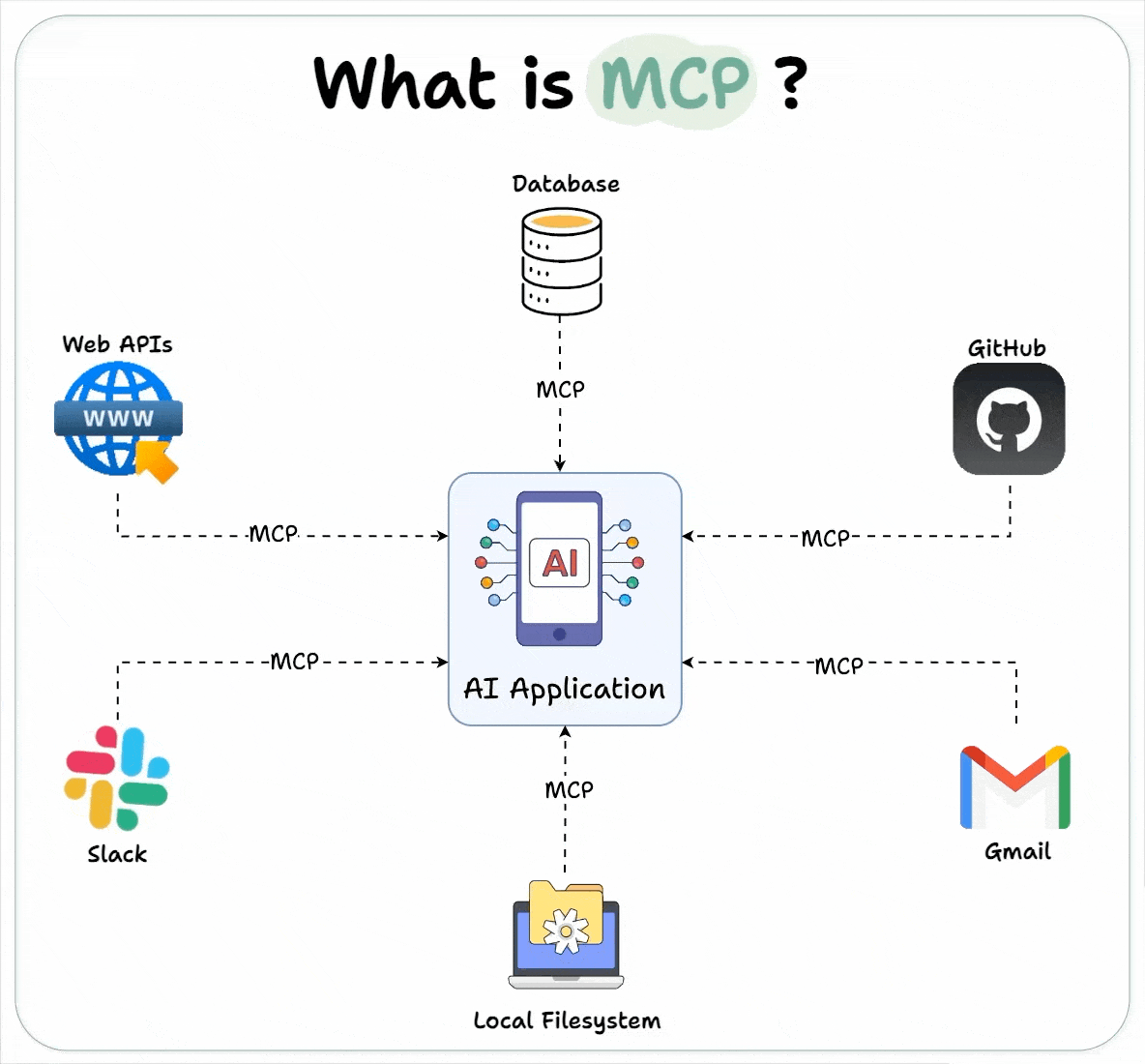
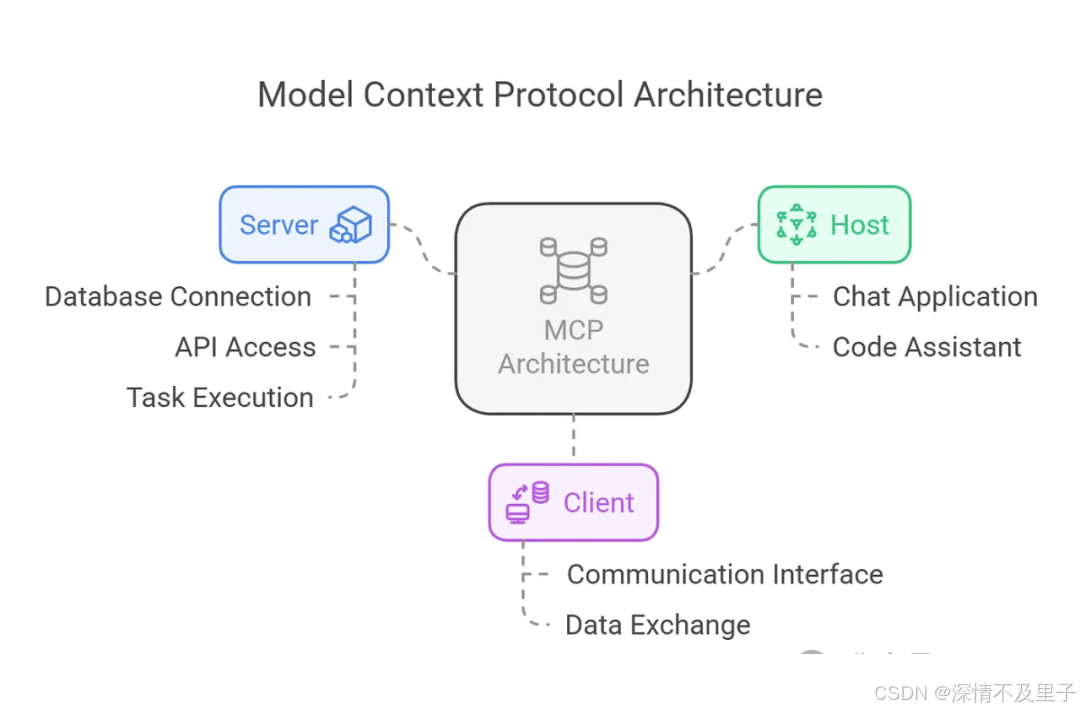
Host 代表任何提供 AI 交互环境、访问外部工具和数据源,Host 是一个还负责运行 MCP Client 的 AI 应用(如 Claude 桌面版 、 Cursor )。MCP Client 在 Host 内运行,实现与 MCP Servers 的通信。
最后,MCP 服务器公开特定的功能,并提供对诸如以下数据的访问:
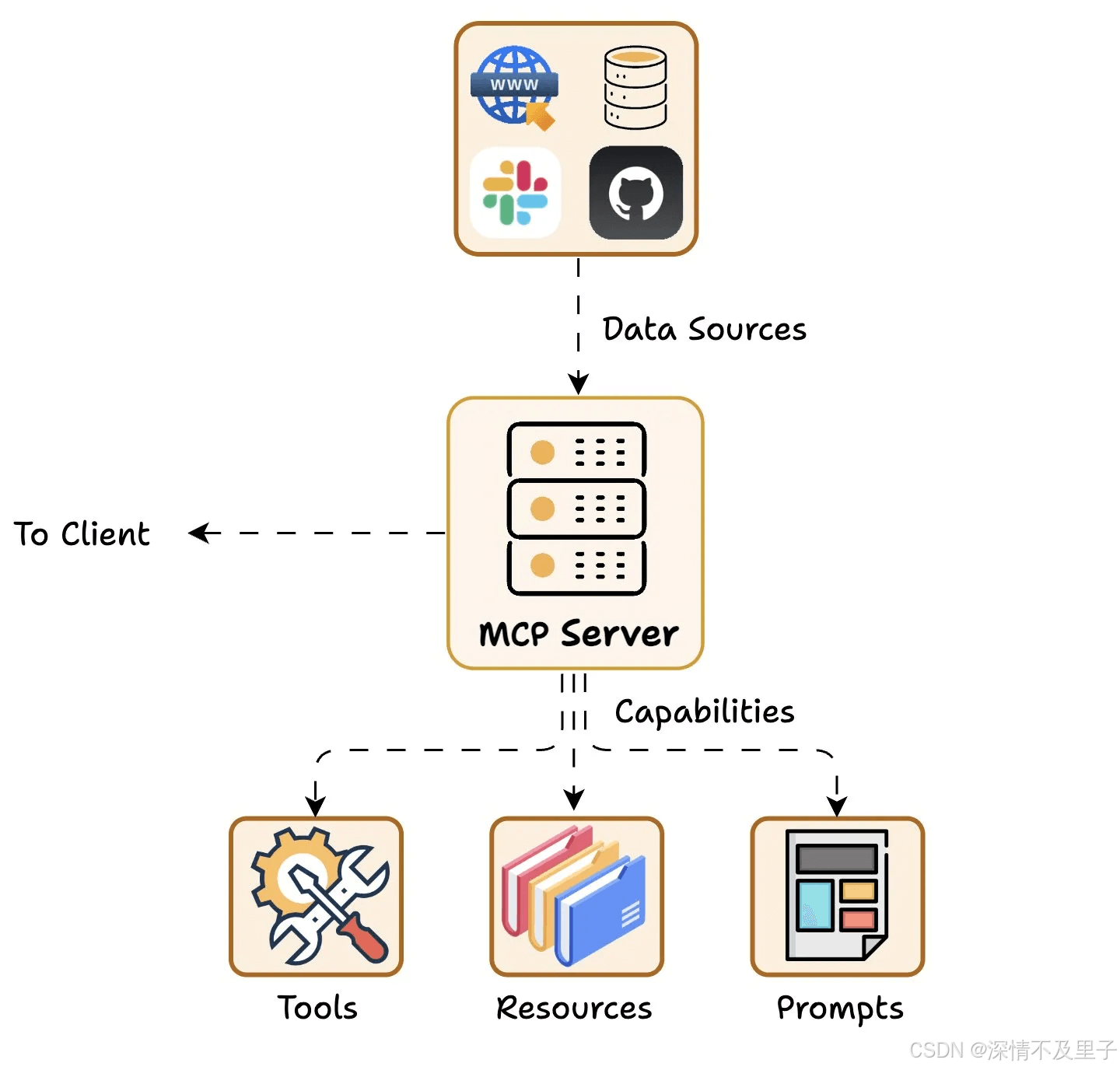
MCP Server 包括:
-
Tools:使大语言模型能够通过你的 Server 执行操作。
-
Resources:将 Server 上的数据和内容开放给大语言模型。
-
Prompts:创建可复用的提示词模板和工作流程。
因此要构建属于我们自己的 MCP 系统,理解客户端-服务器通信机制是必不可少的。
MCP Server 与 MCP Client 之间采用了一种动态服务发现与适配机制,即能力交换(Capability Exchange)机制。通过下图,我们可以直观地理解其工作原理:
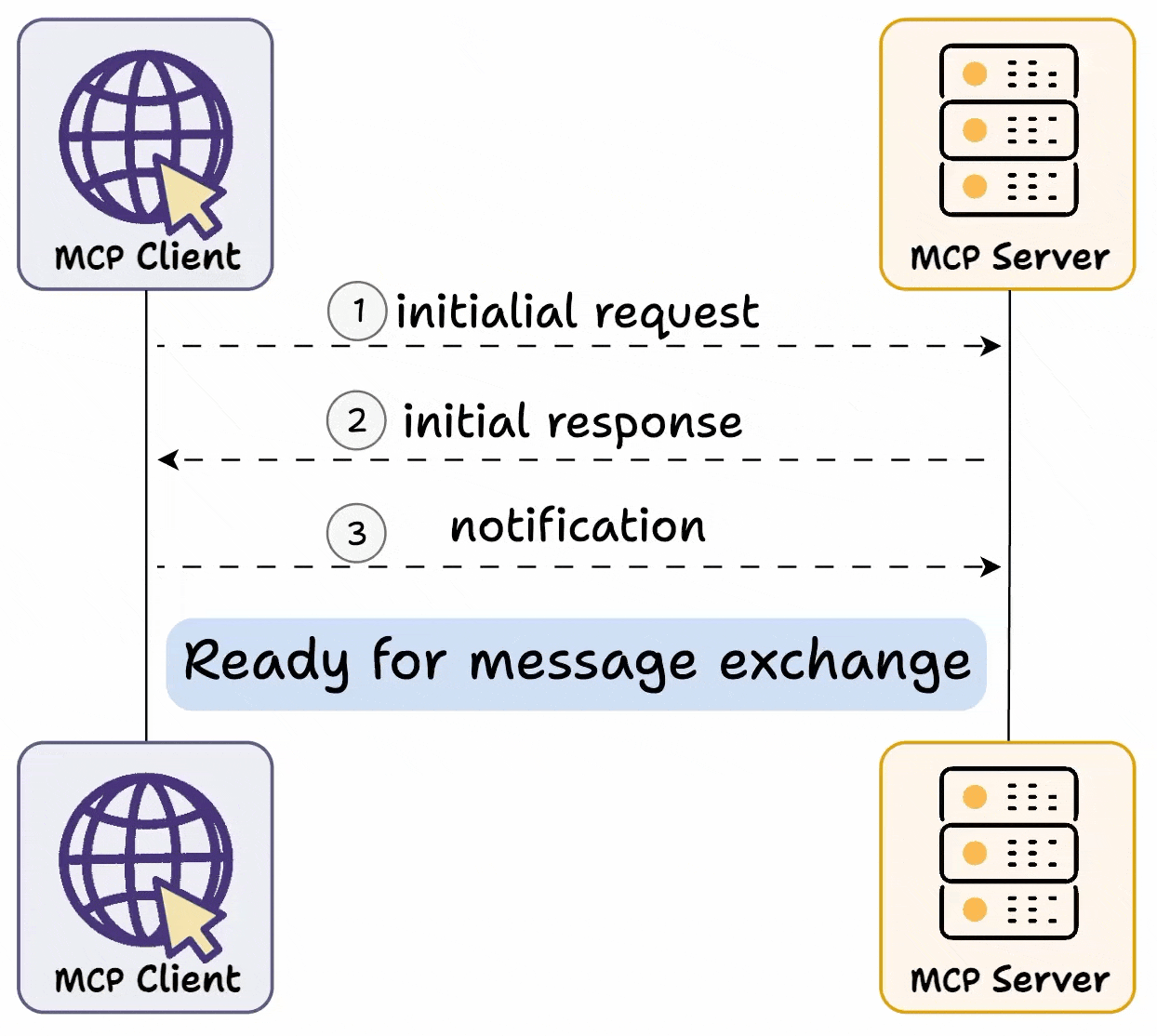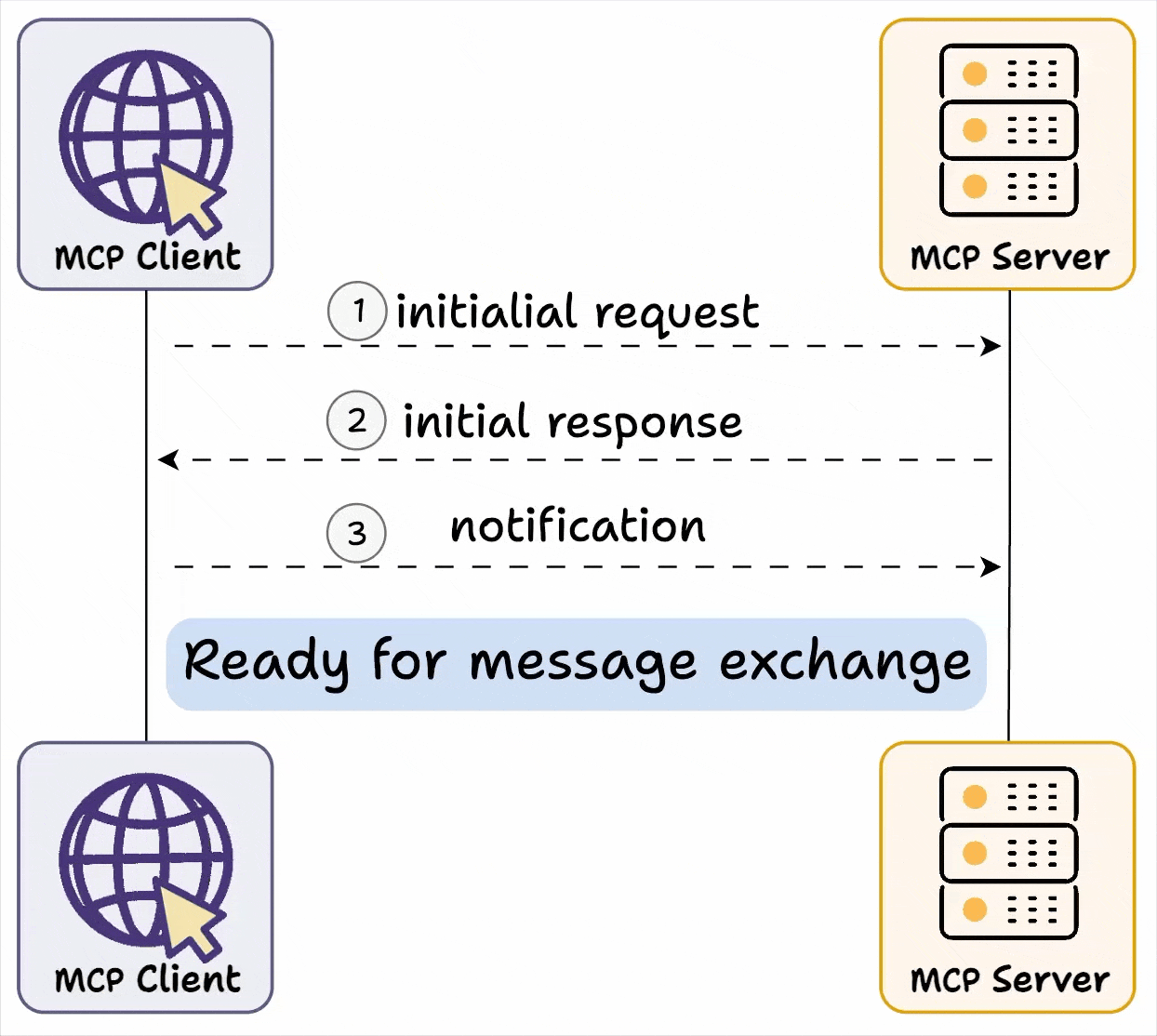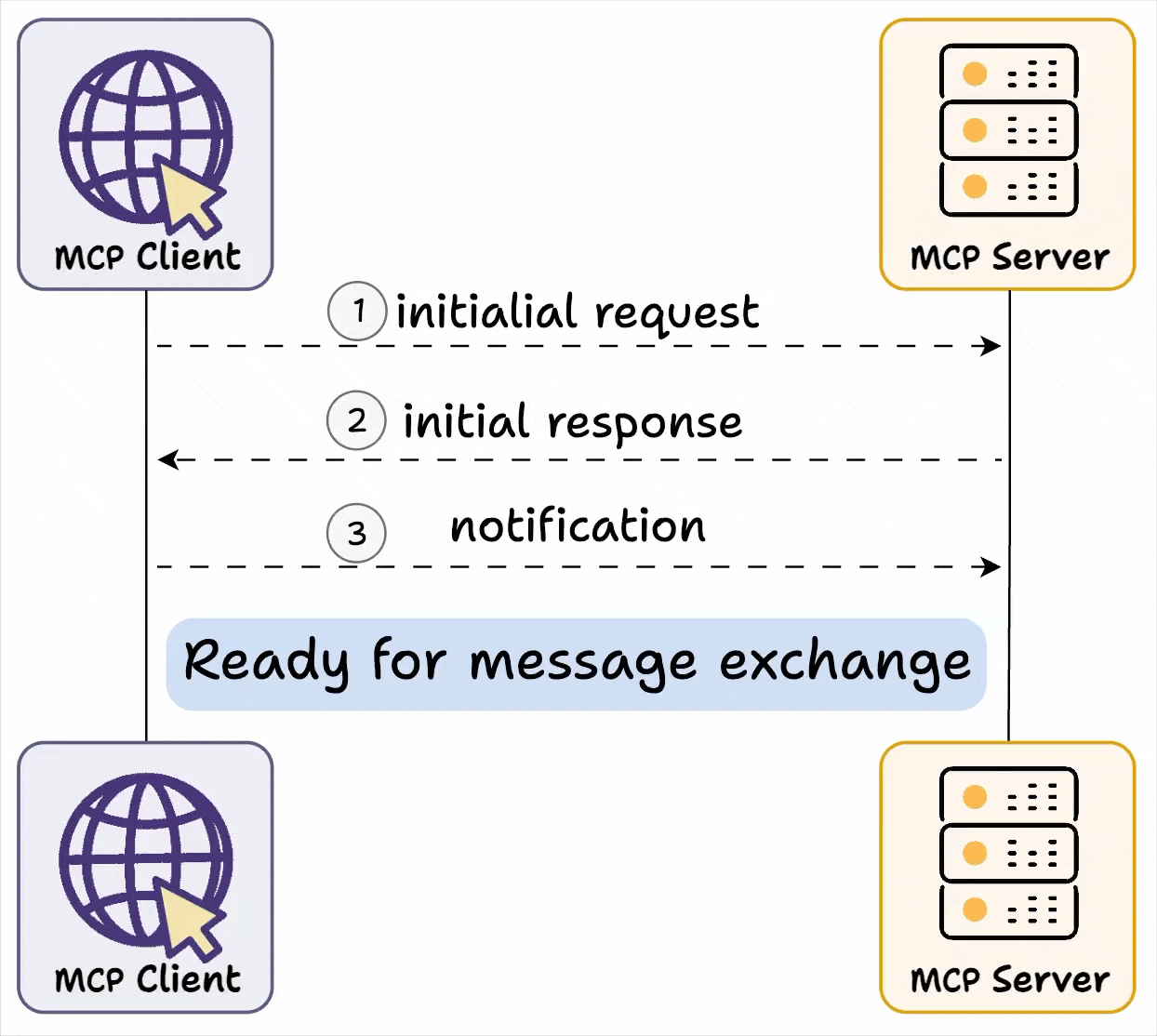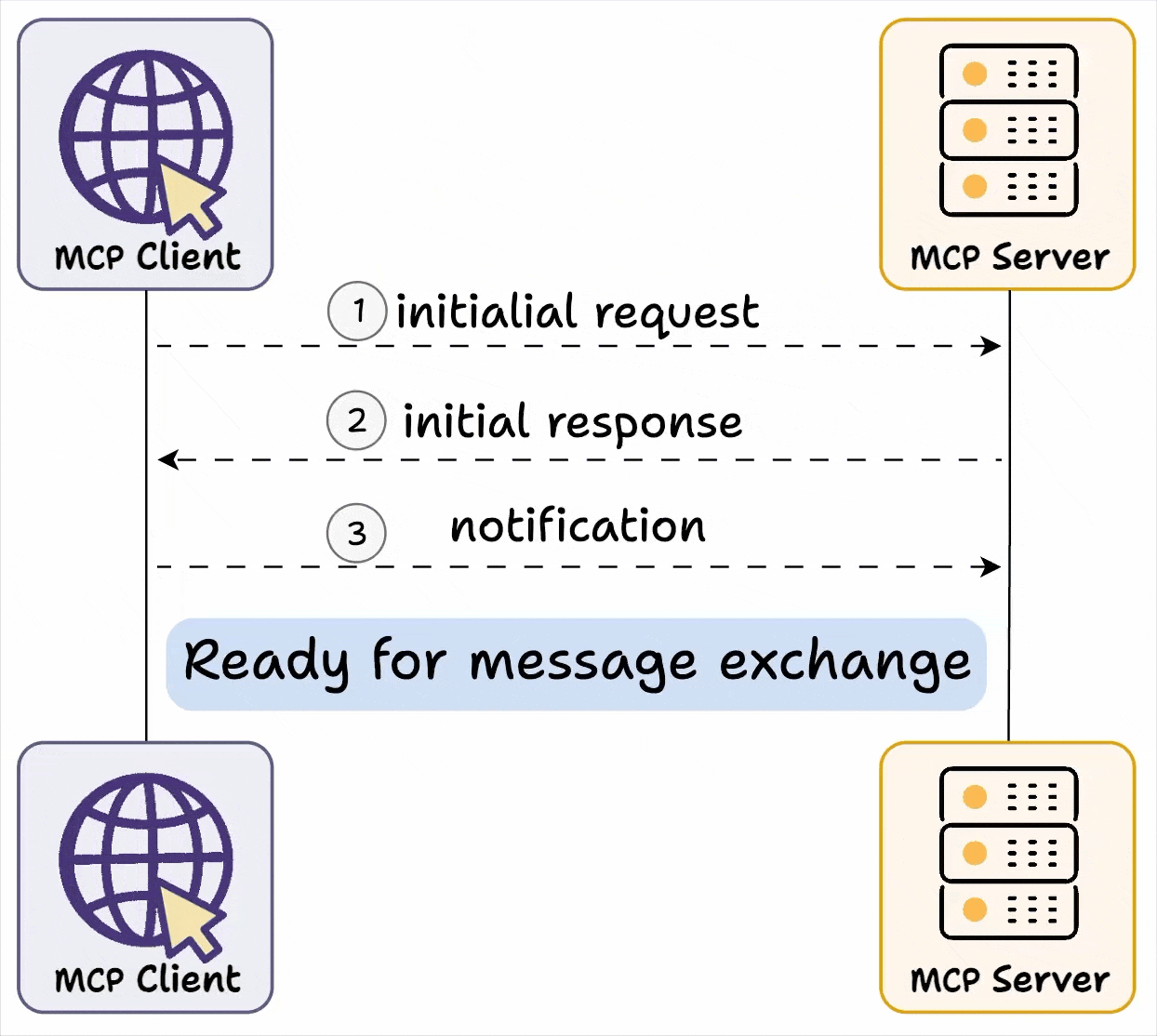
首先进行Capability Exchange,这是一种动态服务发现与适配机制,作为MCP连接建立的必要步骤,其功能类似于"握手协议"。
Capability Exchange 流程如下:
- 客户端发送初始请求,获取服务器能力信息
- 服务器返回其能力信息详情
- 例如当天气 API 服务器被调用时,它可以返回可用的“tools”、“prompts templates”及其他资源供客户端使用**
- 交换完成后,客户端确认连接成功,然后继续交换消息。
那么Capability Exchange 流程具体如何实现呢?
MCP协议官方提供了两种主要通信方式:
-
stdio:通过标准输入输出流进行本地通信。
-
SSE(Server-Sent Events):通过 HTTP 协议实现服务器到客户端的实时单向数据推送,结合 HTTP POST 用于客户端到服务器的消息发送。
SSE Transport 是 MCP 中基于 HTTP 的传输方式,利用 SSE 技术实现服务器到客户端的流式消息推送,同时通过 HTTP POST 请求处理客户端到服务器的双向通信。
这种机制特别适合需要实时更新或远程通信的场景。这两种方式均采用全双工通信模式,通过独立的读写通道实现服务器消息的实时接收和发送。
这时候有同学可能会问了,什么是SSE Transport呢?
三、SSE Transport 的工作原理
SSE(Server-Sent Events)是一种基于 HTTP 协议的服务器推送技术,它允许服务器通过持久的 HTTP 连接向客户端发送实时更新。
与传统的轮询或长轮询技术相比,SSE 提供了更高效、更实时的数据推送机制。SSE 使用简单的文本格式(如 data: 前缀)来传输数据,并且支持自动重连和事件类型过滤等功能,使其非常适合用于实时通知、数据流更新等场景。
MCP的 SSE Transport 是一种结合了 SSE 和 HTTP POST 的混合通信机制,旨在实现高效的双向通信。其工作流程图如下:
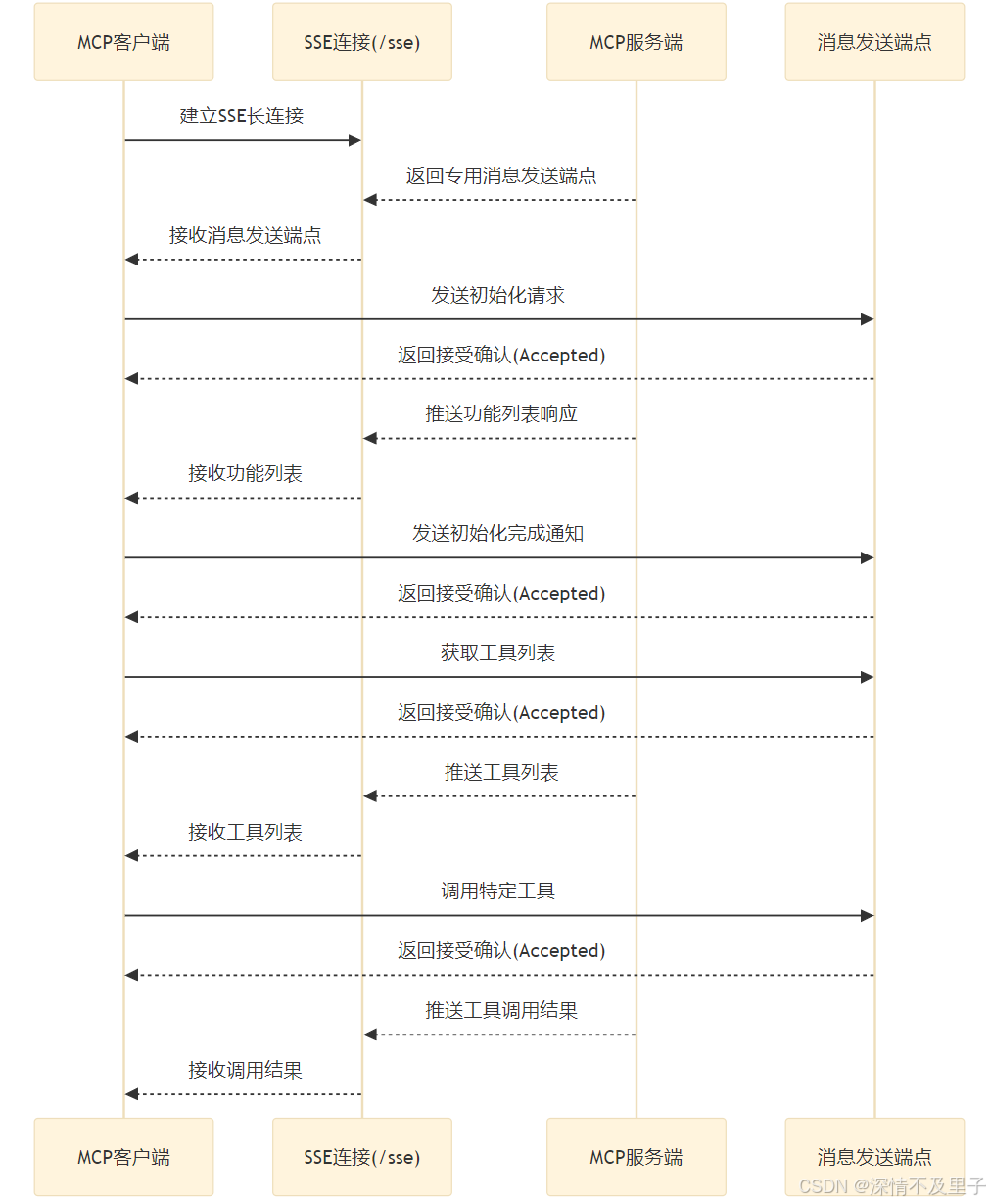
因此我们可以清晰地看到一个详细的SSE Transport 交互流程:
1.建立连接:
-
客户端通过 HTTP GET 请求访问服务器的 SSE 端点(例如 /sse)。
-
服务器响应一个 text/event-stream 类型的内容,保持连接打开。
-
服务器发送一个初始的 endpoint 事件,包含一个唯一的 URI(例如 /messages?session_id=xxx),客户端后续通过这个 URI 发送消息。
2.服务器到客户端的消息推送:
-
服务器通过 SSE 连接,将 JSON-RPC 格式的消息,以事件流的形式发送给客户端。
-
客户端通过 EventSource 或类似机制监听这些事件。
3.客户端到服务器的消息发送:
-
客户端通过 HTTP POST 请求将消息,发送到服务器提供的 URI(例如 /messages)。
-
服务器接收并处理这些请求,返回响应或通过 SSE 推送结果。
4.连接管理:
-
SSE 连接是单向的(服务器到客户端),通常通过定期发送心跳消息(keep-alive)保持活跃。
-
如果连接断开,客户端可以重新发起 SSE 请求重建连接。
通过这种结合 SSE 和 HTTP POST 的方式,MCP 的 SSE Transport 提供了一种高效、灵活且易于实现的实时通信解决方案,适用于多种需要双向交互的实时应用场景。
比如客户端 POST 请求:
POST /messages HTTP/1.1
Content-Type: application/json
{"jsonrpc": "2.0", "method": "post", "params": {"text": "我在测试中"}, "id": 1}
服务器推送:四、SSE 通信流程详解
1 、建立 SSE 连接
客户端首先需要与服务端建立一个SSE长连接,该连接用于接收服务端推送的所有消息:
http://localhost:8080/sse-
可以直接在浏览器中打开此链接实时查看接收到的消息流
-
同步使用curl、Postman等工具进行消息发送测试,便于双向操作验证
建立连接后,服务端会首先返回一个专用的消息发送端点(Endpoint),这是后续通信的关键:
event: endpoint
data: /messages/?session_id=2b3c8777119444c1a1b26bc0d0f7s4xv说明:客户端后续发送的所有消息请求,都必须定向至该专用Endpoint(即特定URL)。当请求格式正确时,Endpoint将返回"Accepted"状态码,而实际的服务器响应内容则通过SSE端点进行异步推送。
2、 通信初始化流程
客户端需要完成两个关键的初始化步骤,确保通信渠道正常建立:
a) 发送初始化请求
客户端需要先向服务端发送初始化请求,表明自身身份和期望的通信参数:
curl -X POST 'http://localhost:8080/messages/?session_id=2b3c8777119444c1a1b26bc0d0f7s4xv -H 'Content-Type: application/json' -d '{
"jsonrpc": "2.0",
"id": 0,
"method": "initialize",
"params": {
"protocolVersion": "2025-05-05",
"capabilities": {},
"clientInfo": {
"name": "mcp",
"version": "0.1.0"
}
}
}'服务端会返回其支持的功能列表,便于客户端了解可用的交互能力:
event: message
data: {
"jsonrpc": "2.0",
"id": 0,
"result": {
"protocolVersion": "2024-05-05",
"capabilities": {
"experimental": {},
"prompts": {
"listChanged": false
},
"resources": {
"subscribe": false,
"listChanged": false
},
"tools": {
"listChanged": false
}
},
"serverInfo": {
"name": "weather",
"version": "1.3.0"
}
}
}b) 发送初始化完成通知
初始化协商完成后,客户端需要明确通知服务端,初始化已完成:
curl -X POST 'http://localhost:8000/messages/?session_id=2b3c8777119444c1a1b26bc0d0f7s4xv' -H 'Content-Type: application/json' -d '{
"jsonrpc": "2.0",
"method": "notifications/initialized",
"params": {}
}'3、 工具调用示例
MCP协议的核心价值在于其工具调用能力,以下是一个完整的调用流程:
a) 获取可用工具列表
客户端首先应该获取服务端提供的工具列表,如果已经知道其工具参数也可跳过,直接去调用工具:
curl -X POST 'http://localhost:8000/messages/?session_id=2b3c8777119444c1a1b26bc0d0f7s4xv' -H 'Content-Type: application/json' -d '{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/list",
"params": {}
}'服务端会返回所有可用的工具及其参数规范:
event: message
data: {
"jsonrpc": "2.0",
"id": 1,
"result": {
"tools": [{
"name": "get_alerts",
"description": "Get weather alerts for a US state.\n\n Args:\n state: Two-letter US state code (e.g. CA, NY)\n ",
"inputSchema": {
"properties": {
"state": {
"title": "State",
"type": "string"
}
},
"required": ["state"],
"title": "get_alertsArguments",
"type": "object"
}
}, {
"name": "get_forecast",
"description": "Get weather forecast for a location.\n\n Args:\n latitude: Latitude of the location\n longitude: Longitude of the location\n ",
"inputSchema": {
"properties": {
"latitude": {
"title": "Latitude",
"type": "number"
},
"longitude": {
"title": "Longitude",
"type": "number"
}
},
"required": ["latitude", "longitude"],
"title": "get_forecastArguments",
"type": "object"
}
}]
}
}b) 调用特定工具
客户端根据需求,选择并调用特定工具:
curl -X POST 'http://localhost:8000/messages/?session_id=2b3c8777119444c1a1b26bc0d0f7s4xv' -H 'Content-Type: application/json' -d '{
"jsonrpc": "2.0",
"id": 2,
"method": "tools/call",
"params": {"name": "get_alerts", "arguments": {"state": "CA"}}
}'服务端执行工具调用并返回结果:
event: message
data: {
"jsonrpc": "2.0",
"id": 2,
"result": {
"content": [{
"type": "text",
"text": "\nEvent: Wind Advisory\nArea: San Gorgonio Pass Near Banning\nSeverity: Moderate\nDescription: * WHAT... \n"
}],
"isError": false
}
}4、通信特点
1 双向异步通信 : 接收通道通过 SSE 长连接接收服务端消息,发送通道通过 HTTP POST 向专用端点发送客户端消息
2 会话状态管理 :使用 session_id 维护客户端与服务端的会话状态,支持多客户端并发连接
3 标准通信协议 :基于 JSON-RPC 2.0 规范,确保通信格式统一,便于跨平台
4 可扩展性 :支持动态发现和调用服务端工具
可以看到,MCP协议凭借其灵活高效的通信机制,为客户端与服务端之间的交互提供了可靠保障。基于SSE的实现方案不仅简化了开发和调试流程,还展现出优异的性能表现。
对开发者来说,深入掌握MCP通信模式不仅能够助力打造高质量的客户端应用,更为设计其他分布式通信系统积累了宝贵的实践经验。
5、注意事项
(1) 所有客户端请求必须使用服务端分配的Endpoint
- 服务端会为每个客户端分配唯一的Endpoint地址,该地址包含协议类型、域名/IP地址和端口号等信息
- 客户端在发起任何API请求时,必须使用服务端分配的Endpoint,不得自行修改或使用其他地址
如果服务端分配的Endpoint为"https://api.example.com:8080",则所有请求URL必须以该地址开头,如需变更Endpoint,必须通过服务端重新分配,客户端不得擅自更改。使用错误的Endpoint可能导致请求失败、数据丢失或安全风险。
(2) 初始化流程必须严格按照顺序完成
五、MCP官方示例分析
我们可以分析一段MCP官方给出的代码示例来学习一下:
all_tools = []
for server in self.servers: tools = await server.list_tools() all_tools.extend(tools)
tools_description = "\n".join([tool.format_for_llm() for tool in all_tools])
system_message = ("You are a helpful assistant with access to these tools:\n\n"
f "{tools_description}\n"
"Choose the appropriate tool based on the user's question. "
"If no tool is needed, reply directly.\n\n"
"IMPORTANT: When you need to use a tool, you must ONLY respond with "
"the exact JSON object format below, nothing else:\n"
"{\n"
' "tool": "tool-name",\n'
' "arguments": {\n'
' "argument-name": "value"\n'
" }\n"
"}\n\n"
"After receiving a tool's response:\n"
"1. Transform the raw data into a natural, conversational response\n"
"2. Keep responses concise but informative\n"
"3. Focus on the most relevant information\n"
"4. Use appropriate context from the user's question\n"
"5. Avoid simply repeating the raw data\n\n"
"Please use only the tools that are explicitly defined above.")方便起见,我们翻译一些系统提示词:
您是一个有用的助手, 可以访问这些工具:{ tools_description} 根据用户的问题选择合适的工具。 如果不需要工具, 请直接回复。
重要提示: 当您需要使用工具时, 您必须只回复下面确切的JSON对象格式, 不回复别的内容: {
"tool": "tool-name",
"arguments": {
"argument-name": "value"
}
}
收到执行结果后:
(1) 将原始数据转换为自然的对话式响应
2.保持回答简洁但信息丰富
3.关注最相关的信息
4.使用用户问题中的适当上下文
5.避免简单地重复原始数据
你只能使用上面明确定义的工具。看到这里,你是否已经明白了MCP的核心原理呢?简单来说,MCP就是将函数描述直接嵌入系统提示词中。
与传统的Function Calling不同,MCP无需将函数参数填入请求参数tools中,也无需依赖云端解析tools的过程。
相反,MCP将函数介绍和参数返回格式都整合到系统提示词中,只要LLM能够理解这些提示词,就能按照既定格式输出结果,从而实现格式的统一。
理解了MCP的基本原理后,我们就能清晰地划分MCP的服务端和客户端:
- ✅MCP服务端:负责执行具体的函数工具。
- ✅MCP客户端:负责与LLM交互,包括介绍函数和获取函数参数。
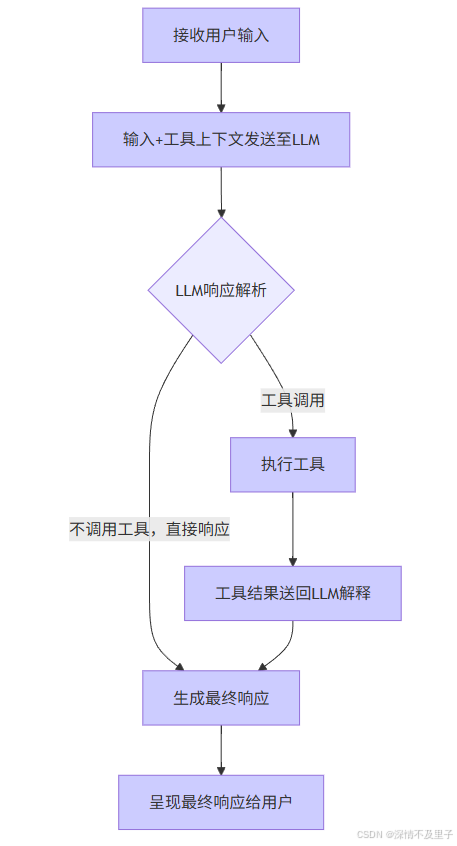
目前,MCP服务端中常用的函数工具和数据查询工具已由社区开发者开发完成,我们可以直接调用。
对于大多数开发者而言,主要的工作还是集中在MCP客户端的开发上。在MCP客户端中,我们需要根据业务流程,引导LLM选择合适的函数工具进行调用,最终实现业务逻辑。
六、MCP的实际应用方式说明
我们将按照官方 GitHub 仓库 modelcontextprotocol/python-sdk 的指导,实际操作开发一个 MCP(Model Context Protocol)Server。
在这个示例中,我们将为 Claude Desktop App 扩展两个新的工具功能:calculate_bmi 和 fetch_weather。默认情况下,Claude Desktop App 并不具备计算 BMI 和查询天气的能力,因此我们将通过 MCP Server 来实现这些功能。
Step1:实现 MCP Server (Python SDK)
# server.py
import httpx
from mcp.server.fastmcp import FastMCP
# 创建一个 MCP 服务器实例,命名为 "Demo"
mcp = FastMCP("Demo")
# 使用 @mcp.tool() 装饰器注册一个同步工具函数,用于计算 BMI
@mcp.tool()
def calculate_bmi(weight_kg: float, height_m: float) -> float:
"""
根据体重(千克)和身高(米)计算 BMI(身体质量指数)
参数:
weight_kg (float): 体重,单位为千克
height_m (float): 身高,单位为米
返回:
float: 计算得到的 BMI 值
"""
return weight_kg / (height_m ** 2)
# 使用 @mcp.tool() 装饰器注册一个异步工具函数,用于获取城市天气信息
@mcp.tool()
async def fetch_weather(city: str) -> str:
"""
获取指定城市的当前天气信息
参数:
city (str): 城市名称
返回:
str: 天气信息的响应文本
"""
async with httpx.AsyncClient() as client:
# 发送 GET 请求到天气 API,获取指定城市的天气信息
response = await client.get(f"https://api.weather.com/{city}")
return response.text
# 如果当前脚本作为主程序运行,则启动 MCP 服务器
if __name__ == "__main__":
mcp.run()
Step2:实现 MCP Client
MCP 客户端充当 LLM 和 MCP 服务器之间的桥梁,MCP 客户端的工作流程如下:
-
MCP 客户端首先从 MCP 服务器获取可用的工具列表。
-
将用户的查询连同工具描述通过 function calling 一起发送给 LLM。
-
LLM 决定是否需要使用工具以及使用哪些工具。
-
如果需要使用工具,MCP 客户端会通过 MCP 服务器执行相应的工具调用。
-
工具调用的结果会被发送回 LLM。
-
LLM 基于所有信息生成自然语言响应。
-
最后将响应展示给用户。
在开始之前,我们需要先完成 MCP Client 客户端类的初始化工作。
MCPClient 类的初始化主要涉及以下三个核心组件:
- self.session:用于存储与 MCP 服务器的会话对象,初始值为 None,在建立服务器连接时进行赋值。
- self.exit_stack:采用 AsyncExitStack 管理异步资源,确保程序结束时能够正确释放所有资源(包括服务器连接和会话等)。
- self.client:创建 OpenAI 异步客户端,通过 OpenRouter 访问 LLM。
具体实现步骤如下:
- 将 base_url 设置为 OpenRouter 的 API 端点。
- 从环境变量中获取 API Key(请确保已配置 OPENROUTER_API_KEY 环境变量)。
class MCPClient:
def init(self):
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.client = AsyncOpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)然后我们需要让MCP Client 和 MCP 服务器连接,我们这里创建一个connect_to_server 方法负责建立与 MCP 服务器的连接。
它首先配置服务器进程的启动参数,然后通过 stdio_client 建立双向通信通道,最后创建并初始化会话。
async def connect_to_server(self, server_script_path: str):
server_params = StdioServerParameters(
command="python",
args=[server_script_path],
env=None
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# 列出可用工具
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])所有的资源管理都通过 AsyncExitStack 来处理,确保资源能够正确释放。连接成功后,它会打印出 MCP 服务器提供的所有可用工具。
接下来,我们定义 process_query 方法来实现请求处理流程:
-
初始化请求:将用户查询作为初始消息发送给 LLM,并附带 MCP 服务器上所有可用工具的描述信息。
-
LLM 决策:LLM 分析用户查询,判断是否需要直接回答或调用工具。若需调用工具,LLM 将明确指定工具名称及相应参数。
-
工具调用:MCP 客户端根据 LLM 的指示执行工具调用,并收集执行结果。
-
结果反馈:将工具调用的结果返回给 LLM,LLM 基于这些新信息生成或更新回答。
-
迭代处理:若 LLM 认为仍需更多信息,将继续请求调用其他工具。此过程循环进行,直至 LLM 收集到足够信息,能够完整回答用户查询。
async def process_query(self, query: str) -> str:
"""使用 LLM 和 MCP 服务器提供的工具处理查询"""
messages = [
{
"role": "user",
"content": query
}
]
response = await self.session.list_tools()
available_tools = [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.inputSchema
}
} for tool in response.tools]
// 初始化 LLM API 调用
response = await self.client.chat.completions.create(
model="qwen/qwen-plus",
messages=messages,
tools=available_tools
)
final_text = []
message = response.choices[0].message
final_text.append(message.content or "")
// 处理响应并处理工具调用
while message.tool_calls:
// 处理每个工具调用
for tool_call in message.tool_calls:
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
// 执行工具调用
result = await self.session.call_tool(tool_name, tool_args)
final_text.append(f"[Calling tool {tool_name} with args {tool_args}]")
// 将工具调用和结果添加到消息历史
messages.append({
"role": "assistant",
"tool_calls": [
{
"id": tool_call.id,
"type": "function",
"function": {
"name": tool_name,
"arguments": json.dumps(tool_args)
}
}
]
})
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(result.content)
})
// 将工具调用的结果交给 LLM
response = await self.client.chat.completions.create(
model="qwen/qwen-plus",
messages=messages,
tools=available_tools
)
message = response.choices[0].message
if message.content:
final_text.append(message.content)
return "\n".join(final_text)Step3:MCP Client调用工具
在 MCP 客户端中,我们使用了以下两个核心函数来与 MCP 服务器进行交互,以实现工具管理和功能调用。
-
list_tools():该函数用于获取 MCP 服务器提供的所有可用工具。这些工具可以是数据处理、查询、监控等功能的封装,具体取决于 MCP 服务器的配置。通过调用此函数,客户端可以动态了解服务器支持的功能,并根据需要选择合适的工具进行调用。 -
call_tool(name, args):该函数用于调用指定的工具并获取其执行结果。其中,name参数指定要调用的工具名称,args参数用于传递工具所需的输入参数。例如,调用list_indices工具可以获取 Elasticsearch 集群中的所有索引信息,这对于监控集群状态或进行索引管理非常有用。
以下是一个完整的代码示例,展示了如何使用 MCP 客户端与服务器进行交互:
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
async def run():
# 配置服务器参数
server_params = StdioServerParameters()
# 建立与 MCP 服务器的连接
async with stdio_client(server_params) as (read, write):
# 创建客户端会话
async with ClientSession(read, write) as session:
# 初始化会话,确保客户端与服务器之间的通信准备就绪
await session.initialize()
# 列出 MCP 服务器提供的所有可用工具
tools = await session.list_tools()
print("Available Tools:", tools)
# 调用 `list_indices` 工具,获取 Elasticsearch 集群中的索引信息
indices = await session.call_tool("list_indices")
print("Cluster Indices:", indices)
if __name__ == "__main__":
import asyncio
# 运行异步主函数
asyncio.run(run())
Step4:集成 LLM调用 MCP Client
在实际应用中,LLM 需要根据用户需求自主决策是否调用工具以及调用哪些工具,这就需要我们将 MCP Client 与 LLM 进行深度集成。
这里我们以通义千问为例,通过 OpenRouter 网关实现统一的 LLM 接口访问,使代码能够兼容不同厂商的大模型。
为简化流程,我们采用 OpenRouter 作为统一的 LLM 网关。该平台提供与 OpenAI 兼容的接口,使我们能够通过标准 OpenAI API 访问包括通义千问在内的多种大型语言模型。
OpenRouter 网关核心优势
| 特性 | 传统多 LLM 接入方式 | OpenRouter 接入方式 |
| API 兼容性 | 需适配各厂商专属 API | 统一 OpenAI 兼容接口 |
| 模型切换成本 | 需修改代码底层逻辑 | 仅需修改模型名称(如qwen/qwen-plus) |
| 功能支持 | 工具调用格式不统一 | 标准化函数调用协议 |
| 安全性 | API Key 分散管理 | 集中管理 + 权限控制 |
这样我们只需在创建 OpenAI 客户端时指定 OpenRouter 的 base_url 和 api_key,并在调用模型时以 <provider>/<model> 的格式(例如 qwen/qwen-plus)指定目标模型,OpenRouter 就会根据模型名称自动将请求路由到对应的 LLM 上。除此之外,其他代码与标准的 OpenAI SDK 保持一致。
import os
import json
import asyncio
from typing import Optional
from mcp.client import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from openai import AsyncOpenAI, types
class MCPClient:
def __init__(self):
"""初始化客户端组件"""
self.session: Optional[ClientSession] = None # MCP服务器会话
self.exit_stack = AsyncExitStack() # 异步资源管理器
self.llm_client = self._init_llm_client() # LLM客户端(通过OpenRouter)
def _init_llm_client(self) -> AsyncOpenAI:
"""配置OpenRouter连接参数"""
return AsyncOpenAI(
base_url="https://openrouter.ai/api/v1", # OpenRouter统一API端点
api_key=os.getenv("OPENROUTER_API_KEY"), # 从环境变量获取API Key
timeout=90 # 设置较长超时应对复杂工具调用
)
async def connect_server(self, server_path: str):
"""建立与MCP服务器的双向通信"""
server_params = StdioServerParameters(
command="python",
args=[server_path], # MCP服务器脚本路径(如./server.py)
env=os.environ.copy()
)
# 创建通信通道并初始化会话
stdio = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.session = await self.exit_stack.enter_async_context(ClientSession(*stdio))
await self.session.initialize()
# 打印可用工具列表
tools = await self.session.list_tools()
print(f"[MCP Client] 成功连接,可用工具:{[t.name for t in tools]}")
async def handle_user_input(self, query: str) -> str:
"""处理用户查询的核心逻辑"""
messages = [{"role": "user", "content": query}] # 初始化对话历史
response_buffer = [] # 存储对话过程中的所有输出
while True:
# 1. 获取MCP工具列表并转换为OpenAI函数调用格式
tools = await self.session.list_tools()
function_list = [self._format_for_openai(t) for t in tools]
# 2. 调用LLM生成响应(支持工具调用)
llm_resp = await self.llm_client.chat.completions.create(
model="qwen/qwen-plus", # 使用通义千问模型(OpenRouter格式)
messages=messages,
tools=function_list,
tool_selection="auto" # 让LLM自动决定是否使用工具
)
choice = llm_resp.choices[0]
if choice.message.tool_calls:
# 处理工具调用
for tool_call in choice.message.tool_calls:
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
# 执行工具并获取结果
tool_resp = await self.session.call_tool(tool_name, tool_args)
response_buffer.append(f"[工具执行] {tool_name}({tool_args}) → {tool_resp.content}")
# 更新对话历史:添加工具调用记录和返回结果
messages.extend([
{"role": "assistant", "tool_calls": [tool_call]},
{"role": "tool", "tool_call_id": tool_call.id, "content": tool_resp.content}
])
else:
# 添加最终文本响应并结束循环
final_resp = choice.message.content or "未生成有效响应"
response_buffer.append(final_resp)
break
return "\n".join(response_buffer)
def _format_for_openai(self, tool: dict) -> dict:
"""将MCP工具元数据转换为OpenAI函数调用格式"""
return {
"type": "function",
"function": {
"name": tool["name"],
"description": tool["description"],
"parameters": tool["inputSchema"] # 直接复用MCP定义的参数结构
}
}
async def shutdown(self):
"""安全释放所有资源"""
await self.exit_stack.aclose()这样的咱们的完整调用示例如下:
async def run_demo():
client = MCPClient()
try:
# 连接MCP服务器(假设server.py在当前目录)
await client.connect_server("server.py")
# 示例1:BMI计算场景
bmi_query = "身高1.65米、体重65公斤的BMI是多少?"
bmi_response = await client.handle_user_input(bmi_query)
print(f"\n【BMI计算】\n{bmi_response}")
# 示例2:天气查询场景
weather_query = "查询北京的天气"
weather_response = await client.handle_user_input(weather_query)
print(f"\n【天气查询】\n{weather_response}")
finally:
await client.shutdown() # 确保资源释放
if __name__ == "__main__":
asyncio.run(run_demo())运行结果与日志分析如下:
[MCP Client] 成功连接,可用工具:['calculate_bmi', 'fetch_weather']
【BMI计算】
身高1.65米、体重65公斤的BMI是多少?
[工具执行] calculate_bmi({"weight_kg": 65.0, "height_m": 1.65}) → 23.876712328767123
该身高体重对应的BMI值为23.88,属于正常体重范围。
【天气查询】
查询北京的天气
[工具执行] fetch_weather({"city": "北京"}) → 北京当前天气:多云,气温25℃,风力3级
北京的天气为多云,当前气温25摄氏度,风力3级。七、总结
当前的 MCP 开发仍处于早期阶段,工程化框架尚未完善,开发流程缺乏标准化。根据 MCP Roadmap 的规划,未来将聚焦于三个核心方向:Remote MCP Support、Agent Support 和 Developer Ecosystem。
Remote MCP Support 旨在通过实现鉴权、服务发现和无状态服务等功能,向 Kubernetes 架构靠拢,构建生产级、可扩展的 MCP 服务。同时,基于最新的 RFC 提案,将支持 Streamable HTTP 协议,以实现低延迟、双向数据传输,解决现有 MCP Server SSE 方案在云原生场景中的局限性。
Agent Support 将优化复杂领域中的 Agent 工作流,提升人机交互体验,为实际应用提供更高效的解决方案。
Developer Ecosystem 则致力于吸引更多开发者和大型厂商参与,共同拓展 AI Agent 的能力边界,推动 MCP 生态的繁荣发展。
若 MCP 成为未来标准,Agent 应用能否准确调用各个 MCP 将成为模型强化学习(RL)的关键功能。与 Function Call 模型不同,MCP 作为动态工具库,要求模型具备对新增 MCP 的泛化理解能力,这对 AI 模型的适应性和扩展性提出了更高要求。总体而言,MCP 的发展将深刻影响 AI Agent 的技术演进和应用场景,推动 AI 生态向更高效、更智能的方向迈进,让我们一起拭目以待吧~


















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











